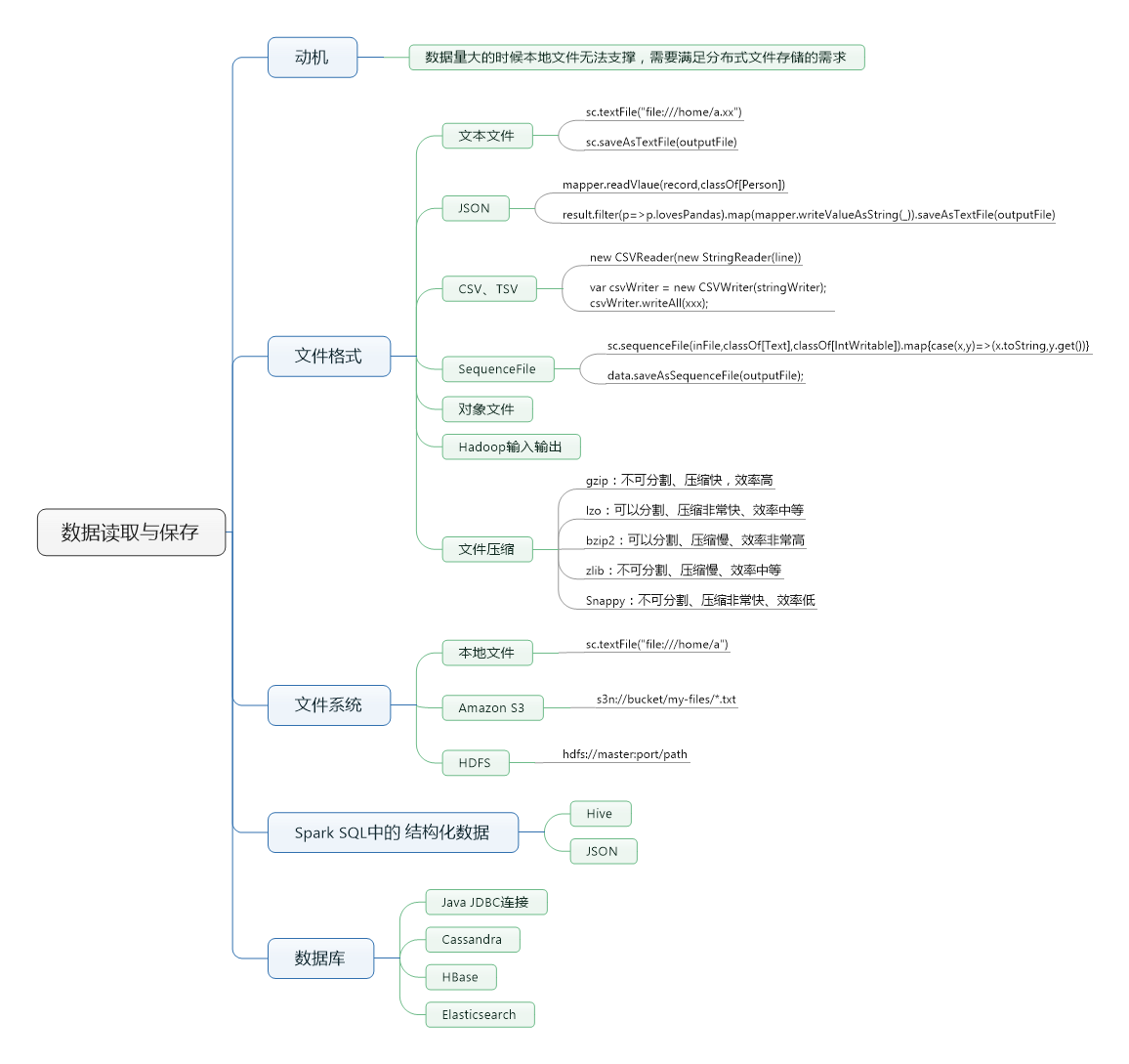
由于Spark是在Hadoop家族之上发展出来的,因此底层为了兼容hadoop,支持了多种的数据格式。如S3、HDFS、Cassandra、HBase,有了这些数据的组织形式,数据的来源和存储都可以多样化~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号