DEEP PARTIAL PERSON RE-IDENTIFICATION VIA ATTENTION MODEL(二)
概要:
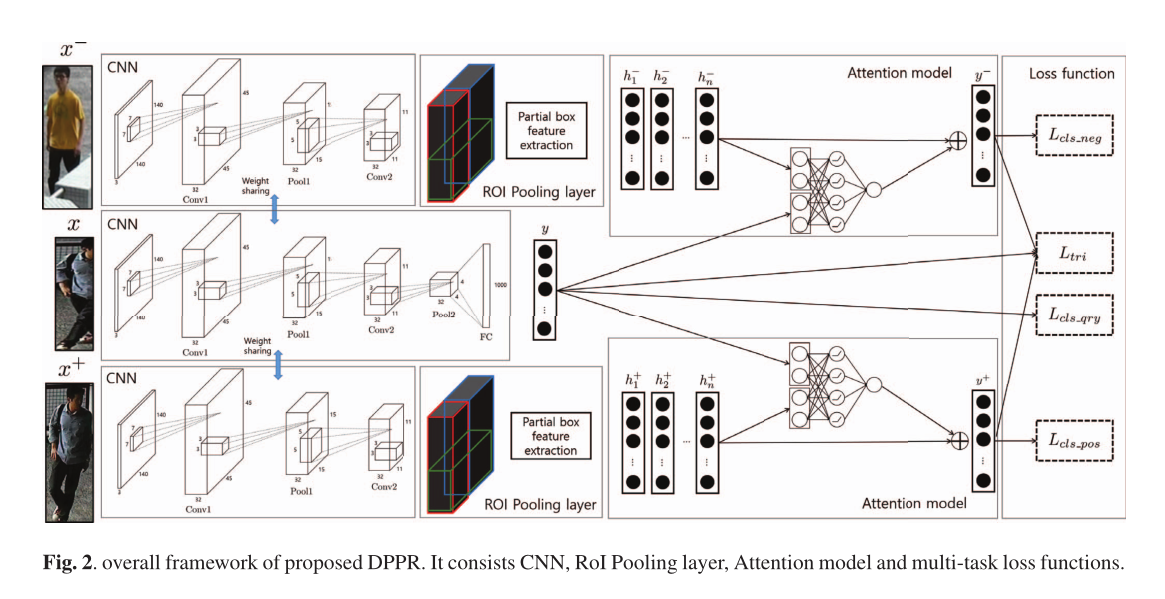
本文考虑了一种称为深度部分行人识别(DPPR)的新算法,用于部分行人身份重识别,其中仅观察到人的一部分并且全身图像可用于识别。DPPR基于端到端深度模型,该模型利用卷积神经网络(CNN)、RoI池层和注意力模型。RoI池层允许提取与输入图像的预定义部分相对应的特征向量。注意力模型选择CNN特征向量的子集。为了对所提出的模型进行定性评估,在构建p-CUHK03时随机裁剪了CUHK03的数据。

贡献:
本文提出了一种用于部分人员重新识别的端到端深度模型。在本文的其余部分,所提出的算法将被称为深度部分人重新识别(DPPR)。本文的主要贡献如下。1) 据我们所知,我们是第一个将深度学习应用于部分人重新识别的人。2) 利用CNN、RoI池和注意力模型,提出了一种新的局部图像与全图像匹配框架。
RoI池层允许提取与输入图像的预定义部分相对应的特征向量。注意力模型选择性地关注CNN特征向量的子集。
方法:
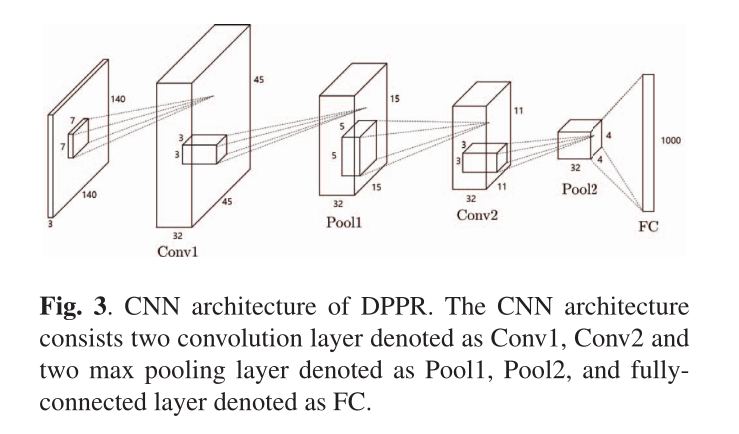
如图3所示,它由两个卷积层、两个池层和一个完全连接层组成。第一个卷积层(Conv1)由32个特征图组成,内核大小为7x7,步幅为3。然后是MAX池层(Pool1)使用3x3大小的内核,步幅为3。第二卷积层(Conv2)有32个特征映射,内核大小为5x5,步幅为1。然后再次使用MAX池层(Pool2),内核大小是3x3,步幅是3。最后,完全连接层(FC)为每个图像输入生成1000维特征向量的输出。对于查询图像,使用上面的CNN提取1000维特征向量。但对于正像和负像,Pool2层被替换为RoI Pooling层。
