caffe模型转pytorch
pytorch/libtorch qq群: 1041467052
本文介绍的是直接读取caffe权重,并根据caffe网络一步一步的搭同样的pytorch网络。本文以分割网络segnet为例。
首先给出参考链接:
https://blog.csdn.net/DumpDoctorWang/article/details/88716962
绝大部分就是参考这位博主的。
首先是需要配环境,我这配好了segnet caffe的训练环境,还有跑推理的脚本,随便找的改一改确保可以跑就可以,当然配环境和跑前向脚本我也花费了不少时间。下面给出跑推理的脚本。
还有就是一定用pycharm,方便打断点调试。用pycharm还会报找不到cuda,然后点run -> Edit Configurations,在Environment variables添加 (Name)LD_LIBRARY_PATH (Value)/usr/local/cuda/lib64;/home/yhl/software_install/opencv3.2/lib
#-*- coding:utf-8 -*-
import sys,os
caffe_root='/data_1/Yang/project/caffe-segnet-2020'
sys.path.insert(0,os.path.join(caffe_root,'python'))
sys.path.insert(0,"/home/yhl/software_install/opencv3.2/lib")
import cv2
import caffe
import numpy as np
import matplotlib.pyplot as plt
import json
import argparse
model_def='/data_1/Yang/project/caffe-segnet-2020/myfile/segnet.prototxt'
model_weights='/data_1/Yang/project/caffe-segnet-2020/myfile/segnet.caffemodel'
image_file='/data_2/2019biaozhushuju/20190716_traindata/00.txt'
size_h=128
size_w=512
##order:R->G->B
color_segmentation =np.asarray(
[
0,0,0, ##nothing
255,236,139, ##0
255,235,205, ##1
255,228,225, ##2
255,225,255, ##3
255,193,37, ##4
255,174,185, ##5
255,140,0, ##6
255,131,250, ##7
255,105,180, ##8
169,169,169, ##9
162,205,90, ##A
154,192,205, ##B
154,50,205, ##C
144,238,144, ##D
142,142,56, ##E
142,56,142, ##F
139,90,43, ##G
139,62,47, ##H
135,206,235, ##J
131,139,139, ##K
69,139,0, ##L
65,105,225, ##M
64,224,208, ##N
0,238,118, ##P
148,0,211, ##Q
0,255,255, ##R
0,238,238, ##S
110,110,110, ##T
108,166,205, ##U
139,26,26, ##V
176,48,96, ##W
154,205,50, ##X/usr/local/cuda/lib64;/home/yhl/software_install/opencv3.2/lib
192,255,62, ##Y
238,48,167, ##Z
],dtype=np.uint8)
class Caffe_segnet_Segmentation:
def __init__(self,gpu_id,model_def,model_weights,size_h,size_w):
caffe.set_mode_gpu()
self.size_w=size_w
self.size_h=size_h
self.net=caffe.Net(model_def,model_weights,caffe.TEST)
self.net.blobs['data'].reshape(1,3,size_h,size_w)
# input preprocessing: 'data' is the name of the input blob == net.inputs[0]
# self.transformer=caffe.io.Transformer({'data':self.net.blobs['data'].data.shape})
self.transformer=caffe.io.Transformer({'data':self.net.blobs[self.net.inputs[0]].data.shape})
self.transformer.set_transpose('data',(2,0,1)) ##set the input channel order for e.g. RGB to BGR conversion
##input_blob=input*scale.While Python represents images in [0, 1], certain Caffe models
# like CaffeNet and AlexNet represent images in [0, 255] so the raw_scale
# of these models must be 255.
# self.transformer.set_raw_scale('data',255)
# Set the mean to subtract for centering the data.
# self.transformer.set_mean('data',np.array([123.68, 116.779, 103.939]))
# Set the scale of preprocessed inputs s.t. the blob = blob * scale.
# N.B. input_scale is done AFTER mean subtraction and other preprocessing
# while raw_scale is done BEFORE.
# self.transformer.set_input_scale('data',0.0078125)
#Set the input channel order for e.g. RGB to BGR conversion
# as needed for the reference ImageNet model.
# N.B. this assumes the channels are the first dimension AFTER transpose.
self.transformer.set_channel_swap('data',(2,1,0))
def prdict(self,imagename,nclasses=34):
# imagename = "/data_1/Yang/project/2020/chejian/test_data/model_test/seg_chejiahao/0113_E3752H_LSGDC82CX3S211458.jpeg"
image=caffe.io.load_image(imagename.strip()) #type:np.float32,size:(HxWx3) or (HxWx1)
##preprocess:
# - convert to single
#- resize to input dimensions (preserving number of channels)
#- transpose dimensions to K x H x W
# - reorder channels (for instance color to BGR)
# - scale raw input (e.g. from [0, 1] to [0, 255] for ImageNet models)
# - subtract mean
# - scale feature
#data:(HxWxK) ndarray
#returns:caffe_in:(KxHxW) ndarray for input to a Net
# [3,128,512]
transformed_image=self.transformer.preprocess('data',image)
##这里发现上面预处理代码不能用,会把图片像素变成0-1之间
transformed_image_1 = cv2.imread(imagename.strip())
transformed_image_1 = np.float32(transformed_image_1)
transformed_image_1 = cv2.resize(transformed_image_1,(512,128)) #[128,512,3]
transformed_image_1 = transformed_image_1.transpose((2,0,1))
# (3,128,512)
transformed_image = transformed_image_1
# cv2.imshow("11",transformed_image_1)
# cv2.waitKey()
self.net.blobs['data'].data[...]=transformed_image
# (1,34,128,512)
output=self.net.forward()
#(34,128,512)
output_prob=output[self.net.outputs[0]][0]
# print type(output_prob) ##np.ndarray
# print output_prob.shape ##(28,473,473)
merge_gray = None
feature_maps = None
#(128,512,34)
output_prob=output_prob.transpose((1,2,0))
#(128,512)
merge_gray=np.argmax(output_prob[:,:,...],axis=2)
# merge_gray = np.argmax(output_prob, axis=2)
merge_gray=merge_gray.astype(np.uint8)
tmp = merge_gray.astype(np.float32) * 25
cv2.imshow("tmp", tmp)
cv2.waitKey(0)
merge_color=np.zeros((self.size_h,self.size_w,3),dtype=np.uint8)
#show img
for i in range(nclasses):
print (str(i), ': ', color_segmentation[i])
