7.2.2-bpf对tcp请求的监控(项目)
流程图
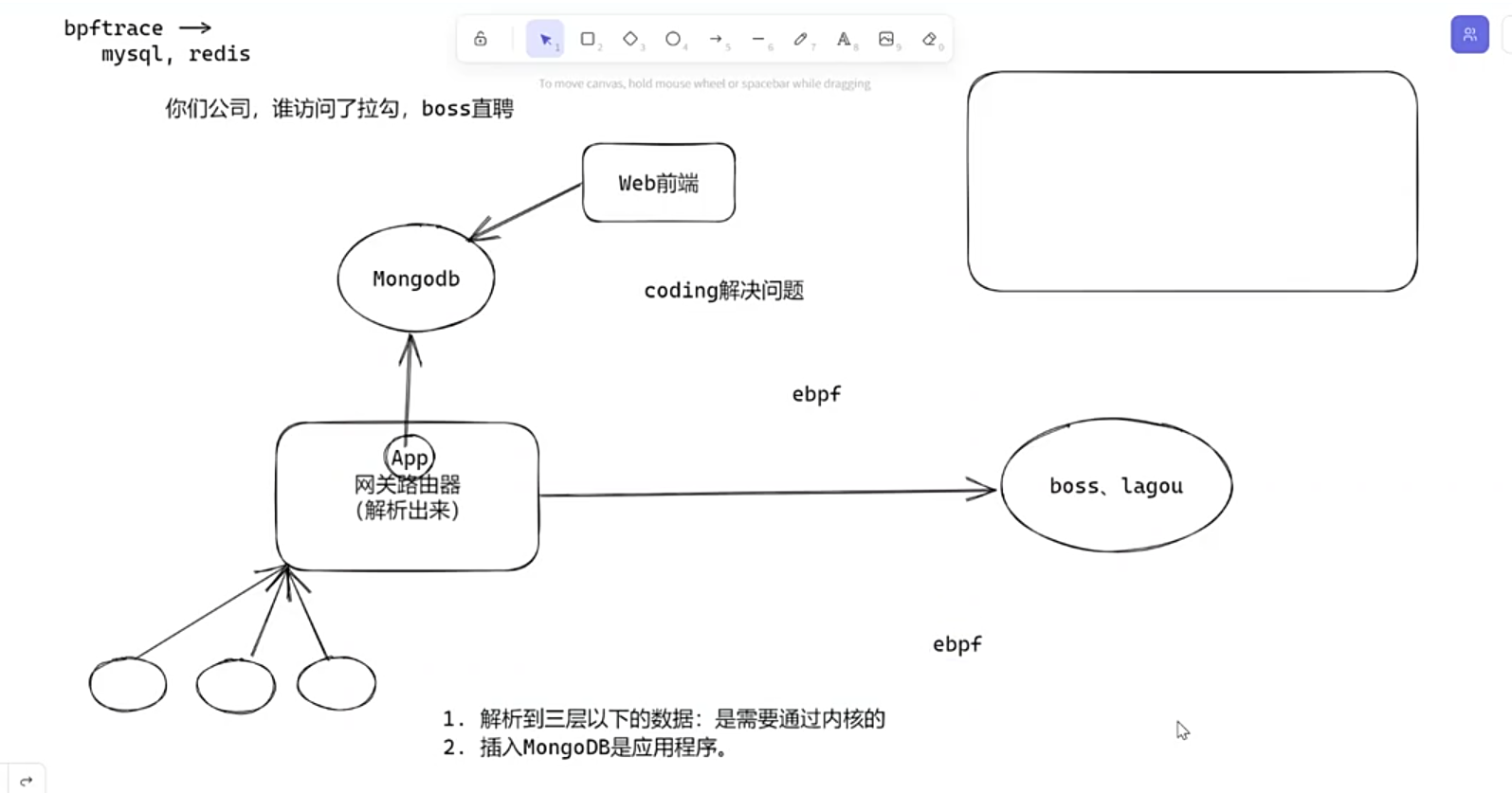
eBPF
-
一个关键点:
eBPF的组成要两份代码,一份放在内核中,一份放在应用层。 -
我们开发
eBPF程序,不能从零开发,就像跑AI模型,你要用到pytorch框架 (难道你从零写cuda算子?)。 -
对于
eBPF,我们也有自己的框架,就是libbpf。它通常以动态库 (libbpf.so) 或静态库 (libbpf.a) 的形式存在。已经写入了内核里面,提供一些遍历的接口。-
接下来举例说明
libbpf的便利性。






-
-
而
libbpf-bootstrap是大佬已经写好的项目。(https://github.com/libbpf/libbpf-bootstrap)-
安装说明
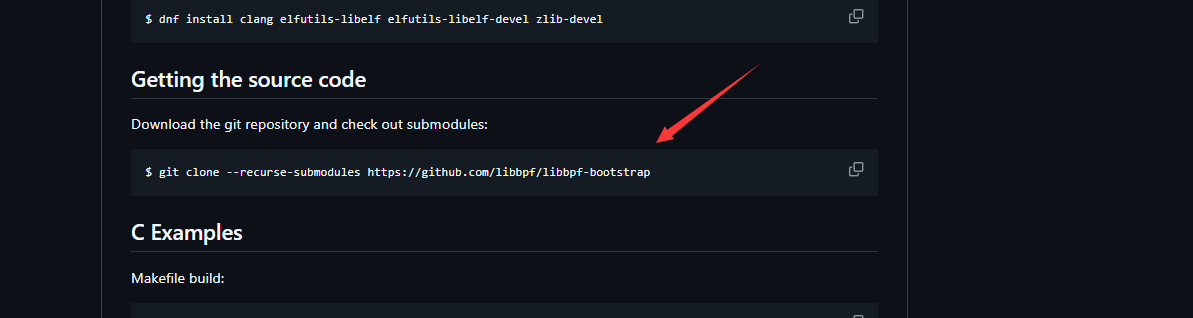
-
项目的意义?

