

经典算法 —— 布隆过滤器
AngryPanda
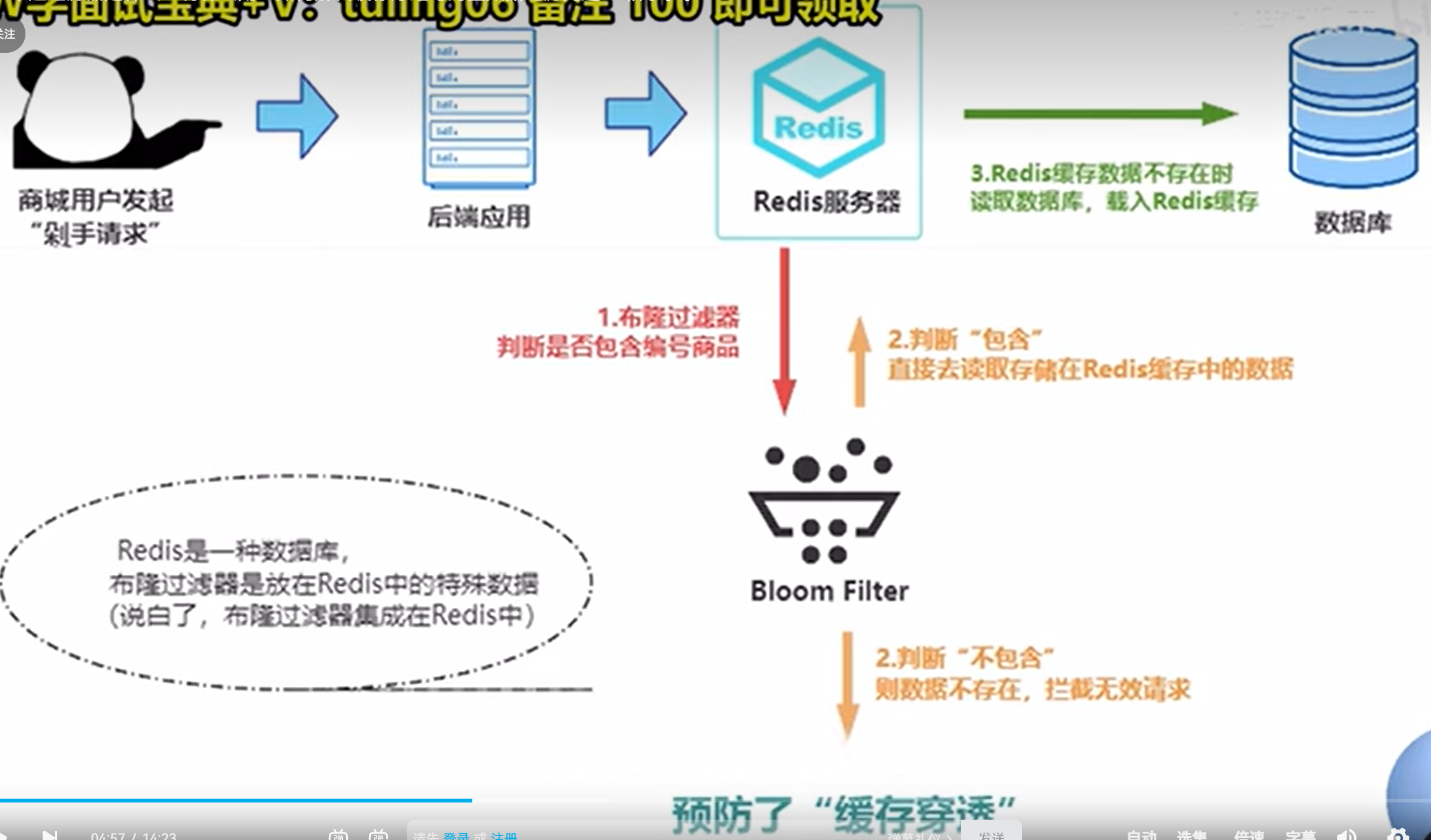
上图来自:
https://www.bilibili.com/video/BV1xF4m1j7US/

来自:
https://blog.csdn.net/qyf__123/article/details/85232935
以下中 m 表示bitmap的总容量,n 表示布隆过滤器中目标需要存储的项个数。
误判概率的相关证明和计算


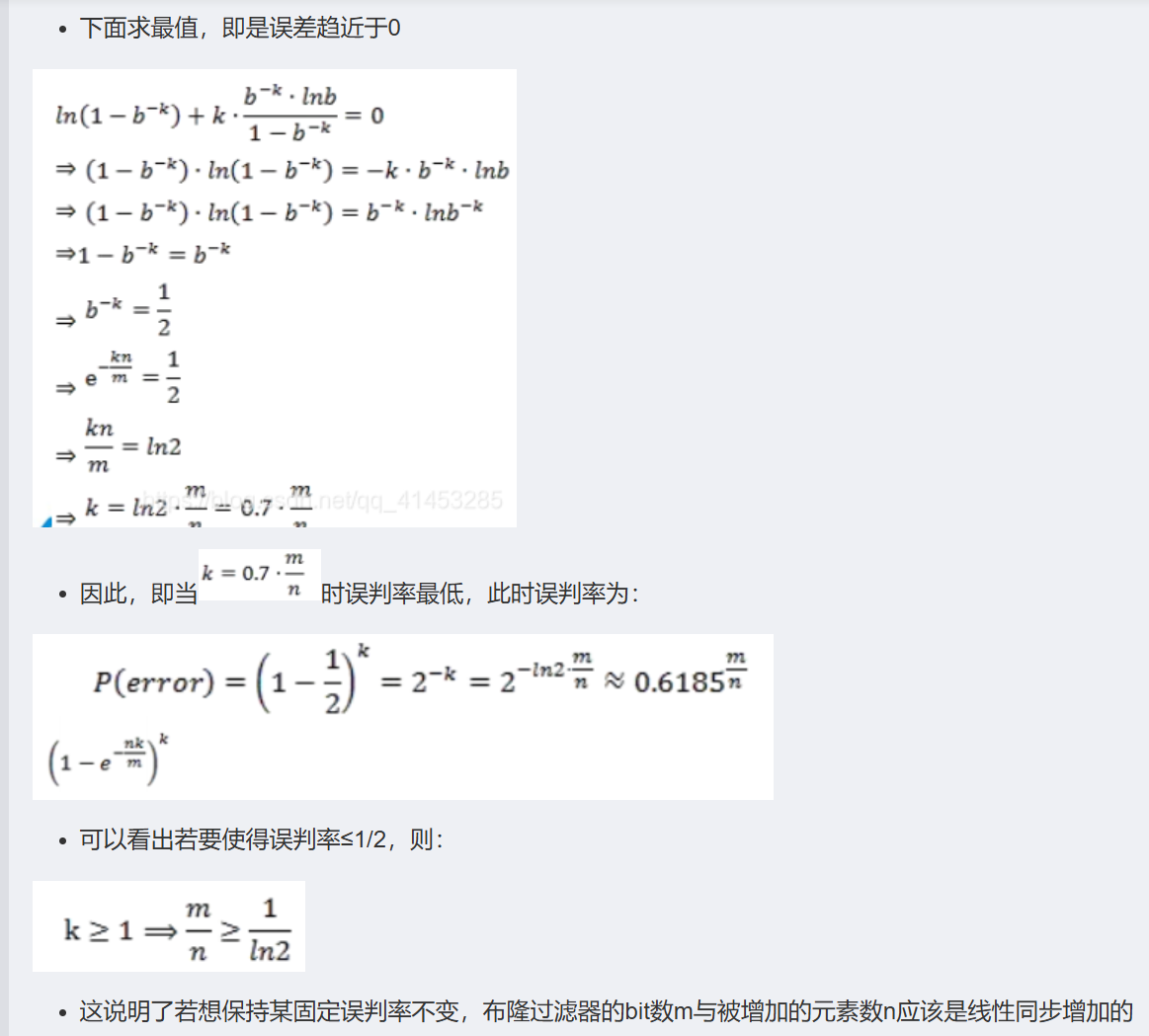
来自:
https://dongshao.blog.csdn.net/article/details/106416470
重点:
k 值的选择与m、n值相关,也就是说k值的选择不能过大也不能过小,否则都不利于最小误判率。

补充:
- 垃圾邮箱系统的布隆过滤器
布隆过滤器里面存储的是垃圾邮箱的地址的hash对应的位置,也就是说一个邮箱地址通过布隆过滤器判断不存在在该过滤器中则该地址一定不是邮箱地址,进入到下一层的LRU缓存系统中寻找;如果邮箱地址存在于布隆过滤器中,则该邮箱地址可能为垃圾邮箱,因为存在对一定的误判率的接受,因此将该地址判为垃圾邮箱地址。
为了避免一些邮箱地址被误判为垃圾邮箱地址,因此需要设置一个白名单列表,具体为如果一个地址存在于过滤器中并不能判断其一定为垃圾邮箱地址,接着需要判断该邮箱地址是否存在于白名单地址中,如果存在则该地址判断为非垃圾邮箱地址,否则依旧判断为垃圾邮箱地址。
该白名单地址依旧可以使用hash结构进行存储,比如使用LRU缓存存储,并且将总的白名单地址保存在数据库中。
- 商品系统的布隆过滤器
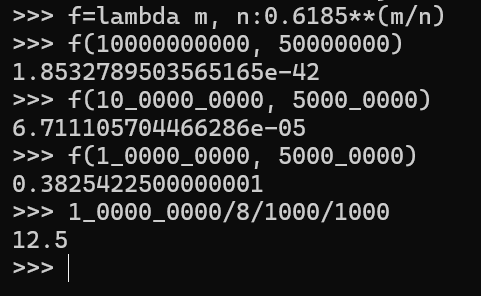
JD商城中前几年公开的商品个数为4000多万个,我们假设假设现在的商品个数为5000万个,如果布隆过滤器的总容量为100亿,那么误判率基本为0;如果总容量为10亿个,那么误判率为0.0067%;如果总容量为1亿个,那么误判率为38% 。
如果总容量为1亿个,那么存储大小约为12.5G;
如果总容量为10亿个,那么存储大小约为125G;
如果总容量为10亿个,那么存储大小约为1250G;
可以看到不论是总容量设置为10亿个还是100亿个,其容量也是可以接受的,毕竟现在的一个高内存的服务器可以有1500GB的大小,因此即使使用100亿容量的布隆过滤器也是可以的。
