


图像分类相关资料整理 3
七、ShuffleNet v1、ShuffleNet v2
论文:《ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices》
https://arxiv.org/pdf/1707.01083.pdf
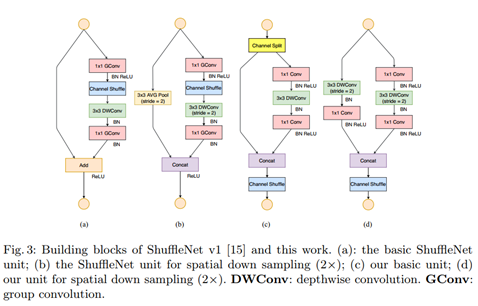
作者发现,一些state-of-the-art的模型架构,如Xception、ResNeXt等,使用在小型网络模型中效率都比较低。这是因为使用大量1×1卷积会消耗大量计算资源。为此,提出了pointwise group convolution来减少计算复杂度。
Group convolution是将输入层的不同特征图进行分组,然后采用不同的卷积核再对各个组进行卷积,这样会降低卷积的计算量。因为一般的卷积都是在所有的输入特征图上做卷积,可以说是全通道卷积,这是一种通道密集连接方式(channel dense connection),而group convolution相比则是一种通道稀疏连接方式(channel sparse connection)
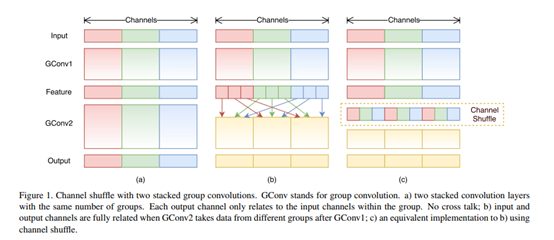
使用组卷积也会带来一些副作用,因为组卷积切断了组内通道与组外通道之间的联系,仅仅能从组内通道提取特征信息。为此,论文中又提出了channel shuffle,来帮助信息在各通道之间流通。
网络中的亮点:
轻量级,快
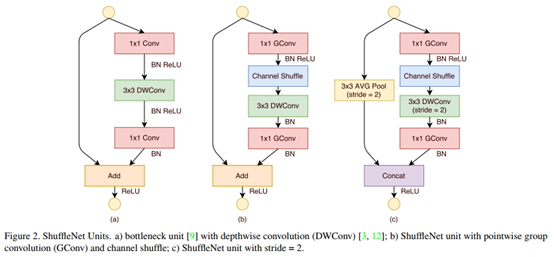
提出了channel shuffle的思想,ShuffleNet Unit中全是GConv和DWConv。
问题:GConv虽然能够减少参数与计算量,但GConv中不同组之间信息没有交流。
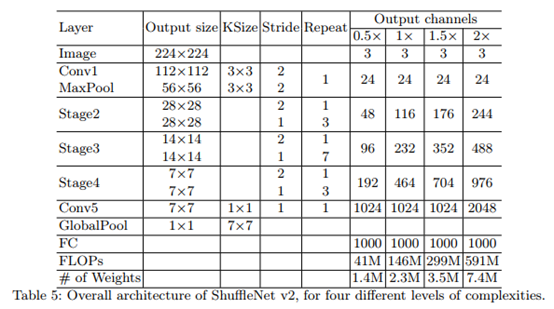
网络结构:
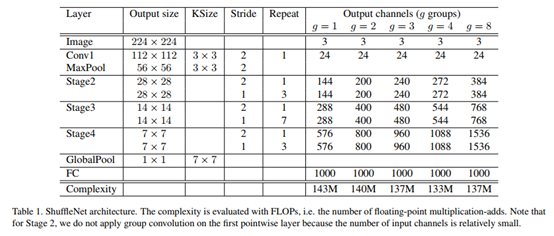
综述:
Xiangyu Zhang(2017)提出了pointwise group convolution进而提出channel shuffle思想,来搭建shufflenet v1结构,保持精度的同时又减少计算复杂度,从而实现了轻量级网络的搭建。
论文:《ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design》
https://pan.baidu.com/s/1so7aD3hLKO-0PB8h4HWliw

FLOPs间接指标,一般我们看速度,影响速度的指标中,比较重要的有:MAC内存访问时间成本;并行等级;平台。
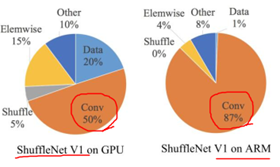
- 卷积层的输入和输出特征通道数相等时MAC最小,此时模型速度最快。
- 过多的group操作会增大MAC,从而使模型速度变慢。
- 模型中的分支数量越少,模型速度越快。
- element-wise操作所带来的时间消耗远比在FLOPs上的体现的数值要多,因此要尽可能减少element-wise操作。
网络中的亮点:
- 计算复杂度不能只看FLOPs
- 提出4条设计高效网络准则
- 提出新的block设计
网络结构:
综述:
Ningning Ma(2018)运用数学推理和理论,分析了模型运行时间的影响因素,根据影响时间的因素,对设计高性能框架提出了四方面建议:使用输入通道和输出通道相同的卷积操作;谨慎使用分组卷积;减少网络分支数;减少element-wise操作。
八、EfficientNet、EfficientNet V2
论文:《EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks》
https://arxiv.org/abs/1905.11946
https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
ICML 2019
