

在数据驱动的时代,“高质量数据” 是数据分析、机器学习项目成功的核心前提。但现实中,我们常面临两大难题:如何高效获取目标数据?以及如何将原始数据打磨成 “干净可用” 的格式?本文将结合实际爬虫代码案例与数据预处理流程,带你从 0 到 1 掌握数据获取与预处理的关键步骤,覆盖网络爬虫实践、缺失值处理、异常值检测、数据标准化等核心环节。
一、数据获取:三大途径与爬虫实战
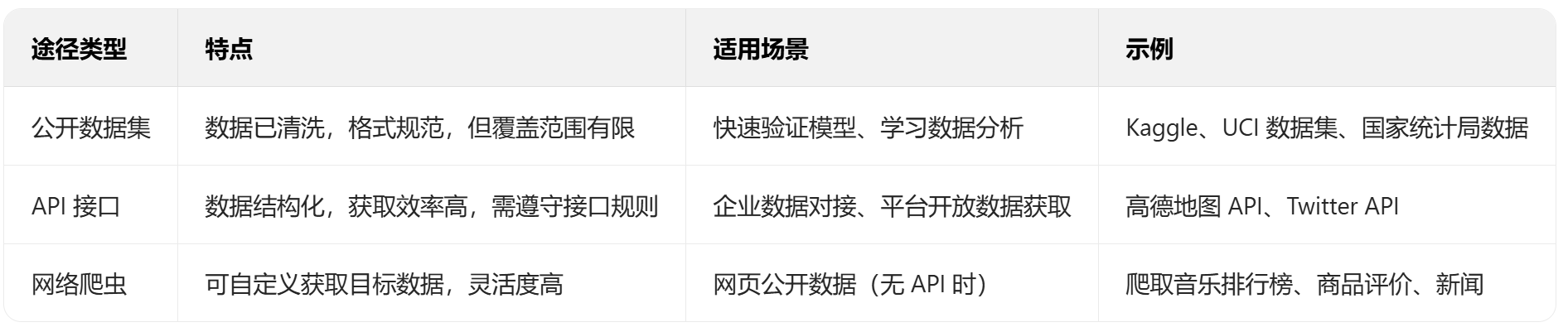
数据获取的途径可分为三类:公开数据集、API 接口、网络爬虫。其中,网络爬虫是获取 “非结构化公开数据”(如网页中的排行榜、商品信息)的核心手段,本文将重点结合「酷狗音乐排行榜爬取」案例,拆解爬虫实现细节。
- 常见数据获取途径对比
![image]()
- 网络爬虫实战:爬取酷狗音乐 TOP500 排行榜
以「2TOP500.py」和「1suogou.py」代码为例,我们从 “环境准备→网页请求→数据解析→数据保存” 四个步骤,完整实现爬虫逻辑。
步骤 1:环境准备
首先安装爬虫必备库,requests用于发送 HTTP 请求,BeautifulSoup用于解析 HTML,pandas用于后续数据处理:
pip install requests beautifulsoup4 lxml pandas
步骤 2:发送网页请求(避免被反爬)
目标网页:酷狗音乐排行榜(https://www.kugou.com/yy/rank/home/1-8888.html)
核心注意点:设置 User-Agent 伪装浏览器,避免被服务器识别为 “爬虫” 而拒绝请求。
参考「2TOP500.py」的get_html函数实现:
点击查看代码
import requests
def get_html(url):
# 伪装浏览器请求头,关键在于User-Agent字段
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36'
}
response = requests.get(url, headers=headers)
# 验证请求是否成功(状态码200表示正常)
if response.status_code == 200:
response.encoding = 'utf-8' # 避免中文乱码
return response.text
else:
print(f"请求失败,状态码:{response.status_code}")
return None
点击查看代码
from bs4 import BeautifulSoup
def get_infos(html):
soup = BeautifulSoup(html, 'html.parser') # 用html.parser解析HTML
# 1. 提取所有排名标签
ranks = soup.select('#rankWrap > div.pc_temp_songlist > ul > li > span.pc_temp_num')
# 2. 提取所有歌手+歌名标签
names = soup.select('#rankWrap > div.pc_temp_songlist > ul > li > a')
# 3. 提取所有时长标签
times = soup.select('#rankWrap > div.pc_temp_songlist > ul > li > span.pc_temp_tips_r > span')
# 循环提取并清洗数据
for r, n, t in zip(ranks, names, times):
# 清洗排名:去除换行、制表符等空白字符
rank = r.get_text().replace('\n', '').replace('\t', '').replace('\r', '').strip()
# 拆分歌手与歌名:按“ - ”分割(限制只分割1次,避免歌名含“-”)
name_text = n.get_text().strip()
song_name, singer = name_text.split(' - ', 1) # 1表示最多分割1次
# 清洗时长:去除空白字符
duration = t.get_text().replace('\n', '').replace('\t', '').replace('\r', '').strip()
# 输出结构化数据
print(f"排名:{rank}, 歌手:{singer}, 歌名:{song_name}, 时长:{duration}")
点击查看代码
import csv
import time
def main():
# 生成23页的URL(页码1-23)
urls = [f'https://www.kugou.com/yy/rank/home/{i}-8888.html?from=rank' for i in range(1, 24)]
