
【翻译】理解 LSTM 网络
本文翻译自 Christopher Olah 的博文 Understanding LSTM Networks,原文以图文并茂的形式,深入浅出地为初学者介绍了 LSTM 网络。
【翻译】理解 LSTM 及其图示 或许可以进一步帮助理解。
理解 LSTM 网络
Understanding LSTM Networks
递归神经网络
Recurrent Neural Networks
人类并不是时刻都从头开始思考。如果你阅读这篇文章,你是在之前词汇的基础上理解每一个词汇,你不需要丢掉一切从头开始思考。你的思想具有延续性。
传统的神经网络无法做到这样,并且这成为了一个主要的缺陷。例如,想像一下你需要对一部电影中正在发生的事件做出判断。目前还不清楚传统的神经网络如何根据先前发生的事件来推测之后发生的事件。
递归神经网络正好用来解决这个问题。递归神经网络的内部存在着循环,用来保持信息的延续性。
Humans don't start their thinking from scratch every second. As you read this essay, you understand each word based on your understanding of previous words. You don't throw everything away and start thinking from scratch again. Your thoughts have persistence.
Traditional neural networks can't do this, and it seems like a major shortcoming. For example, imagine you want to classify what kind of event is happening at every point in a movie. It's unclear how a traditional neural network could use its reasoning about previous events in the film to inform later ones.
Recurrent neural networks address this issue. They are networks with loops in them, allowing information to persist.

上图中有局部神经网络——\(A\),输入值 \(x_t\),和输出值 \(h_t\) 。一个循环保证信息一步一步在网络中传递。
这些循环让递归神经网络难以理解。但是,如果仔细想想就会发现,它们和普通的神经网络没什么区别。一个递归神经网络可以看作是一组相同的网络,每一个网络都将信息传递给下一个。如果展开循环就会看到:
In the above diagram, a chunk of neural network, \(A\), looks at some input \(x_t\) and outputs a value \(h_t\). A loop allows information to be passed from one step of the network to the next.
These loops make recurrent neural networks seem kind of mysterious. However, if you think a bit more, it turns out that they aren't all that different than a normal neural network. A recurrent neural network can be thought of as multiple copies of the same network, each passing a message to a successor. Consider what happens if we unroll the loop:
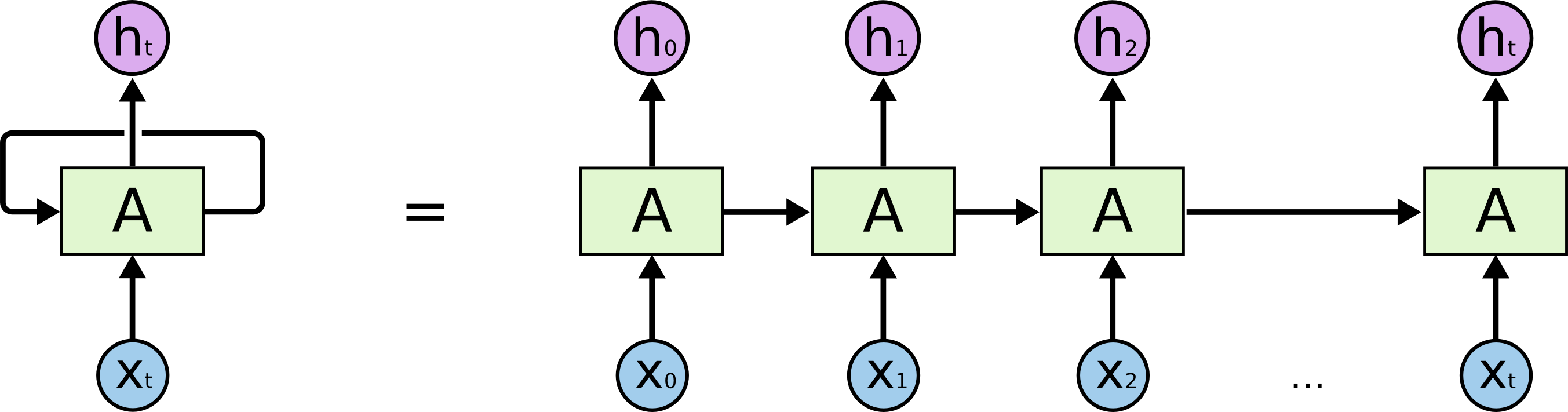
这个链式结构自然地揭示出递归神经网络和序列与列表紧密相关。这是用于处理序列数据的神经网络的自然架构。
当然,也是可用的。最近几年,RNN 在语音识别、语言建模、翻译、图像描述等等领域取得了难以置信的成功。我把对 RNN 所取得成果的讨论留在 Andrej Karpathy 的博客里。RNN 真的很神奇!
这些成功的关键是 “LSTM” ——一种特殊的递归神经网络,在许多问题上比标准版本的 RNN 好得多。几乎所有递归神经网络取得的出色成果均源于 LSTM 的使用。这篇文章要介绍的正是 LSTM。
This chain-like nature reveals that recurrent neural networks are intimately related to sequences and lists. They're the natural architecture of neural network to use for such data.
And they certainly are used! In the last few years, there have been incredible success applying RNNs to a variety of problems: speech recognition, language modeling, translation, image captioning… The list goes on. I'll leave discussion of the amazing feats one can achieve with RNNs to Andrej Karpathy's excellent blog post, The Unreasonable Effectiveness of Recurrent Neural Networks. But they really are pretty amazing.
Essential to these successes is the use of “LSTMs,” a very special kind of recurrent neural network which works, for many tasks, much much better than the standard version. Almost all exciting results based on recurrent neural networks are achieved with them. It's these LSTMs that this essay will explore.
