
python多进程通信中的Queue、SimpleQueue、Pipe
python多进程通信中的Queue、SimpleQueue、Pipe
Queue
多进程中的Queue的底层是使用Pipe实现的,因此使用Queue进行多进程通信的时候,其传输对象要求是可以序列化的,否则会进行PicklingError报错。
为了提供put方法的超时控制,Queue并不是直接将对象写入到管道中,而是先写入到一个本地的缓存中,再将其从缓存中放入到pipe中,内部有个专门的feeder线程负责这项工作。
由于feeder线程的存在,Queue还提供了以下特殊方法来处理进程退出时缓存中仍然存在数据的问题。
close():
表明不再存放数据到queue中。一旦所有缓冲的数据刷新到管道,后台线程(feeder线程)将退出。
join_thread()::
一般在close方法之后使用,它会阻止指定的当前进程退出,直到后台(feeder线程)线程退出,确保所有缓冲区的数据已经刷新到管道(Pipe)中。
(等待后台进程刷新数据,只有调用过 close 方法以后才可以调用该方法。
调用该方法后,进程会一直阻塞,直到所有数据都被刷入队列中的管道,队列的后台线程退出。)
cancel_join_thread():
需要立即退出当前进程,而无需等待排队的数据刷新到底层的管道的时候可以使用该方法,表明无需阻止当前进程直到后台线程的退出。
(默认的,进程在向队列插入数据后退出,都会自动等待后台线程刷新 pipe。
在此之前,通过 cancel_join_thread 可以改变这一默认的行为,即使进程主动调用 join_thread 方法,也会立即返回,作为代价,数据可能并没有被真的写入管道中从而导致数据的丢失。)
SimpleQueue 队列
实现了加锁机制的Pipe,内部去掉了buffer(不使用缓存),但没有提供put和get的超时处理,两个动作都是阻塞的。
PS:
根据上面的介绍可以知道Queue并不难保证Put进来的数据可以被Get方法实时的读取到,其中存在一定可能的时间延迟,其原因是存在缓存和feeder后台线程的原因。
由于SimepleQueue不使用缓存,因此其实时性会比Queue要高,即不提供put和get的超时处理,但是其依然不能说就是可以保证put和get的实时性的,只能说实时性更高,毕竟实时性是一个绝对意义上的概念。
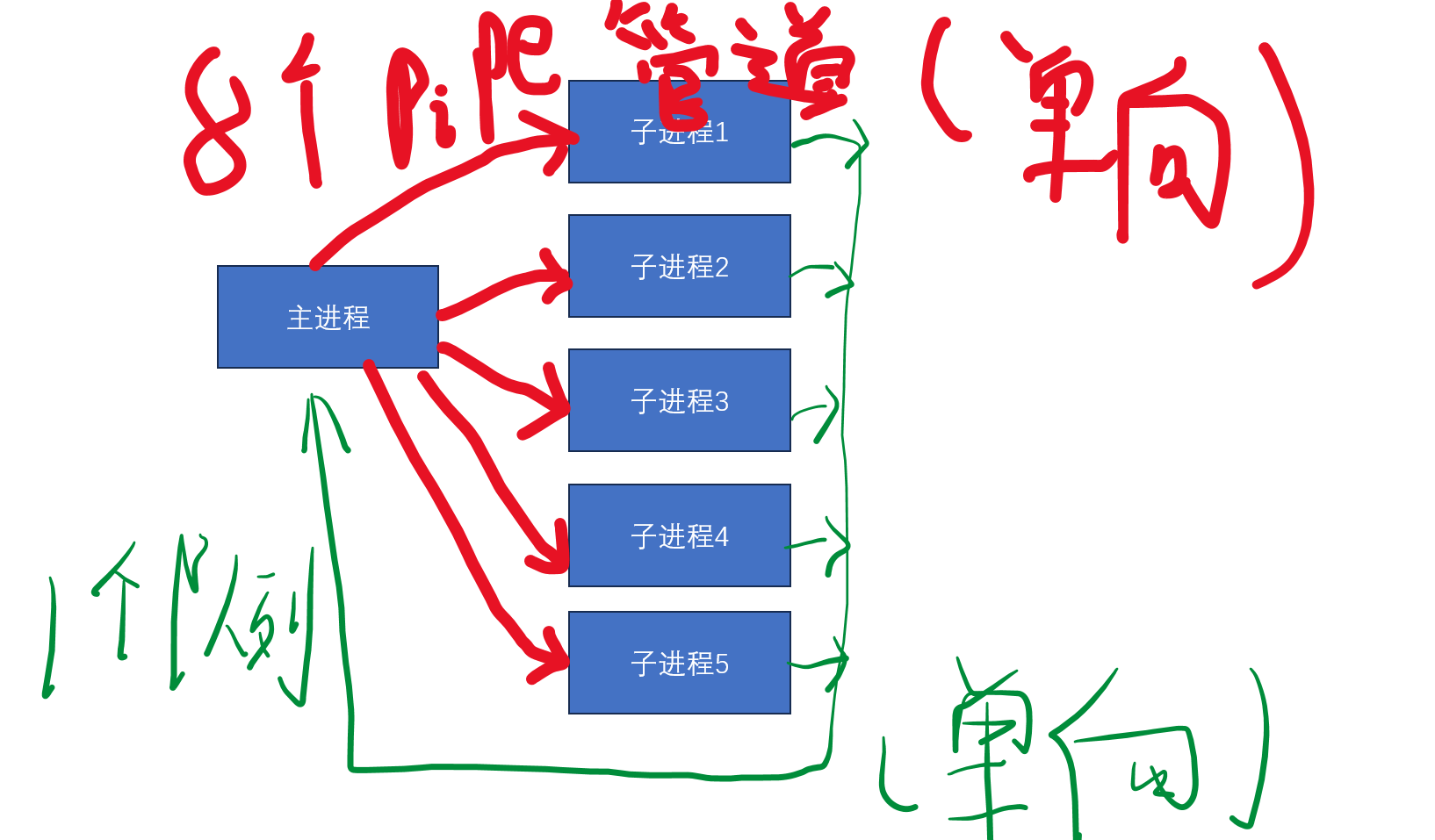
Pipe
Pipe默认为双向管道。
由于Pipe是Queue及SimpleQueue的底层实现,因此其通信效率最高。但是,Pipe不支持进程安全,因此多进程同时对同一观点的一端进行读操作或写操作的时候可能会导致数据丢失或损坏。
因此在进程通信的时候,如果是超过2个以上的进程,可以使用Queue,因为Queue是底层使用Pipe的加锁并加缓存的一种实现,但对于两个进程之间的通信而言Pipe性能更快。
参考:
https://cloud.tencent.com/developer/article/2031441
补充:
posted on 2025-11-16 13:59 Angry_Panda 阅读(19) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号