# 准备保存到CSV
with open('kugou_top500.csv', 'w', encoding='utf-8', newline='') as f:
writer = csv.writer(f)
writer.writerow(['排名', '歌手', '歌名', '时长']) # 表头
for url in urls:
html = get_html(url)
if html:
soup = BeautifulSoup(html, 'html.parser')
ranks = soup.select('#rankWrap > div.pc_temp_songlist > ul > li > span.pc_temp_num')
names = soup.select('#rankWrap > div.pc_temp_songlist > ul > li > a')
times = soup.select('#rankWrap > div.pc_temp_songlist > ul > li > span.pc_temp_tips_r > span')
for r, n, t in zip(ranks, names, times):
# 重复步骤3的数据清洗逻辑
rank = r.get_text().replace('\n', '').replace('\t', '').replace('\r', '').strip()
song_name, singer = n.get_text().strip().split(' - ', 1)
duration = t.get_text().replace('\n', '').replace('\t', '').replace('\r', '').strip()
writer.writerow([rank, singer, song_name, duration])
time.sleep(1) # 每页爬取后暂停1秒,降低反爬风险
print(f"已爬取:{url}")
if __name__ == '__main__':
main()
点击查看代码
import pandas as pd
# 读取爬取的原始数据
df = pd.read_csv('kugou_top500.csv')
# 1. 查看缺失值情况
print("缺失值统计:")
print(df.isnull().sum()) # 输出每列的缺失值数量
# 2. 处理“时长”列的缺失值(假设缺失占比低,直接删除)
df_clean = df.dropna(subset=['时长'], axis=0)
print(f"\n处理前数据量:{len(df)},处理后数据量:{len(df_clean)}")
点击查看代码
import matplotlib.pyplot as plt
# 先将“时长”转换为秒(便于计算)
def time_to_seconds(time_str):
minute, second = time_str.split(':')
return int(minute) * 60 + int(second)
df_clean['时长_秒'] = df_clean['时长'].apply(time_to_seconds)
# 绘制箱线图
plt.figure(figsize=(8, 4))
plt.boxplot(df_clean['时长_秒'], labels=['歌曲时长(秒)'])
plt.title('酷狗TOP500歌曲时长箱线图(识别异常值)')
plt.grid(True, linestyle='--', alpha=0.7)
plt.show()
点击查看代码
import numpy as np
# 计算Z-score
df_clean['Z_score'] = (df_clean['时长_秒'] - df_clean['时长_秒'].mean()) / df_clean['时长_秒'].std()
# 识别异常值(|Z-score|>3)
outliers = df_clean[abs(df_clean['Z_score']) > 3]
print("异常值数据:")
print(outliers[['排名', '歌手', '歌名', '时长', '时长_秒', 'Z_score']])
# 处理异常值(用中位数替换)
median_duration = df_clean['时长_秒'].median()
df_clean.loc[abs(df_clean['Z_score']) > 3, '时长_秒'] = median_duration
print(f"\n异常值替换为中位数:{median_duration}秒")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号