带有最小间隔时间的队列读取实现 —— 最小等待时间的队列 —— Python编程

(注:照片源自免费网站,地址:https://www.freepik.com/photos/angry-panda/13)
==================================================
事情起源是最近在看一个TensorFlow的代码,是 TensorFlow实现了一个最小等待时间的队列,解释一下就是一个进程阻塞在一个队列上等待数据的读取,但是这个阻塞是有条件的,需要满足两个条件中的任意一个即可解除阻塞:一个是读取到了N个数据后;另一个是在阻塞了T秒后如果读取到的数据不为零。满足这两个条件,那么阻塞在队列上的读取进程即可恢复执行。
理论上这个设计是可以提高运算效率的,但是个人认为这个设计在实际使用中作用是十分有效的,但是这个功能既然TensorFlow有提供而其他框架并没有提供,那么我们是否可以手动实现一个呢,或者是python版本呢。
根据前面的描述我们可以知道这个设计需要在满足下面两个条件时接触阻塞:
1. 读取到最少N个数据;
2. 读取到一个以上数据,并且阻塞用时达到阈值T;
对于这个实现,考虑过使用多进程、多线程、异步,后来想想还是用多线程实现大致的逻辑,具体如下(consumer函数没有实现,不能运行,只有逻辑):
from multiprocessing import Process, Queue import threading from threading import Thread import numpy as np import time import asyncio q = Queue(maxsize=128) def produce(q): while True: q.push( np.random.rand(128, 128) ) time.sleep(np.random.randint(10)/1000) for _ in range(10): p = Process(target=produce, args=(q)) p.start() data = [] def consumer(): pass flag = False lock_2 = threading.Lock() def timer(lock): while True: time.sleep(0.1) lock2.acquire() if not flag: if not data: data2 = data[:32] data = data[32:] else: data.append(q.get()) data2 = data[:32] data = data[32:] consumer(data) else: flag = False lock2.release() t = Thread(target=timer, args=(lock,)) t.run() while True: lock2.acquire() data.append(q.get()) if len(data) < 32: lock2.release() continue else: flag = True data2 = data[:32] data = data[32:] consumer(data2) lock2.release()
