

Numpy库
一、引言
Numpy是Python中用于科学计算的核心库,提供了高效的多维数组运算和数学函数支持。
二、Numpy 核心数据结构之 ndarray
ndarray,即 n-dimensional array(n维数组),是 Numpy 库的核心数据结构,用于存储多维数组。它具备诸多特性,使其在数据处理中优势尽显。
- 多维存储能力:ndarray 可以轻松存储一维、二维、三维乃至更高维度的数组。
- 元素类型多样:其元素类型可以是整数、浮点数、复数等常规数值类型。不仅如此,Numpy 还支持自定义数据类型,如 uint8、int32、float64 等。
- 元素有序存储:ndarray 中的元素是有序的,这一特性在许多场景下至关重要。
2.1 创建ndarray数组
- 通过已有数据结构创建:利用np.array()函数,括号内可以传入列表、元组、数组、生成器等。比如:
import numpy as np
# 从列表创建一维数组
ar1 = np.array([1, 2, 3, 4, 5])
# 从元组创建浮点型一维数组
ar2 = np.array((1, 2, 3.14, 4, 5))
# 从嵌套列表创建二维数组
ar3 = np.array([[1, 2, 3], ['a', 'b', 'c']])
- 使用特定函数创建:
- np.arange():类似于 Python 内置的range()函数,在给定间隔内返回均匀间隔的值。例如:
#生成一个包含0到9的一维数组
ar4 = np.arange(10)
- np.linspace():返回在指定间隔(开始,停止)上计算的指定数量的均匀间隔样本。例如:
#生成一个在0到1之间均匀分布的包含5个元素的数组
ar5 = np.linspace(0, 1, 5)
- np.ones()和np.zeros():分别用于创建全为 1 和全为 0 的数组。例如:
#创建一3行2列全为1的二维数组ones_array和一个2行3列全为0的二维数组zeros_array
ones_array = np.ones((3, 2))
zeros_array = np.zeros((2, 3))
- np.eye():创建一个正方的 N*N 的单位矩阵,对角线值为 1,其余为 0。例如:
#生成一个4*4的单位矩阵
eye_array = np.eye(4)
2.2 ndarray对象中定义的重要属性
| 属性 | 具体说明 |
|---|---|
| ndarray.ndia | 维度个数,也就是数组轴的个数,比如一维、二维、三维等 |
| ndarray.shape | 数组的维度。这是一个整数的元组,表示每个维度上数组的大小。例如,一个n行和 m 列的数组,它的 shape 属性为(n.m) |
| ndarray.size | 数组元素的总个数,等于 shape 属性中元组元素的乘积 |
| ndarray.dtype | 描述数组中元素类型的对象,既可以使用标准的 Python 类型创建或指定,也可以使用 NumPy 特有的数据类型来指定,比如numpy.int32、numpy.float64等 |
| ndarray itemsize | 数组中每个元素的字节大小。例如,元素类型为 noat64 的数组有8(64/8)个字节,这相当于ndarray.dtype.itemsize |
- 维度(ndim)
#一维数组,输出结果为1
ar1 = np.array([1, 2, 3, 4, 5, 6, 7])
print(ar1.ndim)
#二维数组,输出结果为2
ar2 = np.array([[1, 2], [3, 4]])
print(ar2.ndim)
- 形状(shape)
#2行3列的二维数组,输出结果为(2, 3)
ar = np.array([[1, 2, 3], [4, 5, 6]])
print(ar.shape)
- 元素总数(size)
#size等于shape中各维度大小的乘积,输出结果为6
ar = np.array([[1, 2, 3], [4, 5, 6]])
print(ar.size)
- 数据类型(dtype)
#描述数组中元素的数据类型,输出结果可能为int64
ar = np.array([1, 2, 3, 4, 5])
print(ar.dtype)
- 元素字节大小(itemsize)
#数组中每个元素占用的字节数,输出结果为 4
ar = np.array([1, 2, 3], dtype=np.int32)
print(ar.itemsize)
2.3 ndarray的操作
- 索引与切片
- 一维数组:
从 0 开始计数,也支持负数索引(从后向前)。切片语法array[start:stop:step],其中start为起始索引(包含),默认为 0;stop为结束索引(不包含),默认为数组长度;step为步长,默认为 1。
ar = np.array([10, 20, 30, 40, 50])
print(ar[2])
