

神经网络
人工神经网络与生物神经网络区别:
所有生物元之间的连接都是不可更换的,所以人工神经网络里没有凭空产生新连接这回事.他所做的就是:已经知道吃糖这件事,让神经网络帮助我们做拿糖果这件事.预先准备好许多吃糖的数据,,将之套入神经网络系统,,然后糖的信号传递到手,对比观察手的动作是否是讨糖的动作,据此修改神经元强度,这种修改的操作叫做”误差反向传递”.也就是将传过来的信号反馈回去让神经元反思修正,看是否对讨糖的动作又没有贡献.
不同于生物神经网络,人工神经网络靠的是正向和反向传播来更新神经元,从而优化模型,得到更好的神经系统.他的本质是一个能让计算机处理和优化的数学模型.
生物神经网络是通过刺激产生新的信号连接,信号通过新连接传递而形成反馈.但记忆的形成还是个谜.
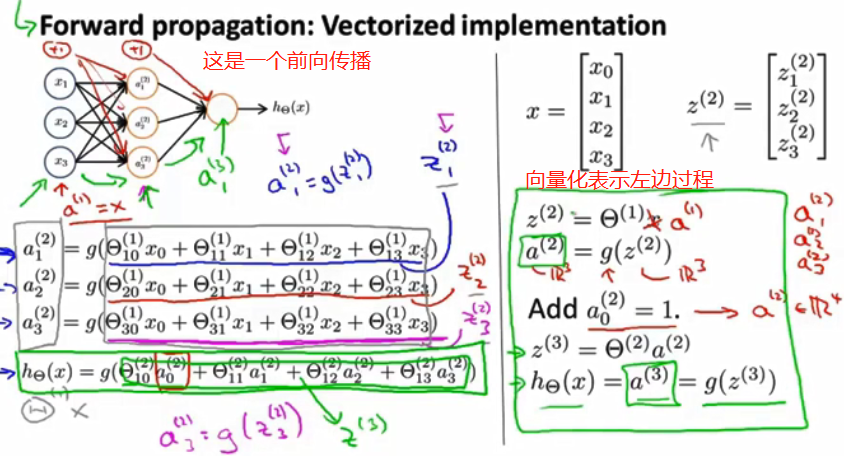
神经网络: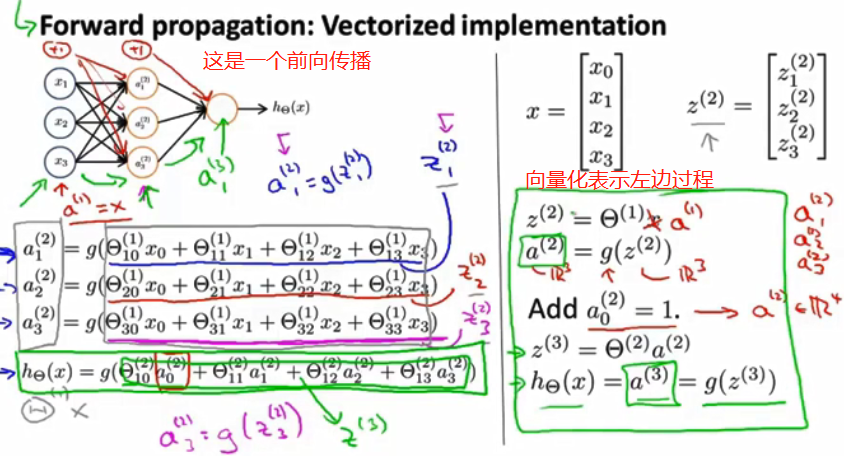
是一基于统计学的数据建模工具.用来对输入和输出间复杂的关系进行建模,或探究数据模式.可以不断训练.
