

OneFlow是否真的实现了单机代码无侵害的运行在分布式集群上?
答案:
不是,但也是。
严格意义上来说,不是。
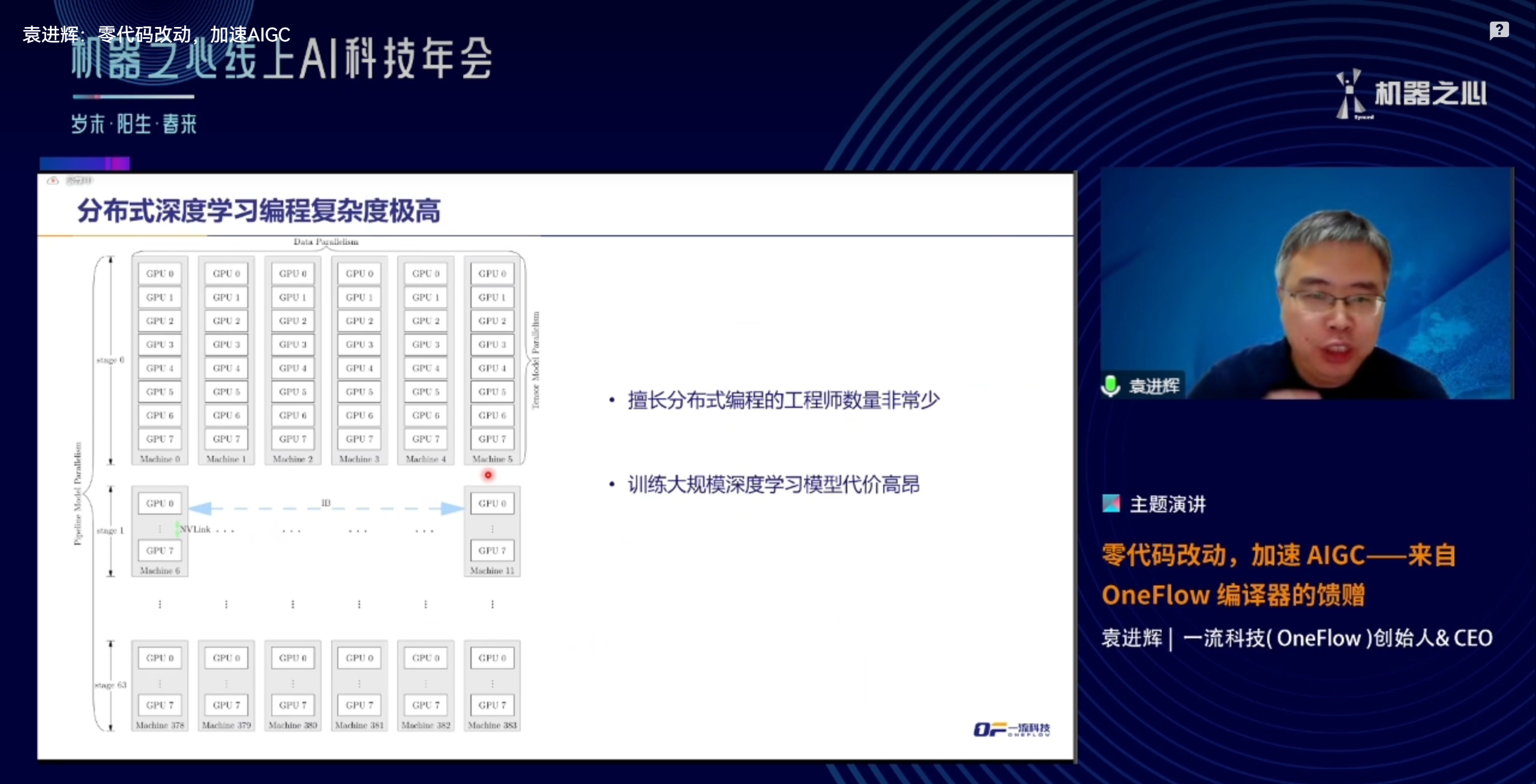
因为技术OneFlow的代码,要从单机改到分布式,也需要改配置,需要给所有的变量设置具体的全局存储还是局部存储,如果局部存储又应该如何划分,等等,这些其实都是需要手动修改的;当然,我们也可以在编写代码之初就留好配置的空间,最后改换到不同的运行配置下只要修改具体的配置文件即可,但是即使如此,单机情况下的代码也是不需要设置这些分布式参数的,而这些依靠修改配置来更改分布式运行情况的也是需要编写之初就留好参数的,因此严格来说OneFlow并不能做到真的“零代码”从单机运行模式切换到分布式,并且即使不需要显示的编写MPI原语操作,但是也需要对分布式的硬件环境做到完全了解才可以进行配置的,因此只能说OneFlow从单机切换到分布式要比其他框架简单,易于操作,不需要对底层分布式计算的编程有太多了解,普通算法工程师就好上手。
之所以说,是。
