
随笔分类 - 机器算法学习
摘要:核心区别 应用范围:自动编码器主要用于数据的压缩、重建和特征提取,而序列到序列模型用于处理序列数据,特别是在输入和输出都是长度可变的序列的情况下。 数据处理方式:自动编码器处理固定大小的输入和输出,而序列到序列模型处理的输入和输出通常是长度可变的序列。 任务类型:自动编码器更多用于无监督学习任务,而
阅读全文
摘要:### np.stack(x_new, axis=-2) 在函数中,`x_new = np.stack(x_new, axis=-2)` 的目的是将保留区域的 `x` 数组沿着倒数第二个维度进行堆叠,得到一个新的数组 `x_new`,该数组的维度为 `(6940, 45, 90, a, 9)`,其中
阅读全文
摘要:### enumerate用法 list1 = ["这", "是", "一个", "测试"] for index, item in enumerate(list1): print index, item >0 这 >1 是 >2 一个 >3 测试
阅读全文
摘要:lstm的官网 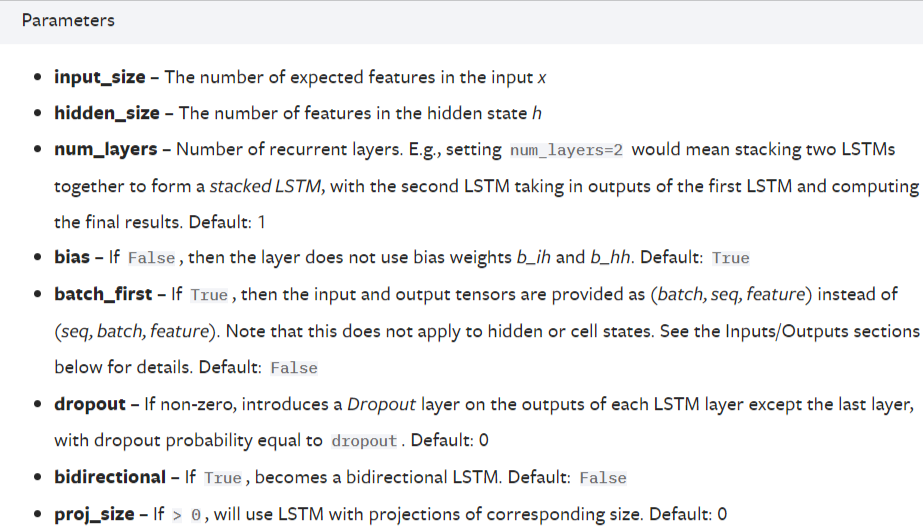 总共有七个参数,其中只有前三个是必须的。由于大家普遍使用PyTorch的DataLoa
阅读全文
摘要:如果您希望将LSTM的点到点训练转换为点到图的训练,可以采取以下步骤进行修改: 1. 调整输入数据的形状:点到点的训练输入是一个时间序列的点,而点到图的训练需要将时间序列转换为图结构。您可以使用时间窗口滑动的方式,将多个连续时间步的点作为一个图的节点,从而形成图的结构。每个时间步的点作为节点特征,节
阅读全文
摘要:点到点的代码理解 点击查看代码 ``` def load_train_data_for_rnn(cfg, x, y, aux, scaler): # x = {nt, nf, ngrid} = {3287,9,1399} # y = {nt, ngrid} = {3287,1399} # aux =
阅读全文
摘要:### 归一化: 1)把数据变成(0,1)或者(1,1)之间的小数。主要是为了数据处理方便提出来的,把数据映射到0~1范围之内处理,更加便捷快速。 2)把有量纲表达式变成无量纲表达式,便于不同单位或量级的指标能够进行比较和加权。归一化是一种简化计算的方式,即将有量纲的表达式,经过变换,化为无量纲的表
阅读全文
摘要:NWP和深度学习融入物理知识在预测天气方面有一些区别。 NWP是基于物理定律和数学方程构建的数值模型。它使用大气物理学、流体动力学和热力学等领域的物理知识来描述大气和地球系统的行为。NWP模型通过对物理过程进行建模和求解来预测天气变量的演变。这些模型需要对大气系统的初始状态和边界条件进行准确的观测和
阅读全文
摘要:NWP代表数值天气预报(Numerical Weather Prediction),它是通过数值模型来预测天气和相关变量如温度、湿度、风速等随时间变化的模型。 NWP系统使用数学方程来描述大气、海洋和地球系统的物理过程。这些方程基于物理定律,如质量守恒、动量守恒和热力学原理,并结合初始观测数据进行求
阅读全文
摘要:### GraphCast模型在10天的预报中,在6小时步长和0.25°经纬度分辨率下,超过了目前最精确的确定性系统——ECMWF的HRES。里面的0.25°分辨率是什么意思 在这个上下文中,0.25°分辨率是指地球表面的经度和纬度之间的间隔。经度是用来测量地球表面东西方向的角度,而纬度则是用来测量
阅读全文
摘要:## data.py里的各个文件的生成 #### Load forcing data ERA5_LAND_label_4_1990???哪生成的 ERA5-Land_forcing {sr} spatial resolution {year}.npy??哪来的 lat_{s}.npy #109 lo
阅读全文
摘要:``` if not os.path.exists(PATH + 'x_train.npy'): x_train = np.memmap(PATH + 'x_train.npy', dtype=cfg['data_type'], mode='w+', shape=( self.time_length
阅读全文
摘要:``` # 查看npy的维度 x_train.npy ERA5_LAND_label_4_1990.npy import numpy as np data = np.load("D:\\WorkSpace\\PyCharmPJ\\pythonProject\\data\\test\\LandBenc
阅读全文
摘要:## 作用 根据特征的组合进行分类 大大减少特征位置对分类带来的影响 ### 减少特征位置对分类带来的影响 **就是它把特征representation整合到一起,输出为一个值** **这样做,有一个什么好处?** **就是大大减少特征位置对分类带来的影响** 个数。比如我们的训练集有1000个数据。这是如果我们设置batch_size=100,那么程序首先会用数据集中的前100个参数,**即第1-100个数据来训练模型。当训练完成后更新权重,再使用第101-200的个数据训练,**直至第十次使
阅读全文
摘要:当前文件夹里的删除文件夹以aa开头的 rm -r -f aa* 当前文件夹里的删除文件夹aa ,bb,cc rm -r -f aa bb cc 删除当前目录文件夹所在的所有文件 Linux rm -r -f ./* 其中,.表示当前目录,/*表示匹配当前目录下的所有文件和子文件夹。-r参数表示递归地
阅读全文
摘要:spatial offset 空间偏移量*(spatial offset*) Splice x according to the sphere shape 根据球体形状拼接x valid_split 有效分割 split_ratio 拆分比率 torch.from_numpy(x_batch).to
阅读全文
摘要:用于土壤湿度预测的,rnn,lstm,convlstm的输入输出有啥不同,做一个表格处理 下面是一个简单的表格,列出了在用于土壤湿度预测时,RNN、LSTM 和 ConvLSTM 的输入和输出的不同之处: | 模型 | 输入 | 输出 | | | | | | RNN | $(X_{1}, X_{2}
阅读全文
 浙公网安备 33010602011771号
浙公网安备 33010602011771号