长期依赖性问题
The Problem of Long-Term Dependencies
RNN 的吸引力之一是它们能够将先前的信息与当前的问题连接,例如使用先前的视频画面可以启发对当前画面的理解。如果 RNN 可以做到这一点,它们会非常有用。但它可以吗?嗯,这是有条件的。
有时候,我们只需要查看最近的信息来应对当前的问题。例如,一个语言模型试图根据先前的词汇预测下一个词汇。如果我们试图预测 “the clouds are in the sky” 中的最后一个词,我们不需要任何进一步的上下文背景,很明显,下一个词将是 sky。在这种情况下,相关信息与它所在位置之间的距离很小,RNN 可以学习使用过去的信息。
One of the appeals of RNNs is the idea that they might be able to connect previous information to the present task, such as using previous video frames might inform the understanding of the present frame. If RNNs could do this, they'd be extremely useful. But can they? It depends.
Sometimes, we only need to look at recent information to perform the present task. For example, consider a language model trying to predict the next word based on the previous ones. If we are trying to predict the last word in “the clouds are in the sky,” we don't need any further context –– it's pretty obvious the next word is going to be sky. In such cases, where the gap between the relevant information and the place that it's needed is small, RNNs can learn to use the past information.
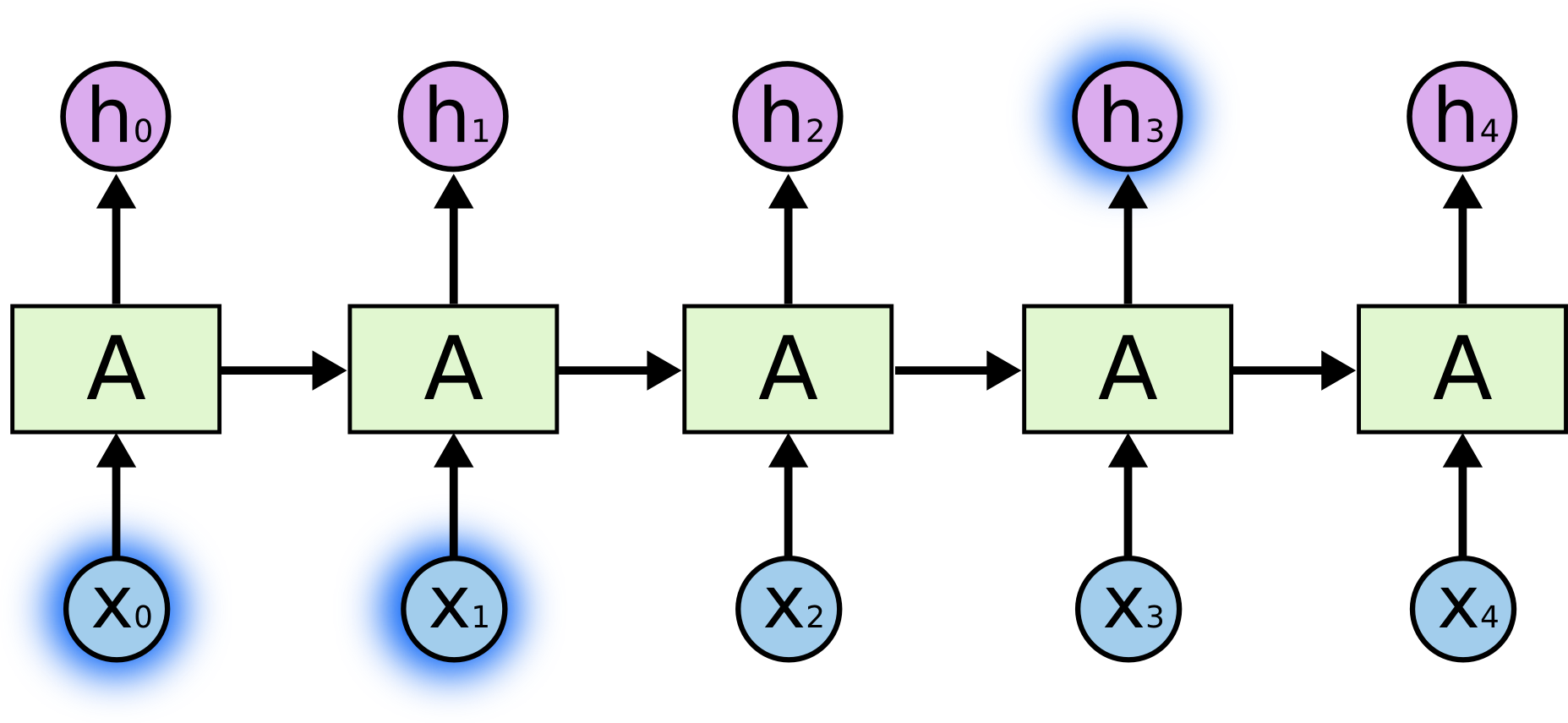
但也有些情况下我们需要更多的上下文。考虑尝试预测 “I grew up in France… I speak fluent French.” 中的最后一个词。最近的信息表明,下一个单词可能是一种语言的名称,但如果我们想要具体到哪种语言,我们需要从更远的地方获得上下文——France。因此,相关信息与它所在位置之间的距离非常大是完全可能的。
遗憾的是,随着距离的增大,RNN 开始无法将信息连接起来。
But there are also cases where we need more context. Consider trying to predict the last word in the text “I grew up in France… I speak fluent French.” Recent information suggests that the next word is probably the name of a language, but if we want to narrow down which language, we need the context of France, from further back. It's entirely possible for the gap between the relevant information and the point where it is needed to become very large.
Unfortunately, as that gap grows, RNNs become unable to learn to connect the information.

理论上,RNN 绝对有能力处理这种“长期依赖性”。人类可通过仔细挑选参数来解决这种形式的“玩具问题”。遗憾的是在实践中,RNN 似乎无法学习它们。这个问题是由 Hochreiter 和 Bengio 等人深入探讨。他发现了问题变困难的根本原因。
谢天谢地,LSTM 没这种问题!
In theory, RNNs are absolutely capable of handling such “long-term dependencies.” A human could carefully pick parameters for them to solve toy problems of this form. Sadly, in practice, RNNs don't seem to be able to learn them. The problem was explored in depth by Hochreiter (1991) [German] and Bengio, et al. (1994), who found some pretty fundamental reasons why it might be difficult.
Thankfully, LSTMs don't have this problem!