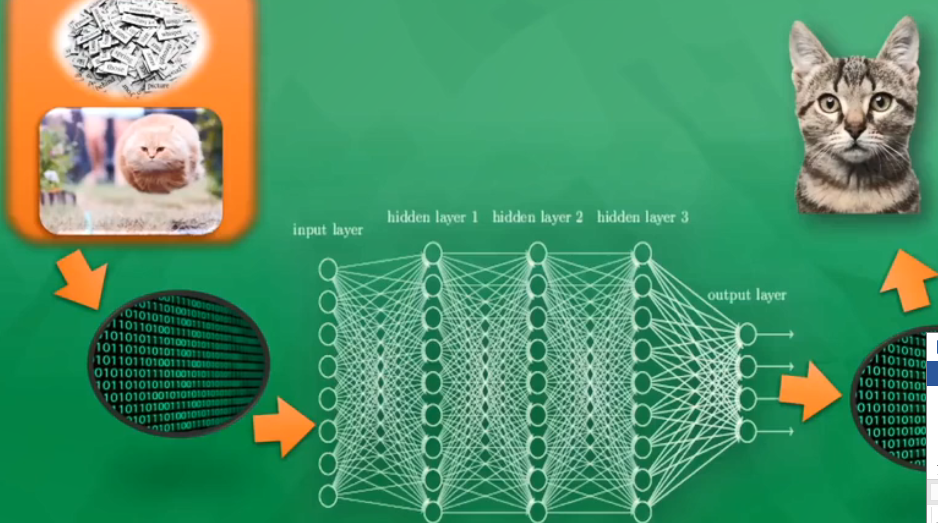
输入层是直接接收信息的神经层,负责传递接收到的信息.
输出层是信息在神经元链接中传递.中转,分析,权衡,形成输出结果,看出计算机对事物的认知.
两层之间是隐藏层,由众多神经元和链接组成,加工处理输入信息.
计算机内部对所有事物的存储是0和1.
怎么训练?
许多许多带有猫狗标签的数据,给计算机看图,返回一个不准确答案,将错误当成经验学习,(怎么学习经验?)通过对比预测答案与真实答案区别,将差别再反方向传递回去,对每一个神经元,往正确的方向上改动一点点,积少成多,识别正确率不断提高.
神经网络怎么训练神经元?
计算机里每一个神经元都有属于它的激励函数,用函数给计算机一个刺激行为.刚开始给计算机一个图,部分神经元被激励,被激活的神经元传递下去的信息是计算机最重视的信息,也是对输出结果最有价值的信息.当结果出错,则神经元参数会改变,变得对图片里真正重要信息敏感.
神经网络黑盒(深入理解):
常有人将神经网络称为黑盒,因为不知道里面是怎么处理的,也就是隐藏层.
深入理解也就是提取多层特征,一个隐藏层一个特征,用这些特征可以区分出最后结果
黑是因为人看不懂特征而以,但计算机可以.根据此原理,很多人研究更高级神经网络,如迁移学习.
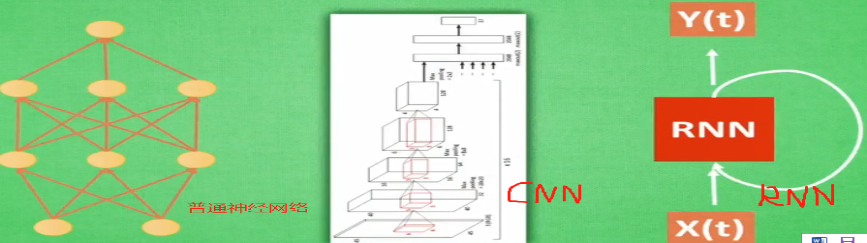
神经网络架构:神经网络中神经元的连接方式。
什么是神经网络进化?
什么是遗传算法?DNA基因会遗传给后代,还会变异一些基因.即: 结合父母的两个神经网络生成宝宝的神经网络,然后变异,将所有宝宝放到自然环境中,适者生存.
什么是进化策略?适者生存,不适者淘汰.DNA若用实数表示,则进化DNA,也能遗传,正态分布产生一个近似数当作变异. 遗传给后代的信息有: 所有数的均值与均值的变异强度.则可在实数范围内进行变异了. 即: 先固定网络结构,然后让它产卵,,产生很多与它结构相同但连接强度不同的宝宝,宝宝肯定有好有坏,下一代的爸爸是所有宝宝的综合体, 其中好宝宝占的比例多,让好宝宝逐渐占领主场.
