

数据可视化是数据分析中不可或缺的环节,它能将枯燥的数字转化为直观的图形,帮助我们快速发现数据规律。本文将基于实际案例,详细介绍如何使用 Matplotlib 和 Seaborn 这两个 Python 库进行数据可视化,从基础操作到实战应用,让你轻松掌握数据可视化技巧。
一、可视化工具准备
在开始之前,我们需要准备好相关的 Python 库。本文主要使用以下工具:
- Matplotlib:Python 最基础的可视化库,功能强大,可绘制各种图表
- Seaborn:基于 Matplotlib 的高级可视化库,语法更简洁,图表更美观
- Pandas:用于数据处理与分析
- NumPy:用于数值计算
安装命令:
pip install matplotlib seaborn pandas numpy
二、Matplotlib 基础操作
Matplotlib 是 Python 可视化的基础,掌握它的核心用法能让你应对大部分可视化需求。
1. 画布与子图
创建画布是绘图的第一步,我们可以通过plt.figure()创建空白画布,通过subplot()或subplots()创建子图:
点击查看代码
import matplotlib.pyplot as plt
import numpy as np
# 创建单个画布
plt.figure(figsize=(10, 6)) # 设置画布尺寸
plt.plot(np.arange(1, 101)) # 绘制折线图
plt.show()
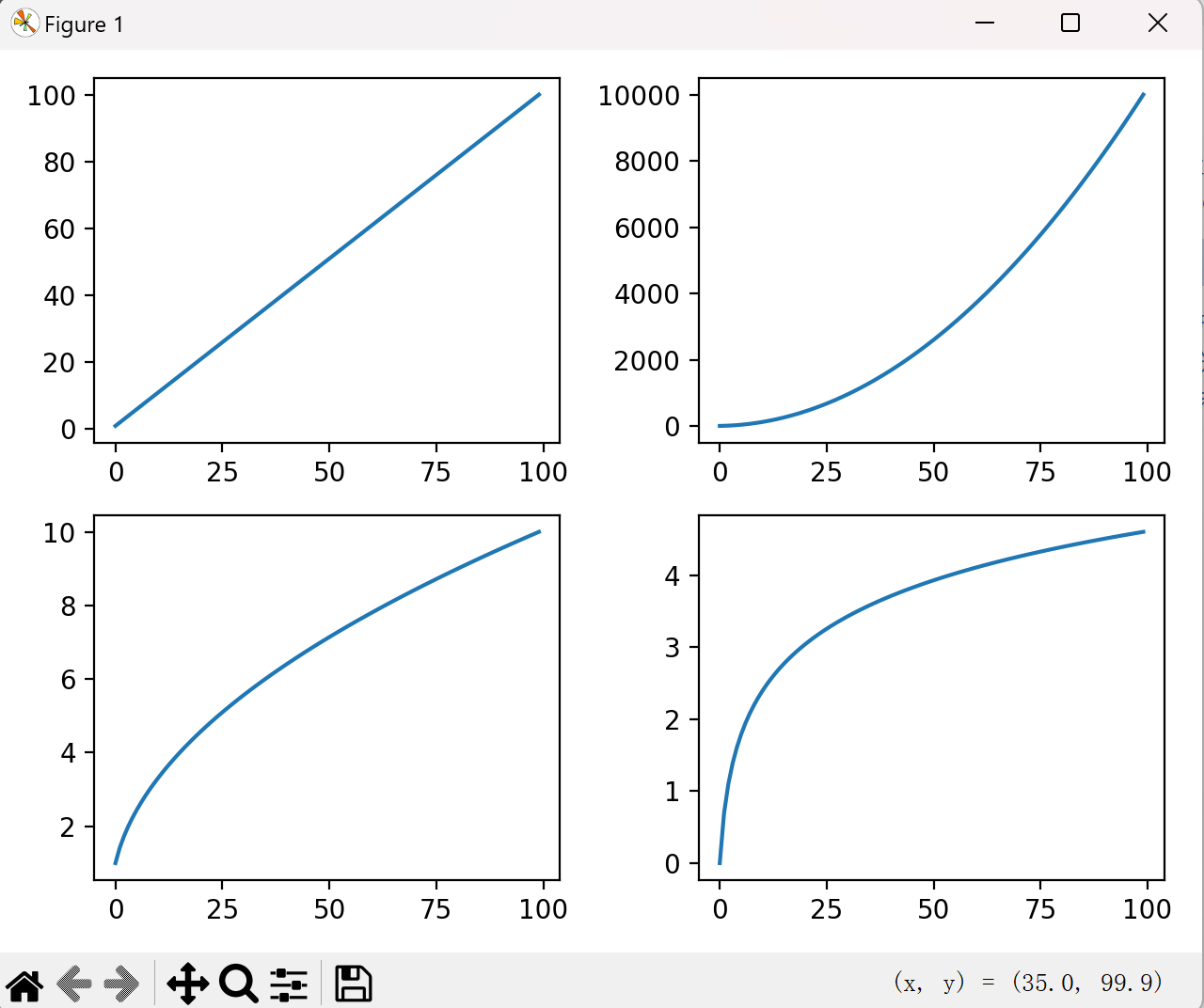
# 创建多个子图
fig, axes = plt.subplots(2, 2) # 创建2x2的子图矩阵
