吴恩达机器学习笔记 —— 8 正则化
本章讲述了机器学习中如何解决过拟合问题——正则化。讲述了正则化的作用以及在线性回归和逻辑回归是怎么参与到梯度优化中的。
更多内容参考 机器学习&深度学习
在训练过程中,在训练集中有时效果比较差,我们叫做欠拟合;有时候效果过于完美,在测试集上效果很差,我们叫做过拟合。因为欠拟合和过拟合都不能良好的反应一个模型应用新样本的能力,因此需要找到办法解决这个问题。
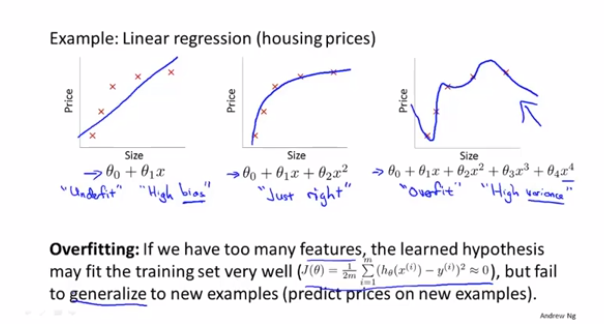
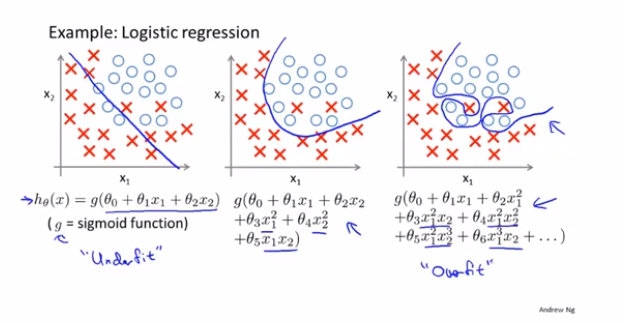
想要解决这个问题,有两个办法:
1 减少特征的数量,可以通过一些特征选择的方法进行筛选。
2 正则化,通过引入一个正则项,限制参数的大小。
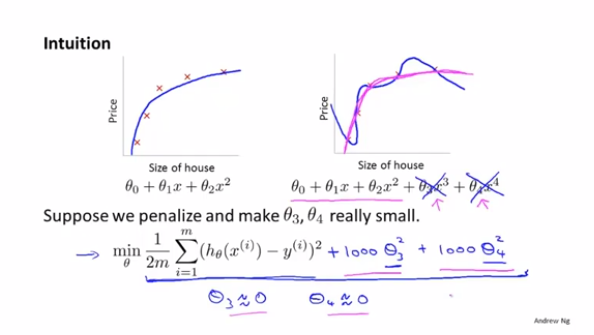
比如下面的曲线,针对高次项的参数,在后面多加一项乘以1000。这样在优化损失函数的时候,会强制θ3和θ4不会很大,并且趋近于0,只有这样才会保证损失函数的值足够小。
得到的公式如下,注意只会针对x1开始,θ0相当于只是针对偏置项设置的,因此不需要加正则项。
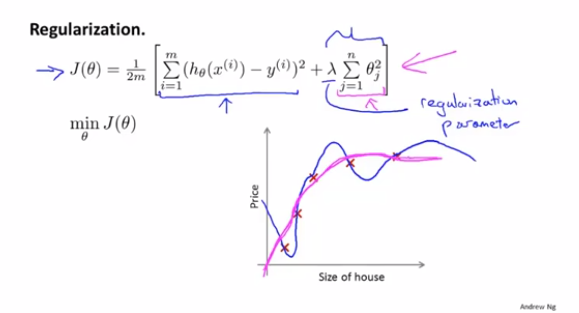
但是如果λ设置的过大,相当于所有的θ都变成了0,损失函数的曲线相当于一条直线,就没有任何意义了,因此选择适合的λ很重要,后面也会讲解如何选择正确的λ。
添加正则项之后,梯度下降的公式就发生了变化:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号