
pytorch多进程运行模型,报错:报错 RuntimeError: Cowardly refusing to serialize non-leaf tensor which requires_grad, since autograd does not support crossing process boundaries.
具体报错信息:
报错 RuntimeError: Cowardly refusing to serialize non-leaf tensor which requires_grad, since autograd does not support crossing process boundaries. If you just want to transfer the data, call detach() on the tensor before serializing (e.g., putting it on the queue).
[W412 09:35:34.731165326 CudaIPCTypes.cpp:16] Producer process has been terminated before all shared CUDA tensors released. See Note [Sharing CUDA tensors]
外网上关于这个报错信息的说法也是各种各样,国内的呢,也是基本见不到这方面的资料,于是就自己研究,发现了解决方法。
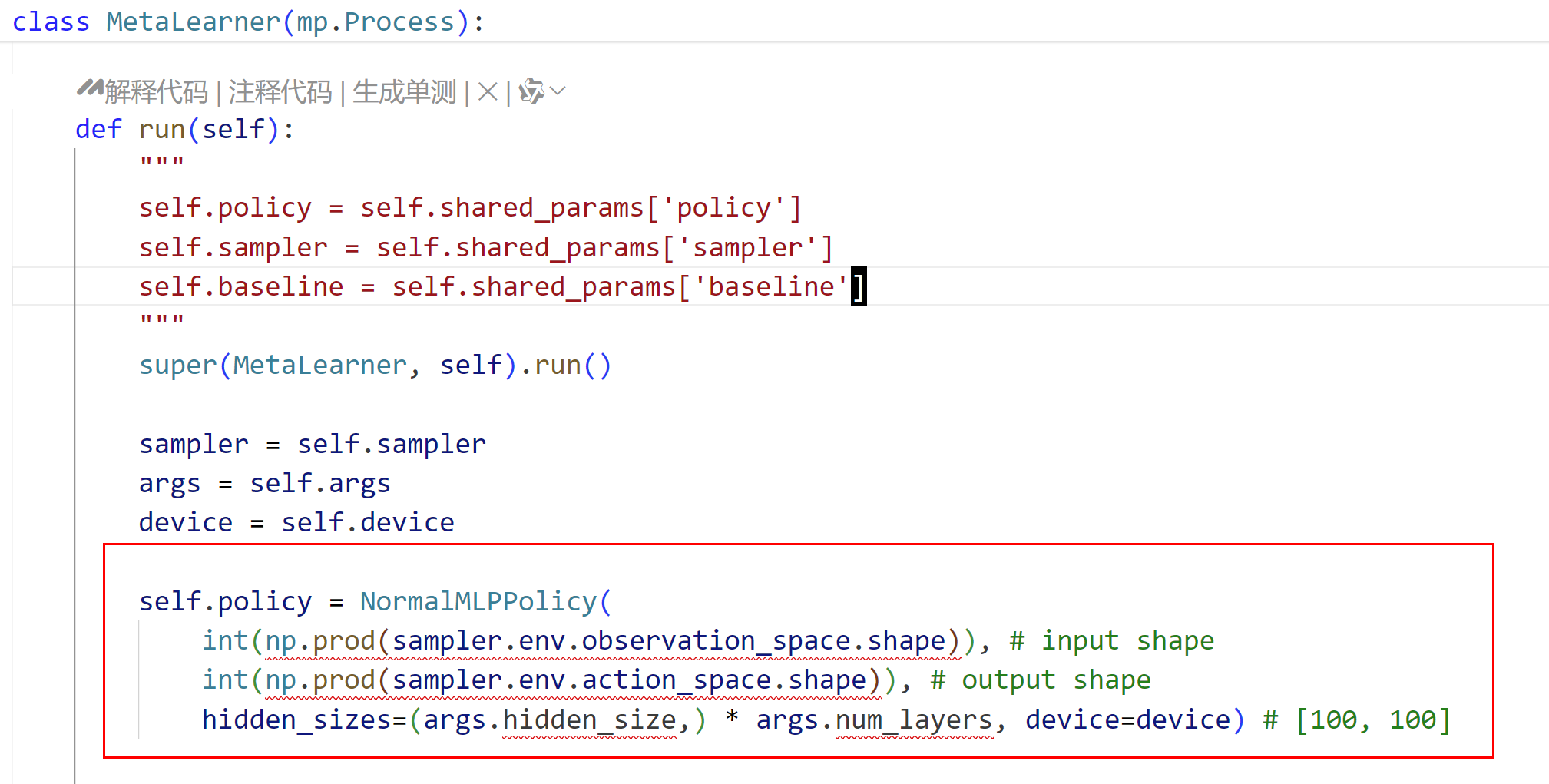
这个问题的出现其实就是在python的多进程中开启pytorch模型,如果是在子进程的__init__函数中创建模型,那么python就会把这个模型进行序列化,然后就会报错,解决方法就是把子进程中的神经网络初始化拿出来放到非__init__函数中就可以了。
具体:

改成:
本博客是博主个人学习时的一些记录,不保证是为原创,个别文章加入了转载的源地址,还有个别文章是汇总网上多份资料所成,在这之中也必有疏漏未加标注处,如有侵权请与博主联系。
如果未特殊标注则为原创,遵循 CC 4.0 BY-SA 版权协议。
posted on 2025-04-12 10:30 Angry_Panda 阅读(184) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号