merge_color[np.where(merge_gray == i)[0], np.where(merge_gray == i)[1]] = (color_segmentation[i*3], color_segmentation[i*3+1], color_segmentation[i*3+2])
return merge_color
def parse_args():
'''parse args'''
parser = argparse.ArgumentParser()
parser.add_argument('--gpu_id', type=int, default=0, help='gpu id')
parser.add_argument('--model_def',default=model_def)
parser.add_argument('--model_weights',default=model_weights)
parser.add_argument('--size_w',default=size_w)
parser.add_argument('--size_h',default=size_h)
parser.add_argument('--image_file',default=image_file)
return parser.parse_args()
if __name__=='__main__':
args=parse_args()
prediction=Caffe_segnet_Segmentation(args.gpu_id,args.model_def,args.model_weights,args.size_h,args.size_w)
if os.path.isdir(args.image_file):
for image_name in os.listdir(args.image_file):
image_name=os.path.join(args.image_file,image_name)
colormat=prediction.prdict(image_name)
img=cv2.imread(image_name)
cv2.imshow('orgimg',img)
cv2.imshow('colormat',colormat)
cv2.waitKey()
elif image_file.endswith('.txt'):
with open(image_file,'r') as f:
image_names=f.readlines()
for image_name in image_names:
image_name=image_name.split(' ')[0]
img=cv2.imread(image_name.strip())
colormat=prediction.prdict(image_name)
# cv2.imwrite("/data_1/Yang/project/caffe-segnet-2020/myfile/color.jpg",colormat)
cv2.imshow('orgimg',img)
cv2.imshow("colormat",colormat)
cv2.waitKey()
else:
colormat=prediction.prdict(args.image_file)
img=cv2.imread(args.image_file)
cv2.imshow('orgimg',img)
cv2.imshow('colormat',colormat)
cv2.waitKey()
这个脚本可以看到分割的效果图。下面来了解一下pycaffe的一些函数操作效果:
output=self.net.forward()
pool2 = self.net.blobs['pool2'].data[0]
这里,net.blobs['top name'],输入top name可以得到该层的输出,是ndarray类型的。如下图:

同时:
np.save('pool2.caffe.npy', pool2)
可以把ndarray类型保存在本地,后面可以和pytorch的结果做对比。
for layer_name, blob in self.net.blobs.iteritems():
print layer_name + '\t' + str(blob.data.shape)
可以打印出每层的feature map 名字和shape
data (1, 3, 128, 512)
conv1_1 (1, 64, 128, 512)
conv1_2 (1, 64, 128, 512)
pool1 (1, 64, 64, 256)
pool1_mask (1, 64, 64, 256)
conv2_1 (1, 64, 64, 256)
conv2_2 (1, 64, 64, 256)
pool2 (1, 64, 32, 128)
pool2_mask (1, 64, 32, 128)
conv3_1 (1, 64, 32, 128)
conv3_2 (1, 64, 32, 128)
conv3_3 (1, 64, 32, 128)
pool3 (1, 64, 16, 64)
pool3_mask (1, 64, 16, 64)
conv4_1 (1, 64, 16, 64)
conv4_2 (1, 64, 16, 64)
conv4_3 (1, 64, 16, 64)
pool4 (1, 64, 8, 32)
pool4_mask (1, 64, 8, 32)
pool4_D (1, 64, 16, 64)
conv4_3_D (1, 64, 16, 64)
conv4_2_D (1, 64, 16, 64)
conv4_1_D (1, 64, 16, 64)
pool3_D (1, 64, 32, 128)
conv3_3_D (1, 64, 32, 128)
conv3_2_D (1, 64, 32, 128)
conv3_1_D (1, 64, 32, 128)
pool2_D (1, 64, 64, 256)
conv2_2_D (1, 64, 64, 256)
conv2_1_D (1, 64, 64, 256)
pool1_D (1, 64, 128, 512)
conv1_2_D (1, 64, 128, 512)
权重与feature,得到的都是ndarray
# [1,64,128,512]
feature_a = self.net.blobs['conv1_1'].data
# [64,3,3,3]
weights_a = self.net.params['conv1_1'][0].data
# [64,]
weights_b = self.net.params['conv1_1'][1].data
恩!介绍完了基本的pycaffe的函数操作,然后我们开始提取caffe权重,该脚本是基于上面的跑推理的脚本,把每层的名字和形状保存txt,同时整一个字典,层名字是key,权重是val。最后把字典保存在本地.pkl文件。
tiqu.py
#-*- coding:utf-8 -*-
import sys,os
caffe_root='/data_1/Yang/project/caffe-segnet-2020'
sys.path.insert(0,os.path.join(caffe_root,'python'))
sys.path.insert(0,"/home/yhl/software_install/opencv3.2/lib")
import cv2
import caffe
import numpy as np
import matplotlib.pyplot as plt
import json
import argparse
import pickle as pkl
model_def='/data_1/Yang/project/caffe-segnet-2020/myfile/segnet.prototxt'
model_weights='/data_1/Yang/project/caffe-segnet-2020/myfile/segnet.caffemodel'
image_file='/data_1/Yang/project/caffe-segnet-2020/myfile/list.txt'
size_h=128
size_w=512
##order:R->G->B
color_segmentation =np.asarray(
[
0,0,0, ##nothing
255,236,139, ##0
255,235,205, ##1
255,228,225, ##2
255,225,255, ##3
255,193,37, ##4
255,174,185, ##5
255,140,0, ##6
255,131,250, ##7
255,105,180, ##8
169,169,169, ##9
162,205,90, ##A
154,192,205, ##B
154,50,205, ##C
144,238,144, ##D
142,142,56, ##E
142,56,142, ##F
139,90,43, ##G
139,62,47, ##H
135,206,235, ##J
131,139,139, ##K
69,139,0, ##L
65,105,225, ##M
64,224,208, ##N
0,238,118, ##P
148,0,211, ##Q
0,255,255, ##R
0,238,238, ##S
110,110,110, ##T
108,166,205, ##U
139,26,26, ##V
176,48,96, ##W
154,205,50, ##X
192,255,62, ##Y
238,48,167, ##Z
],dtype=np.uint8)
class Caffe_segnet_Segmentation:
def __init__(self,gpu_id,model_def,model_weights,size_h,size_w):
caffe.set_mode_gpu()
self.size_w=size_w
self.size_h=size_h
self.net=caffe.Net(model_def,model_weights,caffe.TEST)
self.net.blobs['data'].reshape(1,3,size_h,size_w)
# input preprocessing: 'data' is the name of the input blob == net.inputs[0]
# self.transformer=caffe.io.Transformer({'data':self.net.blobs['data'].data.shape})
self.transformer=caffe.io.Transformer({'data':self.net.blobs[self.net.inputs[0]].data.shape})
self.transformer.set_transpose('data',(2,0,1)) ##set the input channel order for e.g. RGB to BGR conversion
##input_blob=input*scale.While Python represents images in [0, 1], certain Caffe models
