
强化学习在美团“猜你喜欢”的实践
相关:
https://tech.meituan.com/2018/11/15/reinforcement-learning-in-mt-recommend-system.html
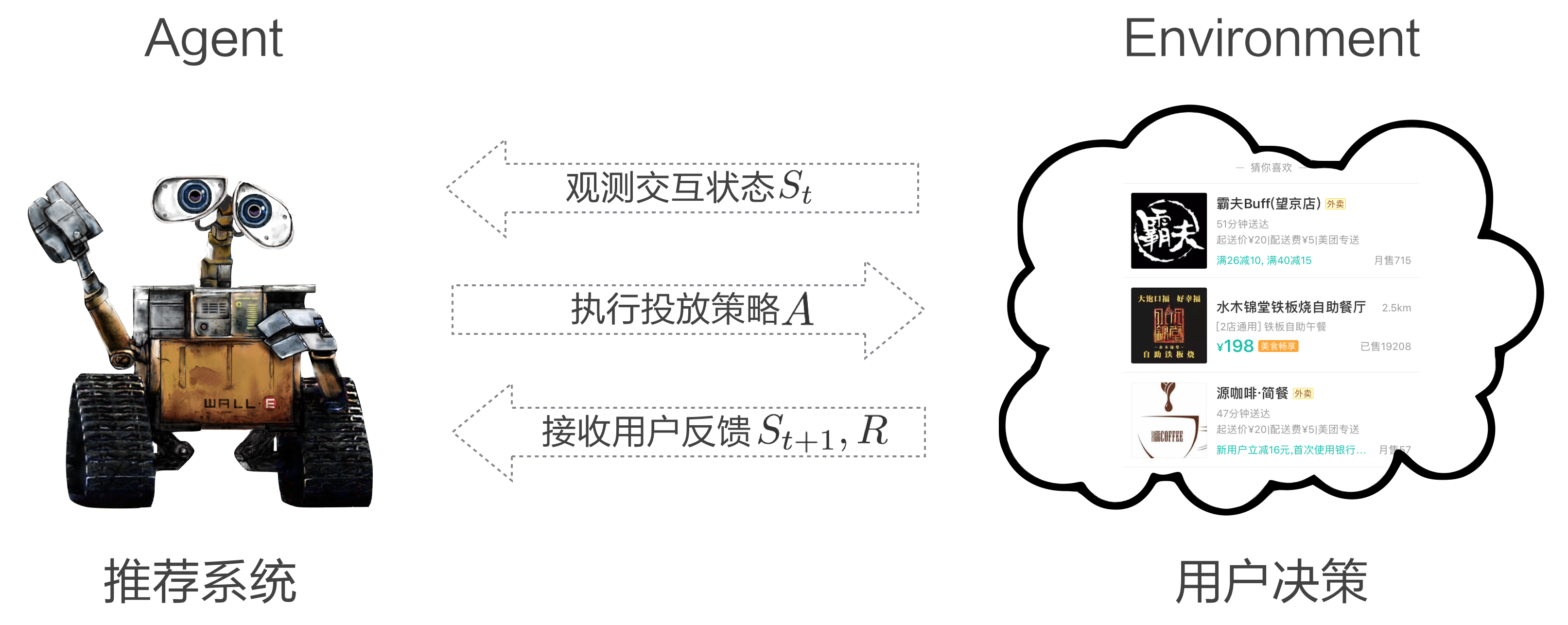
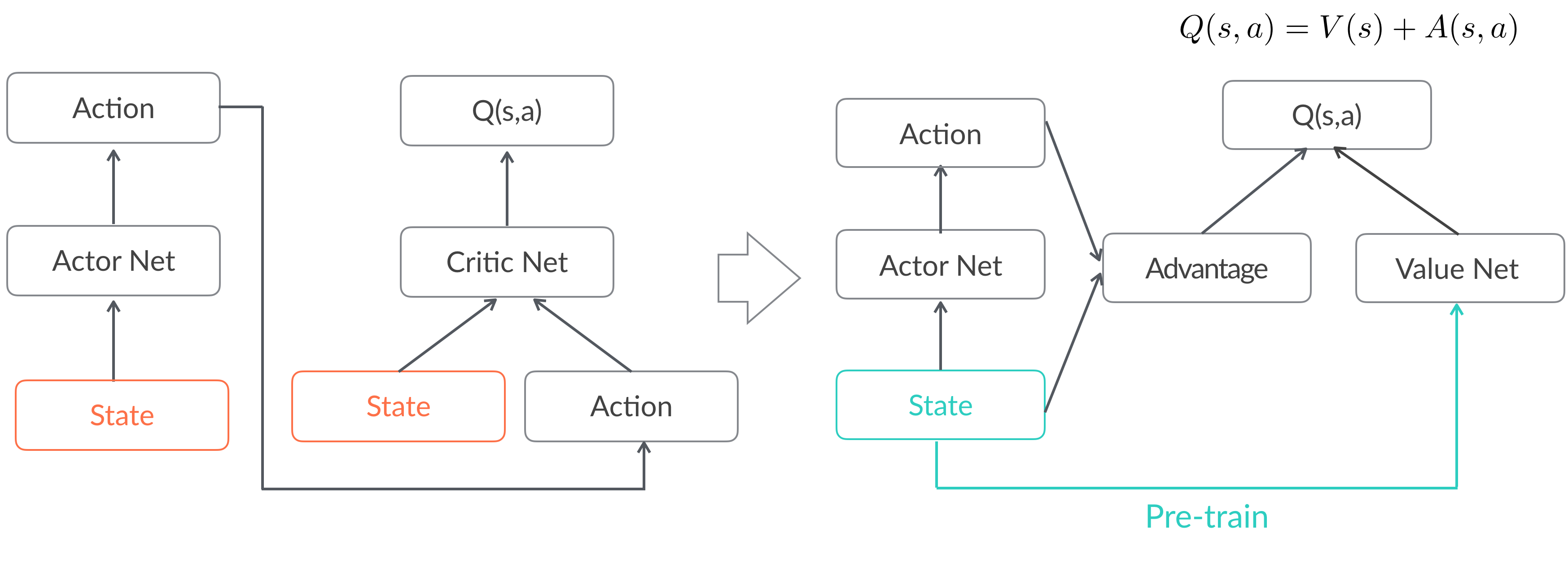