LSTM 网络
LSTM Networks
长短期记忆网络——通常被称为 LSTM,是一种特殊的 RNN,能够学习长期依赖性。由 Hochreiter 和 Schmidhuber(1997)提出的,并且在接下来的工作中被许多人改进和推广。LSTM 在各种各样的问题上表现非常出色,现在被广泛使用。
LSTM 被明确设计用来避免长期依赖性问题。长时间记住信息实际上是 LSTM 的默认行为,而不是需要努力学习的东西!
所有递归神经网络都具有神经网络的链式重复模块。在标准的 RNN 中,这个重复模块具有非常简单的结构,例如只有单个 tanh 层。
Long Short Term Memory networks – usually just called “LSTMs” – are a special kind of RNN, capable of learning long-term dependencies. They were introduced by Hochreiter & Schmidhuber (1997), and were refined and popularized by many people in following work.[1] They work tremendously well on a large variety of problems, and are now widely used.
LSTMs are explicitly designed to avoid the long-term dependency problem. Remembering information for long periods of time is practically their default behavior, not something they struggle to learn!
All recurrent neural networks have the form of a chain of repeating modules of neural network. In standard RNNs, this repeating module will have a very simple structure, such as a single tanh layer.
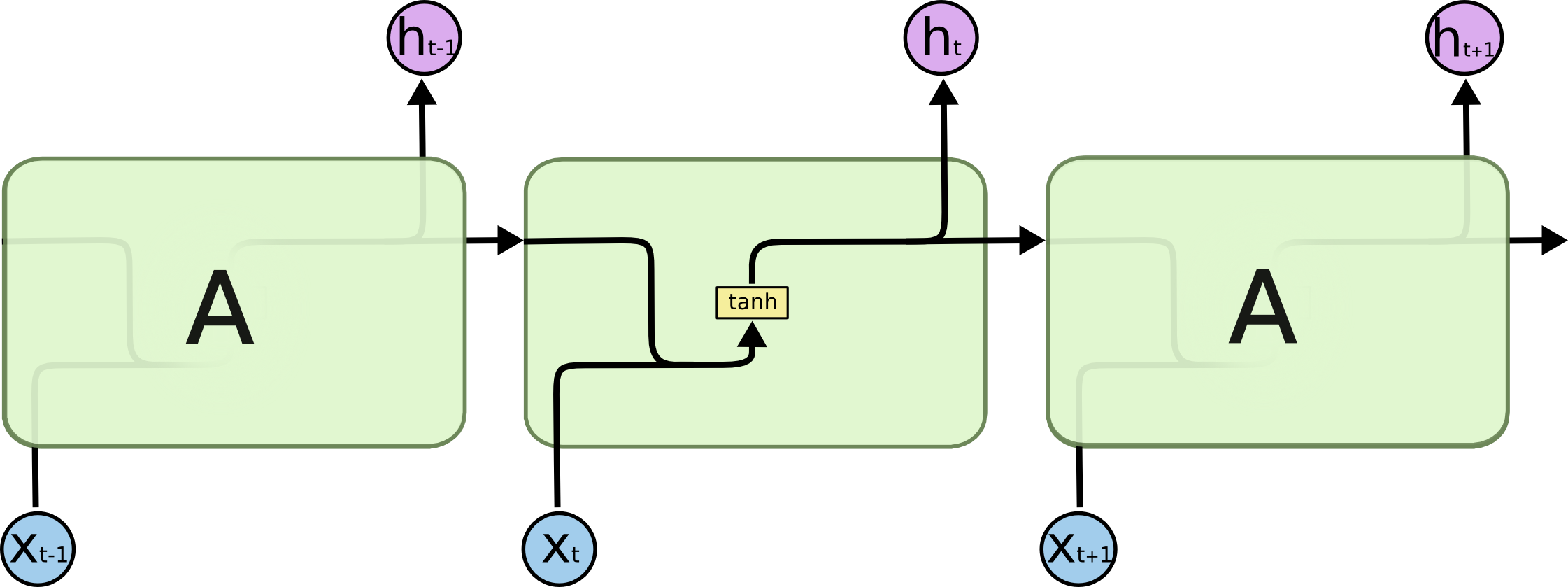
LSTM 也具有这种类似的链式结构,但重复模块具有不同的结构。不是一个单独的神经网络层,而是四个,并且以非常特殊的方式进行交互。
LSTMs also have this chain like structure, but the repeating module has a different structure. Instead of having a single neural network layer, there are four, interacting in a very special way.