# like CaffeNet and AlexNet represent images in [0, 255] so the raw_scale
# of these models must be 255.
# self.transformer.set_raw_scale('data',255)
# Set the mean to subtract for centering the data.
# self.transformer.set_mean('data',np.array([123.68, 116.779, 103.939]))
# Set the scale of preprocessed inputs s.t. the blob = blob * scale.
# N.B. input_scale is done AFTER mean subtraction and other preprocessing
# while raw_scale is done BEFORE.
# self.transformer.set_input_scale('data',0.0078125)
#Set the input channel order for e.g. RGB to BGR conversion
# as needed for the reference ImageNet model.
# N.B. this assumes the channels are the first dimension AFTER transpose.
self.transformer.set_channel_swap('data',(2,1,0))
def prdict(self,imagename,nclasses=34):
image=caffe.io.load_image(imagename.strip()) #type:np.float32,size:(HxWx3) or (HxWx1)
##preprocess:
# - convert to single
#- resize to input dimensions (preserving number of channels)
#- transpose dimensions to K x H x W
# - reorder channels (for instance color to BGR)
# - scale raw input (e.g. from [0, 1] to [0, 255] for ImageNet models)
# - subtract mean
# - scale feature
#data:(HxWxK) ndarray
#returns:caffe_in:(KxHxW) ndarray for input to a Net
# [3,128,512]
transformed_image=self.transformer.preprocess('data',image)
transformed_image_1 = cv2.imread(imagename.strip())
transformed_image_1 = cv2.resize(transformed_image_1,(512,128)) #[128,512,3]
transformed_image_1 = transformed_image_1.transpose((2,0,1))
transformed_image = transformed_image_1
# cv2.imshow("11",transformed_image_1)
# cv2.waitKey()
self.net.blobs['data'].data[...]=transformed_image
for layer_name, blob in self.net.blobs.iteritems():
print layer_name + '\t' + str(blob.data.shape)
############################################################################
############################################################################
name_weights = {}
# 保存每层的参数信息
keys = open('keys.txt', 'w')
keys.write('generated by SfSNet-Caffe/convert_to_pkl.py\n\n')
# 遍历每一网络层
for param_name in self.net.params.keys():
name_weights[param_name] = {}
# 得到此层的参数
layer_params = self.net.params[param_name]
if len(layer_params) == 1:
# 如果参数只有一个,则说明是反卷积层,
# SfSNet整个模型里就只有反卷积层只有一组weight参数
weight = layer_params[0].data
name_weights[param_name]['weight'] = weight
print('%s:\n\t%s (weight)' % (param_name, weight.shape))
keys.write('%s:\n\t%s (weight)\n' % (param_name, weight.shape))
elif len(layer_params) == 2:
# 如果参数有两个,则说明是卷积层或者全连接层。
# 卷积层或者全连接层都有两组参数:weight和bias
# 权重参数
weight = layer_params[0].data
name_weights[param_name]['weight'] = weight
# 偏置参数
bias = layer_params[1].data
name_weights[param_name]['bias'] = bias
print('%s:\n\t%s (weight)' % (param_name, weight.shape))
print('\t%s (bias)' % str(bias.shape))
keys.write('%s:\n\t%s (weight)\n' % (param_name, weight.shape))
keys.write('\t%s (bias)\n' % str(bias.shape))
elif len(layer_params) == 3:
# 如果有三个,则说明是BatchNorm层。
# BN层共有三个参数,分别是:running_mean、running_var和一个缩放参数。
running_mean = layer_params[0].data # running_mean
name_weights[param_name]['running_mean'] = running_mean / layer_params[2].data
running_var = layer_params[1].data # running_var
name_weights[param_name]['running_var'] = running_var / layer_params[2].data
print('%s:\n\t%s (running_var)' % (param_name, running_var.shape),)
print('\t%s (running_mean)' % str(running_mean.shape))
keys.write('%s:\n\t%s (running_var)\n' % (param_name, running_var.shape))
keys.write('\t%s (running_mean)\n' % str(running_mean.shape))
else:
# 如果报错,大家要检查自己模型哈
raise RuntimeError("还有参数个数超过3个的层,别漏了兄dei!!!\n")
keys.close()
# 保存name_weights
with open('weights.pkl', 'wb') as f:
pkl.dump(name_weights, f, protocol=2)
############################################################################
############################################################################
# print(type(output))
# while True:
# pass
##returns:{blob_name:blob_ndarray} dict
output=self.net.forward()
# print(type(output))
# while True:
# pass
# print self.net.outputs[0] ##conv9_interp
output_prob=output[self.net.outputs[0]][0]
# print type(output_prob) ##np.ndarray
# print output_prob.shape ##(28,473,473)
merge_gray = None
feature_maps = None
output_prob=output_prob.transpose((1,2,0))
aaaaa = output_prob[:, :, ...]