axes[0, 0].plot(np.arange(1, 101)) # 第一个子图
axes[0, 1].plot(np.arange(1, 101)**2) # 第二个子图
axes[1, 0].plot(np.arange(1, 101)** 0.5) # 第三个子图
axes[1, 1].plot(np.log(np.arange(1, 101))) # 第四个子图
plt.tight_layout() # 自动调整子图间距
plt.show()
效果图如下:
2. 常见图表类型及绘制方法
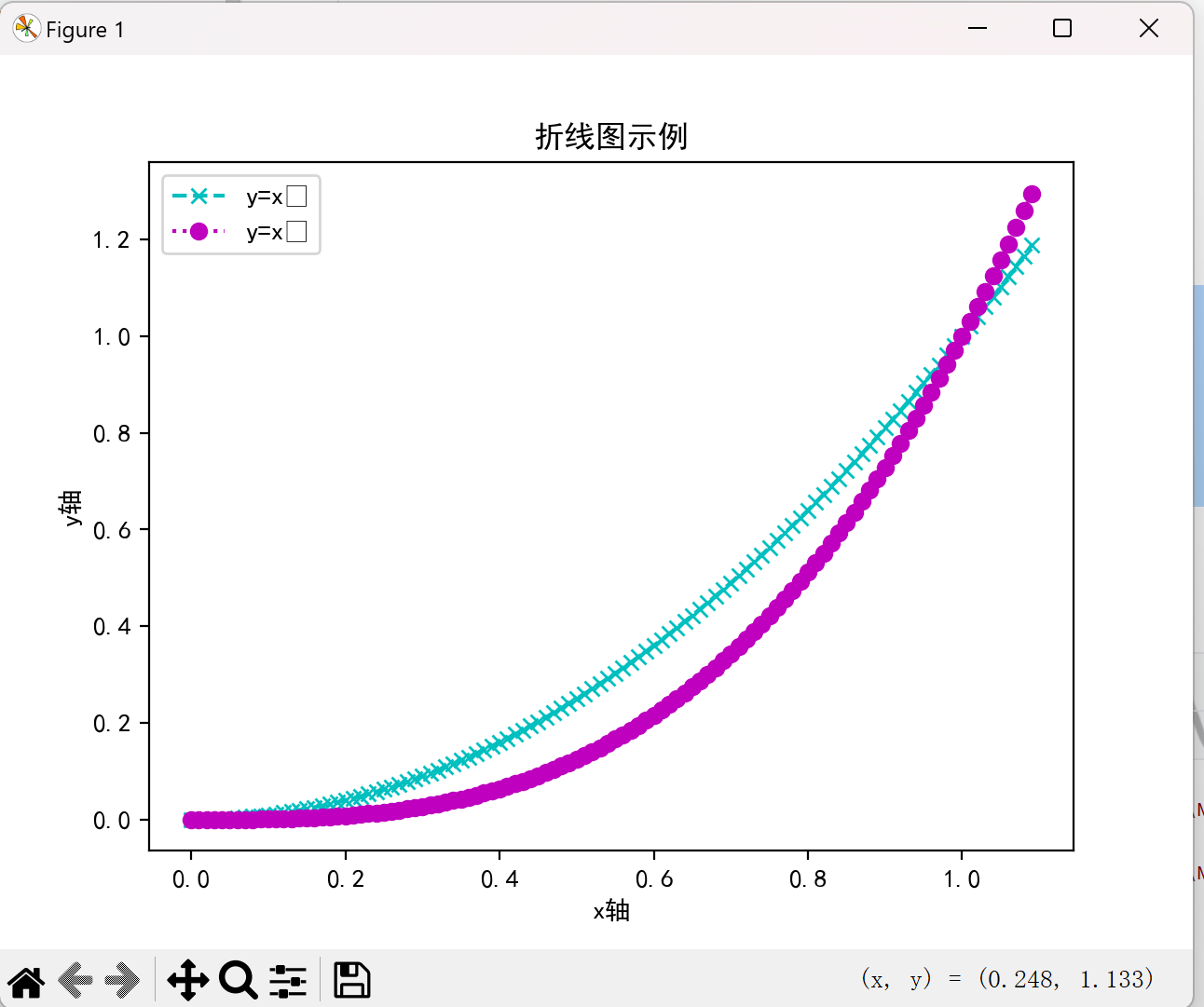
折线图(plot)
折线图适合展示数据随时间或有序类别变化的趋势:
点击查看代码
data = np.arange(0, 1.1, 0.01)
plt.plot(data, data**2, 'cx--', label='y=x²') # 青色x标记虚线
plt.plot(data, data**3, 'mo:', label='y=x³') # 品红圆圈点线
plt.title("折线图示例")
plt.xlabel("x轴")
plt.ylabel("y轴")
plt.legend() # 显示图例
plt.show()
效果图如下:
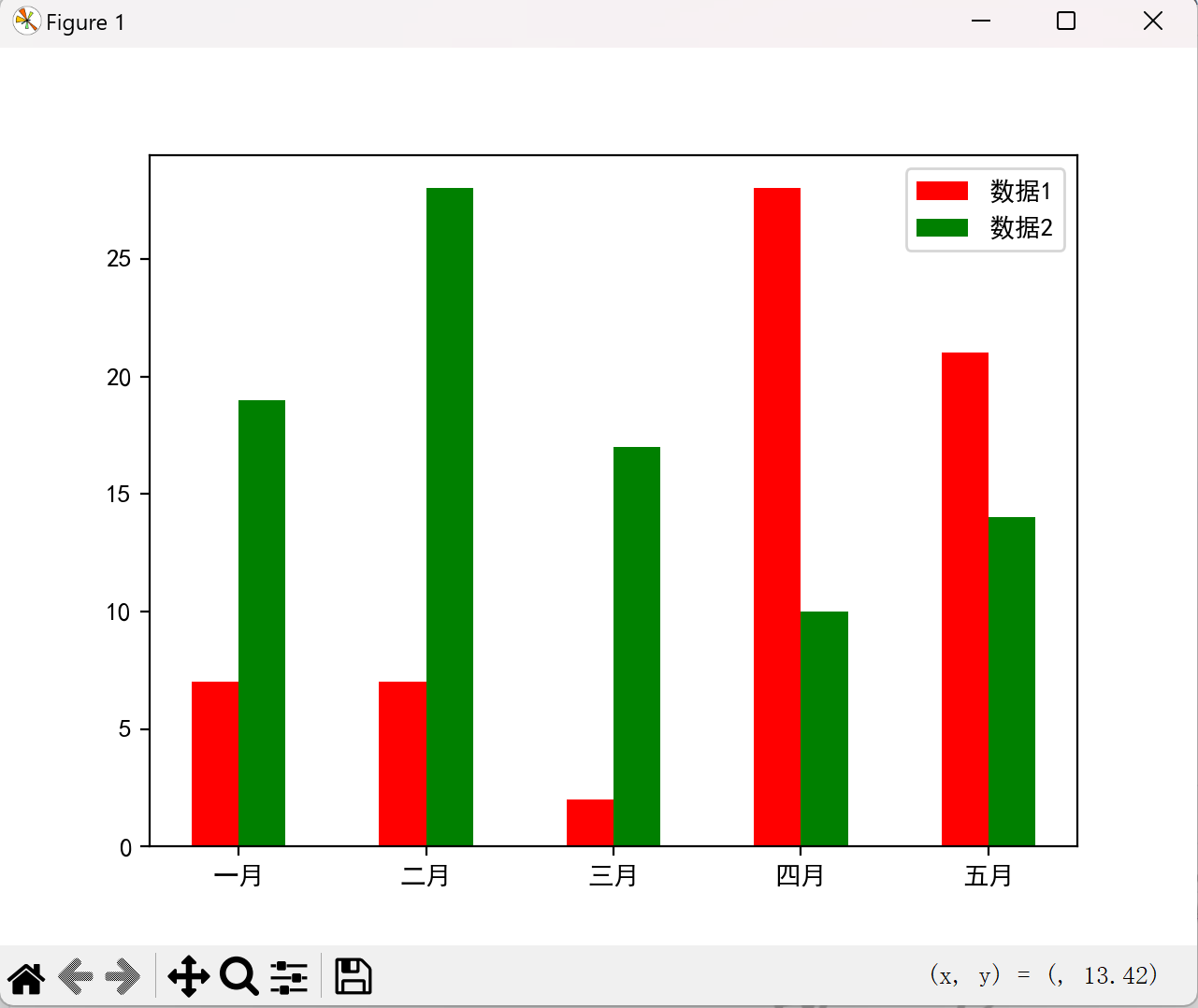
柱状图(bar)
柱状图适合比较不同类别的数据:
点击查看代码
x = np.arange(5)
y1, y2 = np.random.randint(1, 31, size=(2, 5))