RoI Pooling
为了提取相应部分盒的特征向量,使用了RoI Pooling层。每个部分框中的特征向量表示全身图库人物图像的相应部分。具体来说,CNN中的Pool2层被正图像和负图像的RoI Pooling层所取代。由于输入图像的大小为140x140,Conv2层的特征地图大小为11x11,因此我们对RoI Pooling层使用了0.08的空间比率。然后生成4x4大小的特征图,就像Pool2层一样。RoI池层和连续FC层为每个正图像和负图像输出13个特征向量,表示为正RoI特征h+=[h+1,··,h+13]。

给定RoI特征h+和h−, 计算RoI特征的加权和,以生成正特征和负特征:
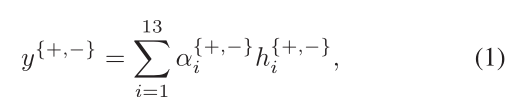
其中α+i和α− i是对应于第i个部分框的正、负图像的关注权重。
我们使用基于查询特征y的前馈神经网络来计算非标准化得分s+i和s− 一:
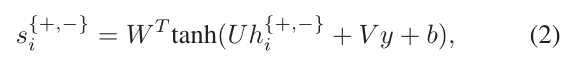
其中W、U、V、b是训练期间学习的注意力模型参数.
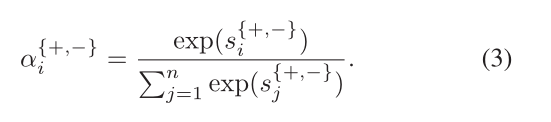
Loss function
三联体损失:![]()
交叉熵损失: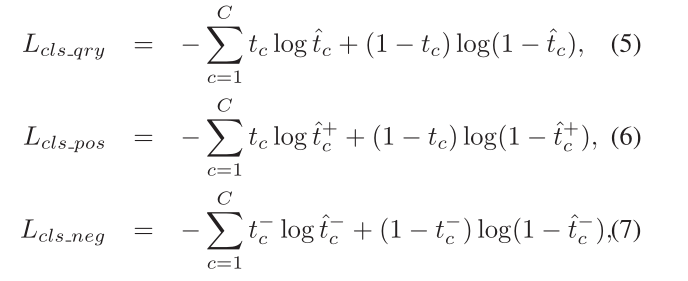
总损失是上述四个损失函数的总和:
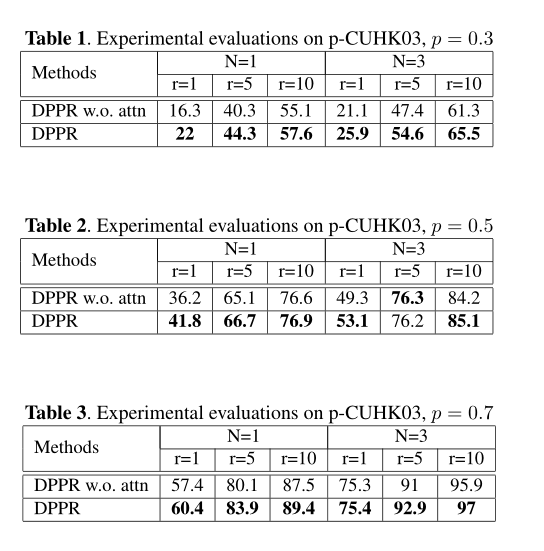
EXPERIMENTS:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号