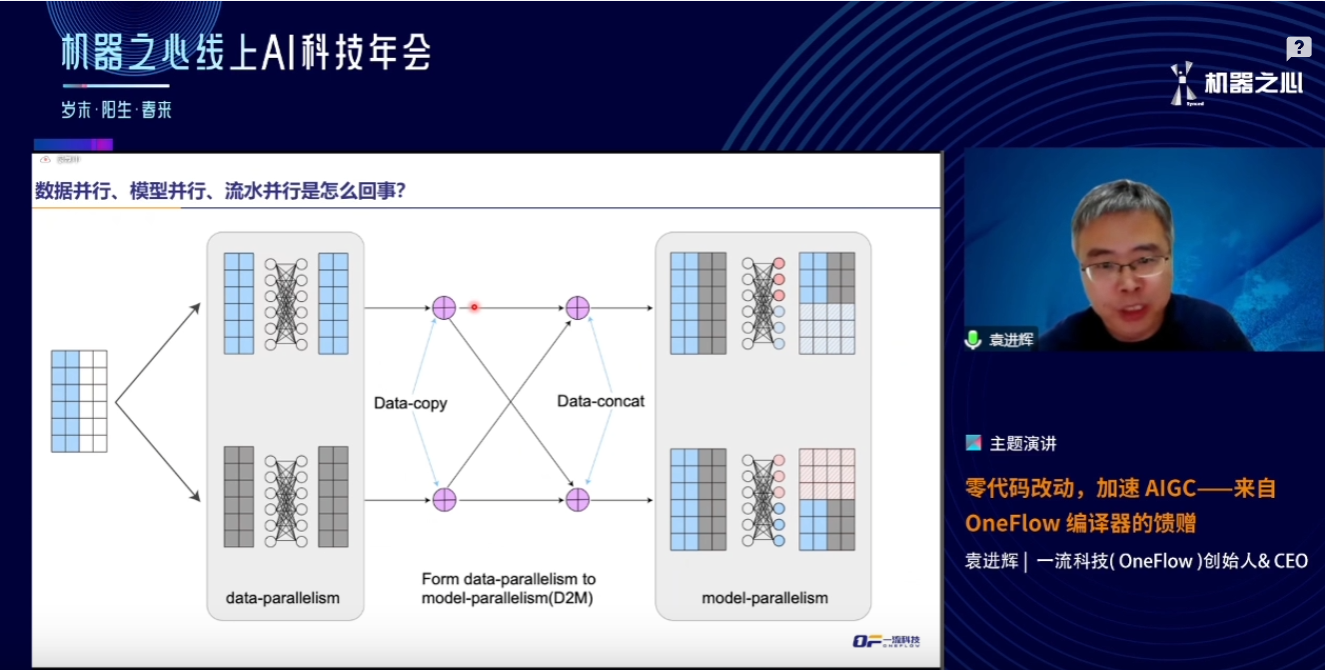
是因为这个OneFlow确实是目前AI领域从单机切换分布式最便捷的一个框架了,只需要对具体权重设置分布式参数即可,如果代码本身设计的时候就留好了分布式参数,那么我们只需要在运行的时候根据具体的硬件情况来修改配置即可。对于很多硬件变化不大的场景下,往往只需要修改几行代码即可实现新的硬件环境下的分布式运行,可以说这个框架确实是目前来说最便捷实现分布式的框架了。如果我们把这种比较小的修改量看作是“零代码”好像也不是完全不能接受的,所以这里才说不是,但也是,就是这个原因了。
PS. 毕竟这个框架是目前来说最大程度将分布式计算的工作从AI大模型工程师身上拿下的框架了,不过这也是对于那些大模型的工程师,对于我这种模型一般不超过8G的情况好像也没有什么分布式的需求,估计搞分布式的也就是那些大模型的玩家了。
标题党:
posted on 2024-02-04 09:05 Angry_Panda 阅读(25) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号