-
上面已经说明了
libbpf-bootstrap写好了Makefile,把它复制到.c,'.bpf.c放在同一文件夹。注意Makefile下述5处修改的绝对地址。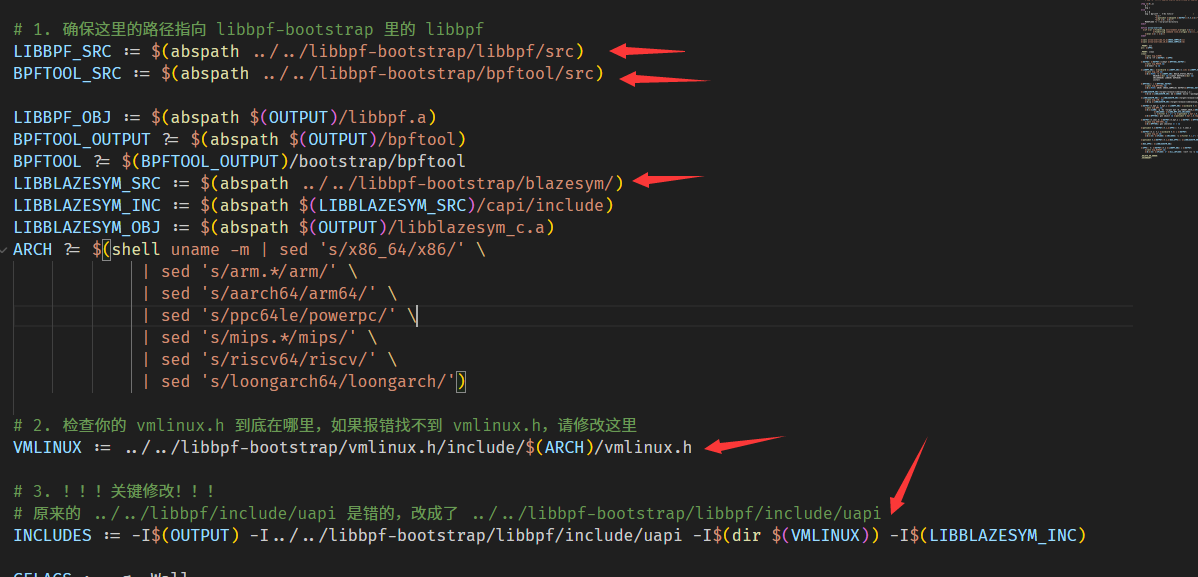
-
做好上述步骤,开发环境是能保证了,编写
.c和bpf.c即可。
-
hello
-
hello.c先来看一份标准开发的
.c文件(这个模板是libbpf-bootstrap项目的, 仅做了略微的修改)
// SPDX-License-Identifier: (LGPL-2.1 OR BSD-2-Clause)
/* Copyright (c) 2020 Facebook */
#include <stdio.h>
#include <unistd.h>
#include <sys/resource.h>
#include <bpf/libbpf.h>
#include "hello.skel.h"
static int libbpf_print_fn(enum libbpf_print_level level, const char *format, va_list args)
{
return vfprintf(stderr, format, args);
}
int main(int argc, char **argv)
{
struct hello_bpf *skel;
int err;
/* Set up libbpf errors and debug info callback */
libbpf_set_print(libbpf_print_fn);
/* Open BPF application */
skel = hello_bpf__open();
if (!skel) {
fprintf(stderr, "Failed to open BPF skeleton\n");
return 1;
}
/* ensure BPF program only handles write() syscalls from our process */
skel->bss->my_pid = getpid();
/* Load & verify BPF programs */
err = hello_bpf__load(skel);
if (err) {
fprintf(stderr, "Failed to load and verify BPF skeleton\n");
goto cleanup;
}
/* Attach tracepoint handler */
err = hello_bpf__attach(skel);
if (err) {
fprintf(stderr, "Failed to attach BPF skeleton\n");
goto cleanup;
}
printf("Successfully started! Please run `sudo cat /sys/kernel/debug/tracing/trace_pipe` "
"to see output of the BPF programs.\n");
for (;;) {
/* trigger our BPF program */
fprintf(stderr, ".");
sleep(1);
}
cleanup:
hello_bpf__destroy(skel);
return -err;
}
-
#include "hello.skel.h"- 只要你的
BPF源码叫xxx.bpf.c,bpftool就会给你生成xxx.skel.h。关于xxx.skel.h的作用,上文已经说过了。
- 只要你的
-
日志回调
static int libbpf_print_fn(...) { ... } libbpf_set_print(libbpf_print_fn);- 这就是为了让
libbpf库内部的报错信息(比如加载失败原因)能打印到你的屏幕上。这就好比开启Debug模式,几乎所有程序都会照抄这段。
- 这就是为了让
-
核心生命周期 (标准动作 - 三部曲)
-
解析
ELF文件,创建结构。skel = hello_bpf__open(); // 名字取决于文件名-
这里不是打开
.bpf.c编译后的.o文件,而是bpftool把hello.bpf.o变成了一个C语言数组(写在.skel.h里)。
-
-
把代码注入内核,通过验证器检查。
hello_bpf__load(skel); -
把程序挂钩到具体的事件上
hello_bpf__attach(skel);- 挂载的事件已经解析出来了。(
.bpf.c中的SEC说明挂载事件)
- 挂载的事件已经解析出来了。(
-
-
唯一的自定义逻辑
/* ensure BPF program only handles write() syscalls from our process */ skel->bss->my_pid = getpid();-
skel->bss->my_pid就是eBPF MAP里面的东西,因为我们在hello.bpf.c中定义了全局变量my_pid
-
Map是在内核里创建的,内核怎么知道你要一个什么样的Map(是哈希表还是数组?Key多大?Value多大?)全靠你在.bpf.c里的这份“说明书” 说明的。
-
-
保持运作 (标准动作)
for (;;) { fprintf(stderr, "."); // 触发 write 系统调用 sleep(1); }eBPF程序是事件驱动的。如果用户态进程退出了(.c文件结束),eBPF程序通常也会被卸载。所以这里必须有一个死循环(或者pause()),让进程不退出。
-
销毁动作
- 打扫战场,释放内存。
hello_bpf__destroy(skel);
hello.bpf.c
// SPDX-License-Identifier: GPL-2.0 OR BSD-3-Clause
/* Copyright (c) 2020 Facebook */
#include <linux/bpf.h>
#include <bpf/bpf_helpers.h>
char LICENSE[] SEC("license") = "Dual BSD/GPL";
int my_pid = 0;
SEC("tracepoint/syscalls/sys_enter_accept")
int handle_tp(void *ctx)
{
int pid = bpf_get_current_pid_tgid() >> 32;
char comm[16] = {0};
bpf_get_current_comm(&comm, sizeof(comm));
bpf_printk("accept from %s %d.\n", comm,pid);
return 0;
}
-
头文件
#include <linux/bpf.h> #include <bpf/bpf_helpers.h>-