width = 0.25
plt.bar(x, y1, width, color='r', label='数据1')
plt.bar(x + width, y2, width, color='g', label='数据2')
plt.xticks(x + width/2, ['一月', '二月', '三月', '四月', '五月'])
plt.legend()
plt.show()
效果图如下:
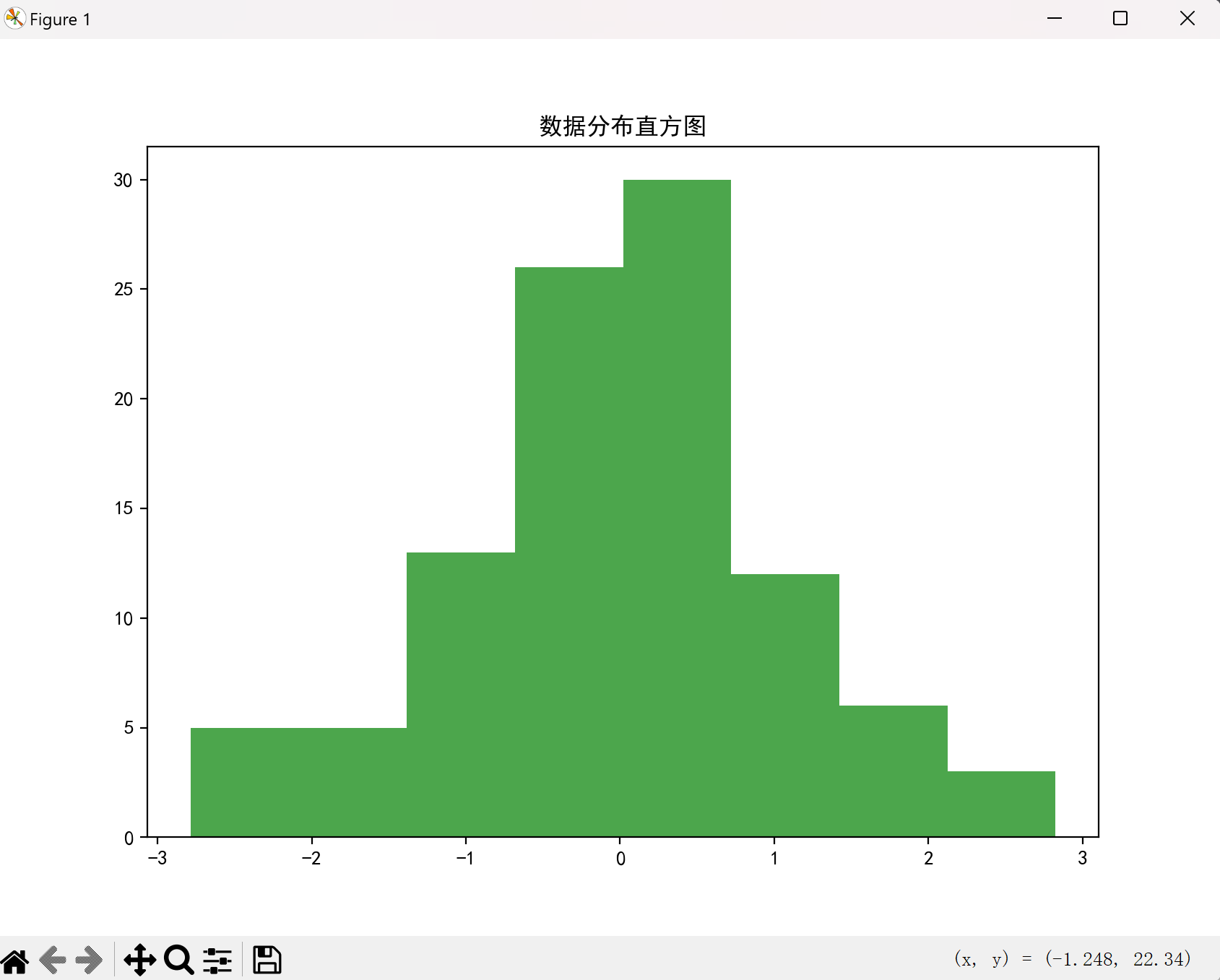
直方图(hist)
直方图用于展示数据的分布情况:
点击查看代码
# 生成100个符合正态分布的随机数
random_data = np.random.randn(100)
plt.hist(random_data, bins=8, color='g', alpha=0.7) # bins设置分箱数
plt.title("数据分布直方图")
plt.show()
效果图如下:
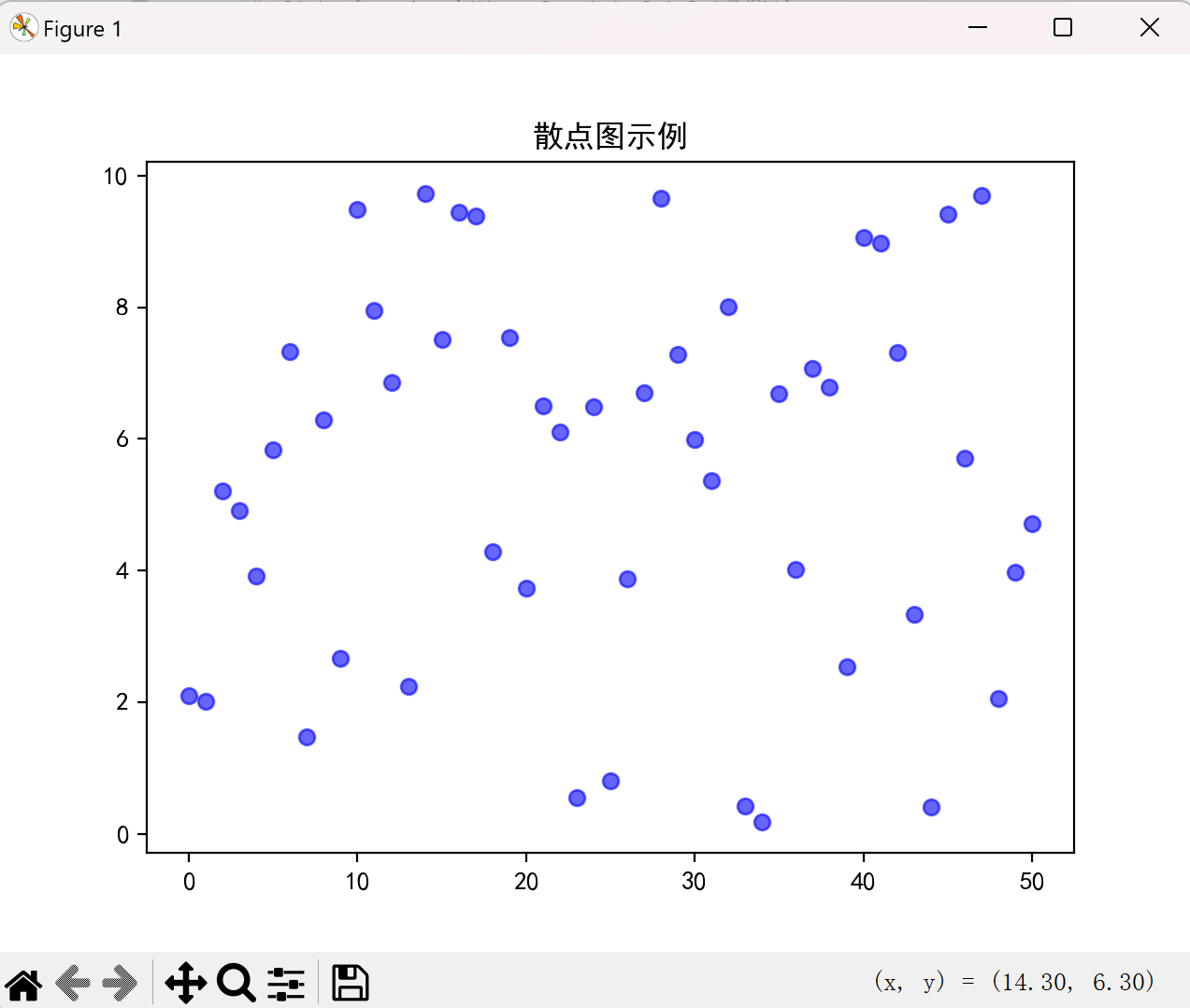
散点图(scatter)
散点图适合观察两个变量之间的关系:
点击查看代码
x = np.arange(51)
y = np.random.rand(51) * 10 # 生成51个0-10的随机数
plt.scatter(x, y, color='b', alpha=0.6)
plt.title("散点图示例")
plt.show()
效果图如下:
- 中文显示设置
在 Matplotlib 中默认不支持中文显示,需要手动设置:
plt.rcParams['font.sans-serif'] = ['SimHei'] # 正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
三、Seaborn 进阶可视化
Seaborn 在 Matplotlib 基础上进行了封装,提供了更简洁的 API 和更美观的默认样式,特别适合统计数据可视化。
1. 分布数据可视化
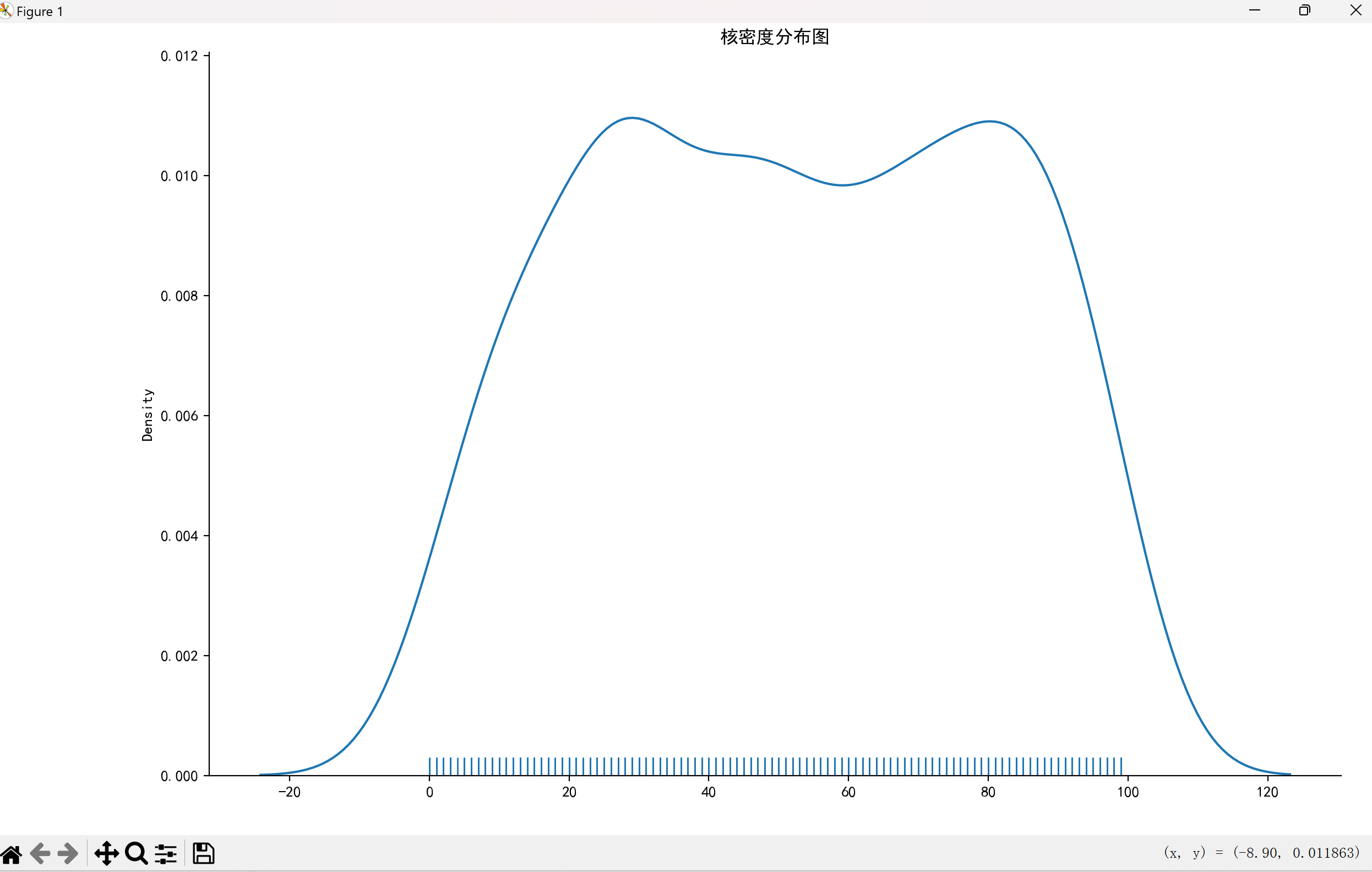
核密度图(kdeplot)
核密度图用于展示单变量或双变量的概率密度分布:
点击查看代码
import seaborn as sns
# 生成随机数据
data = np.random.randint(0, 100, 500)
sns.displot(data, kind="kde", rug=True) # rug参数显示数据点
plt.title("核密度分布图")
plt.show()
效果图如下:
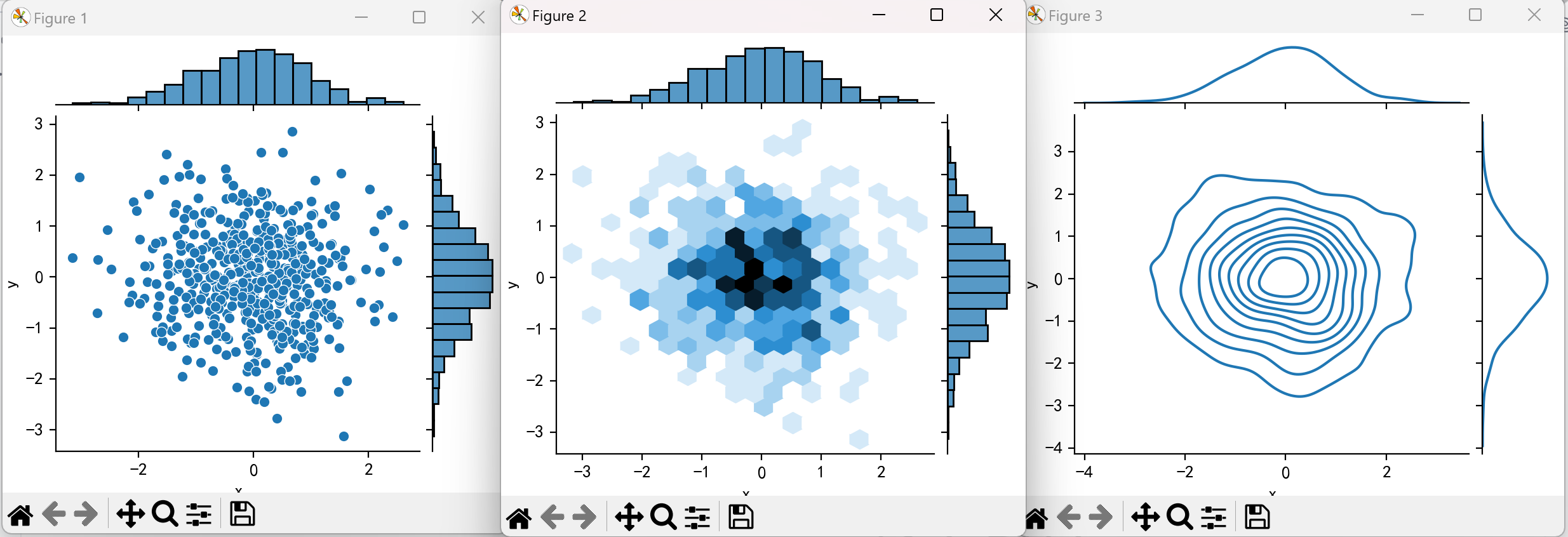
联合分布图(jointplot)
联合分布图可同时展示两个变量的关系及各自的分布:
点击查看代码
# 创建包含两个变量的DataFrame
df = pd.DataFrame({
'x': np.random.randn(500),
'y': np.random.randn(500)
})
# 基础散点联合图
sns.jointplot(x='x', y='y', data=df)
# 六边形箱型联合图(适合大数据量)
sns.jointplot(x='x', y='y', data=df, kind='hex')