后来想想刚才的实现好像很没有必要,完全可以用更简单的实现,具体如下:
主要逻辑:(N为32,最小等待时间为1秒)
q = Queue(maxsize=128) # while True: for i in range(1000000): for _ in range(32): try: data.append(q.get(block=False, timeout=1.0/32)) except queue.Empty: print("Empty!!!") if len(data) == 0: data.append(q.get()) print("time: ", i) consumer(data)
不过很不幸的是这个代码并不能正常运行,原因是queue对象在block为False情况下timeout只能是正整数,如果是小于零的数则视为0.
不过我们已经可以简单化的思想来进行解决,得到下面代码:(可以运行的代码)
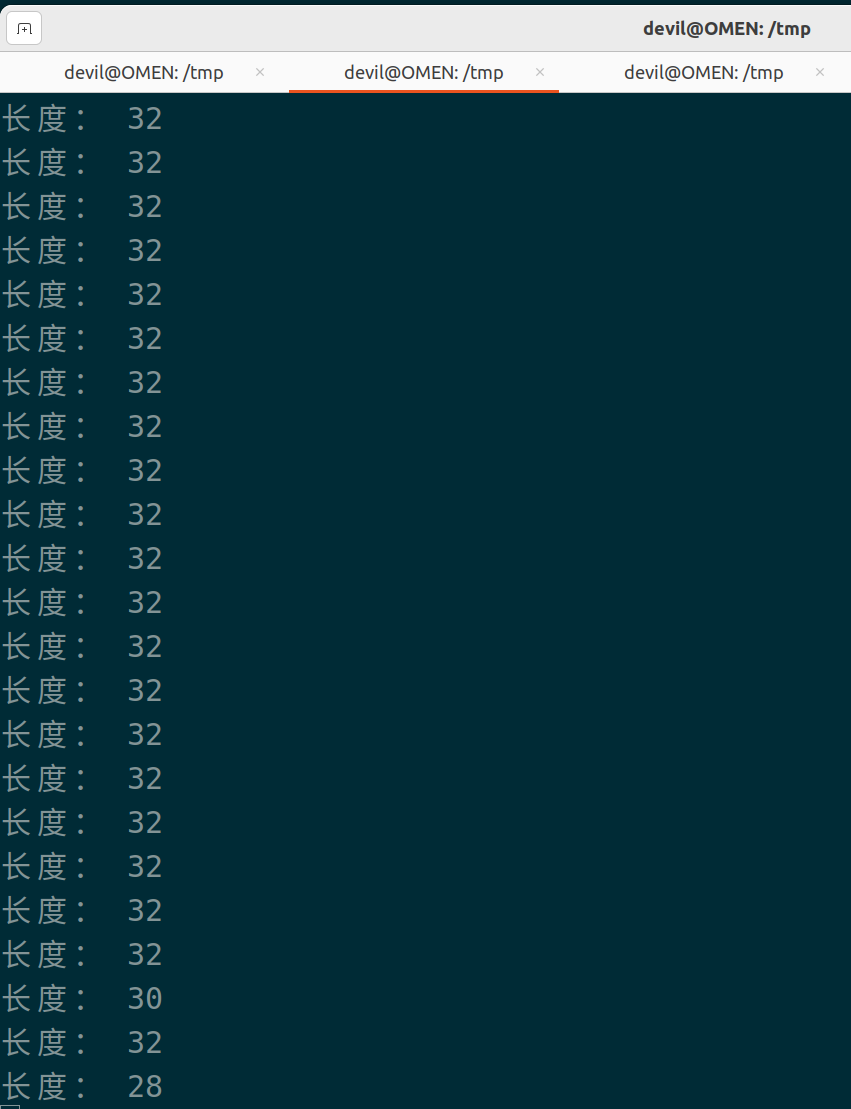
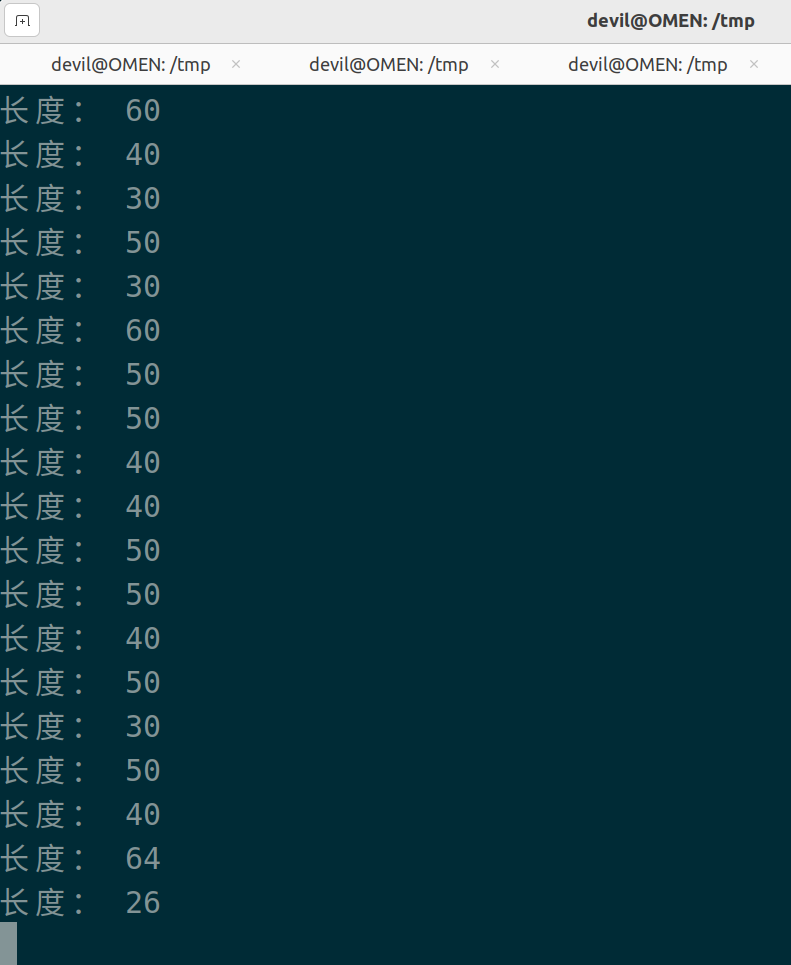
from multiprocessing import Process, Queue import threading from threading import Thread import numpy as np import time import queue q = Queue(maxsize=128) def produce(q): while True: q.put( np.random.rand(128, 128) ) time.sleep(np.random.randint(100)/1000) for _ in range(10): p = Process(target=produce, args=(q, )) p.start() data = [] def consumer(data): print("长度:", len(data)) data.clear() time.sleep(0.1) """ while True: print(q.qsize()) """ # while True: for i in range(3600): a_t = time.time() for _ in range(32): #for _ in range(64): data.append(q.get()) if time.time() - a_t > 0.1: break # print("time: ", i) consumer(data)
当for _ in range(32)时,运行如下:
当for _ in range(64)时,运行如下:
--------------------------------------------------------