图10 使用advantage函数并做state权值共享
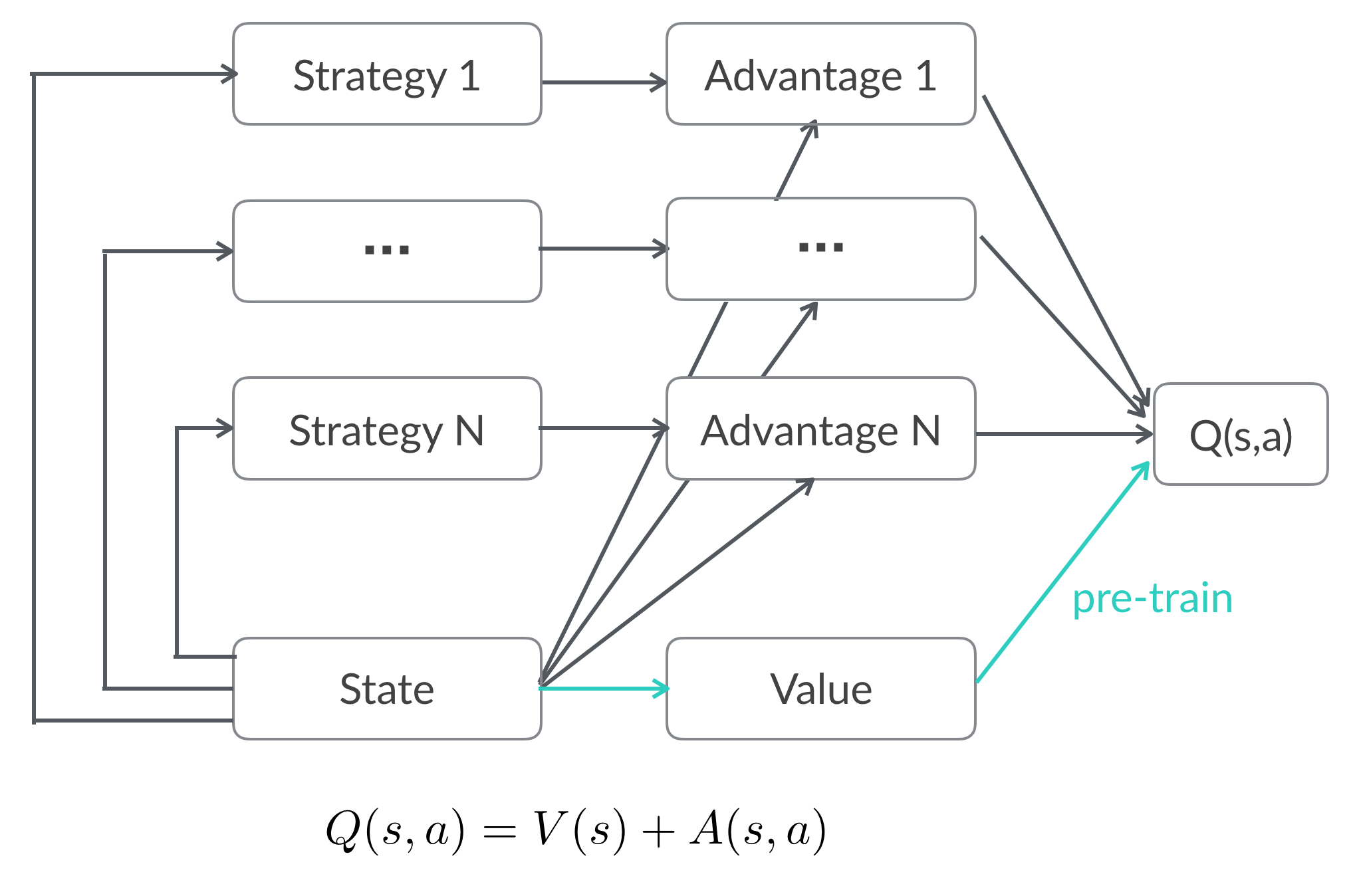
图11 支持多组线上实验DDPG模型
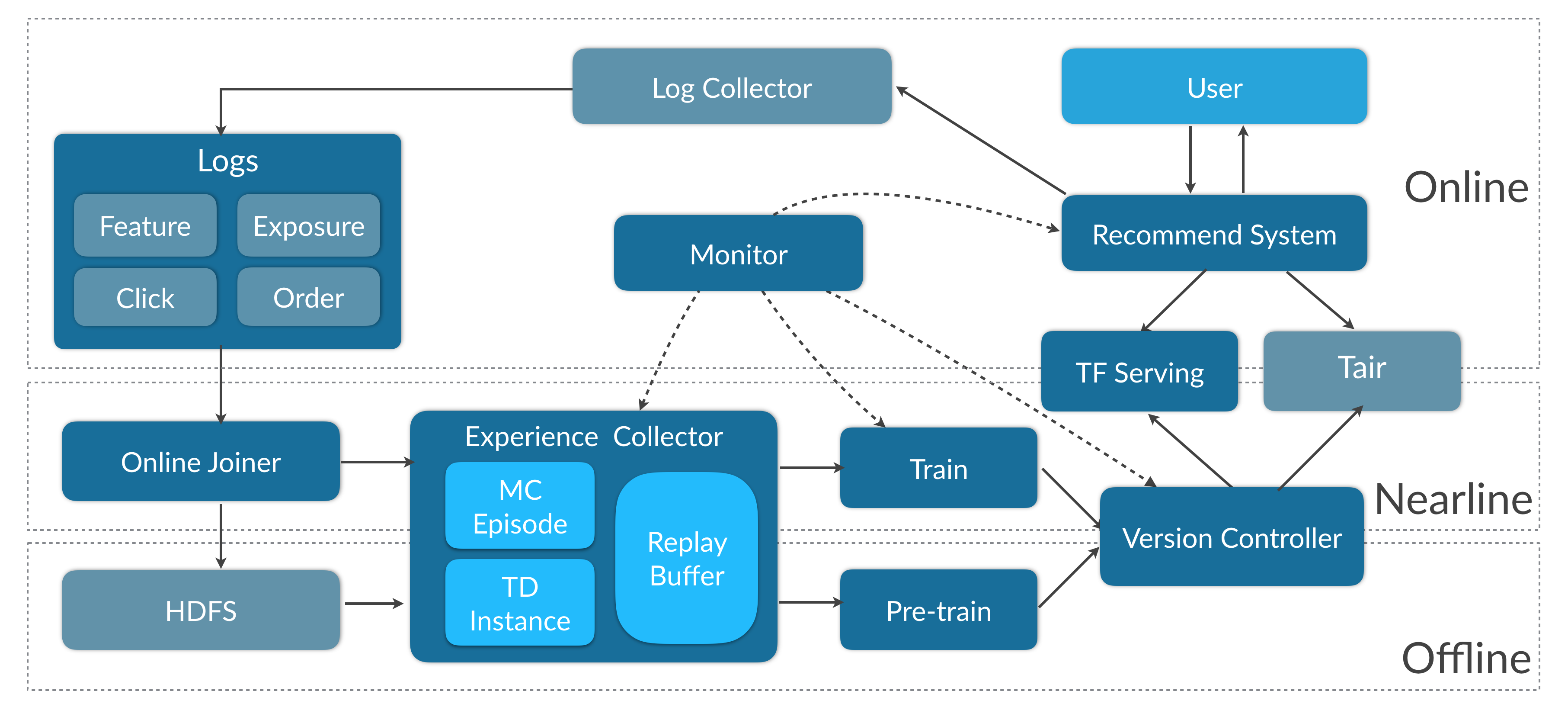
图13 实时更新的强化学习框架
本博客是博主个人学习时的一些记录,不保证是为原创,个别文章加入了转载的源地址,还有个别文章是汇总网上多份资料所成,在这之中也必有疏漏未加标注处,如有侵权请与博主联系。
如果未特殊标注则为原创,遵循 CC 4.0 BY-SA 版权协议。
posted on 2025-01-18 11:19 Angry_Panda 阅读(35) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号