<linux/bpf.h>: 这是Linux内核提供的标准头文件,里面定义了 BPF 所有的基础数据结构和枚举字典。` -
<bpf/bpf_helpers.h>: 这里面包含了bpf_printk、bpf_get_current_pid_tgid等helper function的声明。
-
-
许可证 (必须要写)
char LICENSE[] SEC("license") = "Dual BSD/GPL"; -
函数入口上下文(我觉得这里是最难理解的)
int handle_tp(void *ctx)-
结论:这个
void *ctx必须要写,但void*代表任意类型的指针,cxt代表上下文信息,它是抽象的表达,如果这里的参数写的不是void *ctx, 它写的是void *ctx具体的表达。 -
原因?

-
不同的场景,这些指针有不同的含义

-
-
测试结果



- 注意这里前后缀都有
networkio-23854, 前缀是内核自己的打印信息,后缀是在.bpf.c的中bpf_printk()打印。
- 注意这里前后缀都有
comm
-
comm.h#ifndef __COMM_H__ #define __COMM_H__ #define TASK_COMM_LEN 16 struct info { char comm[TASK_COMM_LEN]; int pid; }; #endif-
#ifndef __COMM_H__和#define __COMM_H__的作用
-
#define TASK_COMM_LEN 16
-
引用
.h文件,完全等同于把那个文件的所有代码,原封不动地抄写到你的.c文件里#include的那一行。
-
-
comm.bpf.c// SPDX-License-Identifier: GPL-2.0 OR BSD-3-Clause /* Copyright (c) 2020 Facebook */ #include <linux/bpf.h> #include <bpf/bpf_helpers.h> #include "comm.h" char LICENSE[] SEC("license") = "Dual BSD/GPL"; struct { __uint(type , BPF_MAP_TYPE_PERF_EVENT_ARRAY); //__uint是宏,相当于int (*name)(val),int型数组 __uint(key_size , sizeof(int)); __uint(value_size , sizeof(int)); } channel SEC(".maps"); SEC("tracepoint/syscalls/sys_enter_accept") int handle_tp(void *ctx) { struct info info = {0}; info.pid = bpf_get_current_pid_tgid() >> 32; bpf_get_current_comm(&info.comm, sizeof(info.comm)); bpf_perf_event_output(ctx, &channel, BPF_F_CURRENT_CPU , &info , sizeof(info)); return 0; }-
info.pid = bpf_get_current_pid_tgid() >> 32;-
bpf_get_current_pid_tgid(): 这是一个eBPF辅助函数。它返回一个u64类型的值。 -
高
32位是当前进程的PID。 -
低
32位是当前线程的TID。
-
-
-
对于
hello.bpf.c,comm.bpf.c主动定义了map -
对于
Map, 分为 "存储型Map" 和 "传输型Map"-
Map的定义有一套规范 (BTF-defined Maps~ 基于BTF定义的Map)。 -
以存储型
Map的模板举例// 定义你的哈希 Map struct { __uint(type, BPF_MAP_TYPE_HASH); __uint(key_size, sizeof(int)); // Key 是一个 int (用于存储 PID) __uint(value_size, sizeof(long long)); // Value 是一个 long long (用于存储计数) __uint(max_entries, 10240); // 最多可以存储 10240 条 Key-Value 对 } my_map SEC(".maps"); // Map 的名字是 my_map // 拦截 sys_enter_write 系统调用 SEC("tracepoint/syscalls/sys_enter_write") int handle_write_entry(void *ctx) { int key; // 用于查找和更新的 Key (PID) long long *value_ptr; // 指向 Map 中 Value 的指针 long long new_value; // 用于更新或插入的新 Value // 1. 获取 Key:当前进程的 PID // bpf_get_current_pid_tgid() 返回一个 u64,高 32 位是 tgid (线程组ID/PID),低 32 位是 pid (线程ID)。 // 这里我们用 PID 作为 Key key = bpf_get_current_pid_tgid() >> 32; // 获取 PID // 2. 调用 bpf_map_lookup_elem 查找 Map 中是否存在该 Key // 含义:内核大哥,帮我去哈希桶里找找,有没有这个 PID 的计数? // 如果找到,value_ptr 会指向 Map 中对应的 Value 的内存地址 // 如果没找到,value_ptr 会是 NULL value_ptr = bpf_map_lookup_elem(&my_map, &key); if (value_ptr) { // 2a. 找到了 Key (该 PID 已经调用过 write),将 Value 加一 // 注意:value_ptr 是一个指针,直接修改 *value_ptr 就是修改 Map 中的值 (*value_ptr)++; } else { // 2b. 没找到 Key (该 PID 第一次调用 write),将新的 Key-Value 对插入 Map // Value 初始化为 1 new_value = 1; // 含义:内核大哥,Map 里没有这个 PID,把它的计数设为 1 吧! // BPF_ANY: 如果 Key 存在则更新,不存在则插入 bpf_map_update_elem(&my_map, &key, &new_value, BPF_ANY); } return 0; } -
进阶写法
