总览
启发算法 - 汇总篇
优化问题-实战经验
车辆路径规划问题分类
## 优质资源
公众号:运筹优化与学习
原理
线性规划
差分进化算法
## 遗传算法
遗传算法-总体框架
遗传算法-选择算子
遗传算法-编码
遗传算法-目标函数与适应度函数变换
进阶汇总
##
模拟退火算法简介
粒子群算法 PSO【1】- 基本原理
## 蚁群算法
蚁群算法【1】基本原理
蚁群算法【2】 优化方法
蚁群算法【3】-论文
拉格朗日松弛
人工蜂群算法(Artificial Bee Colony,ABC)
优化模型建模语言 Pyomo
多目标遗传算法NSGA-II
NSGA-III
求解器 Gurobi,Cplex,SCIP,CBC
混合启发算法
代码
大规模邻域搜索 - 代码
自适应大邻域搜索算法 - 代码
变邻域搜索 - 代码
禁忌搜索算法 - 代码
### 排产
基于日历的 柔性连续车间 排产仿真
柔性车间生产调度问题
物料回流的排产场景
其他
其他启发式算法
【引】智能优化算法汇总
多目标粒子群优化算法原理及其代码实现
在模型优化方面的应用
什么时候使用 优化算法 优化模型参数 而不用梯度下降
遗传算法 进行 超参数 调优
遗传算法 进行 特征选择
粒子群PSO优化融合注意力机制的卷积神经网络-双向长短期记忆网络(PSO-CNN-BiLSTM-Attention)的多变量预测
|
周志华西瓜书 链接:
DeepLearning/books at master · Mikoto10032/DeepLearning
系列教程一
强化学习3-蒙特卡罗MC
强化学习4-时序差分TD
强化学习6-MC与TD的比较-实战
强化学习7-Sarsa
强化学习8-时序差分控制离线算法Q-Learning
强化学习9-Deep Q Learning
强化学习10-Deep Q Learning-fix target
系列教程二

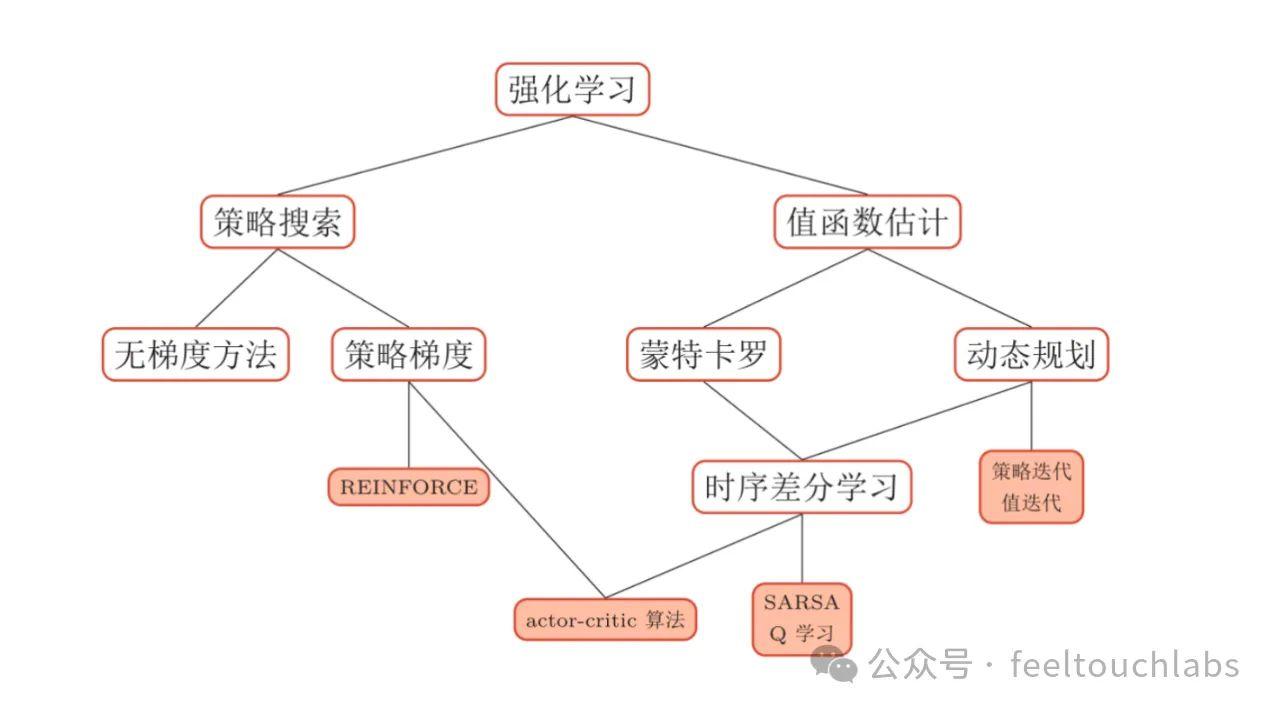
强化学习 Value based核心知识
强化学习 值函数近似Value Function Approximation
强化学习 DQN
Dobule DQN
Q-learning与DQN算法总结
Value Based 总结
强化学习 Policy Based策略梯度
on/off-policy和on/offline和rollout–generation gap
强化学习 Actor Critic
强化学习 PPO
PPO算法中的actor和critic学习率 设置
强化学习 DPO
强化学习 DDPG
LLM强化学习算法演进之路:Q-Learning->DQN->PPO->DPO
强化学习-稀疏奖励问题
RLHF 为什么不对loss 进行梯度下降求解
|
|
|



 浙公网安备 33010602011771号
浙公网安备 33010602011771号