

python _—— 使用hash函数实现一种类似字典的简易hash存储结构
使用hash函数实现一种类似字典的简易hash存储结构:
import random
import time
s_list1 = list(range(100_0000))
random.shuffle(s_list1) # 随机打乱列表
v_list = random.sample(range(100_0000), 100) # 随机采样100个元素
# hash 表
sub_list = [[] for _ in range(100)] # [[, ], [, ], ...]
for v in s_list1:
sub_list[hash(v)%100].append(v)
s_dict = dict()
for v in s_list1:
s_dict[v] = v
a_time = time.time()
for v in v_list:
s_list1.index(v)
b_time = time.time()
for v in v_list:
for v2 in s_list1:
if v2 == v:
break
c_time = time.time()
for v in v_list:
for v2 in sub_list[hash(v)%100]:
if v2 == v:
break
d_time = time.time()
for v in v_list:
x = s_dict[v] + 0
# s_dict[v]
# pass
e_time = time.time()
# print(b_time - a_time, c_time - b_time, d_time - c_time)
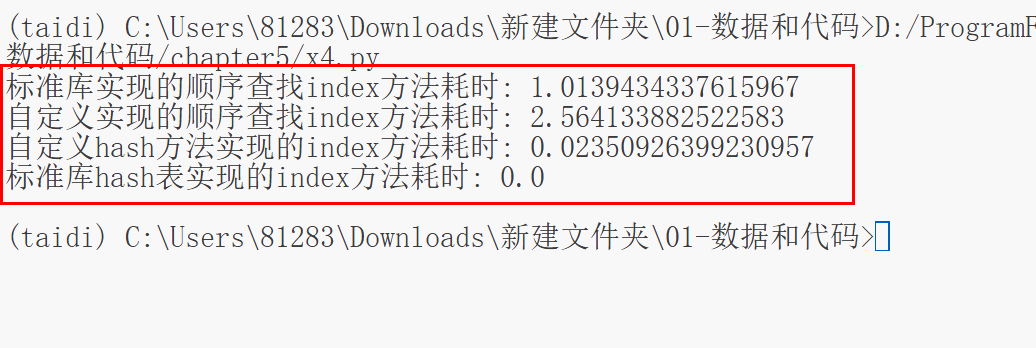
print("标准库实现的顺序查找index方法耗时:", b_time - a_time)
print("自定义实现的顺序查找index方法耗时:", c_time - b_time)
print("自定义hash方法实现的index方法耗时:", d_time - c_time)
print("标准库hash表实现的index方法耗时:", e_time - d_time)
本博客是博主个人学习时的一些记录,不保证是为原创,个别文章加入了转载的源地址,还有个别文章是汇总网上多份资料所成,在这之中也必有疏漏未加标注处,如有侵权请与博主联系。
如果未特殊标注则为原创,遵循 CC 4.0 BY-SA 版权协议。
posted on 2025-12-10 17:00 Angry_Panda 阅读(1) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号