如果查询的商品ID在布隆过滤器中则继续在LRU中查找(如果没有则访问数据库),如果布隆过滤器中不存在则直接返回不存在。

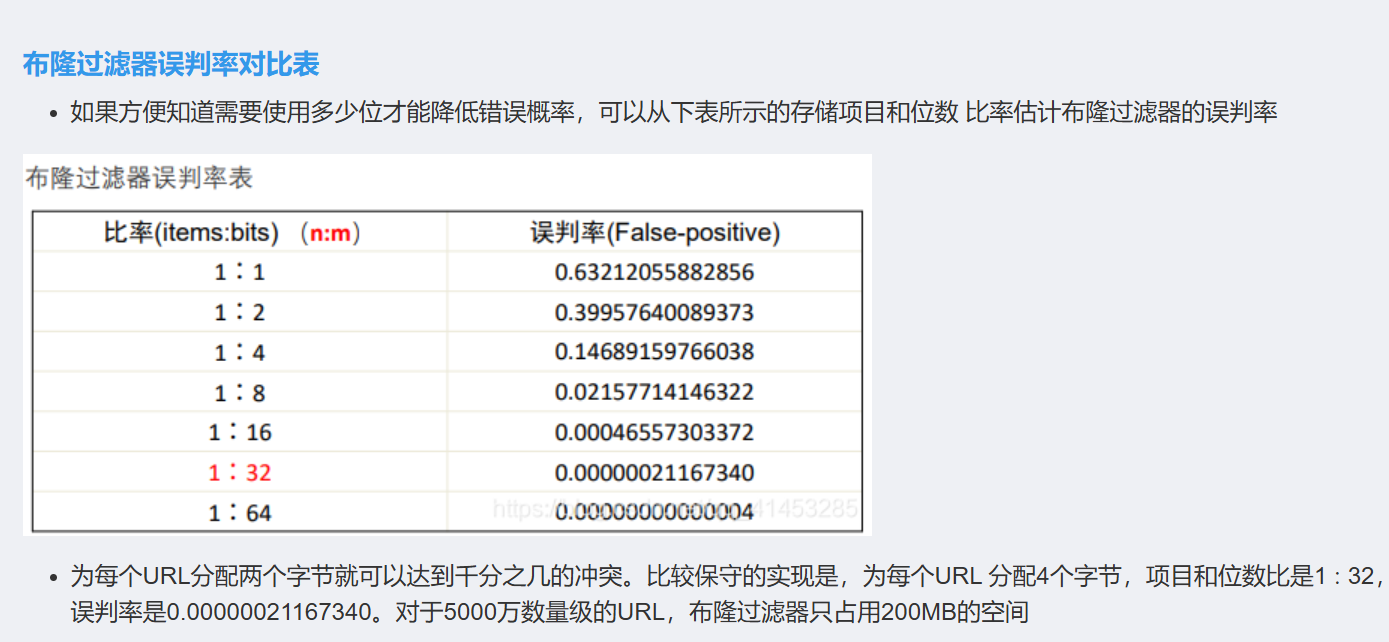

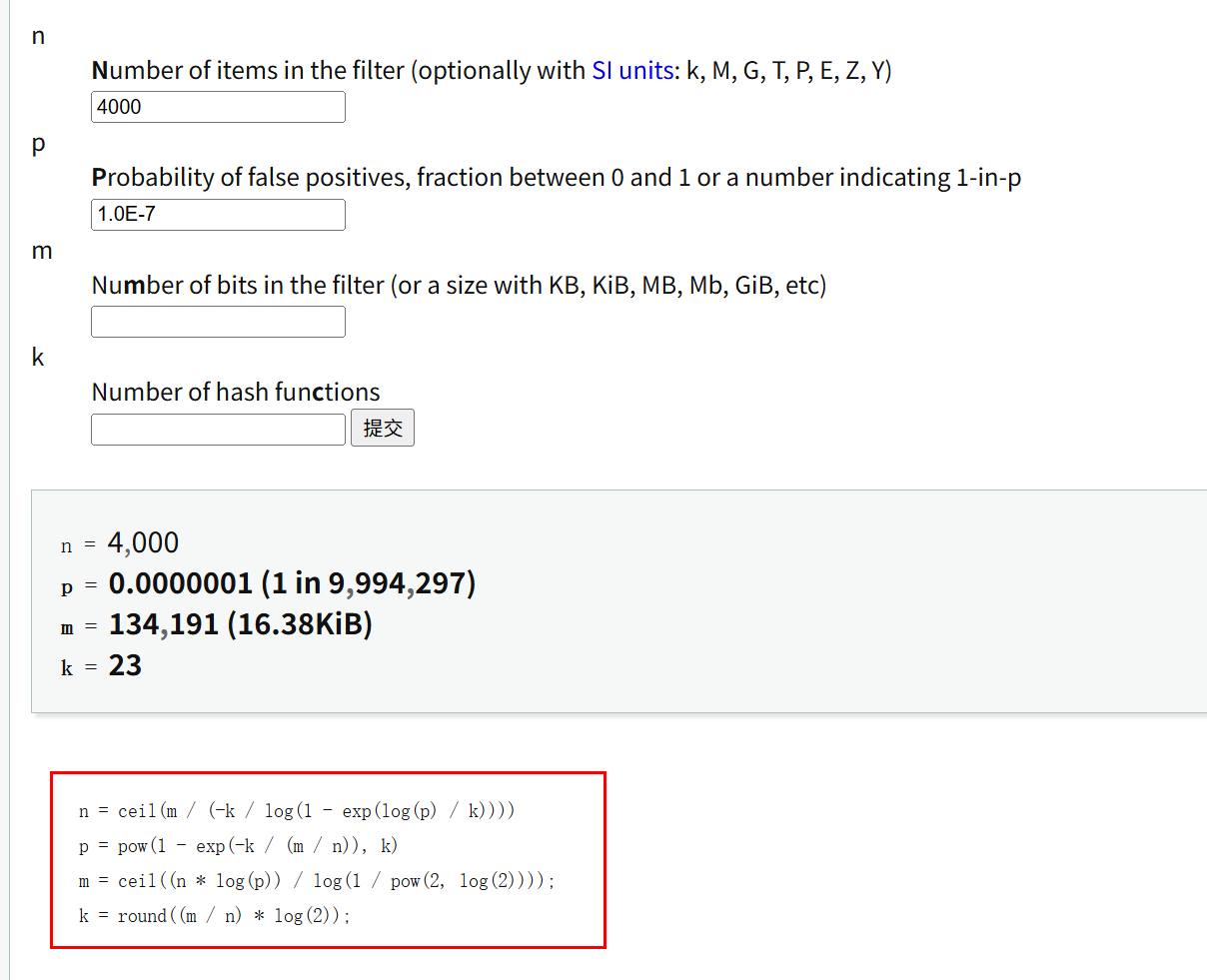
m、n 向下取整,k 四舍五入取整;
m、n ceil取整,k round取整;
地址:
相关:
https://blog.csdn.net/hlzgood/article/details/109847282
posted on 2025-12-14 12:34 Angry_Panda 阅读(7) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号