

一、随机森林:新手友好的 “万能工具”
- 核心应用场景
- 快速做分类 / 回归预测(不用复杂调参)
- 特征重要性分析(比如判断 “哪些因素影响客户流失”)
- 工业级快速原型开发(先出 baseline 结果,再优化)
- 典型案例:客户流失预测、信用风险初筛、商品销量初步预测
- 实操代码(以 “客户流失预测” 为例)
用经典的 telco-customer-churn 数据集(客户流失数据),预测客户是否会流失,同时看哪些因素影响最大。
步骤:安装库 → 加载数据 → 预处理 → 建模 → 评估 → 特征重要性
# 1. 安装需要的库(第一次用要装,之后不用)
# pip install pandas numpy scikit-learn
# 2. 导入库
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split # 划分训练集/测试集
from sklearn.ensemble import RandomForestClassifier # 随机森林分类器
from sklearn.preprocessing import LabelEncoder # 处理分类变量
from sklearn.metrics import accuracy_score, confusion_matrix # 评估指标
# 3. 加载数据(数据集可直接从kaggle下载:https://www.kaggle.com/blastchar/telco-customer-churn)
# 若不想下载,也可以用sklearn内置数据集,这里用真实业务数据集更贴近场景
df = pd.read_csv("WA_Fn-UseCases-Telco-Customer-Churn.csv")
# 4. 数据预处理(菜鸟必看:处理缺失值、分类变量编码)
# 处理缺失值(用均值填充数值型,众数填充分类型)
df['TotalCharges'] = pd.to_numeric(df['TotalCharges'], errors='coerce') # 转换数值类型
df['TotalCharges'].fillna(df['TotalCharges'].mean(), inplace=True) # 填充缺失值
# 处理分类变量(把文字变成模型能识别的数字)
label_cols = ['gender', 'Partner', 'Dependents', 'PhoneService', 'Churn'] # 分类列
for col in label_cols:
df[col] = LabelEncoder().fit_transform(df[col])
# 5. 划分特征(X)和标签(y):y是要预测的目标(是否流失),X是影响因素
X = df.drop(['customerID', 'Churn'], axis=1) # 去掉无关列(客户ID)和目标列
y = df['Churn'] # 目标:1=流失,0=不流失
# 划分训练集(80%用来训练)和测试集(20%用来验证)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 6. 构建随机森林模型(参数新手直接用默认,后续再调)
rf_model = RandomForestClassifier(
n_estimators=100, # 决策树数量(默认100,新手不用改)
max_depth=5, # 每棵树最大深度(防止过拟合)
random_state=42 # 固定随机种子,结果可重复
)
# 7. 训练模型
rf_model.fit(X_train, y_train)
# 8. 预测+评估(看模型准不准)
y_pred = rf_model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred) # 准确率
conf_matrix = confusion_matrix(y_test, y_pred) # 混淆矩阵(看真阳性/假阳性)
print(f"随机森林预测准确率:{accuracy:.2f}") # 新手能达到0.8左右就合格
print("混淆矩阵:")
print(conf_matrix)
# 9. 特征重要性(看哪些因素最影响客户流失)
feature_importance = pd.DataFrame({
'特征': X.columns,
'重要性': rf_model.feature_importances_
}).sort_values('重要性', ascending=False).head(5) # 显示Top5重要特征
print("\n影响客户流失的Top5因素:")
print(feature_importance)
代码说明:
- 数据集可直接从 Kaggle 下载,或替换成自己的业务数据(只要列名对应)
- 预处理步骤是核心:新手必须学会处理缺失值和分类变量
- 评估用 “准确率” 足够入门,混淆矩阵能帮你看 “漏判 / 误判” 情况
- 特征重要性是随机森林的大优势,直接指导业务决策(比如 Top1 是 “月费”,就可以针对性调整定价)
二、XGBoost:追求极致精度的 “竞赛王者”
- 核心应用场景
精准预测场景(竞赛、工业级落地)
数据量较大、特征维度高的回归 / 分类问题
典型案例:房价预测、电商销量预测、金融风控(信贷违约预测)、医疗疾病风险预测 - 实操代码(以 “房价预测” 为例)