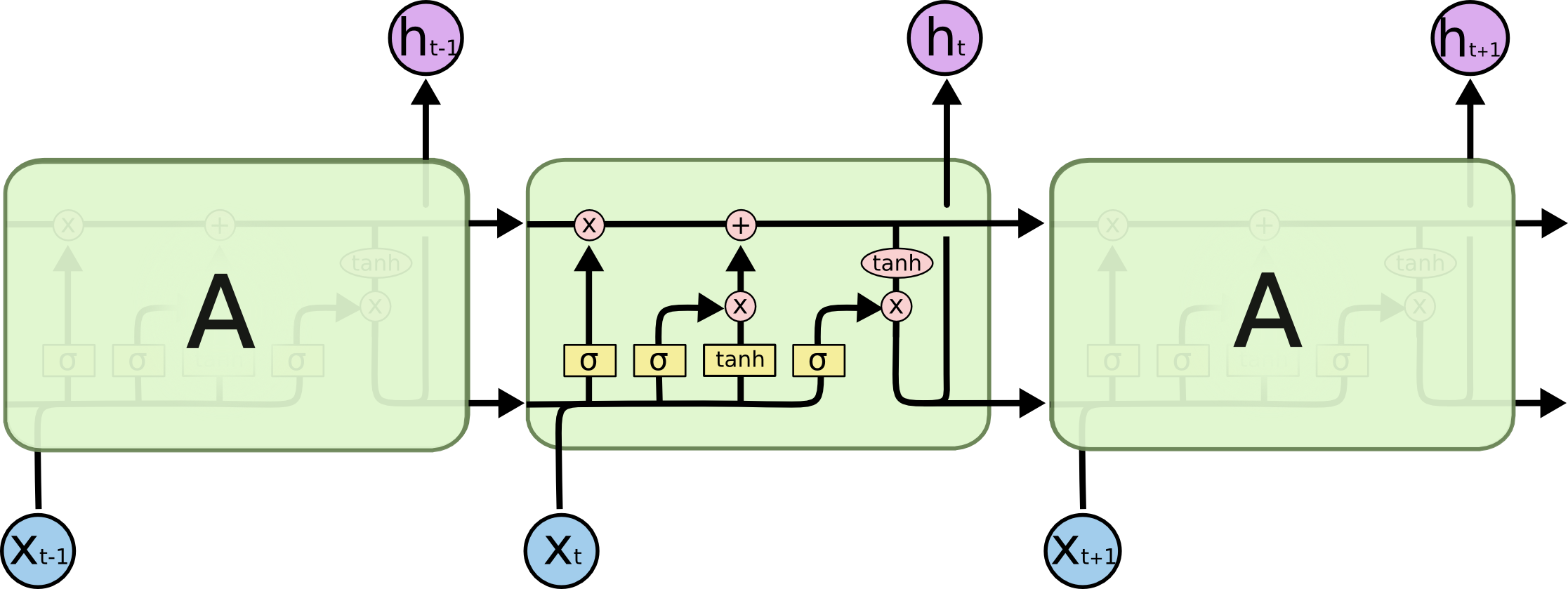
不要担心细节。稍后我们将逐步浏览 LSTM 的图解。现在,让我们试着去熟悉我们将使用的符号。
Don't worry about the details of what's going on. We'll walk through the LSTM diagram step by step later. For now, let's just try to get comfortable with the notation we'll be using.

在上面的图中,每行包含一个完整的向量,从一个节点的输出到其他节点的输入。粉色圆圈表示逐点运算,如向量加法;而黄色框表示学习的神经网络层。行合并表示串联,而分支表示其内容正在被复制,并且副本将转到不同的位置。
In the above diagram, each line carries an entire vector, from the output of one node to the inputs of others. The pink circles represent pointwise operations, like vector addition, while the yellow boxes are learned neural network layers. Lines merging denote concatenation, while a line forking denote its content being copied and the copies going to different locations.
LSTM 的核心想法
The Core Idea Behind LSTMs
LSTM 的关键是细胞状态,即图中上方的水平线。
细胞状态有点像传送带。它贯穿整个链条,只有一些次要的线性交互作用。信息很容易以不变的方式流过。
The key to LSTMs is the cell state, the horizontal line running through the top of the diagram.
The cell state is kind of like a conveyor belt. It runs straight down the entire chain, with only some minor linear interactions. It's very easy for information to just flow along it unchanged.
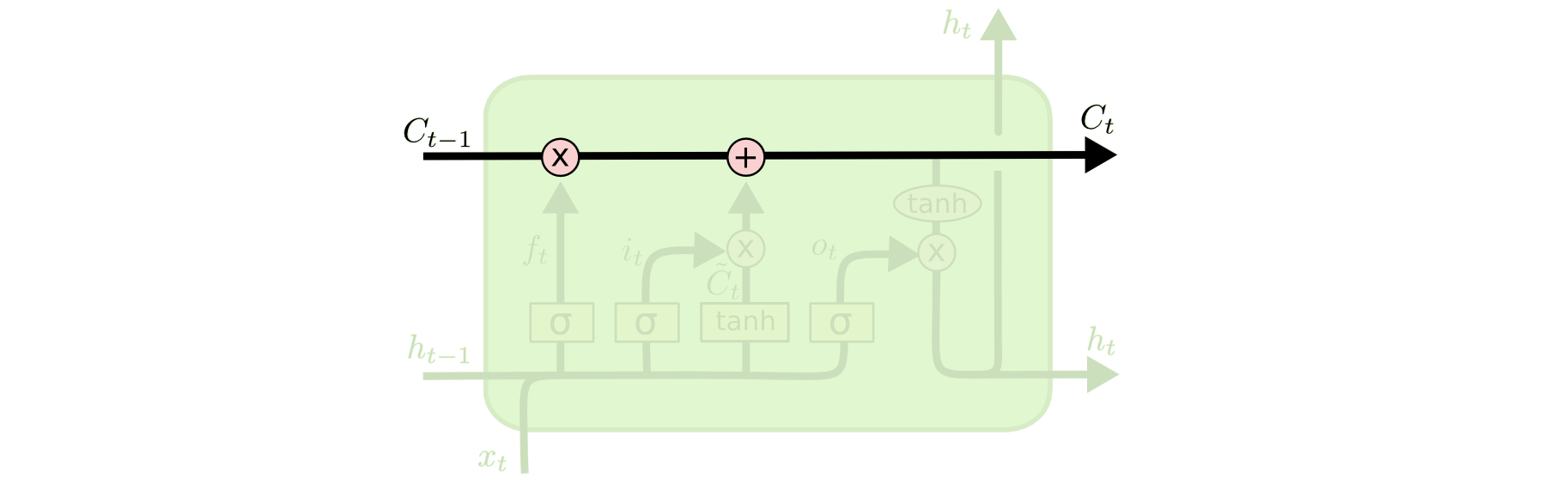
LSTM 可以通过所谓“门”的精细结构向细胞状态添加或移除信息。
门可以选择性地以让信息通过。它们由 S 形神经网络层和逐点乘法运算组成。
The LSTM does have the ability to remove or add information to the cell state, carefully regulated by structures called gates.
Gates are a way to optionally let information through. They are composed out of a sigmoid neural net layer and a pointwise multiplication operation.

S 形网络的输出值介于 0 和 1 之间,表示有多大比例的信息通过。0 值表示“没有信息通过”,1 值表示“所有信息通过”。
一个 LSTM 有三种这样的门用来保持和控制细胞状态。
The sigmoid layer outputs numbers between zero and one, describing how much of each component should be let through. A value of zero means “let nothing through,” while a value of one means “let everything through!”