# 核密度联合图
sns.jointplot(x='x', y='y', data=df, kind='kde')
plt.show()
效果图如下:
2. 分类数据可视化
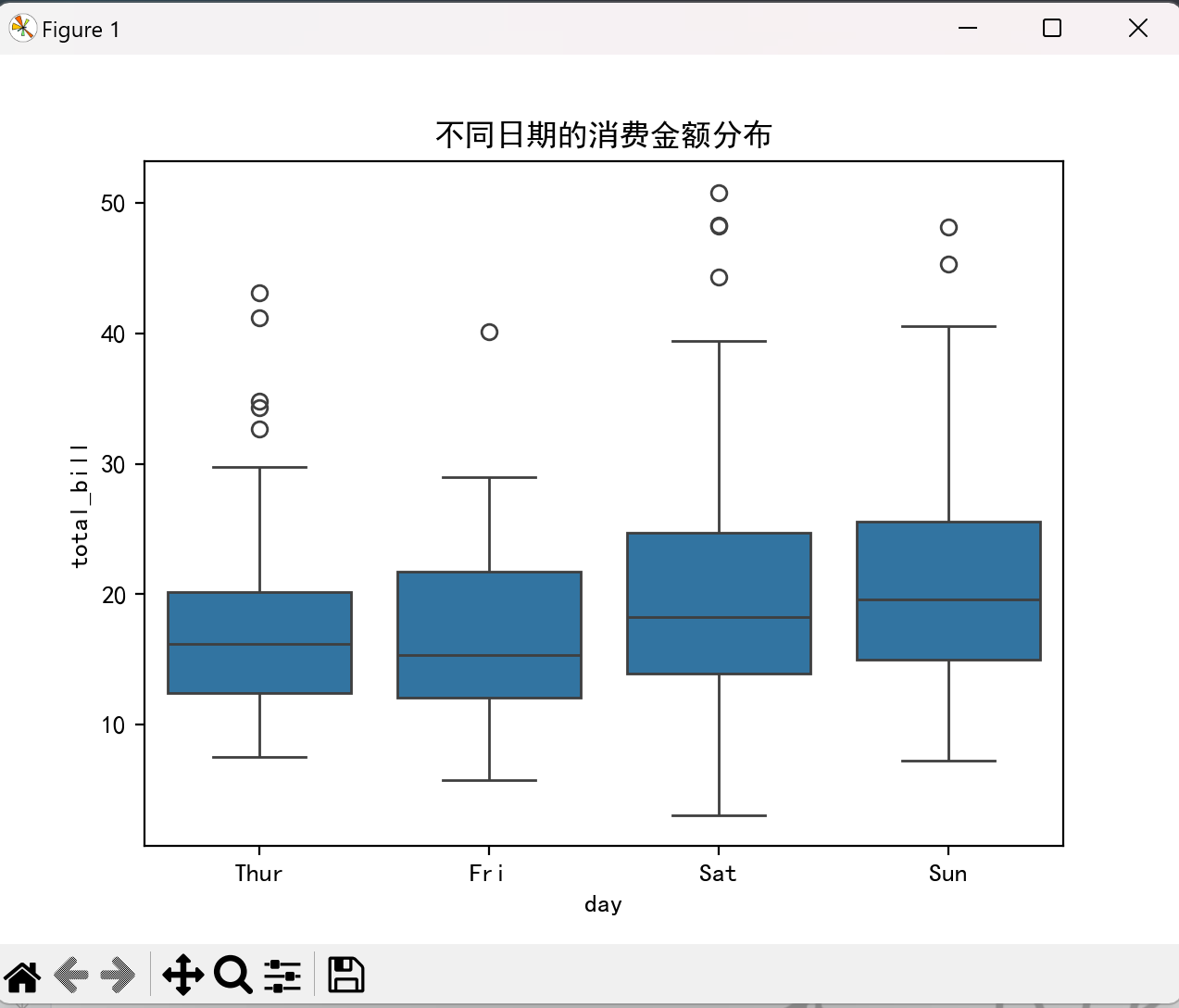
箱线图(boxplot)
箱线图能展示数据的分布特征(中位数、四分位数、异常值等):
点击查看代码
tips = sns.load_dataset("tips") # 加载内置数据集
sns.boxplot(x="day", y="total_bill", data=tips)
plt.title("不同日期的消费金额分布")
plt.show()
效果图如下:
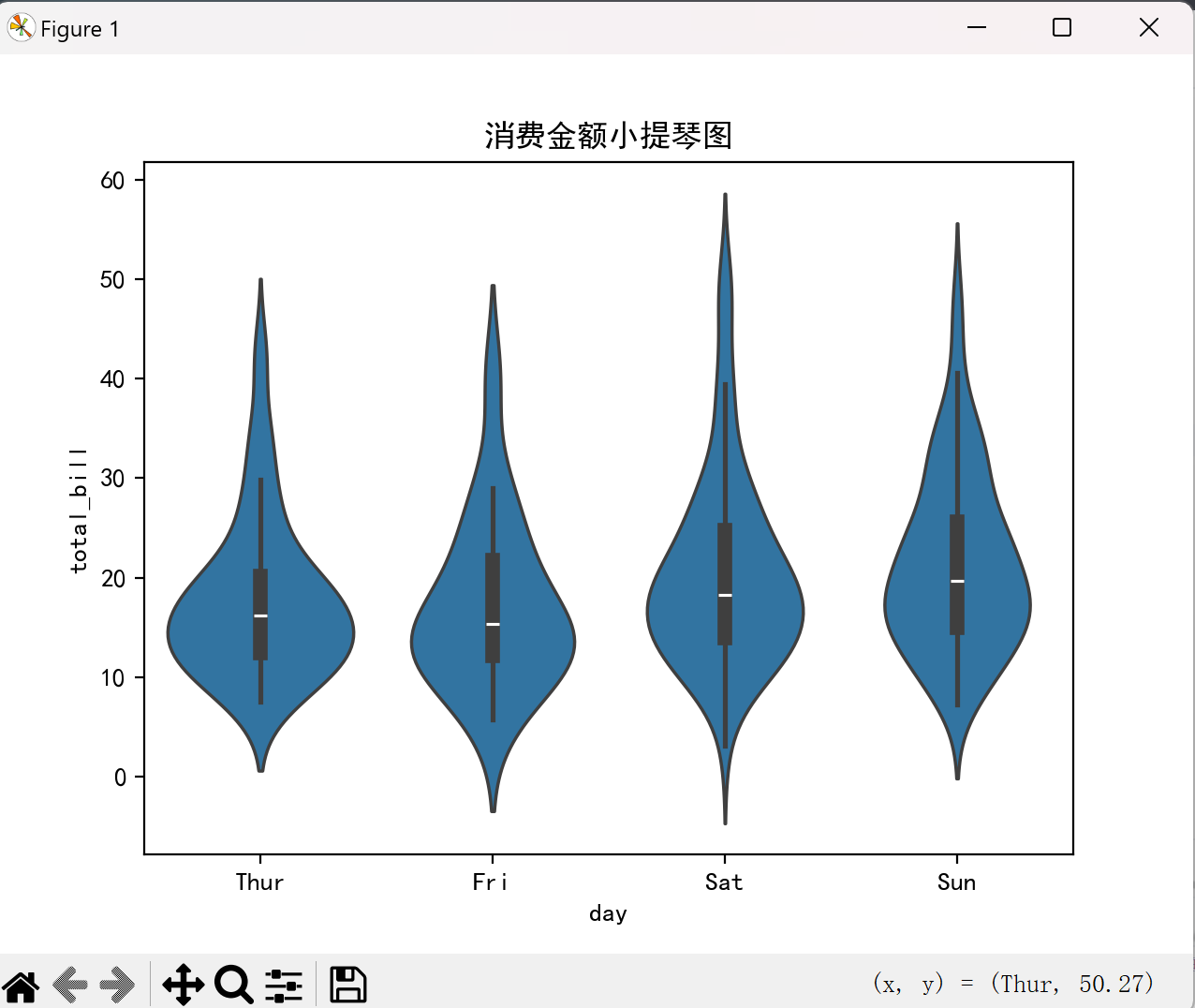
小提琴图(violinplot)
小提琴图结合了箱线图和核密度图的特点,能同时展示数据分布形状:
点击查看代码
sns.violinplot(x="day", y="total_bill", data=tips)
plt.title("消费金额小提琴图")
plt.show()
效果图如下:
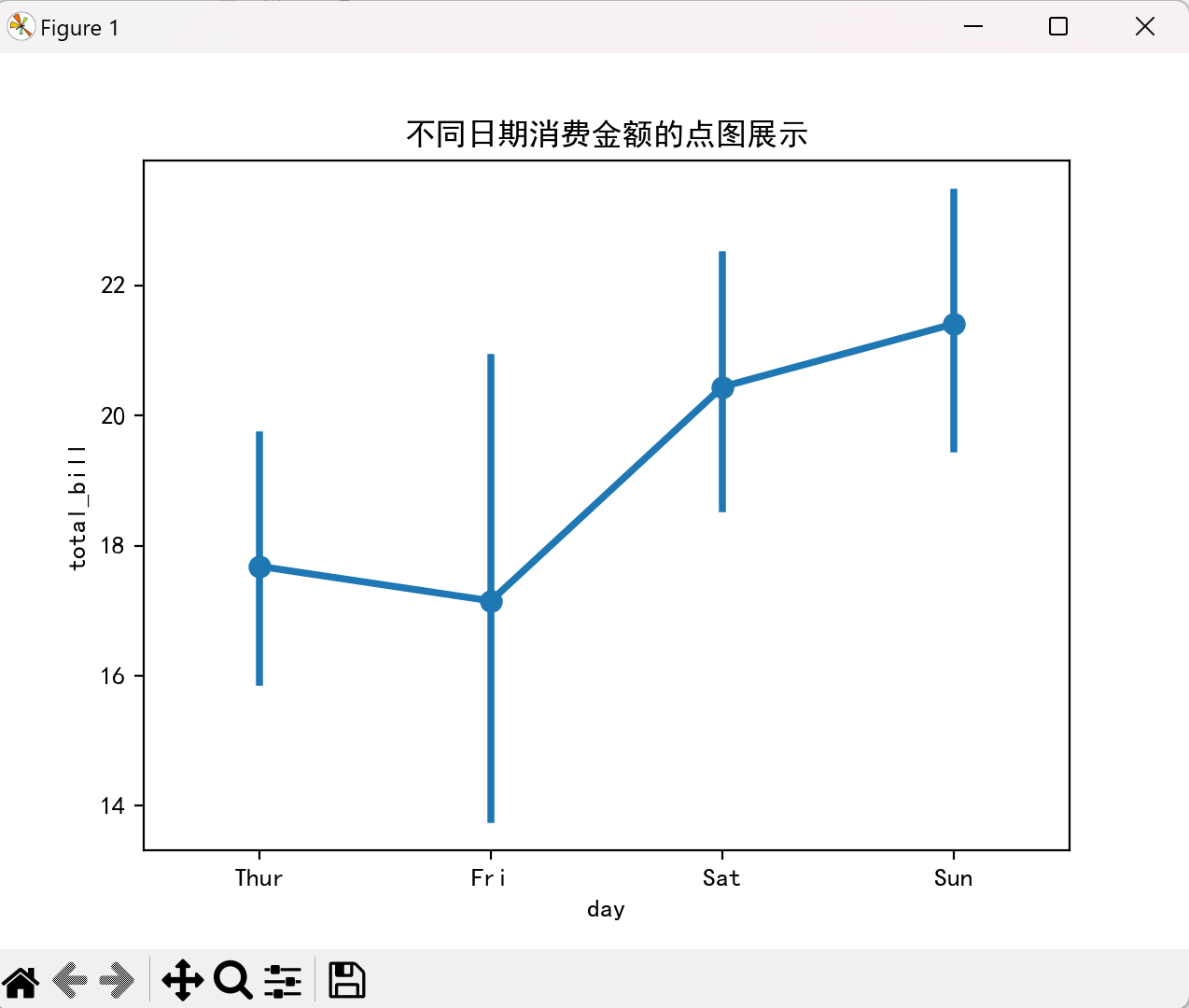
点图(pointplot)
点图适合展示不同类别的集中趋势和置信区间:
点击查看代码
sns.pointplot(x="day", y="total_bill", data=tips)
plt.title("不同日期消费金额的点图展示")
plt.show()
效果图如下:
四、实战案例:风景名胜区数据分析可视化
下面我们通过一个完整案例,展示如何将数据处理与可视化结合起来,分析我国风景名胜区的相关数据。