用 boston_housing 数据集(经典房价预测数据),精准预测房屋价格,适合需要高精度的场景。
# 1. 安装库(xgboost需要单独装)
# pip install pandas numpy scikit-learn xgboost
# 2. 导入库
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.datasets import fetch_california_housing # 加州房价数据集(替代旧版波士顿房价)
from sklearn.metrics import mean_absolute_error, r2_score # 回归问题评估指标
import xgboost as xgb # XGBoost核心库
# 3. 加载数据(sklearn内置,直接调用,不用手动下载)
data = fetch_california_housing()
X = pd.DataFrame(data.data, columns=data.feature_names) # 特征(比如房屋面积、所在区域收入等)
y = pd.Series(data.target) # 目标:房屋价格(单位:10万美元)
# 4. 划分训练集/测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 5. 构建XGBoost回归模型(参数注释清晰,新手可直接用)
xgb_model = xgb.XGBRegressor(
objective='reg:squarederror', # 回归任务(平方误差损失)
n_estimators=100, # 树的数量
max_depth=3, # 每棵树最大深度(控制复杂度,防止过拟合)
learning_rate=0.1, # 学习率(步长,越小越精准但越慢)
subsample=0.8, # 每棵树用80%的数据训练(防止过拟合)
colsample_bytree=0.8, # 每棵树用80%的特征(防止过拟合)
random_state=42
)
# 6. 训练模型
xgb_model.fit(
X_train, y_train,
eval_set=[(X_test, y_test)], # 训练时查看测试集效果
early_stopping_rounds=10, # 连续10轮测试集效果没提升就停止(防止过拟合)
verbose=10 # 每10轮打印一次训练情况
)
# 7. 预测+评估(回归问题看MAE和R²)
y_pred = xgb_model.predict(X_test)
mae = mean_absolute_error(y_test, y_pred) # 平均绝对误差(越小越好)
r2 = r2_score(y_test, y_pred) # 决定系数(越接近1越好,说明模型解释力强)
print(f"\nXGBoost房价预测平均误差:{mae:.2f}(10万美元)") # 新手能做到0.3左右就很好
print(f"R²系数:{r2:.2f}") # 新手能达到0.85以上
# 8. 特征重要性(看哪些因素决定房价)
xgb.plot_importance(xgb_model) # 可视化特征重要性(需要matplotlib库,pip install matplotlib)
代码说明:
- 用加州房价数据集替代旧版波士顿房价(sklearn 已移除旧版),直接加载无需手动下载
- XGBoost 参数比随机森林多,但核心就 5 个(n_estimators、max_depth、learning_rate、subsample、colsample_bytree),新手先按默认值调
- early_stopping_rounds 是 XGBoost 的 “防过拟合神器”,新手一定要加
- 回归评估用 MAE(直观,平均差多少)和 R²(模型解释力),比单纯看准确率更有意义
三、聚类:无标签数据的 “规律挖掘工具”
- 核心应用场景
- 无标签数据找规律(不知道答案时用)
- 用户分群(精准营销)、商品分类、异常检测(比如欺诈交易识别)
- 典型案例:电商用户分群(高价值用户 / 潜力用户 / 流失风险用户)、新闻聚类(相似新闻归为一类)、工业异常检测(设备故障识别)
- 实操代码(以 “电商用户分群” 为例)
用模拟的 “用户消费数据”,按消费金额、消费频率、浏览时长聚类,找出不同用户群体,指导营销。
# 1. 安装库
# pip install pandas numpy scikit-learn matplotlib
# 2. 导入库
import pandas as pd
import numpy as np
from sklearn.cluster import KMeans # K-means聚类
from sklearn.preprocessing import StandardScaler # 数据标准化(聚类必做!)
from sklearn.metrics import silhouette_score # 聚类效果评估(轮廓系数)
import matplotlib.pyplot as plt # 可视化聚类结果
# 3. 构建模拟用户消费数据(新手可直接用,也可替换成自己的真实数据)
np.random.seed(42) # 固定随机种子,结果可重复
data = {
