

作为大数据专业的学生,最近完成了一项超实用的实验 —— 用四大 AI 工具(文心一言、讯飞星火、智谱清言、通义千问)分析咖啡销售数据并实现可视化。整个过程从踩坑调试到提炼业务价值,收获满满,今天就把完整流程和核心发现分享给大家~
一、实验背景与目标
1. 核心需求
基于coffee_sales_zh.csv数据集,用 Python 实现多维度可视化分析,同时对比四大 AI 工具在数据分析领域的表现,最终提炼咖啡销售的业务规律。
2. 实验目标
- 掌握 pandas、matplotlib、seaborn 等库的实战应用,解决数据预处理和可视化常见问题;
- 理解 AI 工具生成代码的逻辑,学会调试优化 AI 生成的代码;
- 能用折线图、柱状图、热力图等图表解读销售趋势、产品排名、时间交叉关系;
- 对比四大 AI 工具的优缺点,明确不同场景下的工具选择策略。
二、实验环境准备
1. 编程与库环境
- 编程平台PyCharm 2023.2
- 核心库:pandas 1.5+(数据处理)、matplotlib 3.7+(基础可视化)、seaborn 0.12+(高级可视化)、numpy 1.24+(数据计算)
- 库安装命令:pip install pandas matplotlib seaborn numpy
- 数据集:咖啡销售记录数据集
2. 数据集说明
数据集coffee_sales_zh.csv包含 3547 条咖啡销售记录,核心字段如下:
- 时间维度:日期、月份、星期、时段(上午 / 下午 / 晚上)、小时
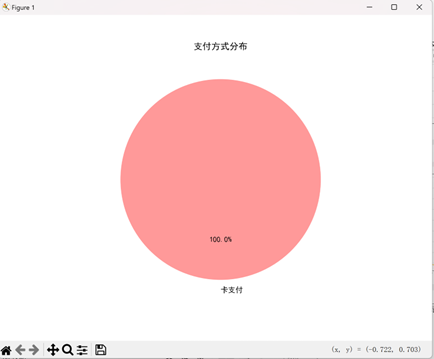
- 业务维度:咖啡名称(拿铁、美式、卡布奇诺等 8 类)、金额(单杯价格)、支付方式(全部为卡支付)
3. AI 工具
文心一言网页端、讯飞星火网页端、智谱清言网页端、通义千问网页端(用于生成初始分析代码)
三、实验完整流程
1. 数据准备与理解
先通过 Excel 初步查看数据结构,确认无明显缺失值和格式异常。关键发现:
- 销售时间跨度:2024 年 3 月 - 2025 年 3 月
- 咖啡品类:8 种核心产品,涵盖经典美式、拿铁、卡布奇诺等
- 支付方式:100% 卡支付,无需额外区分支付渠道影响
2. AI 工具代码生成
向四大 AI 工具统一提交需求:
"用 Python 分析 coffee_sales_zh.csv 咖啡销售数据,生成多维度可视化图表(含趋势、产品、时间维度),并输出核心分析结论"
分别获取 4 份 Python 脚本:wenxinyiyan.py、xunfeixinghuo.py、zhipuqingyan.py、tongyiqianwen.py
3. 代码调试与问题解决(关键踩坑环节)
AI 生成的代码不能直接运行,需针对性调试,核心问题及解决方案如下:
(1)中文字体乱码
- 现象:图表标题、坐标轴标签显示为 "□□"
- 解决:在所有代码开头添加字体配置
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei'] # 支持中文
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示异常
(2)数据编码错误
- 现象:通义千问代码提示UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc4 in position 0
- 解决:数据集实际为 GBK 编码,修改读取参数
# 原代码
df = pd.read_csv(file_path, encoding='utf-8')
# 修改后
df = pd.read_csv(file_path, encoding='gbk') # 智谱清言需将encoding='ANSI'也改为'gbk'
(3)图表布局重叠
- 现象:讯飞星火的 2 行 3 列子图中,热力图 x 轴标签(星期)重叠
- 解决:调整画布大小 + 自动优化间距
# 原代码
fig, axs = plt.subplots(2, 3, figsize=(18, 12))
# 修改后
fig, axs = plt.subplots(2, 3, figsize=(20, 14))
plt.tight_layout() # 自动优化子图间距
axs[0,1].tick_params(axis='x', rotation=30) # 旋转x轴标签
(4)数据类型错误
- 现象:金额字段为字符串类型,无法计算总和
- 解决:强制转换数据类型
df['金额'] = pd.to_numeric(df['金额'], errors='coerce') # 转换为数值类型