An LSTM has three of these gates, to protect and control the cell state.
逐步解析 LSTM 的流程
Step-by-Step LSTM Walk Through
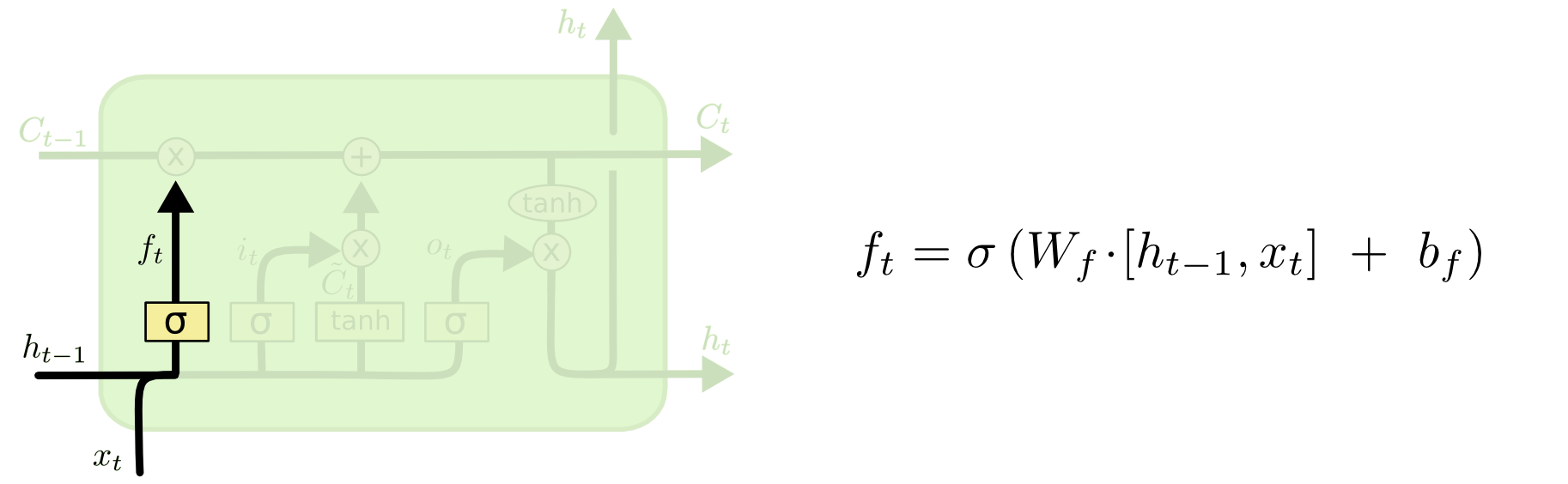
LSTM 的第一步要决定从细胞状态中舍弃哪些信息。这一决定由所谓“遗忘门层”的 S 形网络层做出。它接收 \(h_{t-1}\) 和 \(x_t\),并且对细胞状态 \(C_{t-1}\) 中的每一个数来说输出值都介于 0 和 1 之间。1 表示“完全接受这个”,0 表示“完全忽略这个”。
让我们回到语言模型的例子,试图用先前的词汇预测下一个。在这个问题中,细胞状态可能包括当前主语的词性,因此可以使用正确的代词。当我们看到一个新的主语时,我们需要忘记先前主语的词性。
The first step in our LSTM is to decide what information we're going to throw away from the cell state. This decision is made by a sigmoid layer called the “forget gate layer.” It looks at \(h_{t-1}\) and \(x_t\), and outputs a number between \(0\) and \(1\) for each number in the cell state \(C_{t-1}\). A \(1\) represents “completely keep this” while a \(0\) represents “completely get rid of this.”
Let's go back to our example of a language model trying to predict the next word based on all the previous ones. In such a problem, the cell state might include the gender of the present subject, so that the correct pronouns can be used. When we see a new subject, we want to forget the gender of the old subject.
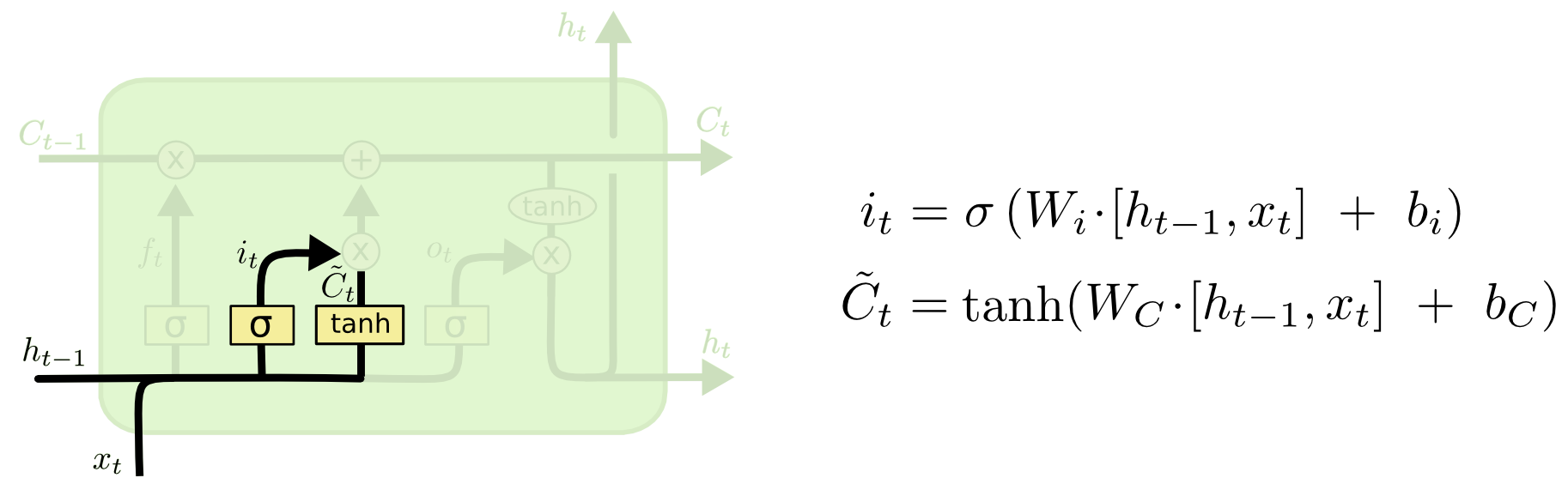
下一步就是要确定需要在细胞状态中保存哪些新信息。这里分成两部分。第一部分,一个所谓“输入门层”的 S 形网络层确定哪些信息需要更新。第二部分,一个 tanh 形网络层创建一个新的备选值向量—— \(\tilde{C}_t\),可以用来添加到细胞状态。在下一步中我们将上面的两部分结合起来,产生对状态的更新。
在我们的语言模型中,我们要把新主语的词性加入状态,取代需要遗忘的旧主语。
The next step is to decide what new information we're going to store in the cell state. This has two parts. First, a sigmoid layer called the “input gate layer” decides which values we'll update. Next, a tanh layer creates a vector of new candidate values, \(\tilde{C}_t\), that could be added to the state. In the next step, we'll combine these two to create an update to the state.