print(ar[1:4])
print(ar[::2])
#分别输出 30、[20 30 40]、[10 30 50]
- 二维数组:
ar = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
print(ar[1, 2])
print(ar[:, 1])
#ar[1, 2]表示第 2 行第 3 列的元素,ar[:, 1]表示取所有行的第 2 列元素。分别输出 6、[2 5 8]
- 数组形状变换
- 转置(.T):使用.T方法可以对数组进行转置。对于原形状为 (3, 4) 的二维数组,转置后形状变为 (4, 3)。需要注意的是,一维数组转置后结果不变。
ar = np.array([[1, 2, 3], [4, 5, 6]])
print(ar.T)
#输出结果为形状为 (3, 2) 的转置数组
- 重塑(.reshape ()):reshape()方法可以改变数组的形状,但要保证变换前后数组的元素总数一致。
ar1 = np.arange(10)
# 直接将已有数组改变形状
ar2 = ar1.reshape(2, 5)
# 生成数组后直接改变形状
ar3 = np.zeros((4, 6)).reshape(3, 8)
# 参数内添加数组,指定目标形状
ar4 = np.reshape(np.arange(12), (3, 4))
- 调整大小(.resize ()):resize()方法返回具有指定形状的新数组,如有必要会重复填充所需数量的元素。与.reshape()不同的是,.resize()会修改原数组。
ar = np.array([1, 2, 3])
ar.resize(5)
print(ar)
#原数组被扩展为长度为 5 的数组,后面的元素通过重复前面的元素来填充。输出结果可能为 [1 2 3 1 2]
- 数组运算
- 矢量化运算(形状相同的数组)
# 矢量化相加,输出结果为[[6 8] [10 12]]
arr1 = np.array([[1, 2], [3, 4]])
arr2 = np.array([[5, 6], [7, 8]])
arr_vector = arr1 + arr2
print(arr_vector)
- 广播机制(形状不同的数组)
# 广播机制相加,输出结果为[[11 22] [13 24]]
arr3 = np.array([[1, 2], [3, 4]])
arr4 = np.array([10, 20])
arr_broadcast = arr3 + arr4
print(arr_broadcast)
- 数组与标量运算(标量)
# 数组与标量相加,输出结果为[[11 12 13] [14 15 16]]
arr = np.array([[1, 2, 3], [4, 5, 6]])
arr_add = arr + 10
print(arr_add)
- 数组排序
arr_random = np.array([3, 1, 4, 2, 5])
# 数组排序,输出结果为[1 2 3 4 5]
arr_sorted = np.sort(arr_random)
print(arr_sorted)
- 随机数模块(生成随机数组)
print(np.random.rand(3,3))
#random函数,输出结果为[[0.70557029 0.83541402 0.86853414]
[0.59086315 0.85581437 0.06283888]
[0.20816329 0.73812082 0.44611151]]
print(numpy.random.seed(seed=None))
#seed函数可以保证生成的随机数具有可预测性,用于指定随机数生成时所用算法开始的整数值,输出结果为None
Numpy 中的矩阵(matrix)
- 矩阵的创建:
mat1 = np.matrix([[1, 2], [3, 4]])
ar = np.array([[5, 6], [7, 8]])
mat2 = np.asmatrix(ar)
- 矩阵的运算:
- 矩阵乘法:
#使用np.dot()函数进行矩阵乘法运算,输出结果为[[19 22][43 50]]
mat1 = np.matrix([[1, 2], [3, 4]])
mat2 = np.matrix([[5, 6], [7, 8]])
result = np.dot(mat1,mat2)
print(result)
- 矩阵转置:
#通过.T属性进行转置,输出结果为[[1 3] [2 4]]
mat = np.matrix([[1, 2], [3, 4]])
print(mat.T)
- 求逆矩阵:
#使用np.linalg.inv()函数,输出结果为[[-2. 1.] [1.5 -0.5]]
mat = np.matrix([[1, 2], [3, 4]])
inv_mat = np.linalg.inv(mat)
print(inv_mat)
Pandas库
一、引言