1. 数据准备与处理
首先加载数据并进行预处理(处理缺失值):
点击查看代码
import pandas as pd
import numpy as np
# 加载数据
scenery_file_path = open('风景名胜区.csv')
scenery_data = pd.read_csv(scenery_file_path)
# 计算缺失值填充值(平均值)
area_mean = float("{:.1f}".format(scenery_data['总面积(平方公里)'].mean()))
tourist_mean = float("{:.1f}".format(scenery_data['游客量(万人次)'].mean()))
# 填充缺失值
values = {"总面积(平方公里)": area_mean, "游客量(万人次)": tourist_mean}
scenery_data = scenery_data.fillna(value=values)
2. 数据分组与筛选
按省份分组,提取河北省的数据进行分析:
点击查看代码
# 按省份分组
province_data = scenery_data.groupby("省份")
# 提取河北省数据
hebei_scenery = dict([x for x in province_data])['河北']
3. 多维度可视化展示
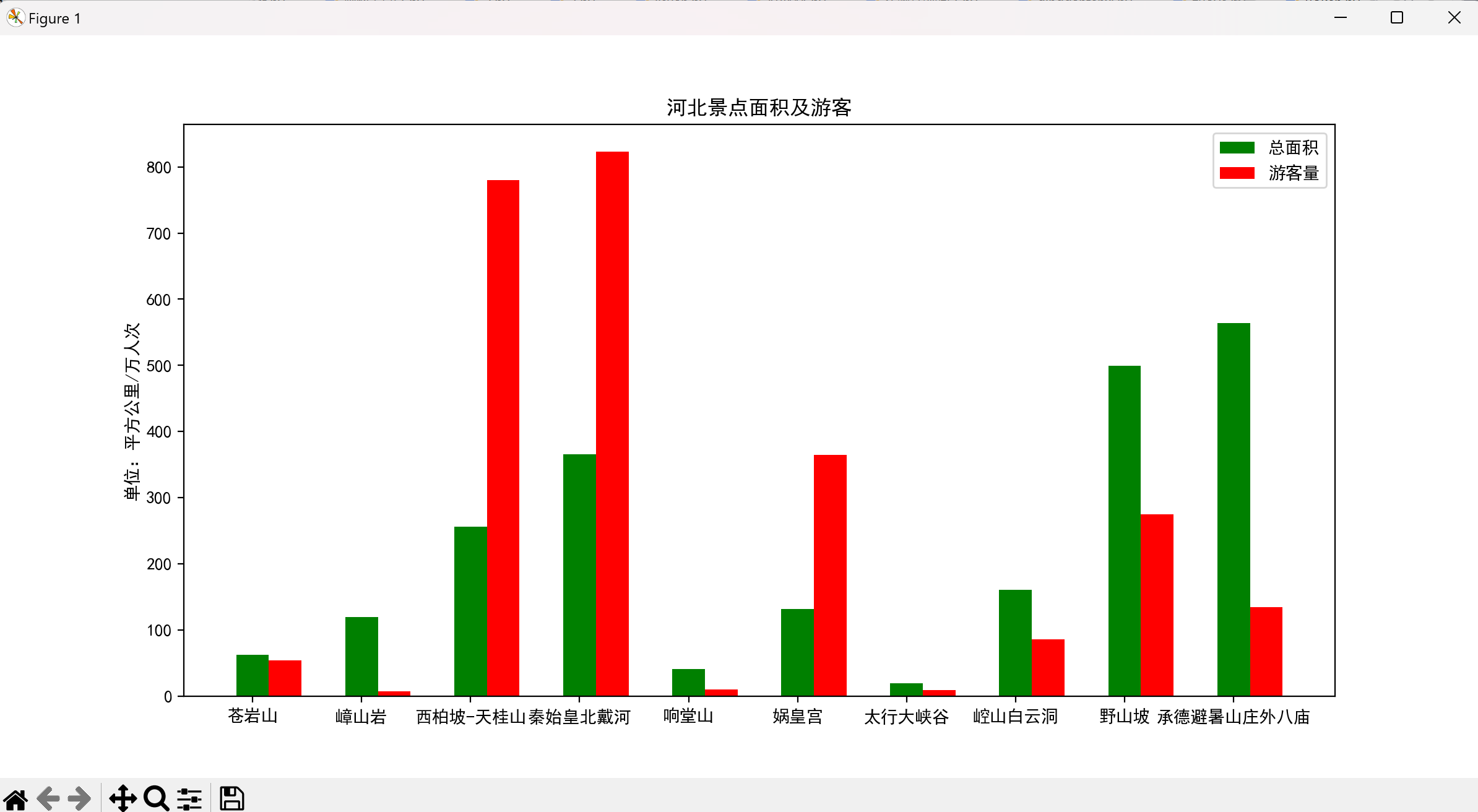
柱状图对比分析
对比河北省各景点的面积与游客量:
点击查看代码