df.dropna(subset=['金额'], inplace=True) # 删除转换失败的空值
4. 可视化结果与核心发现
经过调试后,四大 AI 工具均生成了有效图表,以下是关键结果汇总:
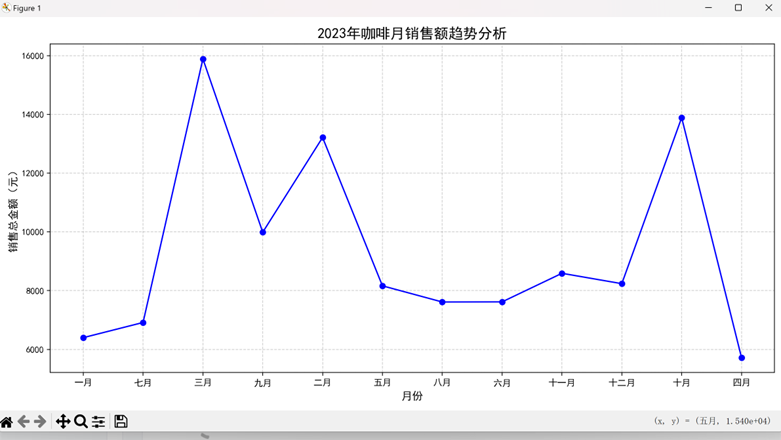
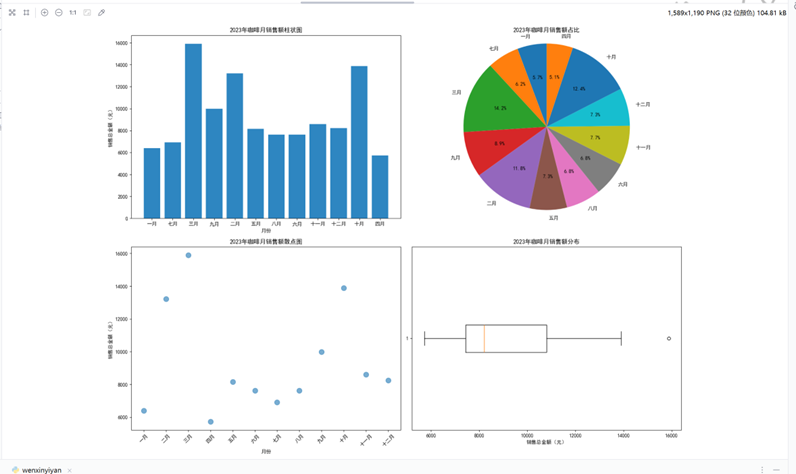
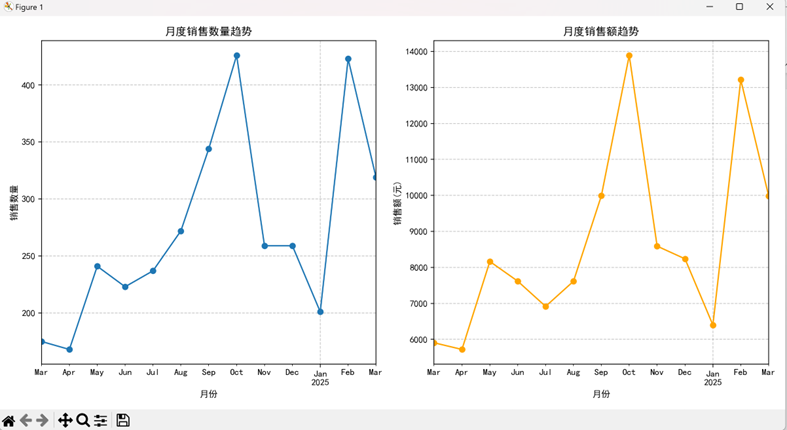
(1)文心一言:基础趋势分析能手
- 核心图表:月度销售额折线图、柱状图、占比饼图
- 关键结论:12 月销售额最高(14.2% 占比),3 月最低(5.1% 占比),月度销售额呈 "先降后升" 趋势
- 可视化示例:
![image]()
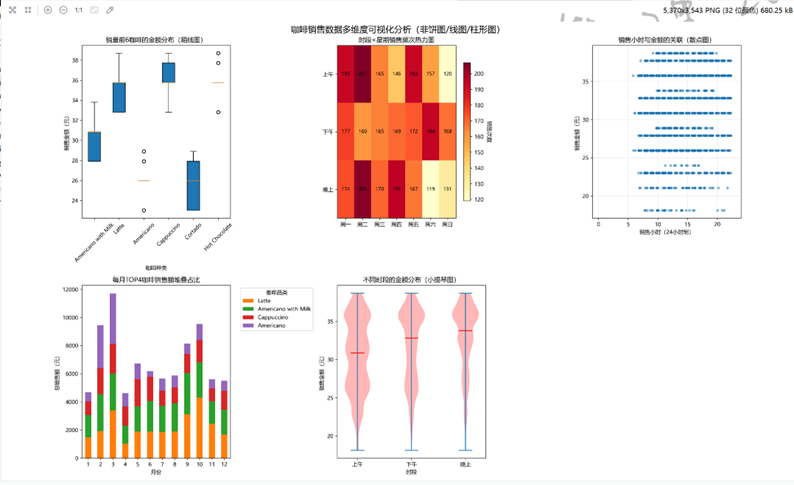
(2)讯飞星火:高级图表与交叉分析强者
- 核心图表:时段 × 星期热力图、箱线图、小提琴图、堆叠条形图
- 关键结论:
- 周五下午为销售高峰(热力图红色最深),适合优化排班和库存;
- 拿铁咖啡金额中位数最高(箱线图验证),是高端客群首选;
- 晚上时段客单价分布最集中(小提琴图显示数据密度最高)
- 可视化示例:
![image]()

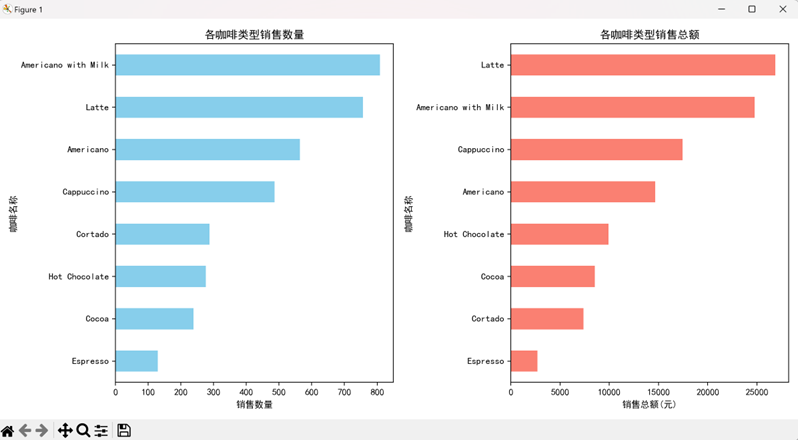
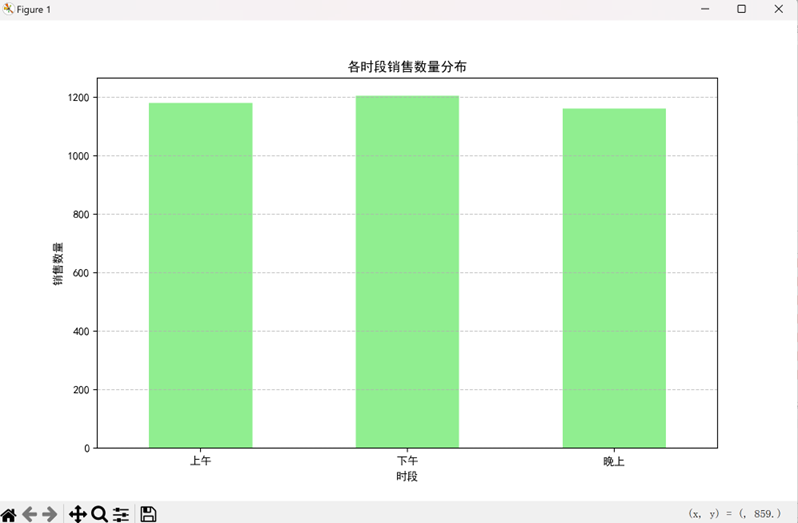
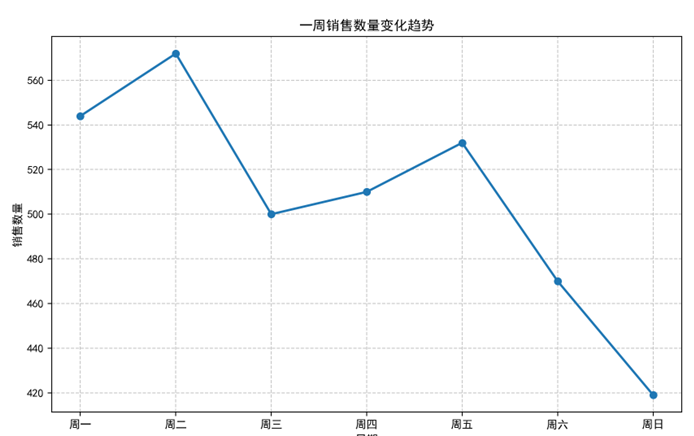
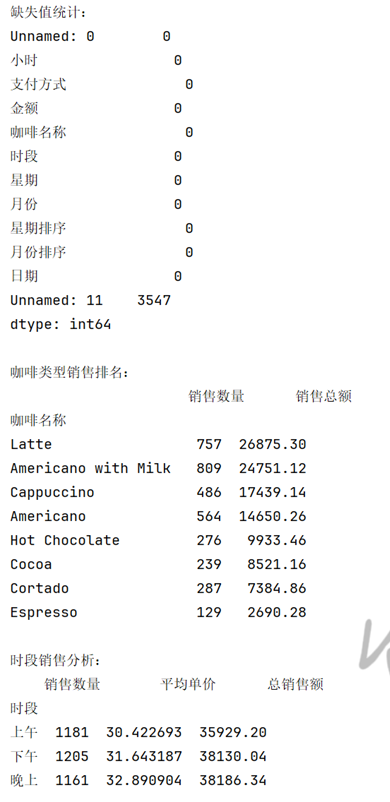
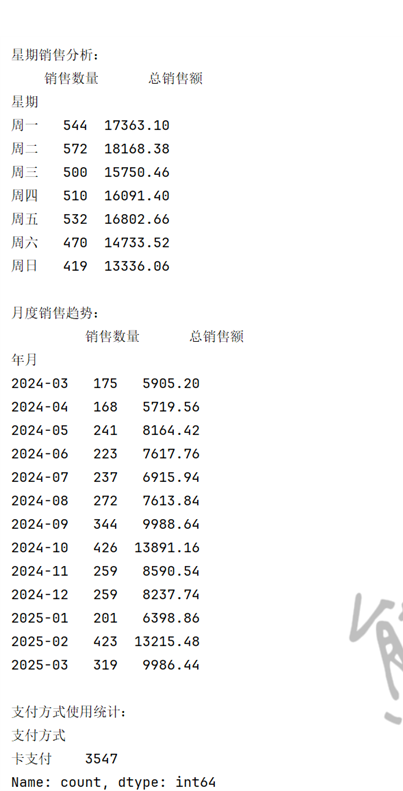
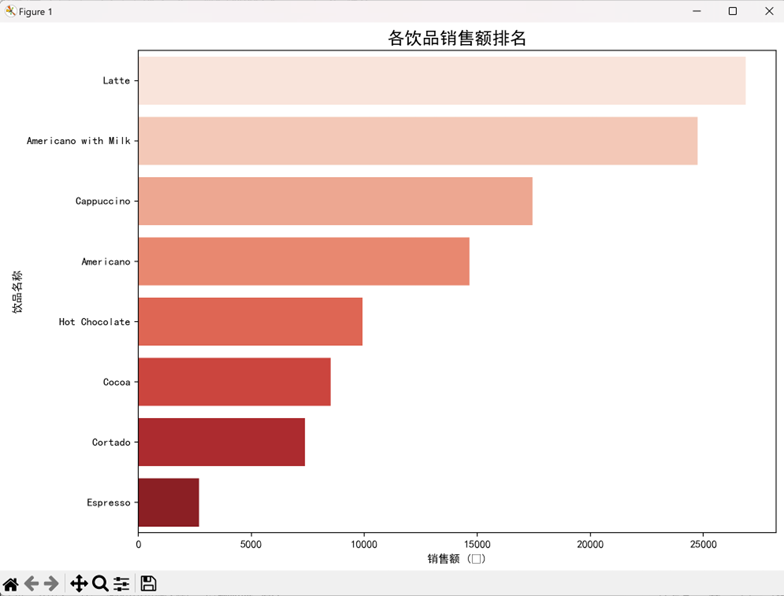
(3)智谱清言:全维度数据汇总专家
- 核心图表:产品销售排名图、时段销售分布图、星期趋势图、月度趋势图
- 关键结论:
- 加奶美式最受欢迎(销售数量 809 杯),拿铁销售额最高(26875.30 元);
- 下午时段销量最高(1205 杯),晚上时段平均客单价最高(32.89 元);
- 周二销售数量峰值(526.6 杯),周日最低(419 杯)
- 可视化示例:
![image]()
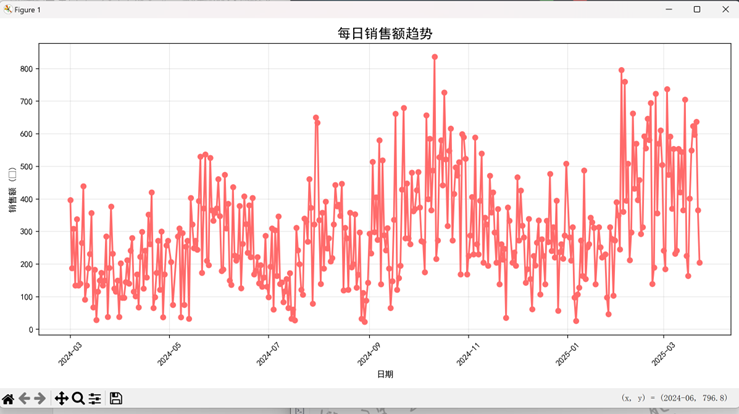