在数据分析领域,Pandas 是 Python 生态中当之无愧的核心工具库。它专为处理结构化数据(如表格、CSV 文件、数据库表等)设计,提供了简洁高效的数据结构和丰富的操作方法,能极大简化数据清洗、转换、分析与可视化的流程。
二、Pandas 核心数据结构:Series 与 DataFrame
Pandas 的所有操作都围绕两种核心数据结构展开:一维的 Series和二维的 DataFrame。
2.1 一维数据结构:Series
Series 是类似 “带索引的数组” 的一维对象,由两部分组成:
- 数据(values):可存储整数、浮点数、字符串等任意类型数据;
- 索引(index):与数据一一对应,默认是从 0 开始的整数索引,也可自定义。
2.1.1 创建 Series
Series 的构造方法为:
pd.Series(data=None, index=None, dtype=None, name=None)
代码示例 1:用列表创建 Series(默认索引与自定义索引)
点击查看代码
import pandas as pd
# 1. 默认整数索引
ser1 = pd.Series([10, 20, 30, 40, 50])
print("默认索引的Series:")
print(ser1)
# 输出:
# 0 10
# 1 20
# 2 30
# 3 40
# 4 50
# dtype: int64
# 2. 自定义索引(字符串索引)
ser2 = pd.Series([10, 20, 30, 40, 50], index=['a', 'b', 'c', 'd', 'e'])
print("\n自定义索引的Series:")
print(ser2)
# 输出:
# a 10
# b 20
# c 30
# d 40
# e 50
# dtype: int64
代码示例 2:用字典创建 Series(字典的 key 自动作为索引)
点击查看代码
# 年份-销售额数据(字典)
year_sales = {2020: 150, 2021: 200, 2022: 280, 2023: 350}
ser3 = pd.Series(year_sales)
print("字典创建的Series:")
print(ser3)
# 输出:
# 2020 150
# 2021 200
# 2022 280
# 2023 350
# dtype: int64
2.1.2 访问 Series 的索引与数据
通过index属性获取索引,values属性获取数据:
点击查看代码
# 获取索引
print("ser2的索引:", ser2.index) # 输出:Index(['a', 'b', 'c', 'd', 'e'], dtype='object')
# 获取数据(返回numpy数组)
print("ser2的数据:", ser2.values) # 输出:[10 20 30 40 50]
# 通过索引访问单个数据(两种方式:位置索引、名称索引)
print("\n位置索引3对应的数据:", ser2[3]) # 输出:40(位置从0开始)
print("名称索引'c'对应的数据:", ser2['c']) # 输出:30
2.1.3 Series 的运算特性
Series 运算后,索引与数据的对应关系会保持不变(这是 Pandas 的核心特性之一):
点击查看代码
# 所有数据乘以2
ser2_double = ser2 * 2
print("ser2乘以2后:")
print(ser2_double)
# 输出:
# a 20
# b 40
# c 60
# d 80
# e 100
# dtype: int64
2.2 二维数据结构:DataFrame
DataFrame 是类似 “Excel 表格” 的二维对象,具备:
- 行索引(index):对应表格的 “行标签”;
- 列索引(columns):对应表格的 “列名”;
- 数据(values):二维数组,每列可存储不同类型数据(如一列整数、一列字符串)。
2.2.1 创建 DataFrame
DataFrame 的构造方法为:
pd.DataFrame(data=None, index=None, columns=None, dtype=None)
代码示例 1:用二维数组创建 DataFrame
点击查看代码
import numpy as np
# 二维数组(3行2列)
arr = np.array([['张三', 25], ['李四', 30], ['王五', 28]])
# 创建DataFrame并指定列索引
df1 = pd.DataFrame(arr, columns=['姓名', '年龄'])
print("二维数组创建的DataFrame:")
print(df1)
# 输出:
# 姓名 年龄
# 0 张三 25
# 1 李四 30
# 2 王五 28
点击查看代码
# 字典的value是列表(每列数据)
data_dict = {
'姓名': ['张三', '李四', '王五'],
