


目标检测相关资料整理 4
一、 RCNN
论文:《Rich feature hierarchies for accurate object detection and semantic segmentation》
论文地址:http://www.cs.berkeley.edu/~rbg/#girshick2014rcnn
项目地址:https://github.com/rbgirshick/rcnn
论文翻译:https://www.cnblogs.com/xiaotongtt/p/6691103.html
R-CNN可以说是利用深度学习进行目标检测的开山之作。作者Ross Girshick多次在PASCAL VOC的目标检测竞赛中折桂,曾在2010年带领团队获得终身成就奖。
网络中的亮点:
R-CNN概括起来就是selective search+CNN+L-SVM的检测器
1 用selective search代替传统的滑动窗口,提取出2k个候选region proposal
2 对于每个region,用摘掉了最后一层softmax层的AlexNet来提取特征
3 训练出来K个L-SVM作为分类器(每个目标类一个SVM分类器,K目标类个数),使用AlexNet提取出来的特征作为输出,得到每个region属于某一类的得分。
4 最后对每个类别用NMS(non-maximum-suppression)来舍弃掉一部分region,得到detection的结果(对得到的结果做针对boundingbox回归,用来修正预测的boundingbox的位置)。
网络结构:
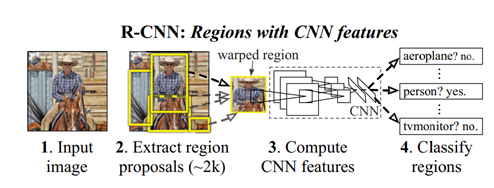

综述:
Ross Girshick(2014)利用selective search方法、深度网络、L-SVM和NMS方法,构建RCNN网络。实现了mAP的大幅度改进,从35.1%到43.5%的mAP,同时也快得多,在VOC 2011/12测试中达到类似的性能,mAP为43.2%。
二、 Fast-RCNN
论文:《Fast R-CNN》
Fast R-CNN是作者Ross Girshick继R-CNN后的又一力作。同样使用VGG16作为网络的backbone,与R-CNN相比训练时间快9倍,测试推理时间快213倍,准确率从62%提升至66%(再Pascal VOC数据集上)。
R-CNN存在以下几个问题:1、训练繁琐。2、时间和内存消耗比较大。3、测试的时候较慢。
网络中的亮点:
1 一张图像生成1K~2K个候选区域(使用Selective Search方法)
2 将图像输入网络得到相应的特征图,将SS算法生成的候选框投影到特征图上获得相应的特征矩阵
3 将每个特征矩阵通过ROI pooling层缩放到7x7大小的特征图,接着将特征图展平通过一系列全连接层得到预测结果
网络结构:
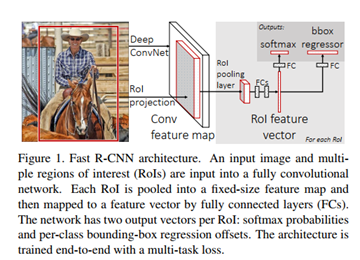

综述:
Ross Girshick(2015)利用ROI pooling层和边界框回归器,对RCNN进行优化,提出Fast-RCNN网络,基于VGG16的Fast RCNN算法在训练速度上比RCNN快了将近9倍,比SPPnet快大概3倍;测试速度比RCNN快了213倍,比SPPnet快了10倍,在VOC2012上的mAP在66%左右。
三、 Faster-RCNN
论文:《Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks》
论文:https://arxiv.org/abs/1506.01497
Faster R-CNN是作者Ross Girshick继Fast R-CNN后的又一力作。同样使用VGG16作为网络的backbone,推理速度在GPU上达到5fps(包括候选区域的生成),准确率也有进一步的提升。在2015年的ILSVRC以及COCO竞赛中获得多个项目的第一名。
网络中的亮点:
- 将图像输入网络得到相应的特征图。
- 使用RPN结构生成候选框,将RPN生成的候选框投影到特征图上获得相应的特征矩阵。
- 将每个特征矩阵通过ROI pooling层缩放到7x7大小的特征图,接着将特征图展平通过一系列全连接层得到预测结果.
网络结构:
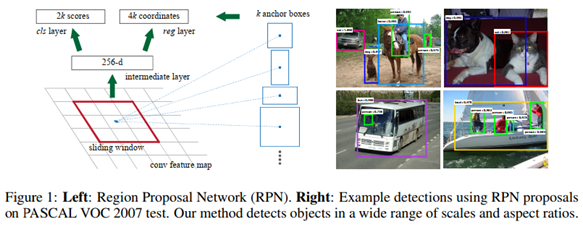
综述:
Shaoqing Ren(2016)运用RPN结构对Fast R-CNN进行优化,提出了Faster R-CNN框架,使用VGG16作为网络的backbone,推理速度在GPU上达到5fps(包括候选区域的生成),准确率也有进一步的提升。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号