但图片识别中,进化策略还比不上梯度策略的宝宝.因为:梯度只有一个点,直接划到最小方就是最优解,但进化策略有好多点,下一点的位置由原来好多点来定,即要产生好多新网络,比梯度慢很多,但有一个好处,就是避免了局部最优解,因为宝宝可以随时跳出局部最优.同时进化策略还可用来进行强化学习.合理利用此方法会速度快很多.
怎么检验神经网络?
训练数据一般70%,测试数据30%.检验结果主要看测试数据.
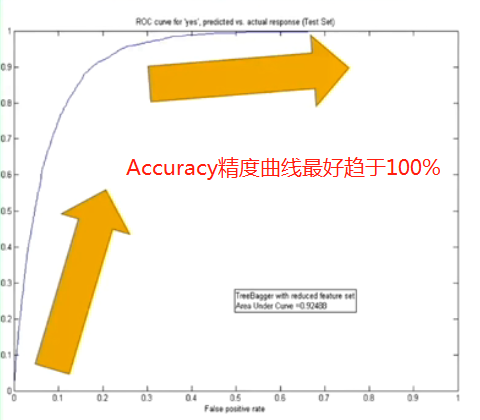
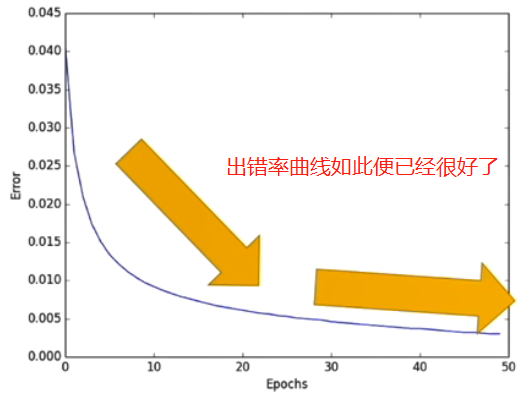
至于回归问题:用R2 score衡量回归精度.
F1 score:
解决过拟合方法:L1/L2 regularization, Dropout方法
交叉验证:可用于神经网络的调参,其他机器学习的调参。如层数等。
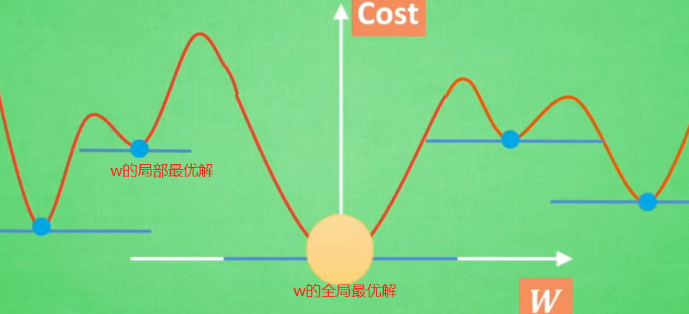
基本原理:梯度下降机制.
优化能力是一个膨大家族, 包括牛顿法则, Least Square method最小二分法, Gradient Descent梯度下降等.神经网络属于梯度下降的一个分支.
通常,平方差函数曲线的斜率线就是我们说的梯度,如下图.但神经网络的梯度不是如此,它有好多w.

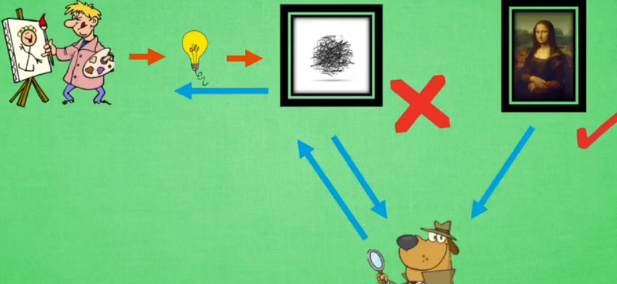
GAN生成对抗网络?
具有想象力.
上面的网络都是通过输入得到结果.
但生成网络(GAN是其一)是凭空捏造结果,即生成一堆随机数,
原理如下图: 新手画家按自己想法画图,图画鉴赏师判断出哪个是新手哪个是画家画的,然后将经验教导给新手画家该怎么画图,最后新手画家画出好图.