In the example of our language model, we'd want to add the gender of the new subject to the cell state, to replace the old one we're forgetting.
现在更新旧的细胞状态 \(C_{t-1}\) 更新到 \(C_{t}\)。先前的步骤已经决定要做什么,我们只需要照做就好。
我们对旧的状态乘以 \(f_t\),用来忘记我们决定忘记的事。然后我们加上 \(i_t*\tilde{C}_t\),这是新的候选值,根据我们对每个状态决定的更新值按比例进行缩放。
语言模型的例子中,就是在这里我们根据先前的步骤舍弃旧主语的词性,添加新主语的词性。
It's now time to update the old cell state, \(C_{t-1}\), into the new cell state \(C_t\). The previous steps already decided what to do, we just need to actually do it.
We multiply the old state by \(f_t\), forgetting the things we decided to forget earlier. Then we add \(i_t*\tilde{C}_t\). This is the new candidate values, scaled by how much we decided to update each state value.
In the case of the language model, this is where we'd actually drop the information about the old subject's gender and add the new information, as we decided in the previous steps.

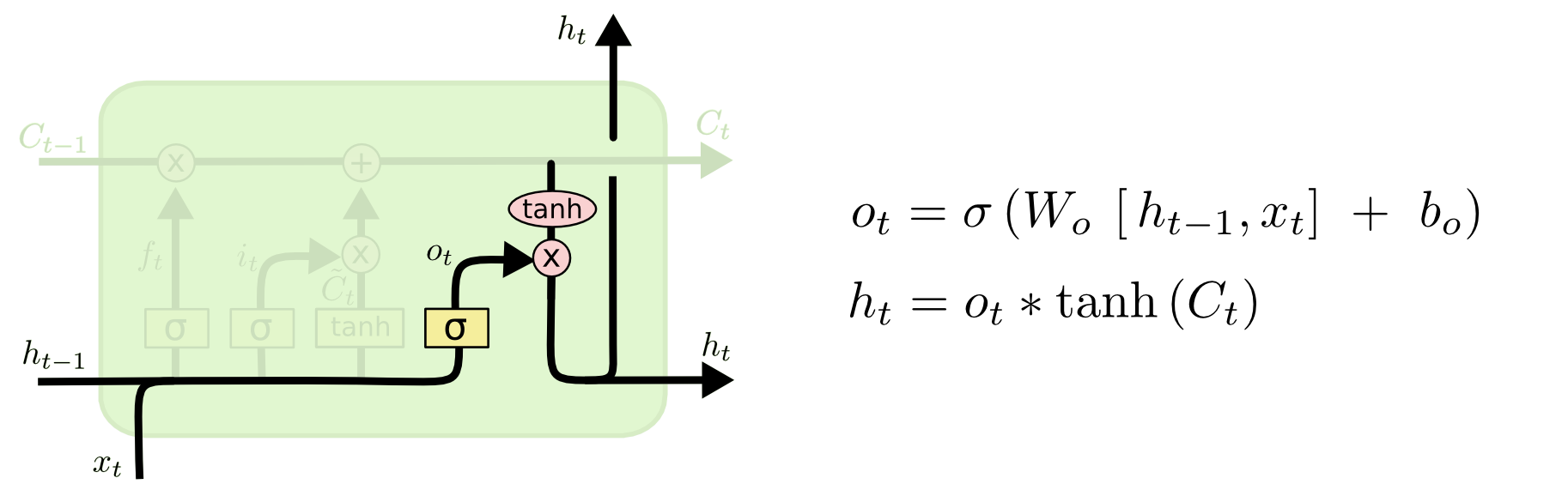
最后,我们需要确定输出值。输出依赖于我们的细胞状态,但会是一个“过滤的”版本。首先我们运行 S 形网络层,用来确定细胞状态中的哪些部分可以输出。然后,我们把细胞状态输入 \(\tanh\)(把数值调整到 \(-1\) 和 \(1\) 之间)再和 S 形网络层的输出值相乘,这样我们就可以输出想要输出的部分。
以语言模型为例子,一旦出现一个主语,主语的信息会影响到随后出现的动词。例如,知道主语是单数还是复数,就可以知道随后动词的形式。
Finally, we need to decide what we're going to output. This output will be based on our cell state, but will be a filtered version. First, we run a sigmoid layer which decides what parts of the cell state we're going to output. Then, we put the cell state through \(\tanh\) (to push the values to be between \(-1\) and \(1\)) and multiply it by the output of the sigmoid gate, so that we only output the parts we decided to.
For the language model example, since it just saw a subject, it might want to output information relevant to a verb, in case that's what is coming next. For example, it might output whether the subject is singular or plural, so that we know what form a verb should be conjugated into if that's what follows next.