struct my_key { int pid; int uid; }; struct my_val { char comm[16]; int count; }; struct { __uint(type, BPF_MAP_TYPE_HASH); // 【变化在这里】:直接告诉内核,Key 是 struct my_key 结构体! // libbpf 会自动帮你计算 sizeof(struct my_key) __type(key, struct my_key); // 【变化在这里】:直接告诉内核,Value 是 struct my_val 结构体! __type(value, struct my_val); __uint(max_entries, 1024); } advanced_map SEC(".maps");
-
-
回到
comm.bpf.c中的Map定义,这是一个另类的传输型Map的定义struct { __uint(type , BPF_MAP_TYPE_PERF_EVENT_ARRAY); //__uint是宏,相当于int (*name)(val),int型数组 __uint(key_size , sizeof(int)); __uint(value_size , sizeof(int)); } channel SEC(".maps");-
BPF_MAP_TYPE_PERF_EVENT_ARRAY-
明确指定这是一个
perf_event类型的Map。这会告诉内核它不应该像哈希表那样进行Key-Value查找和存储,而是要为事件传输准备资源。 -
工作方式: 想象它是一个“消防水带”或“消息队列”。
eBPF程序通过一个特定的辅助函数 (bpf_perf_event_output) 将数据“灌入”这个水带,而用户态程序则通过轮询(perf_buffer__poll)来从水带的另一端“接收”这些数据。
-
-
__uint(key_size, sizeof(int));-
对于
BPF_MAP_TYPE_PERF_EVENT_ARRAY,key_size通常用来指定Map中的“槽位”(slot)或“数组索引”。最常见的情况是,这个key代表CPU ID。 -
为什么是
CPU ID? 为了实现高效的并发事件传输,每个CPU通常会有一个独立的perf_buffer。当eBPF程序在某个CPU上执行并通过bpf_perf_event_output发送事件时,它会使用当前CPU的ID作为 “Key”,将事件数据写入到该CPU对应的perf_buffer中。用户空间程序会收集所有CPU的数据。
-
-
__uint(value_size, sizeof(int));-
真实情况: 这个
value_size不限制你通过bpf_perf_event_output发送的实际数据的大小。你发送的数据大小是由bpf_perf_event_output函数的最后一个参数 (size) 决定的。 -
BPF_MAP_TYPE_PERF_EVENT_ARRAY的value_size是一个形式上的占位符,其值对事件传输的实际数据负载大小没有影响。
-
-
-
bpf_perf_event_output(ctx, &channel, BPF_F_CURRENT_CPU , &info , sizeof(info));-
这是
eBPF专门用于向BPF_MAP_TYPE_PERF_EVENT_ARRAY类型Map发送数据的辅助函数。 -
ctx: 再次传入上下文指针。eBPF运行时会利用它获取当前事件的元数据(如时间戳、CPU ID等),并将这些信息与你发送的数据一起封装。 -
&channel: 这是指向你定义的BPF_MAP_TYPE_PERF_EVENT_ARRAY类型Map的指针。它告诉内核应该通过哪个“通道”发送数据。 -
BPF_F_CURRENT_CPU: 这是一个标志。它指示bpf_perf_event_output将数据发送到当前CPU对应的perf_buffer中。这对于并发和性能很重要,因为每个CPU都有自己的独立缓冲区,可以减少锁竞争。 -
&info: 指向你要发送的实际数据负载的指针。这里就是你刚刚填充好的struct info变量 -
sizeof(info): 你要发送的数据负载的实际大小。注意,这个大小才是真正决定用户空间接收到的数据大小的,而不是channel Map定义中的value_size。 -
将当前进程的
PID和名称(存储在info结构中)封装成一个事件,并通过channel这个perf_event_array Map,异步地、高效地发送到用户空间程序。
-
-
return 0;- 标准的
eBPF程序返回码。0表示程序执行成功,没有错误。
- 标准的
-
comm.c// SPDX-License-Identifier: (LGPL-2.1 OR BSD-2-Clause) /* Copyright (c) 2020 Facebook */ #include <stdio.h> #include <unistd.h> #include <sys/resource.h> #include <bpf/libbpf.h> #include "comm.skel.h" #include "comm.h" //1. comm --> trace_pipe //2. send data from comm.bpf.c to comm.c int level = 3; #define DEBUF_LEVEL 5 void comm_handle_event(void *ctx, int cpu,void *data, __u32 size) { struct info *d = (struct info*)data; printf("%16s %d\n", d->comm,d->pid); } void comm_lost_event(void *ctx, int cpu, __u64 cnt) { printf("--> comm_lost_event\n"); } static int libbpf_print_fn(enum libbpf_print_level level, const char *format, va_list args) { if (level < DEBUF_LEVEL) return 0; return vfprintf(stderr, format, args); } int main(int argc, char **argv) { struct comm_bpf *skel; int err; /* Set up libbpf errors and debug info callback */ libbpf_set_print(libbpf_print_fn); /* Open BPF application */ skel = comm_bpf__open(); if (!skel) { fprintf(stderr, "Failed to open BPF skeleton\n"); return 1; } /* ensure BPF program only handles write() syscalls