迁移学习?
借鉴对方经验往往能节省很多时间.如已经训练了一个识别人男女与眼镜的模型,突然紧急任务,要识别出另一套图中文物的价值.此时可以将原来模型的最后一层去掉,由识别男女分类换成识别文物价值,然后只需要训练最后一层,保持前面训练好的理解能力不变.
但不是所有情况都需要用到迁移学习,要是样本少,数据少就可以全部重新训练.或迁移前后数据差异很大时还不如不迁移.
多任务学习:
强化学习:
为什么要特征标准化?
特征可能来自不同的地方,不同大小,容量等,
如:假设用线性回归 预测房价= a离市中心+ b楼层+c面积.
误差= 预测- 实际价格 (通过误差回归到参数,修改之,使下一次预测更精确.)
若要缩小误差值,需要对参数abc进行调整,但abc对应不同特征,有可能跨度很大,有的参数对结果影响小,有的大,这种差距对最后结果影响很大.所以需要将跨度大的特征数据浓缩一下,跨度小的拓展一点,使他们的跨度尽量统一.
常用两种特征标准化方法:
Minmax normalization: 将所有特征数据按比例缩放到0~1这个区间,或-1~1.
Std normalization:将所有特征数据浓缩到平均值为0,方差为1的数据.
怎么区分好用的特征?
(因为有的特征对最后的结果无意义,或特征不完美,不具有代表性)