# 设置中文显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 提取数据
area = hebei_scenery['总面积(平方公里)'].values
tourist = hebei_scenery['游客量(万人次)'].values
labels = ['苍岩山', '嶂山岩', '西柏坡-天桂山', '秦始皇北戴河', '响堂山',
'娲皇宫', '太行大峡谷', '崆山白云洞', '野山坡', '承德避暑山庄外八庙']
# 创建画布
plt.figure(figsize=(12, 6))
x_num = range(len(area))
x_dis = [i + 0.3 for i in x_num] # 错开柱状图位置
# 绘制柱状图
plt.bar(x_num, area, color='g', width=0.3, label='总面积')
plt.bar(x_dis, tourist, color='r', width=0.3, label='游客量')
# 添加图表元素
plt.ylabel('单位:平方公里/万人次')
plt.title('河北景点面积及游客量对比')
plt.legend(loc='upper right')
plt.xticks([i + 0.15 for i in x_num], labels, rotation=45) # 旋转标签避免重叠
plt.tight_layout() # 自动调整布局
plt.show()
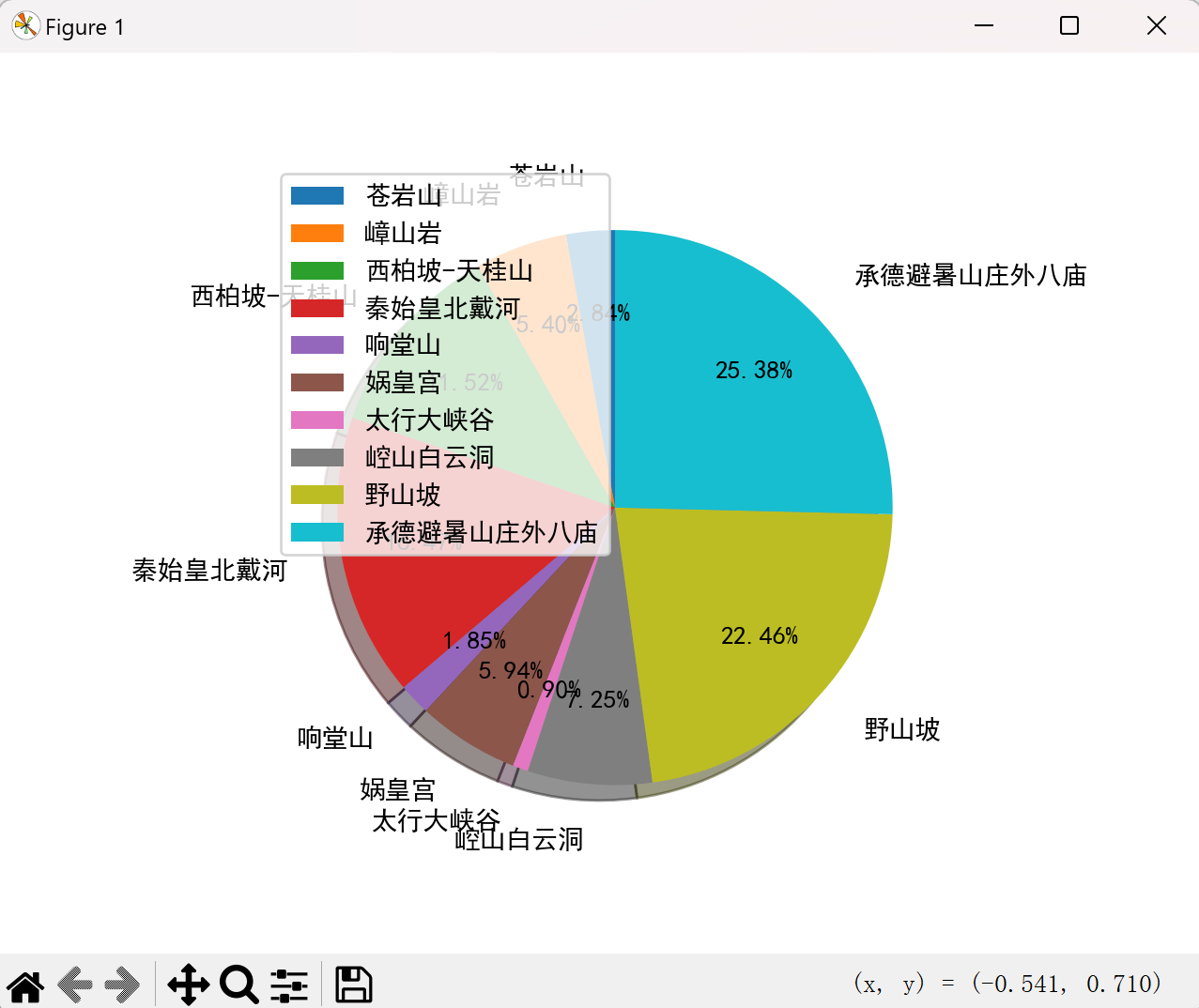
饼图占比分析
分析各景点面积占总面积的比例:
点击查看代码
