时间序列的lstm的输入输出
lstm的官网
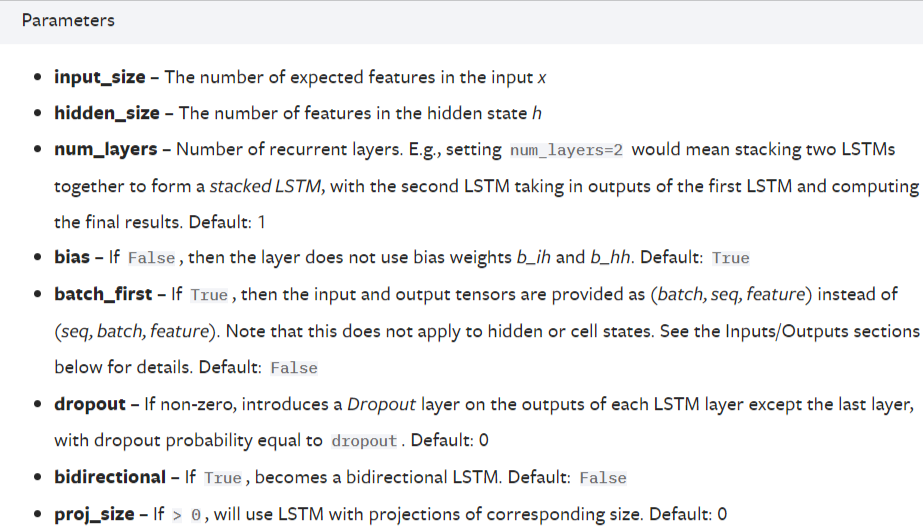
总共有七个参数,其中只有前三个是必须的。由于大家普遍使用PyTorch的DataLoader来形成批量数据,因此batch_first也比较重要。
- input_size:在时间序列预测中,比如需要预测负荷,每一个负荷都是一个单独的值,都可以直接参与运算,因此并不需要将每一个负荷表示成一个向量,此时input_size=1。 但如果我们使用多变量进行预测,比如我们利用前24小时每一时刻的[负荷、风速、温度、压强、湿度、天气、节假日信息]来预测下一时刻的负荷,那么此时input_size=7
- hidden_size:隐藏层节点个数。可以随意设置。
- num_layers:层数。nn.LSTMCell与nn.LSTM相比,num_layers默认为1。
Inputs
官方文档

输入由两部分组成:input、(初始的隐状态h_0,初始的单元状态c_0)
其中input:
input(seq_len, batch_size, input_size)
- seq_len:在文本处理中,如果一个句子有7个单词,则seq_len=7;在时间序列预测中,假设我们用前24个小时的负荷来预测下一时刻负荷,则seq_len=24。
- batch_size:一次性输入LSTM中的样本个数。在时间序列预测中,也可以一次性输入很多条数据。
- input_size:但如果我们使用多变量进行预测,比如我们利用前24小时每一时刻的[负荷、风速、温度、压强、湿度、天气、节假日信息]来预测下一时刻的负荷,那么此时input_size=7
点击查看代码
(h_0, c_0):
h_0(num_directions * num_layers, batch_size, hidden_size)
c_0(num_directions * num_layers, batch_size, hidden_size)
h_0和c_0的shape一致。
num_directions:如果是双向LSTM,则num_directions=2;否则num_directions=1。
num_layers:见前文。
batch_size:见前文。
hidden_size:见前文。
Outputs
官方文档

输出也由两部分组成:otput、(隐状态h_n,单元状态c_n)
其中output的shape为
output(seq_len, batch_size, num_directions * hidden_size)
h_n和c_n的shape保持不变,参数解释见前文。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号