要避免复杂的信息(若有多种选择,尽量选择容易处理计算的).
避免无意义信息(对识别特征没任何贡献.不同范围结果不同不完美的特征).
避免重复信息(即意义相同的信息,如公里和里虽然数据不同但意义同).
什么是激励函数?
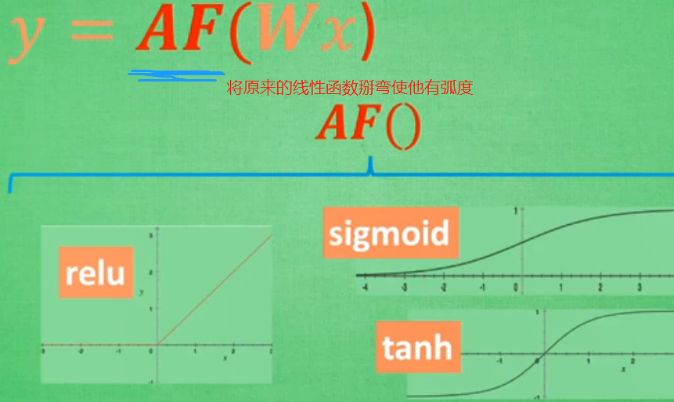
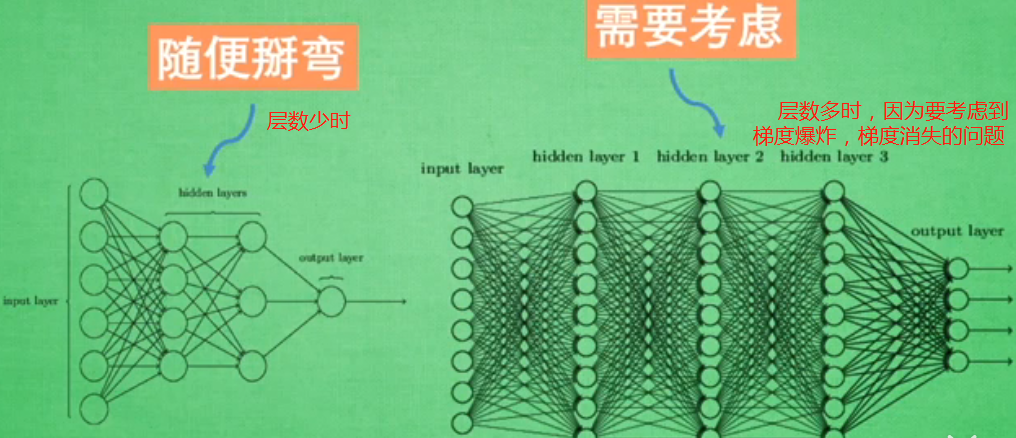
甚至可以创造自己的激励函数,但要确保函数是可以一直微分的
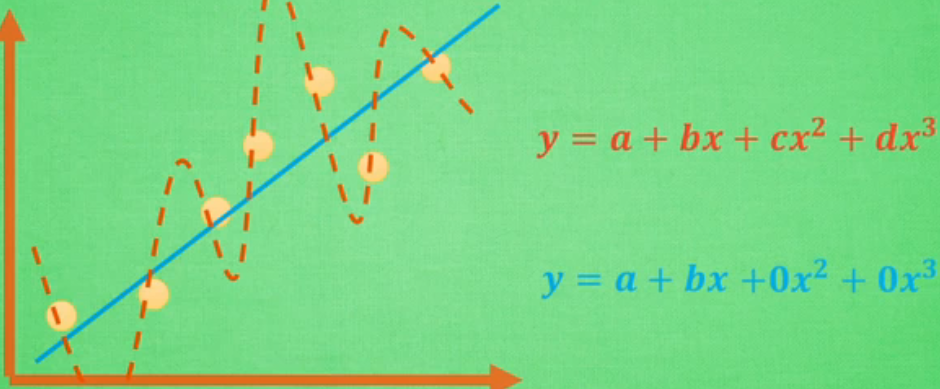
什么是过拟合?
也就是自负,在自己小圈子里厉害,但出去就平淡无奇。
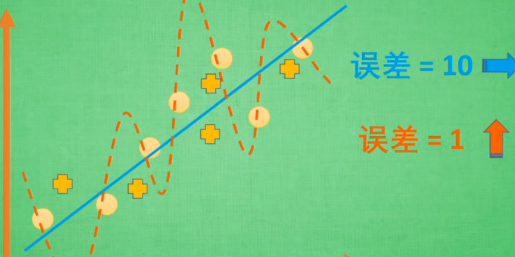 黄色虚线是过拟合,虽然对那些实圆每个都穿过,但若是再加几个外来值即加号,则误差会很大。
黄色虚线是过拟合,虽然对那些实圆每个都穿过,但若是再加几个外来值即加号,则误差会很大。
解决过拟合方法:
增加数据量。
正规化L1,L2..gularization。
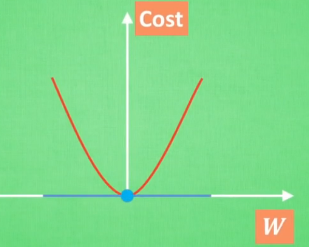
简化机器学习的关键公式为线性函数y=wx。W为机器学习需要学习到的各项。
 Abs(W)指w绝对值。Cost误差值。