'年龄': [25, 30, 28],
'部门': ['技术部', '产品部', '市场部']
}
df2 = pd.DataFrame(data_dict)
print("\n字典创建的DataFrame:")
print(df2)
# 输出:
# 姓名 年龄 部门
# 0 张三 25 技术部
# 1 李四 30 产品部
# 2 王五 28 市场部
2.2.2 访问 DataFrame 的列数据
DataFrame 的列数据本质是 Series 对象,有两种访问方式:
- 列索引方式(推荐):df['列名'],支持列名含特殊字符(如空格);
- 属性方式:df.列名,列名不能含特殊字符。
点击查看代码
# 1. 列索引方式(推荐)
dept_col = df2['部门']
print("'部门'列数据(索引方式):")
print(dept_col)
print("数据类型:", type(dept_col)) # 输出:<class 'pandas.core.series.Series'>
# 2. 属性方式(列名无特殊字符时可用)
age_col = df2.年龄
print("\n'年龄'列数据(属性方式):")
print(age_col)
2.2.3 新增与删除 DataFrame 的列
- 新增列:直接给新列名赋值;
- 删除列:用del语句或drop()方法。
点击查看代码
# 1. 新增列(如“薪资”)
df2['薪资'] = [15000, 18000, 16000]
print("新增'薪资'列后:")
print(df2)
# 2. 删除列(删除“部门”列)
del df2['部门'] # 或 df2.drop('部门', axis=1, inplace=True)
print("\n删除'部门'列后:")
print(df2)
# 输出:
# 姓名 年龄 薪资
# 0 张三 25 15000
# 1 李四 30 18000
# 2 王五 28 16000
三、Pandas索引操作及高级索引
3.1 索引对象(Index)的特性
Pandas 中的索引(Index)是不可修改的(immutable),目的是保障数据与索引的对应关系不被意外破坏:
常见的 Index 子类:
- Int64Index:整数类型索引;
- DatetimeIndex:时间戳索引(用于时间序列数据);
- MultiIndex:层次化索引。
3.2 重置索引:reindex () 方法
reindex()用于根据新索引重新排列数据,核心作用:
- 新索引包含原索引:按新索引顺序排列数据;
- 新索引有原索引没有的项:用fill_value填充缺失值,或用method插值填充。
点击查看代码
# 原Series
ser4 = pd.Series([10, 20, 30], index=['a', 'b', 'c'])
# 1. 新索引含原索引,且新增'd'、'e'
ser4_reindex1 = ser4.reindex(['a', 'b', 'c', 'd', 'e'], fill_value=0)
print("用fill_value=0填充缺失值:")
print(ser4_reindex1)
# 输出:
# a 10
# b 20
# c 30
# d 0
# e 0
# dtype: int64
# 2. 用前向填充(ffill)填充缺失值
ser5 = pd.Series([10, 20, 30], index=[1, 3, 5])
ser5_reindex = ser5.reindex([1, 2, 3, 4, 5], method='ffill') # ffill=前向填充
print("\n前向填充缺失值:")
print(ser5_reindex)
# 输出:
# 1 10
# 2 10 (填充前一个值10)
# 3 20
# 4 20 (填充前一个值20)
# 5 30
# dtype: int64
3.3 高级索引:loc与iloc
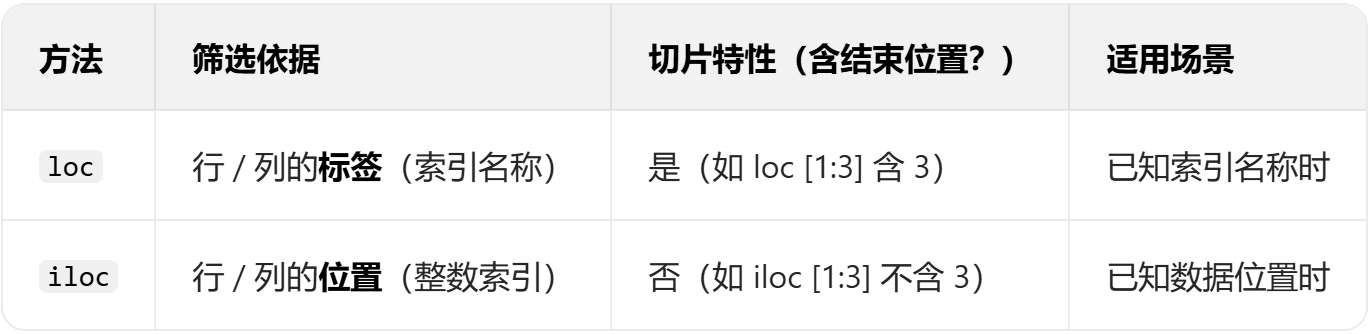
3.3.1 loc:基于标签筛选
点击查看代码
# 准备DataFrame
df3 = pd.DataFrame({
'姓名': ['张三', '李四', '王五', '赵六'],
'年龄': [25, 30, 28, 35],
'薪资': [15000, 18000, 16000, 20000]
}, index=['A', 'B', 'C', 'D']) # 自定义行标签
# 1. 筛选单行(行标签'A')
print("行标签'A'的数据:")
print(df3.loc['A'])
# 2. 筛选多行(行标签'A'到'C',含'C')
print("\n行标签'A'到'C'的数据:")
print(df3.loc['A':'C'])
# 3. 筛选行+列(行'A'到'C',列'姓名'和'薪资')
print("\n行'A'-'C',列'姓名'-'薪资':")