# 计算各景点面积占比
total_area = hebei_scenery['游客量(万人次)'].sum()
area_ratio = (hebei_scenery['总面积(平方公里)'].values / total_area) * 100
# 绘制饼图
plt.axes(aspect=1) # 保证饼图为正圆形
plt.pie(
x=area_ratio,
labels=labels,
autopct='%3.2f%%', # 显示百分比
shadow=True, # 添加阴影效果
labeldistance=1.2, # 标签距离圆心的距离
startangle=90, # 起始角度
pctdistance=0.7 # 百分比距离圆心的距离
)
plt.legend(loc='upper left', bbox_to_anchor=(1, 1)) # 图例放在图表外部
plt.title('河北各景点面积占比')
plt.show()
运行截图如下:
五、总结
本文介绍了 Python 数据可视化的两大核心库:Matplotlib 和 Seaborn,从基础的图表绘制到实战案例分析,涵盖了数据可视化的主要流程。通过这些工具,我们可以轻松实现:
- 基础图表绘制(折线图、柱状图、散点图等)
- 统计分布可视化(直方图、核密度图等)
- 分类数据对比(箱线图、小提琴图等)
- 实际业务数据的多维度分析
数据可视化的关键不仅在于掌握工具的使用,更在于理解数据特点并选择合适的图表类型。希望本文能帮助你快速入门 Python 数据可视化,并应用到实际工作中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号