Abs(W)指w绝对值。Cost误差值。
还有一个机器学习的正规化方法:Dropout regularization。训练时随机忽略掉一些神经元以及之间的连接。第二次训练时同理,再在原来基础上随机忽略掉一些神经元及连接。这样使得每次训练都不会过于依赖某一次的神经元。
优化器optimizer加速神经网络训练。
最基础方法:Stochastic gradient Descent(SGD)。
普通训练是将整套数据放入系统进行训练。SGD是将数据拆分,将批量数据循环放入系统进行训练,加速了NN的训练过程且不会损失太多的精确率。但此方法并不是最快的。下图是几种方法速度,其中SGD是最慢的。
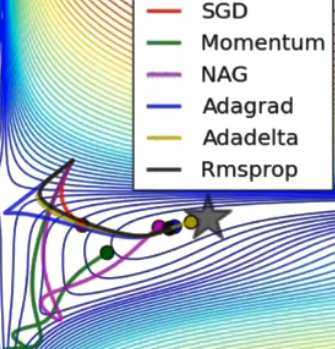
还有其他优化方法,大多是在参数上动手脚。
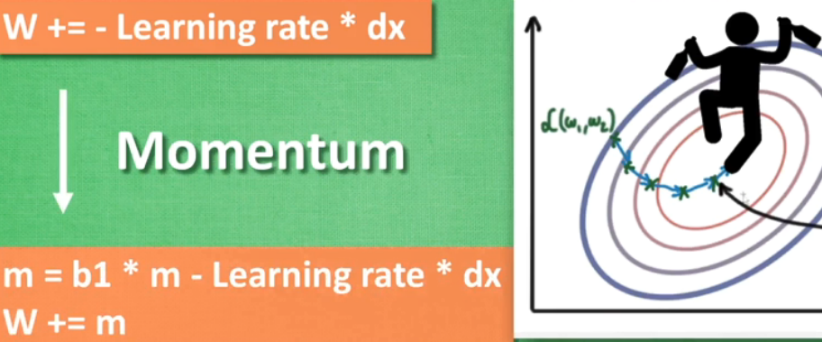 改变的是W,相当于加了个斜坡,使在向下滑时能利用惯性。
改变的是W,相当于加了个斜坡,使在向下滑时能利用惯性。
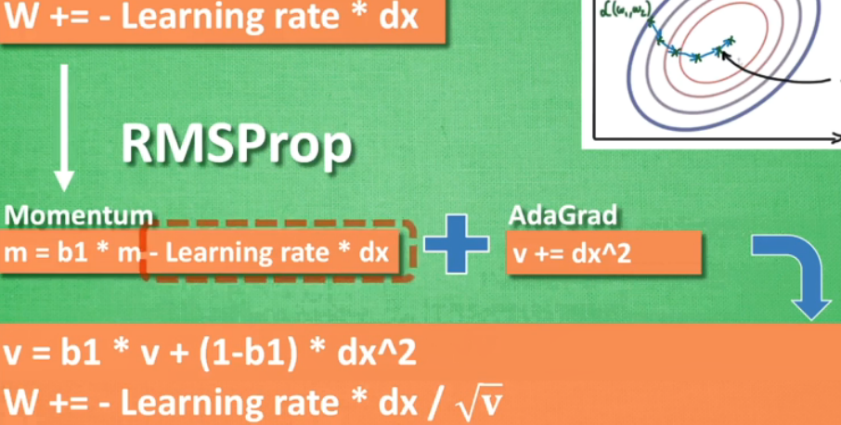
 改变的是学习斜率,相当于加了个阻止他走弯路的鞋子。
改变的是学习斜率,相当于加了个阻止他走弯路的鞋子。

处理不均衡数据