print(df3.loc['A':'C', ['姓名', '薪资']])
3.3.2 iloc:基于位置筛选
点击查看代码
# 1. 筛选单行(位置0,即第一行)
print("位置0的数据:")
print(df3.iloc[0])
# 2. 筛选多行(位置0到2,不含2)
print("\n位置0到2的数据:")
print(df3.iloc[0:2])
# 3. 筛选行+列(位置0到2,列位置0和2)
print("\n行0-2,列0和2:")
print(df3.iloc[0:2, [0, 2]])
四、算术运算与数据对齐
Pandas 的算术运算(加、减、乘、除)会先按索引对齐,再进行运算;未对齐的位置会填充NaN(缺失值)。
自动索引对齐
点击查看代码
# 两个Series(索引部分重叠)
ser6 = pd.Series([10, 20, 30], index=['a', 'b', 'c'])
ser7 = pd.Series([5, 15, 25], index=['b', 'c', 'd'])
# 加法运算(按索引对齐,未对齐的'd'和'a'填充NaN)
ser_add = ser6 + ser7
print("ser6 + ser7(自动对齐):")
print(ser_add)
# 输出:
# a NaN
# b 25.0
# c 55.0
# d NaN
# dtype: float64
五、数据排序
Pandas支持两种排序方式:按索引排序(sort_index)和按值排序(sort_values)。
5.1 按索引排序:sort_index()
核心参数:
axis:排序轴,0 = 按行索引,1 = 按列索引;
ascending:是否升序,True(默认)= 升序,False= 降序。
点击查看代码
# 1. Series按索引排序
ser8 = pd.Series([3, 1, 4, 2], index=[4, 2, 3, 1])
print("Series按索引升序:")
print(ser8.sort_index()) # 按索引1、2、3、4排序
print("\nSeries按索引降序:")
print(ser8.sort_index(ascending=False)) # 按索引4、3、2、1排序
# 2. DataFrame按行索引排序
df4 = pd.DataFrame(np.arange(9).reshape(3, 3), index=[3, 1, 2])
print("\nDataFrame按行索引升序:")
print(df4.sort_index())
5.2 按值排序:sort_values()
核心参数:
by:指定排序的列(DataFrame 必传);
na_position:NaN值的位置,last(默认)= 放最后,first= 放最前。
点击查看代码
# 1. Series按值排序(含NaN)
ser9 = pd.Series([4, np.nan, 2, 5, -1])
print("Series按值升序(NaN放最后):")
print(ser9.sort_values()) # -1、2、4、5、NaN
# 2. DataFrame按列值排序
df5 = pd.DataFrame({
'col1': [3, 1, 2],
'col2': [5, 4, 6]
})
print("\nDataFrame按'col1'升序:")
print(df5.sort_values(by='col1'))
print("\nDataFrame按'col2'降序:")
print(df5.sort_values(by='col2', ascending=False))
六、统计计算与描述
6.1 最常用的统计方法

代码示例:
点击查看代码
# 准备数据
df6 = pd.DataFrame({
'数学': [85, 92, 78, 90, np.nan],
'语文': [76, 88, 95, 82, 80],
'英语': [90, 85, 88, 92, 79]
})
# 计算每列的均值(默认忽略NaN)
print("每列均值:")
print(df6.mean())
# 输出:
# 数学 86.25
# 语文 84.20
# 英语 86.80
# dtype: float64
# 计算每列的最大值
print("\n每列最大值:")
print(df6.max())
# 计算数学列的中位数
print("\n数学列中位数:", df6['数学'].median())
6.2 一次性输出多统计指标:describe()
describe()方法会自动计算数值型列的核心统计指标(计数、均值、标准差、分位数、最值):
点击查看代码
print("df6的统计描述:")
print(df6.describe())
