吴恩达机器学习笔记 —— 19 应用举例:照片OCR(光学字符识别)
本章讲述的是一个复杂的机器学习系统,通过它可以看到机器学习的系统是如何组装起来的;另外也说明了一个复杂的流水线系统如何定位瓶颈与分配资源。
更多内容参考 机器学习&深度学习
OCR的问题就是根据图片识别图片中的文字:

这种OCR识别的问题可以理解成三个步骤:
- 文本检测
- 字符切分
- 字符识别

文本检测
文本的检测可以用行人的检测来做,思路差不多。
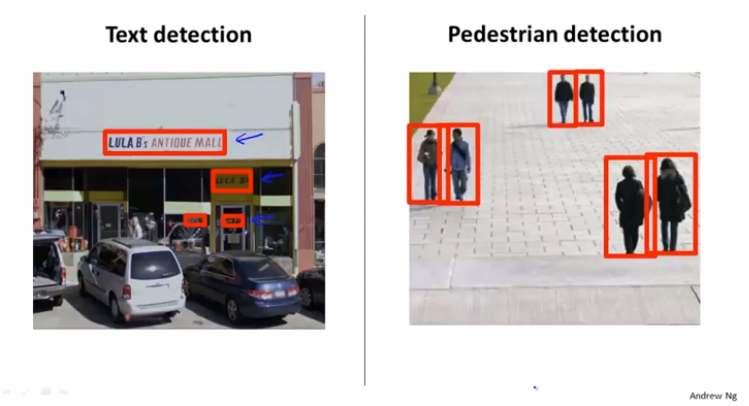
我们定义几个固定大小尺寸的窗口,从照片的左上角开始扫描。扫描出来的图像做二分类,判断是北京还是人物(文字)。然后根据图像处理的一些惯用手段做二值化、膨胀,使得文字区域连通。最终根据规则选择文本框就可以了,过滤那些规则不规整、宽度比高度小的矩形框框,剩下的就是目标文本框了。
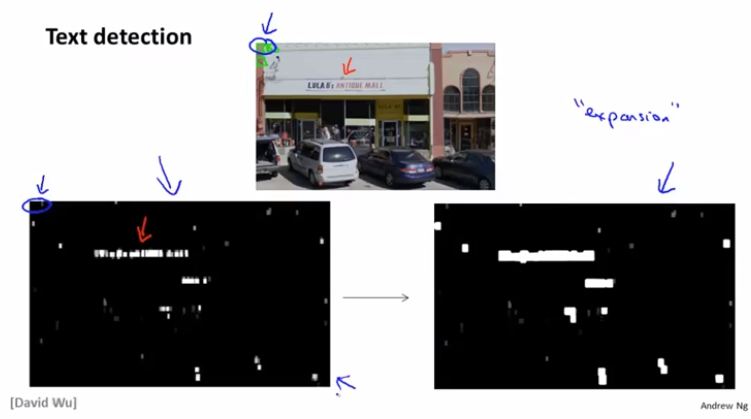
字符切分
字符切分也可以理解成二分类问题,不过这里的滑动窗口是固定大小。根据窗口内的内容判断目标是分隔,还是文本。

字符识别
最后的字符识别就很简单了,找够样本,就可以做多分类了。跟手写体识别一样的玩法~

关于训练的样本
其实训练的样本可以根据已有的样本进行成倍的扩充。比如在做文字识别的时候,根据现有的图片做一些变形、噪声、旋转等,再比如针对一些文字替换背景等等。

关于系统的性能提升
针对系统准确性的提升可以把问题阶段性的考虑,先判断第一个环节的准确率,在判断第二个环节。
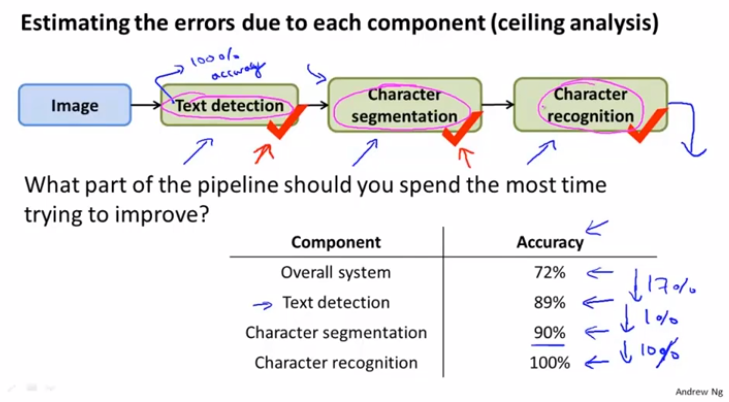
选择准确率影响最关键的节点进行优化。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号