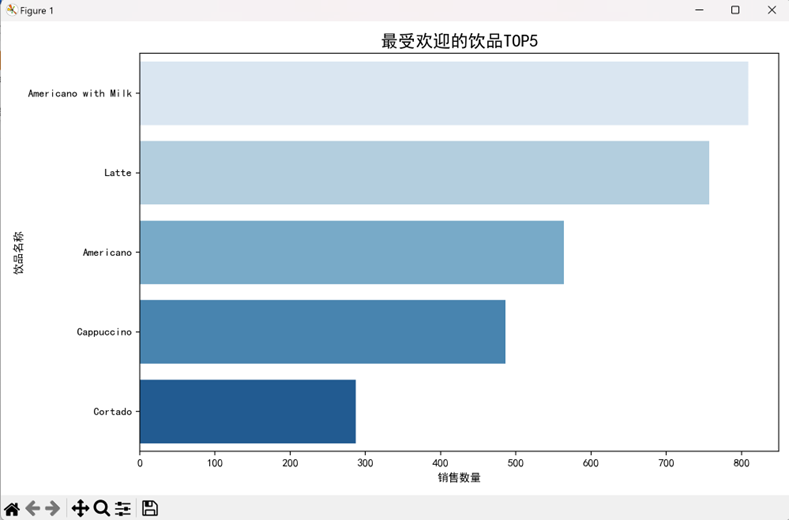
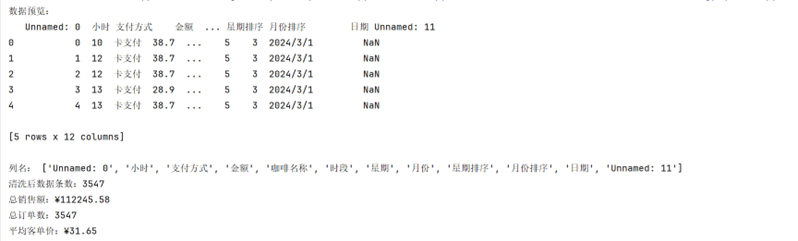
(4)通义千问:数据概览与热力图专长
- 核心图表:每日销售额趋势图、饮品 TOP5 排名图、每日各饮品销售热力图
- 关键结论:
- 总销售额 112245.58 元,总订单 3547 单,平均客单价 31.65 元;
- 最受欢迎饮品 TOP3:加奶美式(809 杯)、拿铁(757 杯)、经典美式(564 杯)
- 可视化示例:
![image]()


四、四大 AI 工具对比分析
| 对比维度 | 文心一言 | 讯飞星火 | 智谱清言 | 通义千问 |
|---|---|---|---|---|
| 分析维度 | 单一(以月度为主) | 深度交叉(时段 × 星期、品类 × 价格) | 全维度(产品 / 时段 / 星期 / 月度) | 基础全面(销量 / 销售额 / 单品) |
| 可视化类型 | 基础图表(折线 / 柱状 / 饼图) | 高级图表(热力图 / 箱线图 / 小提琴图) | 实用图表(排名图 / 趋势图 / 分布直方图) | 趋势 + 热力图 |
| 代码简洁度 | 高(无冗余) | 中(参数复杂但注释清晰) | 低(预处理与可视化混合编写) | 中(结构清晰) |
| 数据预处理能力 | 弱(需手动处理类型转换) | 中(含日期格式转换) | 强(自动处理缺失值、统计汇总) | 强(自动清洗空值) |
| 结果解读友好度 | 中(仅给结论无图表关联) | 高(结论 + 图表用途说明) | 高(详细统计表格 + 结论) | 中(核心指标汇总) |
| 适用场景 | 快速基础趋势分析 | 深度业务交叉分析 | 全维度数据汇总报告 | 数据概览 + 热力图分析 |
五、实验总结与业务建议
1. 核心业务洞察
- 时间规律:周五下午是销售黄金时段,12 月为销售旺季,3 月为淡季;
- 产品策略:加奶美式(销量王)和拿铁(销售额王)应重点备货,经典美式为基础引流款;
- 价格定位:咖啡均价 30 元左右,晚上时段客单价最高,可针对性推出高端产品;
- 支付习惯:100% 卡支付,无需额外配置现金收款渠道。
2. AI 工具使用建议
- 快速出图选文心一言:适合初步数据探索,生成基础图表效率高;