from our process */ //skel->bss->my_pid = getpid(); /* Load & verify BPF programs */ err = comm_bpf__load(skel); if (err) { fprintf(stderr, "Failed to load and verify BPF skeleton\n"); goto cleanup; } /* Attach tracepoint handler */ err = comm_bpf__attach(skel); if (err) { fprintf(stderr, "Failed to attach BPF skeleton\n"); goto cleanup; } // printf("Successfully started! Please run `sudo cat /sys/kernel/debug/tracing/trace_pipe` " // "to see output of the BPF programs.\n"); #if 0 for (;;) { /* trigger our BPF program */ fprintf(stderr, "."); sleep(1); } #else printf("%16s %s\n","comm","pid"); struct perf_buffer *pb = perf_buffer__new(bpf_map__fd(skel->maps.channel),8,comm_handle_event,comm_lost_event,NULL,NULL); if (!pb) { goto cleanup; } while(1) { perf_buffer__poll(pb,1000); } perf_buffer__free(pb); #endif cleanup: comm_bpf__destroy(skel); return -err; }
-
创建并初始化
perf_buffer,用于接收来自eBPF程序的事件// 创建并初始化 perf_buffer,用于接收来自 eBPF 程序的事件 struct perf_buffer *pb = perf_buffer__new( bpf_map__fd(skel->maps.channel), // 获取 channel Map 的文件描述符 8, // 每个 CPU 环形缓冲区的页数 (8 * 4KB = 32KB) comm_handle_event, // 事件处理回调函数,用于处理正常接收到的事件数据。 comm_lost_event, // 丢失事件回调函数,用于处理因缓冲区溢出而丢失的事件。 NULL, // 用户自定义上下文,这里为 NULL NULL // perf_buffer 选项,这里为 NULL ); -
comm_handle_event(事件处理回调函数) /comm_lost_event(丢失事件回调函数)void comm_handle_event(void *ctx, int cpu,void *data, __u32 size) { struct info *d = (struct info*)data; printf("%16s %d\n", d->comm,d->pid); } void comm_lost_event(void *ctx, int cpu, __u64 cnt) { printf("--> comm_lost_event\n"); }-
这些事件处理回调函数 (
comm_handle_event) 和丢失事件回调函数 (comm_lost_event) 的参数签名是由libbpf库严格规定好的。

-
-
轮询事件
while(1) { // 每隔 1000 毫秒 (1秒) 轮询一次 perf_buffer。 // 如果有事件到达,perf_buffer 会调用 comm_handle_event。 // 如果有事件丢失,perf_buffer 会调用 comm_lost_event。 perf_buffer__poll(pb, 1000); }
-
结果

sock
-
sock,h#ifndef __COMM_H__ #define __COMM_H__ #define TASK_COMM_LEN 16 #define MAX_BUF_SIZE 32 struct info { char comm[TASK_COMM_LEN]; int pid; }; struct sock_event { __u32 src_addr; __u32 dst_addr; __u16 src_port; __u16 dst_port; __u16 payload_length; __u16 pkt_type; __u8 payload[MAX_BUF_SIZE]; }; #endif- 这里没什么好说的,更之前的
.h差不多。
- 这里没什么好说的,更之前的
-
sock.bpf.c// SPDX-License-Identifier: GPL-2.0 OR BSD-3-Clause /* Copyright (c) 2020 Facebook */ #include <stddef.h> #include <linux/bpf.h> #include <linux/if_ether.h> #include <linux/ip.h> #include <linux/in.h> #include <linux/socket.h> #include <bpf/bpf_helpers.h> #include <bpf/bpf_endian.h> #include "sock.h" char LICENSE[] SEC("license") = "Dual BSD/GPL"; #define ETH_HDR_LEN 14 struct { __uint(type , BPF_MAP_TYPE_PERF_EVENT_ARRAY); //__uint是宏,相当于int (*name)(val),int型数组 __uint(key_size , sizeof(int)); __uint(value_size , sizeof(int)); } channel SEC(".maps"); struct { __uint(type , BPF_MAP_TYPE_RINGBUF); __uint(max_entries , 256 * 1024); } ringbuffer SEC(".maps"); //http //ethhdr + iphdr + tcphdr --> http content SEC("socket") int sock_event_handler(struct __sk_buff *skb) { //__sk_buff 指向 http 的原数据 __u16 proto; //以太网 bpf_skb_load_bytes(skb, 12, &proto , sizeof(__u16)); //bpf helper function proto = __bpf_ntohs(proto); //网络字节序 --> 本地字节序 // bpf_printk("sock_event_handler --> %x, %x\n",proto,ETH_P_IP); if (proto != ETH_P_IP) { return 0; } //ip //必须判断 ip 是否分片 __u16 frag_off; bpf_skb_load_bytes(skb , ETH_HDR_LEN + 6 , &frag_off , sizeof(__u16)); //第二个参数单位是字节,可以看图片计算 frag_off = __bpf_ntohs(frag_off); // bpf_printk("sock_event_handler --> %x\n",frag_off,ETH_P_IP); if (frag_off & 0x3fff) { // fragment return 0; } __u8 verlen; bpf_skb_load_bytes(skb , ETH_HDR_LEN , &verlen , sizeof(__u8)); verlen &= 0x0F; //不要版本号,只要首部长度。 verlen *= 4; //ip头的长度,这里要乘4 //ip totlen __u16 totlen; bpf_skb_load_bytes(skb , ETH_HDR_LEN + 2 , &totlen , sizeof(__u16)); //第二个参数单位是字节,可以看图片计算 totlen = __bpf_ntohs(totlen); //ip type __u8 type; bpf_skb_load_bytes(skb , ETH_HDR_LEN + 9 , &type , sizeof(__u8)); //bpf_skb_load_bytes(skb , ETH_HDR_LEN , ) //tcp __u8 tcphdrlen; bpf_skb_load_bytes(skb , ETH_HDR_LEN + verlen + 12 , &tcphdrlen , sizeof(__u8)); tcphdrlen &= 0xF0; tcphdrlen >>= 4; tcphdrlen *= 4; //http __u16 payload_offset = ETH_HDR_LEN + verlen + tcphdrlen; __u16 payload_length = totlen - verlen - tcphdrlen; char line_buffer[32]; bpf_skb_load_bytes(skb,payload_offset,line_buffer,32); #if 0 if (bpf_strncmp(line_buffer,3,"GET") != 0 && bpf_strncmp(line_buffer,4,"POST") != 0) { return 0; } //bpf_printk("--> %s\n",line_buffer); #endif //这里不用定义好的 channel 进行map共享,用另外的方式 __u16 src_port,dst_port; bpf_skb_load_bytes(skb,ETH_HDR_LEN + verlen, &src_port,2); bpf_skb_load_bytes(skb,ETH_HDR_LEN + verlen + 2 , &dst_port,2); src_port = __bpf_ntohs(src_port); dst_port = __bpf_ntohs(dst_port); if (src_port == 22 || dst_port == 22) { return 0; } struct sock_event *event = bpf_ringbuf_reserve(&ringbuffer , sizeof(struct sock_event) , 0); if (!event) { return 0; } event->payload_length = payload_length; event->pkt_type = skb->pkt_type; bpf_skb_load_bytes(skb,ETH_HDR_LEN + 12 , &event->src_addr , 4); bpf_skb_load_bytes(skb,ETH_HDR_LEN + 16 , &event->dst_addr , 4); bpf_skb_load_bytes(skb,payload_offset, event->payload, MAX_BUF_SIZE); bpf_skb_load_bytes(skb,ETH_HDR_LEN + verlen, &event->src_port,2); bpf_skb_load_bytes(skb,ETH_HDR_LEN + verlen + 2 , &event->dst_port,2); bpf_ringbuf_submit(event , 0); return 0; }
-
Map定义部分struct { __uint(type , BPF_MAP_TYPE_PERF_EVENT_ARRAY); //__uint是宏,相当于int (*name)(val),int型数组 __uint(key_size , sizeof(int)); __uint(value_size , sizeof(int)); } channel SEC(".maps"); struct { __uint(type , BPF_MAP_TYPE_RINGBUF); __uint(max_entries , 256 * 1024); } ringbuffer SEC(".maps");-
ringbuffer-
BPF_MAP_TYPE_RINGBUF: 这明确指定了Map的类型是一个环形缓冲区(Ring Buffer)。-
用途: 环形缓冲区是
eBPF内核程序向用户空间高效、低延迟、多生产者-单消费者(MPSC)或多生产者-多消费者(MPMC)传输事件数据的首选机制。 -
特点:

-
-
__uint(max_entries , 256 * 1024);
-
-
为啥选择用
ringbuffer
-
-
奇怪的挂载点
sock
-
struct __sk_buff *skb参数-
这是
BPF_PROG_TYPE_SOCKET_FILTER类型程序所期望的输入参数。 -
skb (socket kernel buffer)是Linux内核中用于表示网络数据包的核心数据结构。 -
struct __sk_buff *skb指向的就是原始的网络数据包数据,你的代码中通过bpf_skb_load_bytes等helper函数来解析以太网头、IP头、TCP头,并最终提取HTTP负载。
-
-
接下来是网络包的解析