若对的数据占比大部分,错的占据小部分,则计算机学乖了,每次都预测数据是对的,则成功率就会很高,但这样有弊端。为了解决这个问题,两种方法:
想办法获取更多数据。因为可能前后段数据占比不一样会影响计算机预测标准。
换个评判方式。
重组数据。通过复制一些占比少的数据或砍掉一些占比多的数据,使得两种数据占比差不多。
使用其他机器学习方法。
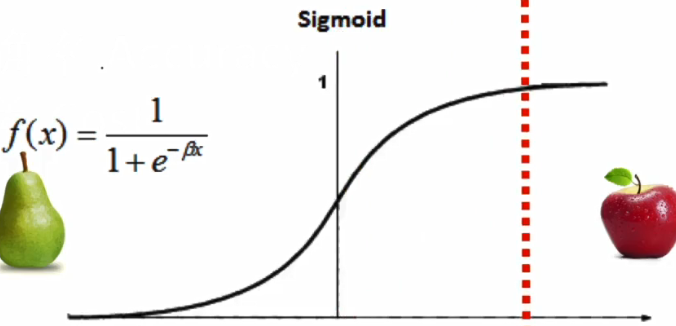
修改算法。如:下图算法,红虚线是门槛,本来在y轴上,结果落在左边则预测是梨,右边是苹果。由于大部分数据是梨,所以为了平衡,将门槛右移。
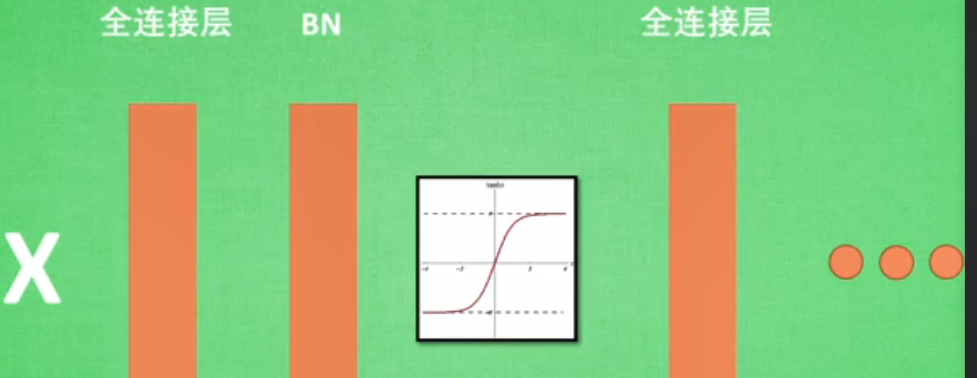
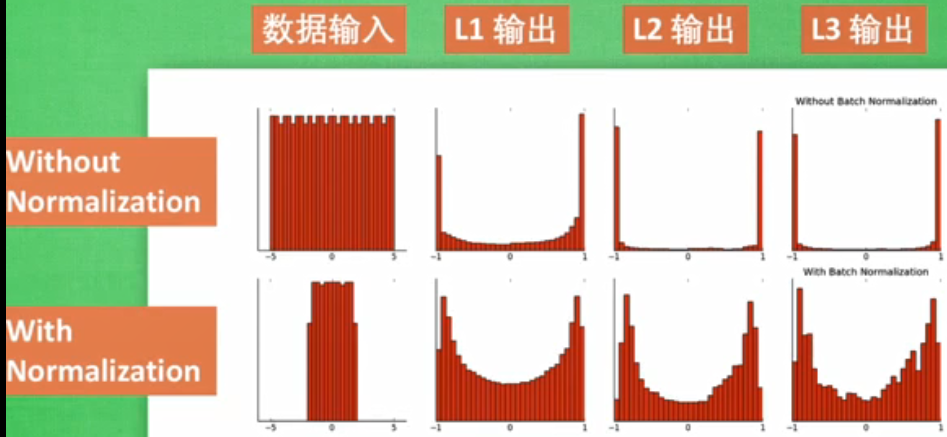
批标准化Batch normalization。????
是将分散的数据统一的一种优化神经网络的方法。统一规格的数据能使机器更容易学到规律。

将数据分成一批一批的,然后每批数据前向传递的时候都对它进行标准化。

什么是L1/L2正规化?
让误差不止取决于拟合数据的好坏,还取决于函数参数c,d的大小。
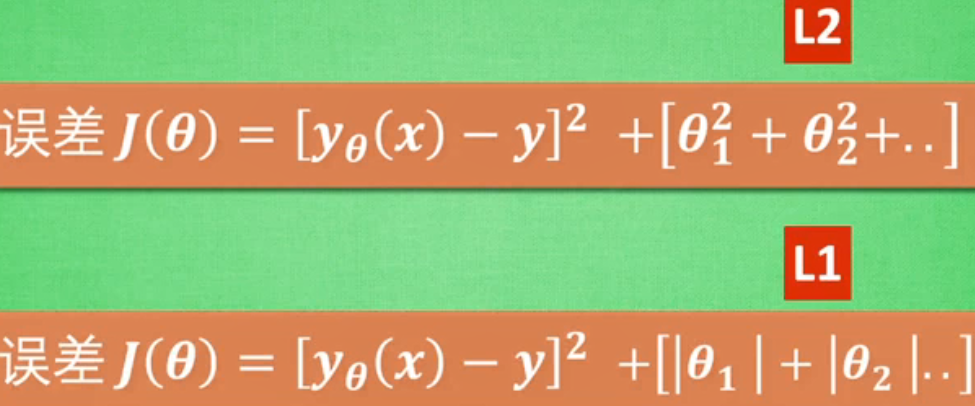