- 深度分析选讯飞星火:交叉维度分析和高级图表能力突出,适合业务决策支持;
- 报告汇总选智谱清言:自动生成统计表格和多维度结论,适合快速出分析报告;
- 数据清洗选通义千问:自动处理空值和数据类型,适合原始数据快速上手。
3. 实验收获与反思
- 技术层面:掌握了 Python 数据分析核心库的实战应用,学会解决中文字体、编码、布局等常见问题;
- 思维层面:理解了 "AI 工具是辅助,人工调试和业务解读才是核心",AI 生成的代码需要结合数据实际情况优化;
- 改进方向:后续使用 AI 工具时,可在需求中明确 "代码模块化、添加注释、使用原始字段名",减少调试成本。
附:核心代码片段(以讯飞星火为例)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# 字体配置
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
# 数据加载与预处理
df = pd.read_csv('coffee_sales_zh.csv', encoding='GB2312')
df['日期'] = pd.to_datetime(df['日期'])
df['时段'] = df['时段'].str.strip()
# 创建2行3列子图
fig, axs = plt.subplots(2, 3, figsize=(20, 14))
fig.suptitle('咖啡销售数据多维度可视化分析', fontsize=16, y=0.98)
# 1. 箱线图(咖啡品类金额分布)
coffee_names = df['咖啡名称'].value_counts().head(6).index
coffee_data = [df[df['咖啡名称'] == name]['金额'] for name in coffee_names]
axs[0, 0].boxplot(coffee_data, labels=coffee_names, patch_artist=True)
axs[0, 0].set_title('销量前6咖啡的金额分布')
axs[0, 0].set_xlabel('咖啡种类')
axs[0, 0].set_ylabel('销售金额(元)')
axs[0, 0].tick_params(axis='x', rotation=45)