merge_gray=np.argmax(output_prob[:,:,...],axis=2)
# merge_gray = np.argmax(output_prob, axis=2)
merge_gray=merge_gray.astype(np.uint8)
tmp = merge_gray.astype(np.float32) * 25
cv2.imshow("tmp", tmp)
cv2.waitKey(0)
merge_color=np.zeros((self.size_h,self.size_w,3),dtype=np.uint8)
#show img
for i in range(nclasses):
print (str(i), ': ', color_segmentation[i])
merge_color[np.where(merge_gray == i)[0], np.where(merge_gray == i)[1]] = (color_segmentation[i*3], color_segmentation[i*3+1], color_segmentation[i*3+2])
return merge_color
def parse_args():
'''parse args'''
parser = argparse.ArgumentParser()
parser.add_argument('--gpu_id', type=int, default=0, help='gpu id')
parser.add_argument('--model_def',default=model_def)
parser.add_argument('--model_weights',default=model_weights)
parser.add_argument('--size_w',default=size_w)
parser.add_argument('--size_h',default=size_h)
parser.add_argument('--image_file',default=image_file)
return parser.parse_args()
if __name__=='__main__':
args=parse_args()
prediction=Caffe_segnet_Segmentation(args.gpu_id,args.model_def,args.model_weights,args.size_h,args.size_w)
if os.path.isdir(args.image_file):
for image_name in os.listdir(args.image_file):
image_name=os.path.join(args.image_file,image_name)
colormat=prediction.prdict(image_name)
img=cv2.imread(image_name)
cv2.imshow('orgimg',img)
cv2.imshow('colormat',colormat)
cv2.waitKey()
elif image_file.endswith('.txt'):
with open(image_file,'r') as f:
image_names=f.readlines()
for image_name in image_names:
image_name=image_name.split(' ')[0]
img=cv2.imread(image_name)
colormat=prediction.prdict(image_name)
cv2.imwrite("/data_1/Yang/project/caffe-segnet-2020/myfile/color.jpg",colormat)
# cv2.imshow('orgimg',img)
# cv2.imshow("colormat",colormat)
# cv2.waitKey()
else:
colormat=prediction.prdict(args.image_file)
img=cv2.imread(args.image_file)
cv2.imshow('orgimg',img)
cv2.imshow('colormat',colormat)
cv2.waitKey()
如图,会得到keys.txt,weights.pkl两个文件
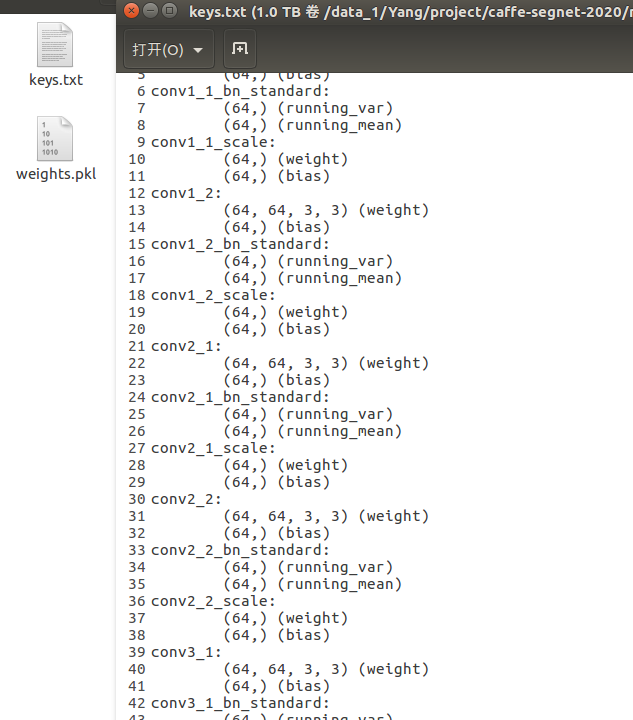
至此,caffe层面的转换就完成了,后面需要把提取的权重导入pytorch。
pytorch加载caffe权重
首先需要仿照caffe的prototxt搭同样的网络。比如第一层是卷积和bn和relu。就先搭个只有卷积的
# coding=utf-8
from __future__ import absolute_import, division, print_function
import torch
import torchvision
import pickle as pkl
from torch import nn
import torch.nn.functional as F
import pickle as pkl
import cv2
import numpy as np
class segnet_my(nn.Module): # SfSNet = PS-Net in SfSNet_deploy.prototxt
def __init__(self):
super(segnet_my, self).__init__()
self.conv1_1 = nn.Conv2d(3, 64, 3, 1, 1)
self.bn1_1 = nn.BatchNorm2d(64)
def forward(self,inputs):
#x = self.conv1_1(inputs)
x = F.relu(self.bn1_1(self.conv1_1(inputs)))
return x
if __name__ == '__main__':
net = segnet_my()
# net.eval()
index = 0
print("*" * 50)
for name, param in list(net.named_parameters()):
print(str(index) + ':', name, param.size())
index += 1
print("*" * 50)
for k, v in net.state_dict().items():
print(k)
print(v.shape)
# print(k,v)
print("@" * 50)
上面两种都是打印出pytorch权重名和形状,只是下面这种可以更全,上面不会打印bn层的running_mean,running_var
0: conv1_1.weight (64, 3, 3, 3)
1: conv1_1.bias (64,)
2: bn1_1.weight (64,)
3: bn1_1.bias (64,)
########################################################################################
conv1_1.weight
(64, 3, 3, 3)
conv1_1.bias
(64,)
bn1_1.weight
(64,)
bn1_1.bias
(64,)
bn1_1.running_mean
(64,)
bn1_1.running_var
(64,)
bn1_1.num_batches_tracked
()
这个只是打印出pytorch权重形状,要和caffe的比较看是不是一样的。
下面是从pkl加载权重,并且检查权重是否一致
if __name__ == '__main__':
net = segnet_my()
# net.eval()
index = 0
print("*" * 50)
for name, param in list(net.named_parameters()):
print(str(index) + ':', name, param.size())
index += 1
print("*" * 50)
for k, v in net.state_dict().items():
print(k)
print(v.shape)
# print(k,v)
print("@" * 50)
from torch import from_numpy
with open('/data_1/Yang/project/caffe-segnet-2020/myfile/weights.pkl', 'rb') as wp:
name_weights = pkl.load(wp)
state_dict = {}
state_dict['conv1_1.weight'] = from_numpy(name_weights['conv1_1']['weight'])
state_dict['conv1_1.bias'] = from_numpy(name_weights['conv1_1']['bias'])
state_dict['bn1_1.running_var'] = from_numpy(name_weights['conv1_1_bn_standard']['running_var'])
state_dict['bn1_1.running_mean'] = from_numpy(name_weights['conv1_1_bn_standard']['running_mean'])
state_dict['bn1_1.weight'] = from_numpy(name_weights['conv1_1_scale']['weight'])
state_dict['bn1_1.bias'] = from_numpy(name_weights['conv1_1_scale']['bias'])
##########检测pkl读取的权重和加载到pytorch net的权重是否一致#####################################################################################
# for k, v in net.state_dict().items():
# print(k)
# print(v.shape)
# print(k,v)
#
# # params = dict(net.named_parameters())
# # print("*"*100)
# print(params['bn1.running_var'].detach().numpy())
#
# f = open('/data_1/Yang/project/caffe-segnet-2020/myfile/weights.pkl', 'rb')
# name_weights_1 = pkl.load(f)
# f.close()
# print("#" * 100)
# print(name_weights_1['conv1_1_bn_standard']['running_var'])
#
# print("*" * 100)
###############################################################################################
最关键的是caffe和pytorch经过一层的feature map的结果是否一致。首先是确保送进网络的图片预处理一样,下面给出完整代码
# coding=utf-8
from __future__ import absolute_import, division, print_function