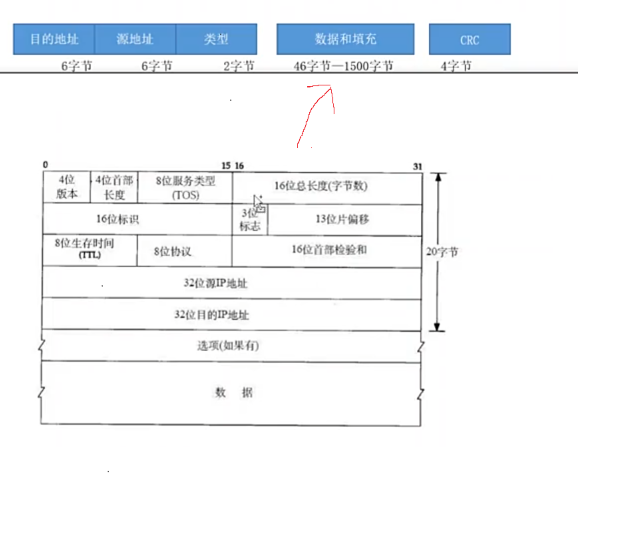

-
“选项(如果有)” 下面的 “数据”:整个
TCP报文段(TCP Header+ 应用层数据)。 -
下面的图片是
TCP Header。
-
-
以太网获取
__u16 proto; // 声明一个无符号16位整数变量来存储协议类型 //以太网 bpf_skb_load_bytes(skb, 12, &proto , sizeof(__u16)); // 从skb中加载数据 proto = __bpf_ntohs(proto); // 将网络字节序转换为本地字节序 if (proto != ETH_P_IP) { // 如果协议类型不是 IPv4 return 0; // 则返回0,表示丢弃该数据包 }
-
读取分片信息
bpf_skb_load_bytes(skb , ETH_HDR_LEN + 6 , &frag_off , sizeof(__u16));- 看图就好了,读取的是 “
3位标志” + “13为片便宜”
if (frag_off & 0x3fff) { // fragment return 0; }
- 看图就好了,读取的是 “
-
获取首部长度
注意这个长度指得是 “
20个字节” + 选项(如果有)__u8 tcphdrlen; bpf_skb_load_bytes(skb , ETH_HDR_LEN + verlen + 12 , &tcphdrlen , sizeof(__u8)); tcphdrlen &= 0xF0; tcphdrlen >>= 4; tcphdrlen *= 4;*4细节:TCP协议规定:Data Offset字段的值表示的是TCP头部包含多少个32位字(4字节为单位)。
-
totlen: 整个 “数据与填充” 的长度 -
type:type变量代表的是IP数据包中封装的下一层协议类型。
-
tcphdrlen: 存储TCP头部在当前数据包中的实际字节长度。 -
payload_offset:TCP头部结束的位置,也就是TCP负载(应用层数据)的开始位置。 -
payload_length:TCP负载(应用层数据)的实际长度。 -
ringbuffer的使用

-
sock.c// SPDX-License-Identifier: (LGPL-2.1 OR BSD-2-Clause) /* Copyright (c) 2020 Facebook */ #include <stdio.h> #include <unistd.h> #include <sys/resource.h> #include <bpf/libbpf.h> #include <linux/if_packet.h> #include <linux/if_ether.h> #include <arpa/inet.h> #include <net/if.h> #include "sock.skel.h" #include "sock.h" //1. sock --> trace_pipe //2. send data from sock.bpf.c to sock.c int level = 6; #define DEBUF_LEVEL 5 #if 0 void sock_handle_event(void *ctx, int cpu,void *data, __u32 size) { struct info *d = (struct info*)data; printf("%16s %d\n", d->comm,d->pid); } #else static inline void ltoa(uint32_t addr, char *dst) { snprintf(dst, 16, "%u.%u.%u.%u", (addr >> 24) & 0xFF, (addr >> 16) & 0xFF, (addr >> 8) & 0xFF, (addr & 0xFF)); } int sock_handle_event(void *ctx,void *data,size_t size) { struct sock_event *d = (struct sock_event*)data; char sstr[16] = {}, dstr[16] = {}; ltoa(ntohl(d->src_addr), sstr); ltoa(ntohl(d->dst_addr), dstr); printf("%16s:%d %16s:%d %s\n", sstr,ntohs(d->src_port),dstr,ntohs(d->dst_port),d->payload); return 0; } #endif void sock_lost_event(void *ctx, int cpu, __u64 cnt) { printf("--> sock_lost_event\n"); } static int libbpf_print_fn(enum libbpf_print_level level, const char *format, va_list args) { if (level < DEBUF_LEVEL) return 0; return vfprintf(stderr, format, args); } int open_raw_sock(const char *name) { int fd = socket(PF_PACKET , SOCK_RAW | SOCK_NONBLOCK , htons(ETH_P_ALL)); if (fd < 0) { return -1; } struct sockaddr_ll sll; memset(&sll , 0 , sizeof(sll)); sll.sll_family = AF_PACKET; sll.sll_ifindex = if_nametoindex(name); sll.sll_protocol = htons(ETH_P_ALL); if (bind(fd, (struct sockaddr*)&sll , sizeof(sll)) < 0) { close(fd); return -1; } return fd; } int main(int argc, char **argv) { struct sock_bpf *skel; int err; /* Set up libbpf errors and debug info callback */ libbpf_set_print(libbpf_print_fn); /* Open BPF application */ skel = sock_bpf__open(); if (!skel) { fprintf(stderr, "Failed to open BPF skeleton\n"); return 1; } /* ensure BPF program only handles write() syscalls from