长短期记忆的变种
Variants on Long Short Term Memory
目前我所描述的还只是一个相当一般化的 LSTM 网络。但并非所有 LSTM 网络都和之前描述的一样。事实上,几乎所有文章都会改进 LSTM 网络得到一个特定版本。差别是次要的,但有必要认识一下这些变种。
一个流行的 LSTM 变种由 Gers 和 Schmidhuber 提出,在 LSTM 的基础上添加了一个“窥视孔连接”,这意味着我们可以让门网络层输入细胞状态。
What I've described so far is a pretty normal LSTM. But not all LSTMs are the same as the above. In fact, it seems like almost every paper involving LSTMs uses a slightly different version. The differences are minor, but it's worth mentioning some of them.
One popular LSTM variant, introduced by Gers & Schmidhuber (2000), is adding “peephole connections.” This means that we let the gate layers look at the cell state.
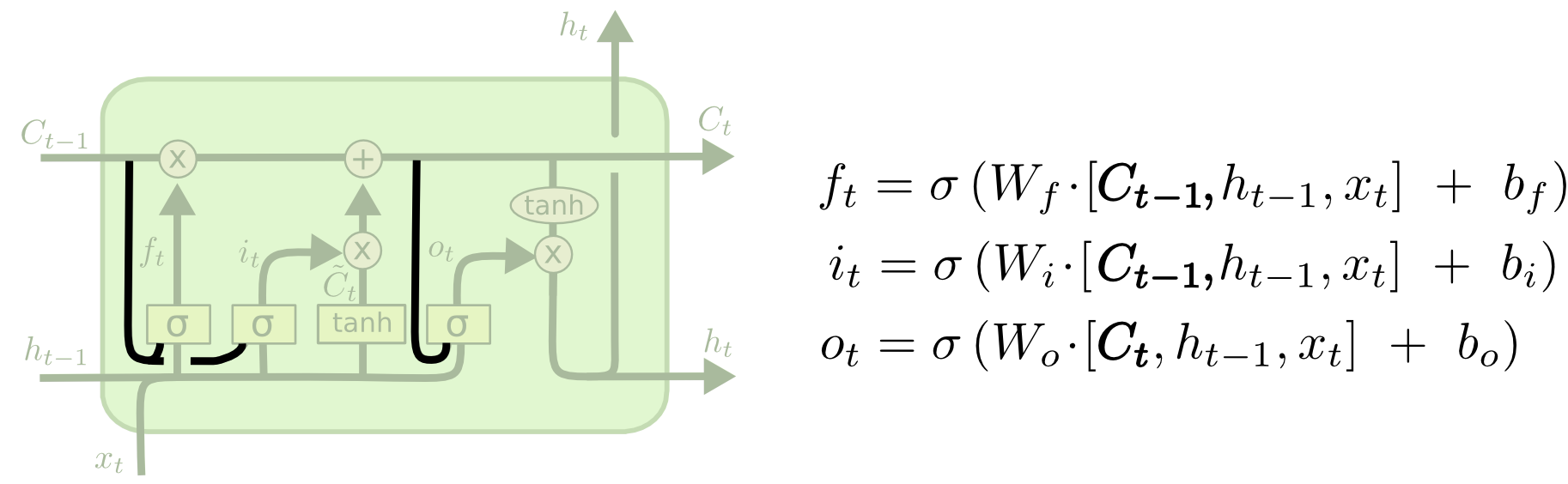
上图中我们为所有门添加窥视孔,但许多论文只为部分门添加。
另一个变种把遗忘和输入门结合起来。同时确定要遗忘的信息和要添加的新信息,而不再是分开确定。当输入的时候才会遗忘,当遗忘旧信息的时候才会输入新数据。
The above diagram adds peepholes to all the gates, but many papers will give some peepholes and not others.
Another variation is to use coupled forget and input gates. Instead of separately deciding what to forget and what we should add new information to, we make those decisions together. We only forget when we're going to input something in its place. We only input new values to the state when we forget something older.
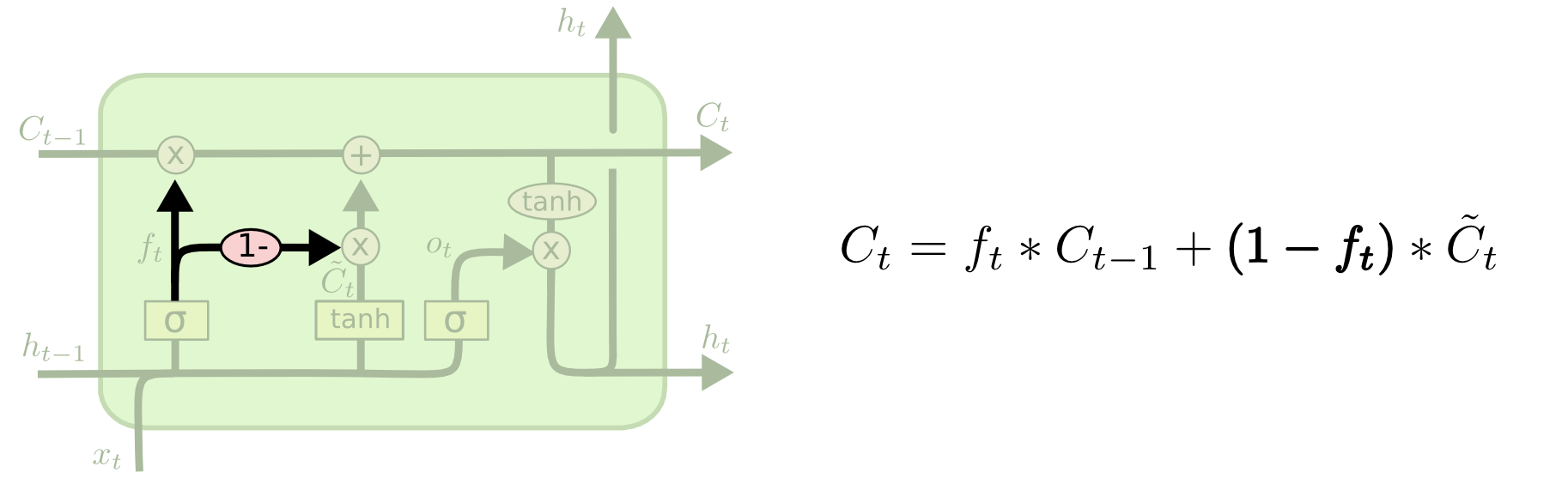
一个更有意思的 LSTM 变种称为 Gated Recurrent Unit(GRU),由 Cho 等人提出。GRU 把遗忘门和输入门合并成为一个“更新门”,把细胞状态和隐含状态合并,还有其他变化。这样做使得 GRU 比标准的 LSTM 模型更简单,因此正在变得流行起来。
A slightly more dramatic variation on the LSTM is the Gated Recurrent Unit, or GRU, introduced by Cho, et al. (2014). It combines the forget and input gates into a single “update gate.” It also merges the cell state and hidden state, and makes some other changes. The resulting model is simpler than standard LSTM models, and has been growing increasingly popular.