import torch
import torchvision
import pickle as pkl
from torch import nn
import torch.nn.functional as F
import pickle as pkl
import cv2
import numpy as np
class segnet_my(nn.Module): # SfSNet = PS-Net in SfSNet_deploy.prototxt
def __init__(self):
super(segnet_my, self).__init__()
#################################################################################
self.conv1_1 = nn.Conv2d(3, 64, 3, 1, 1)
self.bn1_1 = nn.BatchNorm2d(64) ##self.bn1 = nn.BatchNorm2d(64,affine=False)
self.conv1_2 = nn.Conv2d(64, 64, 3, 1, 1)
self.bn1_2 = nn.BatchNorm2d(64)
self.pool1 = nn.MaxPool2d(kernel_size=2,stride=2)
#################################################################################
#################################################################################
self.conv2_1 = nn.Conv2d(64, 64, 3, 1, 1)
self.bn2_1 = nn.BatchNorm2d(64) ##self.bn1 = nn.BatchNorm2d(64,affine=False)
self.conv2_2 = nn.Conv2d(64, 64, 3, 1, 1)
self.bn2_2 = nn.BatchNorm2d(64)
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
#################################################################################
#################################################################################
self.conv3_1 = nn.Conv2d(64, 64, 3, 1, 1)
self.bn3_1 = nn.BatchNorm2d(64) ##self.bn1 = nn.BatchNorm2d(64,affine=False)
self.conv3_2 = nn.Conv2d(64, 64, 3, 1, 1)
self.bn3_2 = nn.BatchNorm2d(64)
self.conv3_3 = nn.Conv2d(64, 64, 3, 1, 1)
self.bn3_3 = nn.BatchNorm2d(64)
self.pool3 = nn.MaxPool2d(kernel_size=2, stride=2)
#################################################################################
#################################################################################
self.conv4_1 = nn.Conv2d(64, 64, 3, 1, 1)
self.bn4_1 = nn.BatchNorm2d(64) ##self.bn1 = nn.BatchNorm2d(64,affine=False)
self.conv4_2 = nn.Conv2d(64, 64, 3, 1, 1)
self.bn4_2 = nn.BatchNorm2d(64)
self.conv4_3 = nn.Conv2d(64, 64, 3, 1, 1)
self.bn4_3 = nn.BatchNorm2d(64)
self.pool4 = nn.MaxPool2d(kernel_size=2, stride=2)
#################################################################################
self.upsample4 = nn.Upsample(scale_factor=2, mode='nearest')
#################################################################################
self.conv4_3_D = nn.Conv2d(64, 64, 3, 1, 1)
self.bn4_3_D = nn.BatchNorm2d(64) ##self.bn1 = nn.BatchNorm2d(64,affine=False)
self.conv4_2_D = nn.Conv2d(64, 64, 3, 1, 1)
self.bn4_2_D = nn.BatchNorm2d(64)
self.conv4_1_D = nn.Conv2d(64, 64, 3, 1, 1)
self.bn4_1_D = nn.BatchNorm2d(64)
#################################################################################
##@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
#################################################################################
self.conv3_3_D = nn.Conv2d(64, 64, 3, 1, 1)
self.bn3_3_D = nn.BatchNorm2d(64) ##self.bn1 = nn.BatchNorm2d(64,affine=False)
self.conv3_2_D = nn.Conv2d(64, 64, 3, 1, 1)
self.bn3_2_D = nn.BatchNorm2d(64)
self.conv3_1_D = nn.Conv2d(64, 64, 3, 1, 1)
self.bn3_1_D = nn.BatchNorm2d(64)
#################################################################################
##1111111
#################################################################################
self.conv2_2_D = nn.Conv2d(64, 64, 3, 1, 1)
self.bn2_2_D = nn.BatchNorm2d(64) ##self.bn1 = nn.BatchNorm2d(64,affine=False)
self.conv2_1_D = nn.Conv2d(64, 64, 3, 1, 1)
self.bn2_1_D = nn.BatchNorm2d(64)
#################################################################################
##2222
#################################################################################
self.conv1_2_D = nn.Conv2d(64, 64, 3, 1, 1)
self.bn1_2_D = nn.BatchNorm2d(64) ##self.bn1 = nn.BatchNorm2d(64,affine=False)
#################################################################################
##last
#################################################################################
self.conv1_1_D = nn.Conv2d(64, 34, 3, 1, 1)
#################################################################################
def forward(self,inputs):
# x = self.conv1_1(inputs)
# x = self.bn1(x)
x = F.relu(self.bn1_1(self.conv1_1(inputs)))
x = F.relu(self.bn1_2(self.conv1_2(x)))
pool1, pool1_mask = F.max_pool2d(x, kernel_size=2, stride=2, return_indices=True)
x = F.relu(self.bn2_1(self.conv2_1(pool1)))
x = F.relu(self.bn2_2(self.conv2_2(x)))
pool2, pool2_mask = F.max_pool2d(x, kernel_size=2, stride=2, return_indices=True)
x = F.relu(self.bn3_1(self.conv3_1(pool2)))
x = F.relu(self.bn3_2(self.conv3_2(x)))
x = F.relu(self.bn3_3(self.conv3_3(x)))
pool3, pool3_mask = F.max_pool2d(x, kernel_size=2, stride=2, return_indices=True)
x = F.relu(self.bn4_1(self.conv4_1(pool3)))
x = F.relu(self.bn4_2(self.conv4_2(x)))
x = F.relu(self.bn4_3(self.conv4_3(x)))
pool4, pool4_mask = F.max_pool2d(x, kernel_size=2, stride=2, return_indices=True)
pool4_D = F.max_unpool2d(pool4, pool4_mask, kernel_size=2, stride=2)
x = F.relu(self.bn4_3_D(self.conv4_3_D(pool4_D)))
x = F.relu(self.bn4_2_D(self.conv4_2_D(x)))
x = F.relu(self.bn4_1_D(self.conv4_1_D(x)))
pool3_D = F.max_unpool2d(x, pool3_mask, kernel_size=2, stride=2)
x = F.relu(self.bn3_3_D(self.conv3_3_D(pool3_D)))
x = F.relu(self.bn3_2_D(self.conv3_2_D(x)))
x = F.relu(self.bn3_1_D(self.conv3_1_D(x)))
