机器学习中的权重衰退 —— 深度学习中的权重衰退 —— 权重衰退 —— weight decay
在看代码时看到了这个概念,以前虽然也看到过但是没有太在意,再次看到于是研究了一下。
引自:
https://sota.jiqizhixin.com/models/methods/0bdb8f87-9c05-483e-af49-e1140b9e7d19

直接说答案,weight decay 就是L2 Regularization 。
引自:
https://www.jianshu.com/p/995516301b0a

其实在深度学习框架中的优化器参数中就可以设置weight decay,如:
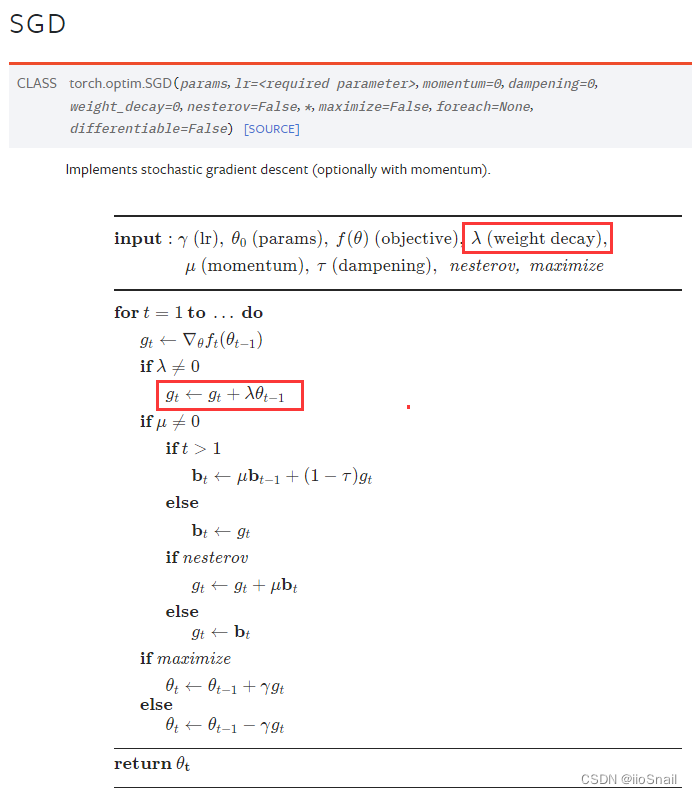
============================================
引自:
https://blog.csdn.net/zhaohongfei_358/article/details/129625803
weight_decay的一些trick:
- weight_decay并没有你想想中的那么好,它的效果可能只有一点点,不要太指望它。尤其是当你的模型很复杂时,权重衰退的效果可能会更小了。
- 通常取1e-3,如果要尝试的话,一般也就是1e-2, 1e-3, 1e-4 这些选项。
- 权重衰退通常不对bias做。但通常bias做不做权重衰退其实效果差不多,不过最好不要做。
- weight_decay取值越大,对抑制模型的强度越大。但这并不说明越大越好,太大的话,可能会导致模型欠拟合。
============================================
给出chainer框架中的实现:(不对bias进行decay,只对weight进行decay)
地址:
https://github.com/chainer/chainerrl/blob/master/chainerrl/optimizers/nonbias_weight_decay.py
class NonbiasWeightDecay(object): """Weight decay only for non-bias parameters. This hook can be used just like chainer.optimizer_hooks.WeightDecay except that this hook does not apply weight decay to bias parameters. This hook assumes that all the bias parameters have the name of "b". Any parameter whose name is "b" is considered as a bias and excluded from weight decay. """ name = 'NonbiasWeightDecay' call_for_each_param = True timing = 'pre' def __init__(self, rate): self.rate = rate def __call__(self, rule, param): if param.name == 'b': return p, g = param.array, param.grad if p is None or g is None: return with cuda.get_device_from_array(p) as dev: if int(dev) == -1: g += self.rate * p else: kernel = cuda.elementwise( 'T p, T decay', 'T g', 'g += decay * p', 'weight_decay') kernel(p, self.rate, g)
def add_hook(self, hook, name=None, timing='auto'): """Adds a hook function. The hook function is called before or after any updates (see the timing attribute). Args: hook (callable): Hook function to be added. It takes two arguments: the update rule object and the parameter variable. name (str): Name of the hook function. The name attribute of the hook function is used by default. timing (str): Specifies when the hook is called. If 'auto', the timimg property of the hook will decide the timing. If 'pre', the hook will be called before any updates. If 'post', the hook will be called after any updates. If 'auto' and the timing property of the hook is not available, timing will default to 'pre'. """ if not callable(hook): raise TypeError('hook function must be callable') if timing not in ('pre', 'post', 'auto'): raise ValueError("timing must be one of ('pre', 'post', 'auto')") if timing == 'auto': timing = getattr(hook, 'timing', 'pre') if name is None: name = getattr(hook, 'name', getattr(hook, '__name__', None)) if name is None: raise ValueError( 'the name of the hook function is not specified') if name in self._pre_update_hooks or name in self._post_update_hooks: raise ValueError('hook "{}" already exists'.format(name)) if timing == 'pre': self._pre_update_hooks[name] = hook else: self._post_update_hooks[name] = hook def remove_hook(self, name): """Removes the specified hook function. Args: name (str): Name of the hook function to be removed. The hook function registered with this name will be removed. """ try: del self._pre_update_hooks[name] except KeyError: del self._post_update_hooks[name] def update(self, param): """Invokes hook functions and updates the parameter. Args: param (~chainer.Variable): Variable to be updated. """ if not self.enabled: return self.t += 1 if self._use_fp32_update and param.dtype == numpy.float16: if self._fp32_param is None: self._fp32_param = variable.Variable( param.array.astype(numpy.float32), name=param.name) fp32_param = self._fp32_param fp32_param.grad = param.grad.astype(numpy.float32) if fp32_param.data is not None: self._prepare(fp32_param) if param._loss_scale is not None: fp32_param.grad /= param._loss_scale for hook in six.itervalues(self._pre_update_hooks): hook(self, fp32_param) self.update_core(fp32_param) for hook in six.itervalues(self._post_update_hooks): hook(self, fp32_param) param.data = fp32_param.data.astype(param.dtype) fp32_param.grad = None else: if param.data is not None: self._prepare(param) if param._loss_scale is not None: param.grad /= param._loss_scale for hook in six.itervalues(self._pre_update_hooks): hook(self, param) self.update_core(param) for hook in six.itervalues(self._post_update_hooks): hook(self, param)
============================================
参考:
https://www.jianshu.com/p/995516301b0a
https://blog.csdn.net/zhaohongfei_358/article/details/129625803
posted on 2023-10-14 17:31 Angry_Panda 阅读(287) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号