

机器学习-监督与非监督学习
监督学习:
给定一个包含正确答案的数据集,也就是给定一个实际发生的真实地数据集,通过此数据集预测出另一个参数对应的正确答案。
回归问题,即有连续的预测数值输出。例:房价与面积关系。
分类问题,预测离散值输出。例:肿瘤是良性还是恶性。
监督学习:结构化信息即有定义的信息如年龄面积广告数等。
无监督学习
非结构化信息即如音频视频图片文字等计算机难理解的数据,但人类对他们很理解,所以有了神经网络。
数据集没有标签,或都具有相同标签,我们不知道数据集是什么,用来干什么,能在其中自动找到某种结构吗?无监督算法可能判定数据集包含不同的簇,即聚类算法,例:谷歌新闻每天网络上收集几万条新闻将它们分成不同的专题,不断点击可以进入越来越深层新闻。
用途:
组织大型的计算机集群;社交网络的分析,可得知联系最多的人,判断是否认识;天文数据分析,带来星系形成理论。
人声与音乐色混合录制音频,录制两个,交给计算机处理,它会告知我们有两个音频源,并分别提取出来。实现这个功能并没有我们想得那么难,实际只需要一行代码:(当然这个公式的出现费了研究员很长时间)
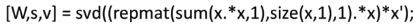
Octave软件,matlab,许多算法可以用几行代码表示。先octave建立软件原型,可以工作后再迁移到其他编译环境,更快。只用c++或java,python则需要很多步骤。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号