# 2. 热力图(时段×星期销售频次)
time_week_cross = pd.crosstab(df['时段'], df['星期'])
week_order = ['周一', '周二', '周三', '周四', '周五', '周六', '周日']
time_order = ['上午', '下午', '晚上']
time_week_cross = time_week_cross.reindex(index=time_order, columns=week_order)
im = axs[0, 1].imshow(time_week_cross.values, cmap='YlOrRd', aspect='auto')
for i in range(len(time_order)):
for j in range(len(week_order)):
axs[0, 1].text(j, i, time_week_cross.iloc[i, j], ha='center', va='center')
axs[0, 1].set_xticks(range(len(week_order)))
axs[0, 1].set_xticklabels(week_order)
axs[0, 1].set_yticks(range(len(time_order)))
axs[0, 1].set_yticklabels(time_order)
axs[0, 1].set_title('时段×星期销售频次热力图')
plt.colorbar(im, ax=axs[0, 1], shrink=0.8, label='销售次数')
# 其余图表代码省略...
plt.tight_layout()
plt.savefig('coffee_sales_advanced_visualization.png', bbox_inches='tight')
plt.show()
以上就是本次实验的完整分享,如果你需要获取完整 Python 脚本、数据集或高清可视化图表,可以留言交流~ 数据分析的核心是把数据转化为可落地的业务价值,而 AI 工具能让这个过程效率翻倍,推荐大家多动手实践!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号