由于上面的代码都是基于假设的produce方法和consumer方法,在实际应用中我们可以通过调整参数的方式来寻找更高效的运行方式,具体的修改参数有两处,为:
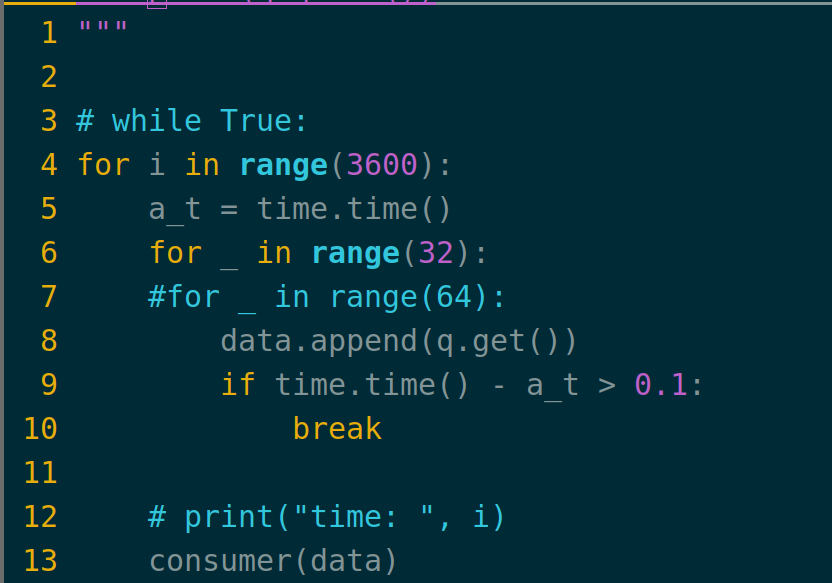
具体调整的位置为第6行的range(32)以及第9行的0.1,通过这两个数值的修改可以对具体的product和consumer进行性能提升。
具体问题时需要根据具体表现出的吞吐率来对这两个数值进行调整。
range数值代表我们预设的希望读取的数据量;0.1处的数值代表我们的最小容忍时间/等待时间。
==================================================
对上面的代码做些修改,加入了吞吐率的计算:
from multiprocessing import Process, Queue import threading from threading import Thread import numpy as np import time import queue q = Queue(maxsize=128) def produce(q): while True: q.put( np.random.rand(128, 128) ) time.sleep(np.random.randint(100)/1000) for _ in range(10): p = Process(target=produce, args=(q, )) p.start() data = [] def consumer(data): l = len(data) #print("长度:", len(data)) data.clear() time.sleep(0.1) return l """ while True: print(q.qsize()) """ s = 0 # while True: b_t = time.time() for i in range(36): a_t = time.time() #for _ in range(32): for _ in range(16): data.append(q.get()) if time.time() - a_t > 0.1: break # print("time: ", i) s += consumer(data) b = time.time() - b_t print(b) print(s) print("吞吐率", s/b)
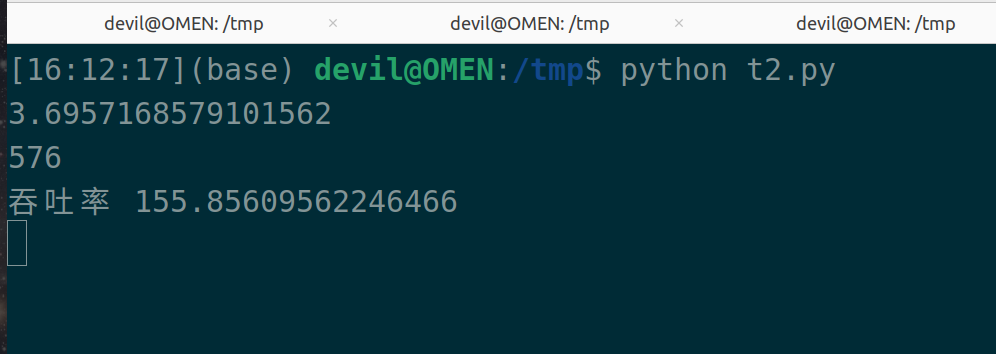
在保持最小间隔时间0.1不变的情况下:
当range(32)和range(64)时吞吐率大致为200个每一秒,在range(16)时则为155个每一秒。
===============================================
posted on 2023-11-01 09:47 Angry_Panda 阅读(72) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号