# 输出:
# 数学 语文 英语
# count 4.000000 5.000000 5.000000
# mean 86.250000 84.200000 86.800000
# std 5.916080 7.266360 4.764452
# min 78.000000 76.000000 79.000000
# 25% 83.250000 80.000000 85.000000
# 50% 87.500000 82.000000 88.000000
# 75% 90.500000 88.000000 90.000000
# max 92.000000 95.000000 92.000000
可通过percentiles参数自定义分位数:
点击查看代码
# 自定义分位数(10%、50%、90%)
print("\n自定义分位数的统计描述:")
print(df6.describe(percentiles=[0.1, 0.5, 0.9]))
七、层次化索引(MultiIndex)
层次化索引是指在单个轴上有多层索引,适用于多维数据的简化表示(如 “省份 - 城市”“类别 - 产品”)。
7.1 创建层次化索引
7.1.1 方法 1:构造方法传嵌套列表
点击查看代码
# 数据:省份-城市的人口(单位:万人)
pop_data = [1124, 954, 886, 765, 1020, 830]
# 嵌套列表索引:外层=省份,内层=城市
index = [
['河北省', '河北省', '河北省', '河南省', '河南省', '河南省'],
['石家庄', '唐山', '邯郸', '郑州', '洛阳', '开封']
]
# 创建层次化索引的Series
ser_multi1 = pd.Series(pop_data, index=index)
print("层次化索引的Series:")
print(ser_multi1)
# 输出:
# 河北省 石家庄 1124
# 唐山 954
# 邯郸 886
# 河南省 郑州 1020
# 洛阳 830
# 开封 765
# dtype: int64
7.1.2 方法 2:用 MultiIndex 类创建
MultiIndex 提供了 3 种常用创建方法:
- from_tuples():元组列表→MultiIndex;
- from_arrays():数组列表→MultiIndex;
- from_product():多个集合的笛卡尔积→MultiIndex。
示例:from_product(笛卡尔积)
点击查看代码
# 两个集合:类别(水果、蔬菜)、名称(苹果、香蕉、番茄)
categories = ['水果', '蔬菜']
names = ['苹果', '香蕉', '番茄']
# 笛卡尔积创建索引(所有组合:(水果,苹果)、(水果,香蕉)、...、(蔬菜,番茄))
multi_index = pd.MultiIndex.from_product(
[categories, names],
names=['类别', '名称'] # 给每层索引命名
)
# 创建DataFrame
df_multi = pd.DataFrame({
'价格(元/斤)': [5.8, 3.2, 2.5, 1.8, 2.2, 3.0]
}, index=multi_index)
print("\n笛卡尔积创建的层次化索引DataFrame:")
print(df_multi)
7.2 层次化索引的核心操作
7.2.1 筛选数据(按外层 / 内层索引)
点击查看代码
# 1. 按外层索引筛选(所有“河北省”数据)
print("河北省的所有数据:")
print(ser_multi1['河北省'])
# 输出:
# 石家庄 1124
# 唐山 954
# 邯郸 886
# dtype: int64
# 2. 按内层索引筛选(所有“郑州”数据)
print("\n所有'郑州'的数据:")
print(ser_multi1[:, '郑州']) # 冒号表示匹配所有外层索引
# 输出:
# 河南省 郑州 1020
# dtype: int64
7.2.2 交换索引层级:swaplevel()
点击查看代码
# 交换外层和内层索引
ser_multi_swap = ser_multi1.swaplevel()
print("\n交换索引后的Series:")
print(ser_multi_swap)
# 输出:
# 石家庄 河北省 1124
# 唐山 河北省 954
# 邯郸 河北省 886
# 郑州 河南省 1020
# 洛阳 河南省 830
# 开封 河南省 765
# dtype: int64
7.2.3 按索引层级排序:sort_index(level)
点击查看代码
# 按内层索引(城市)升序排序
ser_multi_sort = ser_multi1.sort_index(level=1) # level=1表示内层索引
print("\n按内层索引排序后的Series:")
print(ser_multi_sort)
八、读写数据操作
Pandas 支持读写多种格式的数据文件,如 CSV、Excel、HTML、数据库等,是数据输入输出的核心工具。
8.1 读写文本文件(CSV/TXT)