这些只是若干知名 LSTM 变种中的一小部分。还有其他变种,例如 Yao 等人提出的 Depth Gated RNN。也有一些完全不同的方法处理长期依赖性,例如 Koutnik 等人提出的 Clockwork RNN。
这些变种哪一个是最好的?它们之间的区别重要吗?Greff 等人做了研究,细致的比较流行的变种,结果发现它们几乎都一样。Jozefowicz 等人测试了一万余种 RNN 架构,发现在特定问题上有些架构的表现好于 LSTM。
These are only a few of the most notable LSTM variants. There are lots of others, like Depth Gated RNNs by Yao, et al. (2015). There's also some completely different approach to tackling long-term dependencies, like Clockwork RNNs by Koutnik, et al. (2014).
Which of these variants is best? Do the differences matter? Greff, et al. (2015) do a nice comparison of popular variants, finding that they're all about the same. Jozefowicz, et al. (2015) tested more than ten thousand RNN architectures, finding some that worked better than LSTMs on certain tasks.
结论
Conclusion
早先,我注意到有些人使用 RNN 取得了显著的成果,这些几乎都是通过 LSTM 网络做到的。对于绝大部分问题,LSTM 真的更好用!
罗列一大堆公式之后,LSTM 看起来令人生畏。还好,文章中逐步的解析让它们更容易接受。
LSTM 是 RNN 取得的一大进步。很自然地要问:还有其他的进步空间吗?研究人员的普遍答案是:Yes!还有进步的空间,那就是注意力(attention)!注意力的想法是让 RNN 中的每一步都从信息更加富集的地方提取信息。例如,你想使用 RNN 对一幅图片生成描述,它也需要提取图片中的一部分来生成输出的文字。事实上,Xu 等人就是这么做的,如果你想探索注意力,这会是一个相当不错的起始点。还有许多出色的成果使用了注意力,注意力未来还将发挥更大的威力...
注意力并非 RNN 研究中唯一一个激动人心的思路。Kalchbrenner 等人提出的 Grid LSTM 看起来极具潜力。Gregor等人、Chung 等人,或者 Bayer 与 Osendorfer 在生成模型中使用 RNN 的想法也非常有意思。最近几年是递归神经网络的明星时间,新出的成果只会更具前景。
Earlier, I mentioned the remarkable results people are achieving with RNNs. Essentially all of these are achieved using LSTMs. They really work a lot better for most tasks!
Written down as a set of equations, LSTMs look pretty intimidating. Hopefully, walking through them step by step in this essay has made them a bit more approachable.
LSTMs were a big step in what we can accomplish with RNNs. It's natural to wonder: is there another big step? A common opinion among researchers is: “Yes! There is a next step and it's attention!” The idea is to let every step of an RNN pick information to look at from some larger collection of information. For example, if you are using an RNN to create a caption describing an image, it might pick a part of the image to look at for every word it outputs. In fact, Xu, et al. (2015) do exactly this – it might be a fun starting point if you want to explore attention! There's been a number of really exciting results using attention, and it seems like a lot more are around the corner…
Attention isn't the only exciting thread in RNN research. For example, Grid LSTMs by Kalchbrenner, et al. (2015) seem extremely promising. Work using RNNs in generative models – such as Gregor, et al. (2015), Chung, et al. (2015), or Bayer & Osendorfer (2015) – also seems very interesting. The last few years have been an exciting time for recurrent neural networks, and the coming ones promise to only be more so!
鸣谢
Acknowledgments
我很感谢有许多人帮助我更好地理解 LSTM 网络,无论是可视化上边的评注,还是文章后面的反馈。
我非常感谢我在 Google 的同事提供了有益的反馈,特别是 Oriol Vinyals、Greg Corrado、Jon Shlens、Luke Vilnis 和 Ilya Sutskever。我也非常感谢其他花时间帮助我的同事,包括 Dario Amodei 和 Jacob Steinhardt。我要特别感谢 Kyunghyun Cho 针对文章图解的极具关切的来信。
在这篇博客之前,我已经在两个系列研讨班上阐述过 LSTM 网络,当时我正在做神经网络方面的教学。感谢所有参加过研讨班的人以及他们提出的反馈。
I'm grateful to a number of people for helping me better understand LSTMs, commenting on the visualizations, and providing feedback on this post.
I'm very grateful to my colleagues at Google for their helpful feedback, especially Oriol Vinyals, Greg Corrado, Jon Shlens, Luke Vilnis, and Ilya Sutskever. I'm also thankful to many other friends and colleagues for taking the time to help me, including Dario Amodei, and Jacob Steinhardt. I'm especially thankful to Kyunghyun Cho for extremely thoughtful correspondence about my diagrams.
Before this post, I practiced explaining LSTMs during two seminar series I taught on neural networks. Thanks to everyone who participated in those for their patience with me, and for their feedback.
In addition to the original authors, a lot of people contributed to the modern LSTM. A non-comprehensive list is: Felix Gers, Fred Cummins, Santiago Fernandez, Justin Bayer, Daan Wierstra, Julian Togelius, Faustino Gomez, Matteo Gagliolo, and Alex Graves. ↩︎

 浙公网安备 33010602011771号
浙公网安备 33010602011771号