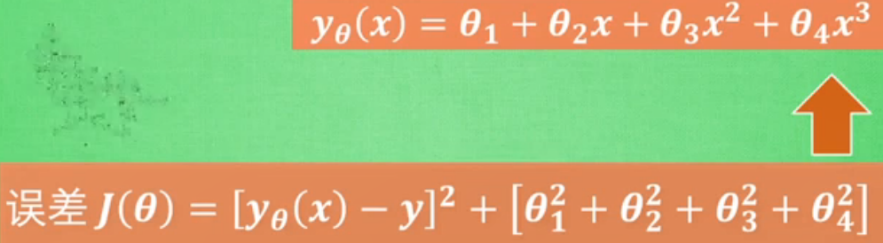
机器学习过程是通过改变参数 来减少误差的过程。减少误差时,非线性越强函数,次数越高的参数改动的越大。而正则化作用就是防止某一个参数对整体影响过大,使得所有参数都有贡献,避免两极化出风头。
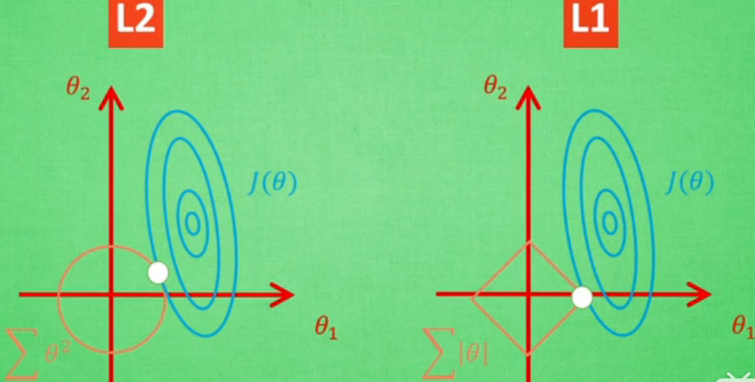
蓝色中心是一般误差最小值,每一圈蓝线上的误差值都相同。红色区域是额外误差,也可称为惩罚度,红线上的额外误差值也都一样。红蓝交界处是正规化的最优解,两者误差和最小。上图是L1,L2区别。用L1训练不稳定
最终表达形式:![]()
AlphaGo Zero为何厉害?
Alpha可以做出树形预测,每一个分支都是情况的一种预测。

用深度搜索训练,加神经网络评估当前状态并决策。原理如下图:
用了两套神经网络,一套预测下一步怎么走,一套评估当前所走步骤对我方是否有利。
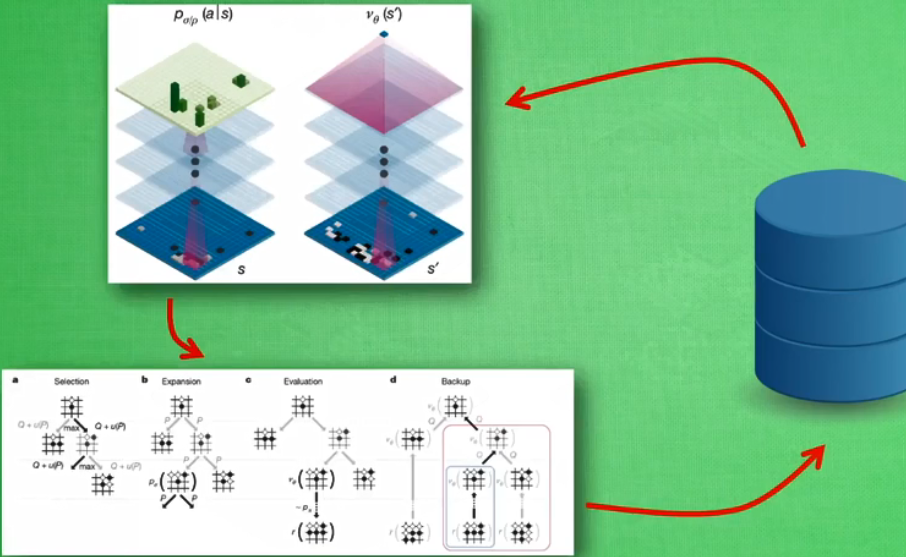
Alphago zero没有学习过任何人类棋谱,打破人类思维,不受人类经验影响。将原来两个网络合成一个网络,不用GPU训练,而用自家专门打造的TPU进行训练。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号