'用户ID': range(1, 1001), # 1000个用户
'消费金额': np.random.normal(500, 200, 1000), # 平均消费500元,标准差200
'消费频率': np.random.normal(10, 3, 1000), # 平均每月消费10次,标准差3
'浏览时长': np.random.normal(60, 20, 1000) # 平均每次浏览60分钟,标准差20
}
df = pd.DataFrame(data)
# 4. 数据预处理(聚类关键:标准化!不然数值大的特征会主导结果)
scaler = StandardScaler()
# 选择聚类的特征(消费金额、消费频率、浏览时长)
X = df[['消费金额', '消费频率', '浏览时长']]
X_scaled = scaler.fit_transform(X) # 标准化后的数据(均值0,方差1)
# 5. 确定聚类数量K(新手用“肘部法则”+轮廓系数)
# 肘部法则:画K值和误差的图,找“肘部”对应的K
inertia = []
k_range = range(2, 10) # 测试K从2到9
for k in k_range:
kmeans = KMeans(n_clusters=k, random_state=42)
kmeans.fit(X_scaled)
inertia.append(kmeans.inertia_) # 簇内平方和(越小越紧凑)
# 可视化肘部法则结果(新手直接运行,看哪个K是“拐点”)
plt.plot(k_range, inertia, 'o-')
plt.xlabel('聚类数量K')
plt.ylabel('簇内平方和(Inertia)')
plt.title('K-means肘部法则图')
plt.show()
# 6. 这里选择K=3(根据肘部法则,可自行调整),构建K-means模型
k = 3
kmeans_model = KMeans(
n_clusters=k,
random_state=42,
n_init=10 # 避免局部最优解,默认10次
)
df['用户群体'] = kmeans_model.fit_predict(X_scaled) # 给每个用户贴群体标签(0/1/2)
# 7. 评估聚类效果(轮廓系数:越接近1越好,越接近-1越差)
sil_score = silhouette_score(X_scaled, df['用户群体'])
print(f"聚类轮廓系数:{sil_score:.2f}") # 0.5以上就是合格的聚类结果
# 8. 分析每个群体的特征(业务解读核心)
group_analysis = df.groupby('用户群体').agg({
'消费金额': 'mean',
'消费频率': 'mean',
'浏览时长': 'mean',
'用户ID': 'count' # 每个群体的用户数
}).rename(columns={'用户ID': '用户数量'})
print("\n各用户群体特征:")
print(group_analysis)
# 9. 可视化聚类结果(取前两个特征画图,新手能直观看到分类)
plt.scatter(
X_scaled[:, 0], # 消费金额(标准化后)
X_scaled[:, 1], # 消费频率(标准化后)
c=df['用户群体'], # 按群体上色
cmap='viridis',
alpha=0.6
)
plt.xlabel('消费金额(标准化)')
plt.ylabel('消费频率(标准化)')
plt.title('K-means用户分群结果')
plt.show()
代码说明:
- 用模拟数据避免下载麻烦,新手可直接替换成自己的用户数据(只要有 3 个以上数值型特征)
- 聚类必做 “标准化”:不然 “消费金额”(几百元)会比 “消费频率”(几次)权重高,导致结果失真
- K 值选择是聚类的难点:新手先用肘部法则找拐点,再用轮廓系数验证(0.5 以上合格)
- 聚类的核心是 “业务解读”:比如分析后发现群体 0 是 “高消费高频率” 用户,就可以推高端会员服务
关键补充:3 个算法的环境配置 + 避坑指南
- 环境配置
打开 cmd / 终端,执行以下命令安装所有需要的库:
pip install pandas numpy scikit-learn xgboost matplotlib
- 避坑指南
- 随机森林:不用过度调参,n_estimators 默认 100 足够,max_depth 设 5-10 防止过拟合
- XGBoost:必须指定 objective(分类用 binary:logistic,回归用 reg:squarederror),否则报错;learning_rate 别太大(0.05-0.1 最佳)
- 聚类:一定要标准化数据!K 值别乱设,结合业务场景(比如用户分群一般 3-5 类,太多没意义)
- 最终选择清单(直接对照业务选算法)
![image]()
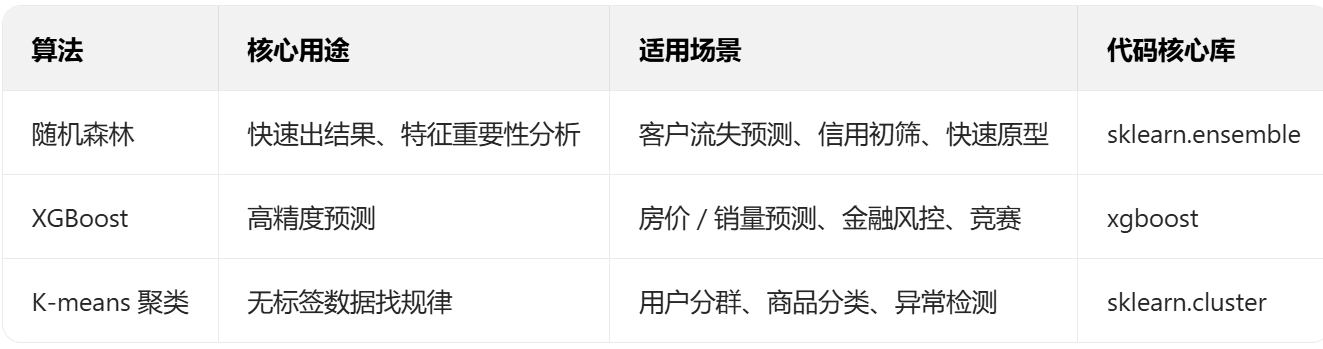
建议按 “随机森林→XGBoost→聚类” 的顺序练习:先跑通随机森林的代码,感受 “快速出结果” 的快乐;再用 XGBoost 优化精度,理解参数调优的思路;最后用聚类探索无标签数据,培养 “找规律” 的思维。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号