pool2_D = F.max_unpool2d(x, pool2_mask, kernel_size=2, stride=2)
x = F.relu(self.bn2_2_D(self.conv2_2_D(pool2_D)))
x = F.relu(self.bn2_1_D(self.conv2_1_D(x)))
pool1_D = F.max_unpool2d(x, pool1_mask, kernel_size=2, stride=2)
x = F.relu(self.bn1_2_D(self.conv1_2_D(pool1_D)))
x = self.conv1_1_D(x)
return x
if __name__ == '__main__':
net = segnet_my()
# net.eval()
index = 0
print("*" * 50)
for name, param in list(net.named_parameters()):
print(str(index) + ':', name, param.size())
index += 1
print("*" * 50)
for k, v in net.state_dict().items():
print(k)
print(v.shape)
# print(k,v)
print("@" * 50)
from torch import from_numpy
with open('/data_1/Yang/project/caffe-segnet-2020/myfile/weights.pkl', 'rb') as wp:
name_weights = pkl.load(wp)
state_dict = {}
state_dict['conv1_1.weight'] = from_numpy(name_weights['conv1_1']['weight'])
state_dict['conv1_1.bias'] = from_numpy(name_weights['conv1_1']['bias'])
state_dict['bn1_1.running_var'] = from_numpy(name_weights['conv1_1_bn_standard']['running_var'])
state_dict['bn1_1.running_mean'] = from_numpy(name_weights['conv1_1_bn_standard']['running_mean'])
state_dict['bn1_1.weight'] = from_numpy(name_weights['conv1_1_scale']['weight'])
state_dict['bn1_1.bias'] = from_numpy(name_weights['conv1_1_scale']['bias'])
state_dict['conv1_2.weight'] = from_numpy(name_weights['conv1_2']['weight'])
state_dict['conv1_2.bias'] = from_numpy(name_weights['conv1_2']['bias'])
state_dict['bn1_2.running_var'] = from_numpy(name_weights['conv1_2_bn_standard']['running_var'])
state_dict['bn1_2.running_mean'] = from_numpy(name_weights['conv1_2_bn_standard']['running_mean'])
state_dict['bn1_2.weight'] = from_numpy(name_weights['conv1_2_scale']['weight'])
state_dict['bn1_2.bias'] = from_numpy(name_weights['conv1_2_scale']['bias'])
state_dict['conv2_1.weight'] = from_numpy(name_weights['conv2_1']['weight'])
state_dict['conv2_1.bias'] = from_numpy(name_weights['conv2_1']['bias'])
state_dict['bn2_1.running_var'] = from_numpy(name_weights['conv2_1_bn_standard']['running_var'])
state_dict['bn2_1.running_mean'] = from_numpy(name_weights['conv2_1_bn_standard']['running_mean'])
state_dict['bn2_1.weight'] = from_numpy(name_weights['conv2_1_scale']['weight'])
state_dict['bn2_1.bias'] = from_numpy(name_weights['conv2_1_scale']['bias'])
state_dict['conv2_2.weight'] = from_numpy(name_weights['conv2_2']['weight'])
state_dict['conv2_2.bias'] = from_numpy(name_weights['conv2_2']['bias'])
state_dict['bn2_2.running_var'] = from_numpy(name_weights['conv2_2_bn_standard']['running_var'])
state_dict['bn2_2.running_mean'] = from_numpy(name_weights['conv2_2_bn_standard']['running_mean'])
state_dict['bn2_2.weight'] = from_numpy(name_weights['conv2_2_scale']['weight'])
state_dict['bn2_2.bias'] = from_numpy(name_weights['conv2_2_scale']['bias'])
state_dict['conv3_1.weight'] = from_numpy(name_weights['conv3_1']['weight'])
state_dict['conv3_1.bias'] = from_numpy(name_weights['conv3_1']['bias'])
state_dict['bn3_1.running_var'] = from_numpy(name_weights['conv3_1_bn_standard']['running_var'])
state_dict['bn3_1.running_mean'] = from_numpy(name_weights['conv3_1_bn_standard']['running_mean'])
state_dict['bn3_1.weight'] = from_numpy(name_weights['conv3_1_scale']['weight'])
state_dict['bn3_1.bias'] = from_numpy(name_weights['conv3_1_scale']['bias'])
#
state_dict['conv3_2.weight'] = from_numpy(name_weights['conv3_2']['weight'])
state_dict['conv3_2.bias'] = from_numpy(name_weights['conv3_2']['bias'])
state_dict['bn3_2.running_var'] = from_numpy(name_weights['conv3_2_bn_standard']['running_var'])
state_dict['bn3_2.running_mean'] = from_numpy(name_weights['conv3_2_bn_standard']['running_mean'])
state_dict['bn3_2.weight'] = from_numpy(name_weights['conv3_2_scale']['weight'])
state_dict['bn3_2.bias'] = from_numpy(name_weights['conv3_2_scale']['bias'])
#
state_dict['conv3_3.weight'] = from_numpy(name_weights['conv3_3']['weight'])
state_dict['conv3_3.bias'] = from_numpy(name_weights['conv3_3']['bias'])
state_dict['bn3_3.running_var'] = from_numpy(name_weights['conv3_3_bn_standard']['running_var'])
state_dict['bn3_3.running_mean'] = from_numpy(name_weights['conv3_3_bn_standard']['running_mean'])
state_dict['bn3_3.weight'] = from_numpy(name_weights['conv3_3_scale']['weight'])
state_dict['bn3_3.bias'] = from_numpy(name_weights['conv3_3_scale']['bias'])
###layer 4############################################################
state_dict['conv4_1.weight'] = from_numpy(name_weights['conv4_1']['weight'])
state_dict['conv4_1.bias'] = from_numpy(name_weights['conv4_1']['bias'])
state_dict['bn4_1.running_var'] = from_numpy(name_weights['conv4_1_bn_standard']['running_var'])
state_dict['bn4_1.running_mean'] = from_numpy(name_weights['conv4_1_bn_standard']['running_mean'])
state_dict['bn4_1.weight'] = from_numpy(name_weights['conv4_1_scale']['weight'])
state_dict['bn4_1.bias'] = from_numpy(name_weights['conv4_1_scale']['bias'])
#
state_dict['conv4_2.weight'] = from_numpy(name_weights['conv4_2']['weight'])
state_dict['conv4_2.bias'] = from_numpy(name_weights['conv4_2']['bias'])
state_dict['bn4_2.running_var'] = from_numpy(name_weights['conv4_2_bn_standard']['running_var'])