在论文中提到,本文提出的EfficientNet-B7在Imagenet top-1上达到了当年最高准确率84.3%,与之前准确率最高的GPipe相比,参数数量仅为其1/8.4,理速度提升了6.1倍。
网络中的亮点:
同时探索输入分辨率,网络的深度、宽度的影响。
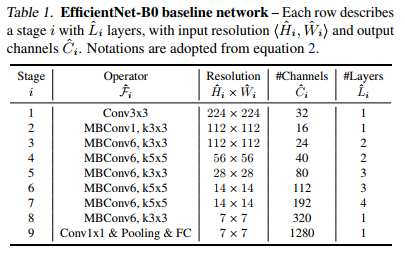
网络结构:
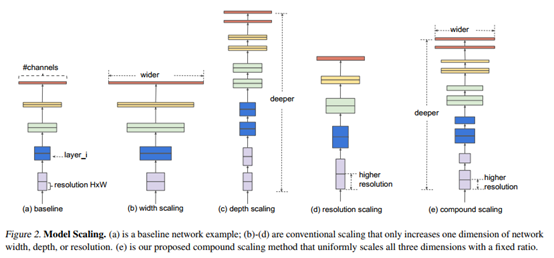
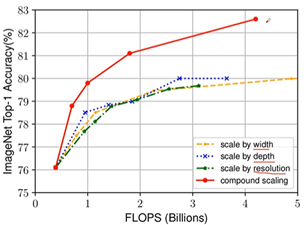
图a,传统的网络;图b,在基准网络a上,增加了宽度即channel;图c,在基准网络a上,增加了深度,layer更多了;图d,在基准网络a上,增加了分辨率,每个特征矩阵高和宽也会增加。图e,同时增加这三个。
1、根据以往的经验,增加网络的深度depth能够得到更加丰富、复杂的特征并且能够很好的应用到其它任务中。但网络的深度过深会面临梯度消失,训练困难的问题。
2、增加网络的width能够获得更高细粒度的特征并且也更容易训练,但对于width很大而深度较浅的网络往往很难学习到更深层次的特征。
3、增加输入网络的图像分辨率能够潜在得获得更高细粒度的特征模板,但对于非常高的输入分辨率,准确率的增益也会减小。并且大分辨率图像会增加计算量。
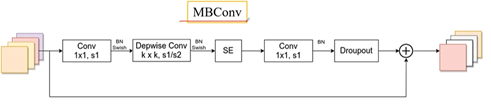
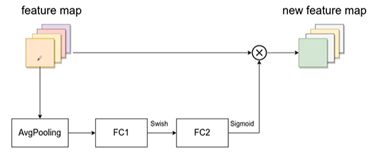
SE模块
综述:
Mingxing Tan(2019)研究了网络框架的深度、宽度和分辨率带来的影响,提出了一种缩放方法,并运用网络搜索设计了EfficientNets网络框架,实验结果,在ImageNet上达到了最先进的84.3%的top-1精度,而在推理上比现有最好的ConvNet小8.4倍,快6.1倍。我们的EfficientNets也可以在CIFAR-100(91.7%)、Flowers(98.8%)和其他3个传输学习数据集上实现良好的传输,且参数更少。
论文:《EfficientNetV2: Smaller Models and Faster Training》
https://arxiv.org/abs/2104.00298
https://github.com/google/automl/tree/master/efficientnetv2
本文是谷歌的MingxingTan与Quov V.Le对EfficientNet的一次升级,旨在保持参数量高效利用的同时尽可能提升训练速度。在EfficientNet的基础上,引入了Fused-MBConv到搜索空间中;同时为渐进式学习引入了自适应正则强度调整机制。两种改进的组合得到了本文的EfficientNetV2,它在多个基准数据集上取得了SOTA性能,且训练速度更快。比如EfficientNetV2取得了87.3%的top1精度且训练速度快5-11倍。
问题:占GPU显存。
网络中的亮点:
- 提出一类更小、更快的卷积神经网络EfficientNetV2。受益于训练感知NAS与缩放,EfficientNetV2在训练速度与参数量方面显著优于其他方案;
- 提出一种改进版渐进学习策略,它可以自适应的随图像大小而调整正则化因子。它可以在加速训练的同时提升精度;
- 所提方案在ImageNet、CIFAR、Cars、Flowers等数据集上取得了11x更快的训练速度,6.8x更少的参数量。
网络结构:
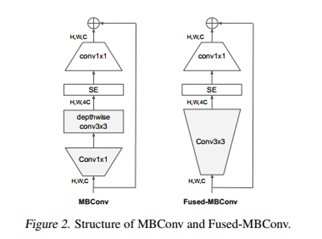
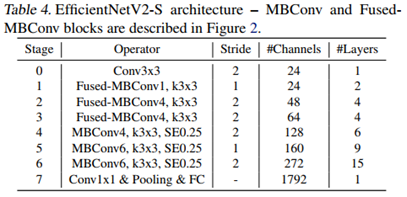
综述:
Mingxing Tan(2021)利用训练感知神经结构搜索和缩放方法,构建了EfficientNetV2模型,实验分析,EfficientNetV2在ImageNet ILSVRC2012上达到了87.3%的top-1准确率,并且比最近的ViT准确率高出2.0%。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号