
深度学习笔记(二十二)Structure-Preserving Neural Style Transfer
PS: 我本身没有实践过此类任务,有些地方会有些理解错误,还请见谅!
Image style transfer 是一个 pixel to pixel 的任务,常见的方法中 image representation 一般包含 style representation and content representation 两部分,但由于这些预训练模型都来源与图像识别任务,特征提取更关注与中心目标而忽略了其他细节(depth and edge?),这导致 生成的图片内容容易失真。作者在此基础上引入了一个 structure representation(depth and edge)。
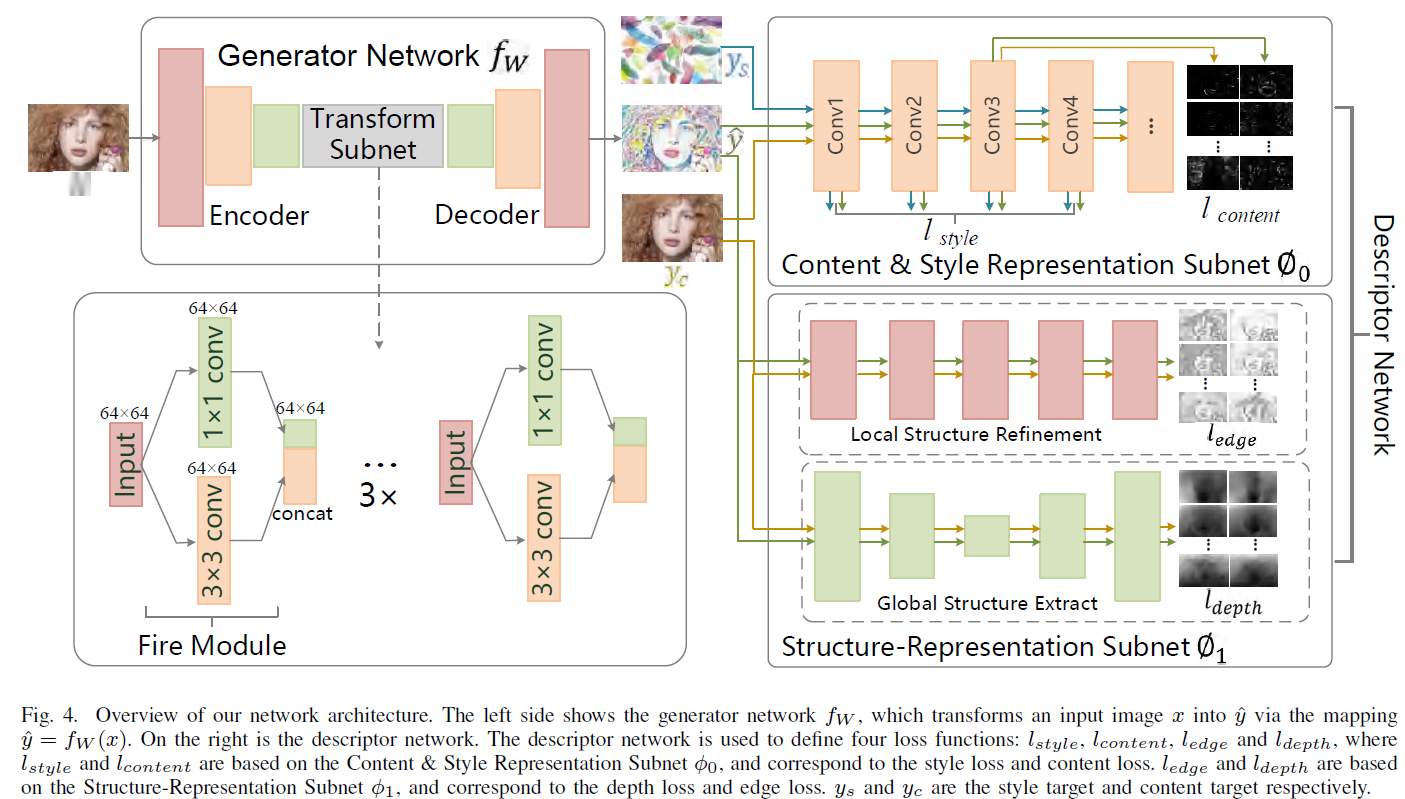
算法设计上,对照上面的图片来看:
整个系统包含三个部分:生成网络 $f_W$,两个 image representation $\phi_0$, $\phi_1$。
生成网络是一个常规的 U 型 Encoder-Decoder 网络,网络结构上采用了 SqueezeNet Block(好老的网络组件)
Image representation $\phi_0$ 是一个 pre-trained image classification network。
Image representation $\phi_1$ 则分别由 a single-image depth perception network 和 a holistically-nested edge detection network 构成,目的是提取 depth 和 edge information。
Loss 由 $l_{style}$, $l_{content}$,$l_{depth}$, $l_{edge}$ 四部分加权组成。
训练中,输入图片 $x$ 送入 U 型的生成网络 $f_W$ 得到输出图片 $\hat{y}$。 $\hat{y}$、 $y_c$ (输入图像 $x$) 、$y_s$(风格目标图像) 三张图片再分别送入 pre-trained image classification network 中从特征级别计算 style loss($l_{style}$) and content loss($l_{content}$)。这是 features level 的对比,目的是让 $\hat{y}$ 和 $x$ 的 perceptual and semantic information 更接近。随后再将 $\hat{y}$、 $y_c$ 再分别送入 depth perception network 和 edge detection network 中获得彼此的 depth image 和 edge image,从而计算 depth loss( $l_{depth}$) 和 edge loss($l_{edge}$), 这是 pixel-level 的对比,目的是让生成的 $\hat{y}$ 仍保留 源图$x$ 的 depth and edge content.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号