8.1.1 CSV文件(逗号分隔)
- 写入 CSV:to_csv(),参数index=False表示不写入行索引;
- 读取 CSV:read_csv(),参数header=0表示用第一行作为列名。
点击查看代码
# 1. 写入CSV文件
df2.to_csv('employee.csv', index=False, encoding='utf-8')
print("CSV文件已写入")
# 2. 读取CSV文件
df_csv = pd.read_csv('employee.csv', header=0)
print("\n读取的CSV文件数据:")
print(df_csv)
8.1.2 TXT 文件(制表符分隔)
TXT 文件常用\t(制表符)分隔,可通过read_table()或read_csv(sep='\t')读取:
点击查看代码
# 1. 写入TXT文件(用\t分隔)
df2.to_csv('employee.txt', index=False, sep='\t', encoding='utf-8')
# 2. 读取TXT文件(两种方法)
# 方法1:read_table(默认sep='\t')
df_txt1 = pd.read_table('employee.txt', header=0)
# 方法2:read_csv(指定sep='\t')
df_txt2 = pd.read_csv('employee.txt', header=0, sep='\t')
print("\n读取的TXT文件数据:")
print(df_txt1)
8.2 读写 Excel 文件
读写 Excel 需要先安装依赖库:pip install openpyxl(支持.xlsx 格式)。
写入 Excel:to_excel(),参数sheet_name指定工作表名称;
读取 Excel:read_excel(),参数sheet_name指定读取的工作表。
点击查看代码
# 1. 写入Excel文件
df2.to_excel('employee.xlsx', sheet_name='员工信息', index=False)
print("Excel文件已写入")
# 2. 读取Excel文件
df_excel = pd.read_excel('employee.xlsx', sheet_name='员工信息', header=0)
print("\n读取的Excel文件数据:")
print(df_excel)
8.3 读取 HTML 表格数据
读取网页中的表格需要安装依赖库:pip install lxml。使用read_html()函数,返回一个包含所有表格的 DataFrame 列表。
点击查看代码
# 读取本地HTML文件(或直接传入网页URL)
# 示例:读取包含“专业信息”的HTML表格
df_html_list = pd.read_html(
'majors.html', # 本地HTML文件路径或网页URL
attrs={'class': 'table'} # 筛选class为'table'的表格
)
# 取第一个表格
df_html = df_html_list[0]
print("读取的HTML表格数据:")
print(df_html)
8.4 读写数据库(以 MySQL 为例)
读写数据库需要安装依赖库:pip install mysqlconnector sqlalchemy。核心步骤:
- 用SQLAlchemy创建数据库连接;
- 用read_sql()读取数据,to_sql()写入数据。
点击查看代码
from sqlalchemy import create_engine
# 1. 创建数据库连接(格式:mysql+驱动://用户名:密码@主机:端口/数据库名)
engine = create_engine('mysql+mysqlconnector://root:123456@localhost:3306/test_db')
# 2. 写入数据到数据库(表名:employee,if_exists='append'表示追加)
df2.to_sql(
name='employee', # 表名
con=engine, # 数据库连接
if_exists='append', # 若表存在则追加
index=False # 不写入行索引
)
print("数据已写入数据库")
# 3. 从数据库读取数据(两种方式:读表、读SQL语句)
# 方式1:读取整个表
df_db1 = pd.read_sql('employee', con=engine)
# 方式2:执行SQL语句(筛选年龄>28的员工)
df_db2 = pd.read_sql('SELECT * FROM employee WHERE 年龄>28', con=engine)
print("\n从数据库读取的数据(年龄>28):")
print(df_db2)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号