state_dict['bn4_2.running_mean'] = from_numpy(name_weights['conv4_2_bn_standard']['running_mean'])
state_dict['bn4_2.weight'] = from_numpy(name_weights['conv4_2_scale']['weight'])
state_dict['bn4_2.bias'] = from_numpy(name_weights['conv4_2_scale']['bias'])
#
state_dict['conv4_3.weight'] = from_numpy(name_weights['conv4_3']['weight'])
state_dict['conv4_3.bias'] = from_numpy(name_weights['conv4_3']['bias'])
state_dict['bn4_3.running_var'] = from_numpy(name_weights['conv4_3_bn_standard']['running_var'])
state_dict['bn4_3.running_mean'] = from_numpy(name_weights['conv4_3_bn_standard']['running_mean'])
state_dict['bn4_3.weight'] = from_numpy(name_weights['conv4_3_scale']['weight'])
state_dict['bn4_3.bias'] = from_numpy(name_weights['conv4_3_scale']['bias'])
###layer 4 D ############################################################
state_dict['conv4_3_D.weight'] = from_numpy(name_weights['conv4_3_D']['weight'])
state_dict['conv4_3_D.bias'] = from_numpy(name_weights['conv4_3_D']['bias'])
state_dict['bn4_3_D.running_var'] = from_numpy(name_weights['conv4_3_D_bn_standard']['running_var'])
state_dict['bn4_3_D.running_mean'] = from_numpy(name_weights['conv4_3_D_bn_standard']['running_mean'])
state_dict['bn4_3_D.weight'] = from_numpy(name_weights['conv4_3_D_scale']['weight'])
state_dict['bn4_3_D.bias'] = from_numpy(name_weights['conv4_3_D_scale']['bias'])
#
state_dict['conv4_2_D.weight'] = from_numpy(name_weights['conv4_2_D']['weight'])
state_dict['conv4_2_D.bias'] = from_numpy(name_weights['conv4_2_D']['bias'])
state_dict['bn4_2_D.running_var'] = from_numpy(name_weights['conv4_2_D_bn_standard']['running_var'])
state_dict['bn4_2_D.running_mean'] = from_numpy(name_weights['conv4_2_D_bn_standard']['running_mean'])
state_dict['bn4_2_D.weight'] = from_numpy(name_weights['conv4_2_D_scale']['weight'])
state_dict['bn4_2_D.bias'] = from_numpy(name_weights['conv4_2_D_scale']['bias'])
#
state_dict['conv4_1_D.weight'] = from_numpy(name_weights['conv4_1_D']['weight'])
state_dict['conv4_1_D.bias'] = from_numpy(name_weights['conv4_1_D']['bias'])
state_dict['bn4_1_D.running_var'] = from_numpy(name_weights['conv4_1_D_bn_standard']['running_var'])
state_dict['bn4_1_D.running_mean'] = from_numpy(name_weights['conv4_1_D_bn_standard']['running_mean'])
state_dict['bn4_1_D.weight'] = from_numpy(name_weights['conv4_1_D_scale']['weight'])
state_dict['bn4_1_D.bias'] = from_numpy(name_weights['conv4_1_D_scale']['bias'])
###layer 3 D ############################################################
state_dict['conv3_3_D.weight'] = from_numpy(name_weights['conv3_3_D']['weight'])
state_dict['conv3_3_D.bias'] = from_numpy(name_weights['conv3_3_D']['bias'])
state_dict['bn3_3_D.running_var'] = from_numpy(name_weights['conv3_3_D_bn_standard']['running_var'])
state_dict['bn3_3_D.running_mean'] = from_numpy(name_weights['conv3_3_D_bn_standard']['running_mean'])
state_dict['bn3_3_D.weight'] = from_numpy(name_weights['conv3_3_D_scale']['weight'])
state_dict['bn3_3_D.bias'] = from_numpy(name_weights['conv3_3_D_scale']['bias'])
#
state_dict['conv3_2_D.weight'] = from_numpy(name_weights['conv3_2_D']['weight'])
state_dict['conv3_2_D.bias'] = from_numpy(name_weights['conv3_2_D']['bias'])
state_dict['bn3_2_D.running_var'] = from_numpy(name_weights['conv3_2_D_bn_standard']['running_var'])
state_dict['bn3_2_D.running_mean'] = from_numpy(name_weights['conv3_2_D_bn_standard']['running_mean'])
state_dict['bn3_2_D.weight'] = from_numpy(name_weights['conv3_2_D_scale']['weight'])
state_dict['bn3_2_D.bias'] = from_numpy(name_weights['conv3_2_D_scale']['bias'])
#
state_dict['conv3_1_D.weight'] = from_numpy(name_weights['conv3_1_D']['weight'])
state_dict['conv3_1_D.bias'] = from_numpy(name_weights['conv3_1_D']['bias'])
state_dict['bn3_1_D.running_var'] = from_numpy(name_weights['conv3_1_D_bn_standard']['running_var'])
state_dict['bn3_1_D.running_mean'] = from_numpy(name_weights['conv3_1_D_bn_standard']['running_mean'])
state_dict['bn3_1_D.weight'] = from_numpy(name_weights['conv3_1_D_scale']['weight'])
state_dict['bn3_1_D.bias'] = from_numpy(name_weights['conv3_1_D_scale']['bias'])
###layer 2 D ############################################################
state_dict['conv2_2_D.weight'] = from_numpy(name_weights['conv2_2_D']['weight'])
state_dict['conv2_2_D.bias'] = from_numpy(name_weights['conv2_2_D']['bias'])
state_dict['bn2_2_D.running_var'] = from_numpy(name_weights['conv2_2_D_bn_standard']['running_var'])
state_dict['bn2_2_D.running_mean'] = from_numpy(name_weights['conv2_2_D_bn_standard']['running_mean'])
state_dict['bn2_2_D.weight'] = from_numpy(name_weights['conv2_2_D_scale']['weight'])
state_dict['bn2_2_D.bias'] = from_numpy(name_weights['conv2_2_D_scale']['bias'])
#
state_dict['conv2_1_D.weight'] = from_numpy(name_weights['conv2_1_D']['weight'])
state_dict['conv2_1_D.bias'] = from_numpy(name_weights['conv2_1_D']['bias'])
state_dict['bn2_1_D.running_var'] = from_numpy(name_weights['conv2_1_D_bn_standard']['running_var'])
state_dict['bn2_1_D.running_mean'] = from_numpy(name_weights['conv2_1_D_bn_standard']['running_mean'])
state_dict['bn2_1_D.weight'] = from_numpy(name_weights['conv2_1_D_scale']['weight'])
state_dict['bn2_1_D.bias'] = from_numpy(name_weights['conv2_1_D_scale']['bias'])