our process */ //skel->bss->my_pid = getpid(); /* Load & verify BPF programs */ err = sock_bpf__load(skel); if (err) { fprintf(stderr, "Failed to load and verify BPF skeleton\n"); goto cleanup; } #if 1 int fd = open_raw_sock("wlp0s20f3"); if (fd < 0) { fprintf(stderr, "Failed to open raw sock\n"); goto cleanup; } int prog_fd = bpf_program__fd(skel->progs.sock_event_handler); if (0 != setsockopt(fd , SOL_SOCKET , SO_ATTACH_BPF , &prog_fd , sizeof(prog_fd))) { fprintf(stderr, "Failed to set sock option\n"); goto cleanup; } #else /* Attach tracepoint handler */ err = sock_bpf__attach(skel); if (err) { fprintf(stderr, "Failed to attach BPF skeleton\n"); goto cleanup; } #endif // printf("Successfully started! Please run `sudo cat /sys/kernel/debug/tracing/trace_pipe` " // "to see output of the BPF programs.\n"); #if 0 for (;;) { /* trigger our BPF program */ fprintf(stderr, "."); sleep(1); } #elif 0 // printf("%16s %s\n","sock","pid"); struct perf_buffer *pb = perf_buffer__new(bpf_map__fd(skel->maps.channel),8,sock_handle_event,sock_lost_event,NULL,NULL); if (!pb) { goto cleanup; } while(1) { perf_buffer__poll(pb,1000); } perf_buffer__free(pb); #else struct ring_buffer *rb = ring_buffer__new(bpf_map__fd(skel->maps.ringbuffer), sock_handle_event , NULL , NULL); if (!rb) { goto cleanup; } while(1) { ring_buffer__poll(rb,1000); } ring_buffer__free(rb); #endif cleanup: sock_bpf__destroy(skel); return -err; }
-
open_raw_sock解析int open_raw_sock(const char *name) { // 1. 创建原始套接字 int fd = socket(PF_PACKET, SOCK_RAW, SOCK_NONBLOCK, htons(ETH_P_ALL)); if (fd < 0) { return -1; // 创建失败,返回-1 } // 2. 准备套接字地址结构体,用于绑定到特定网络接口 struct sockaddr_ll sll; // sockaddr_ll 是用于底层链路层原始套接字的地址结构 memset(&sll, 0, sizeof(sll)); // 清零,确保所有字段都初始化 sll.sll_family = AF_PACKET; // 地址族:用于链路层数据包 sll.sll_ifindex = if_nametoindex(name); // 将接口名称(如 "eth0")转换为对应的索引号 sll.sll_protocol = htons(ETH_P_ALL); // 协议:捕获所有以太网协议类型的数据包 (htons 用于网络字节序转换) // 3. 将套接字绑定到指定的网络接口 if (bind(fd, (struct sockaddr*)&sll, sizeof(sll)) < 0) { close(fd); // 绑定失败,关闭套接字 return -1; // 返回-1 } return fd; // 成功创建并绑定套接字,返回文件描述符 }
-
调用
open_raw_sock和附加eBPF程序// 1. 调用 open_raw_sock 创建并绑定原始套接字 int fd = open_raw_sock("wlp0s20f3"); // 假设网络接口名称为 "wlp0s20f3" if (fd < 0) { fprintf(stderr, "Failed to open raw sock\n"); // 如果失败,打印错误信息 goto cleanup; // 跳转到错误处理标签 } // 2. 获取 eBPF 程序的描述符 int prog_fd = bpf_program__fd(skel->progs.sock_event_handler); // 这里假设 skel 是 bpf_skeleton 的一个实例,通过 bpf_skeleton 加载了 eBPF 程序。 // skel->progs.sock_event_handler 会返回名为 sock_event_handler 的 eBPF 程序的 文件描述符。 // 3. 将 eBPF 程序附加到原始套接字 if (0 != setsockopt(fd, SOL_SOCKET, SO_ATTACH_BPF, &prog_fd, sizeof(prog_fd))) { fprintf(stderr, "Failed to set sock option\n"); // 附加失败,打印错误信息 goto cleanup; // 跳转到错误处理标签 }
-
ltoa函数解析static inline void ltoa(uint32_t addr, char *dst) { snprintf(dst, 16, "%u.%u.%u.%u", (addr >> 24) & 0xFF, (addr >> 16) & 0xFF, (addr >> 8) & 0xFF, (addr & 0xFF)); }- 这个函数将一个
32位无符号整数(通常代表一个IPv4地址)转换为其标准的点分十进制字符串表示。
- 这个函数将一个
-
结果


 浙公网安备 33010602011771号
浙公网安备 33010602011771号