####layer 1_2
state_dict['conv1_2_D.weight'] = from_numpy(name_weights['conv1_2_D']['weight'])
state_dict['conv1_2_D.bias'] = from_numpy(name_weights['conv1_2_D']['bias'])
state_dict['bn1_2_D.running_var'] = from_numpy(name_weights['conv1_2_D_bn_standard']['running_var'])
state_dict['bn1_2_D.running_mean'] = from_numpy(name_weights['conv1_2_D_bn_standard']['running_mean'])
state_dict['bn1_2_D.weight'] = from_numpy(name_weights['conv1_2_D_scale']['weight'])
state_dict['bn1_2_D.bias'] = from_numpy(name_weights['conv1_2_D_scale']['bias'])
##last
state_dict['conv1_1_D.weight'] = from_numpy(name_weights['conv1_1_D']['weight'])
state_dict['conv1_1_D.bias'] = from_numpy(name_weights['conv1_1_D']['bias'])
net.load_state_dict(state_dict)
net.cuda()
net.eval()
torch.save(net.state_dict(), './model.pth')
###############################################################################################
# for k, v in net.state_dict().items():
# print(k)
# print(v.shape)
# print(k,v)
#
# # params = dict(net.named_parameters())
# # print("*"*100)
# print(params['bn1.running_var'].detach().numpy())
#
# f = open('/data_1/Yang/project/caffe-segnet-2020/myfile/weights.pkl', 'rb')
# name_weights_1 = pkl.load(f)
# f.close()
# print("#" * 100)
# print(name_weights_1['conv1_1_bn_standard']['running_var'])
#
# print("*" * 100)
###############################################################################################
#
#
#
#
imagename = "/data_1/Yang/project/2020/example.jpeg"
transformed_image_1 = cv2.imread(imagename.strip())
transformed_image_1 = np.array(transformed_image_1, dtype=np.float32)
transformed_image_1 = cv2.resize(transformed_image_1, (512, 128)) # [128,512,3]
transformed_image_1 = transformed_image_1.transpose((2, 0, 1))
transformed_image = from_numpy(transformed_image_1)
transformed_image = torch.unsqueeze(transformed_image,0).cuda()
# np.save('img.pytorch.npy', transformed_image[0].detach().numpy())
# xx = torch.randn(1, 3, 320, 320)
output = net(transformed_image)
aa5 = 0
# import sys
# traced_script_module = torch.jit.trace(net, transformed_image)
# traced_script_module.save("/data_1/Yang/project/caffe-segnet-2020/myfile/pytorch/00000.pt")
# print("sys.exit(1)")
# sys.exit(1)
output_prob = output[0].cpu().detach().numpy()
# np.save('output_prob.pytorch.npy', output_prob)
merge_gray = None
feature_maps = None
output_prob = output_prob.transpose((1, 2, 0))
aaaaa = output_prob[:, :, ...]
merge_gray = np.argmax(output_prob[:, :, ...], axis=2)
# merge_gray = np.argmax(output_prob, axis=2)
merge_gray = merge_gray.astype(np.uint8)
tmp = merge_gray.astype(np.float32) * 25
img_src = cv2.imread(imagename)
cv2.imshow("img_src", img_src)
cv2.imshow("tmp", tmp)
cv2.waitKey(0)
# np.save('bn1-relu.pytorch.npy', bb[0].detach().numpy())
如上,output = net(transformed_image)就是输出的feature map可以和caffe的feature map做对比。
写了一个same.py脚本,就是加载npy文件,做对比。下面的脚本只要看aa就可以了,我转完的segnet的最后一层的feature map两者之间的差是10的-7次方。基本没有问题。
# coding=utf-8
import numpy as np
def same(arr1, arr2):
# type: (np.ndarray, np.ndarray) -> bool
# 判断shape是否相同
assert arr1.shape == arr2.shape
# 对应元素相减求绝对值
diff = np.abs(arr1 - arr2)
aa = np.average(diff)
# 判断是否有任意一个两元素之差大于阈值1e-5
return aa,(diff > 1e-5).any()
def compare(layer, params, name_weights):
# type: (str, dict, dict) -> tuple[bool, bool]
# 判断权重
w = same(params[layer+'.weight'].detach().numpy(), name_weights[layer]['weight'])
# 判断偏置
b = same(params[layer+'.bias'].detach().numpy(), name_weights[layer]['bias'])
return w, b
if __name__ == '__main__':
caffe_result = np.load('/data_1/Yang/project/caffe-segnet-2020/myfile/conv1_1_D.caffe.npy')
torch_result = np.load('/data_1/Yang/project/caffe-segnet-2020/myfile/pytorch/output_prob.pytorch.npy')
# same函数之前有提到
print(same(caffe_result, torch_result))
还有一个疑惑是,caffe的网络层有一些是in place操作,比如一般是卷积、bn、relu他们的top都是叫一个名字,导致下面的运算会覆盖上面的结果。比如:
layer {
bottom: "data"
top: "conv1_1" ########################################################
name: "conv1_1"
type: "Convolution"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
weight_filler {
type: "msra"
}
bias_filler {
type: "constant"
}
num_output: 64
pad: 1
kernel_size: 3
}
}
layer {
bottom: "conv1_1"
top: "conv1_1" ########################################################
name: "conv1_1_bn_standard"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
#moving_average_fraction: 0.9
}
}
layer {
bottom: "conv1_1"
top: "conv1_1" ########################################################
name: "conv1_1_scale"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "conv1_1"
top: "conv1_1" ########################################################
name: "relu1_1"
type: "ReLU"
}
因为只能通过top看feature的,forward之后只保留了最后一个的feature的结果,即只保留了relu层之后的结果。那么,如果要看conv1_1_bn_standard这一层的输出怎么办?
答案是修改 top: "conv1_1"名字,确保下面的bottom和上面的top一致就可以!不影响权重加载,因为加载只看name加载权重。
至于,可能会遇到caffe有的算子,pytorch没有。比如这里的上采样,弄了很久,然后xiao hu提醒我去找segnet的pytorch实现,果真找到了上采样的函数:
https://github.com/delta-onera/segnet_pytorch
x5p, id5 = F.max_pool2d(x53,kernel_size=2, stride=2,return_indices=True)
x5d = F.max_unpool2d(x5p, id5, kernel_size=2, stride=2)
至于还会有不一样的算子的话,那就需要再研究研究怎么弄了。。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号