
pointTransformer V1训练自定义数据
源码地址:https://github.com/POSTECH-CVLab/point-transformer
一、环境安装
1.1 本机环境
我的相关依赖如下,python版本是3.7.16,cuda版本11.0,unbuntu:18.04
Package Version
----------------- ---------------
certifi 2022.12.7
h5py 3.7.0
numpy 1.21.6
Pillow 9.3.0
pip 22.3.1
pointops 0.0.0
protobuf 3.18.0
PyYAML 6.0
setuptools 65.6.3
SharedArray 3.2.1
six 1.16.0
tensorboardX 2.5.1
torch 1.9.0
torchaudio 0.9.0a0+33b2469
torchvision 0.10.0
typing_extensions 4.3.0
wheel 0.38.4
1.2 安装步骤
可以按照以下命令进行安装
bash env_setup.sh pt # 安装所有依赖
如果安装不成功可以参考以下步骤,注意其中pytorch的cuda版本要高于nvcc的版本
conda create -n pt python=3.7 # 创建环境并制定python版本
conda activate pt # 进入环境
conda install h5py pyyaml -y
conda install -c conda-forge sharedarray tensorboardx -y
pip install torch==1.9.0+cu111 torchvision==0.10.0+cu111 torchaudio==0.9.0 -f https://download.pytorch.org/whl/torch_stable.html
# pip list # 检查按照的库
cd lib/pointops
python3 setup.py install # 打包C++代码
1.3 主要事项
- pointops_cuda要进行编译
如果上述步骤中编译C++代码没有成功,那后续运行时会报以下错误。
import pointops_cuda
ModuleNotFoundError: No module named 'pointops_cuda'
确保已正确安装lib/pointops下面的库文件
python setup.py install
验证步骤
import torch
import pointops_cuda # 先要引用torch,否则会报错ImportError: libc10.so: cannot open shared object file: No such file or directory
- 还有要留意pytorch对应的cuda版本,如果低于nvcc有可能会报以下错误:
RuntimeError: CUDA error: no kernel image is available for execution on the device
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1
- fatal error: THC/THC.h: No such file or directory #include <THC/THC.h>
PyTorch 从 1.10 版本开始,将底层张量计算库从 THC 迁移到 ATen,导致旧代码的 THC 头文件无法找到。
替换头文件
// 旧代码
#include <THC/THC.h>
// 新代码(使用 ATen 库)
#include <ATen/ATen.h>
#include <ATen/cuda/CUDAContext.h>
二、配置文件
2.1配置文件结构
主要包含Data、Train、Test三部分,其他的Distributed用于多GPU训练。
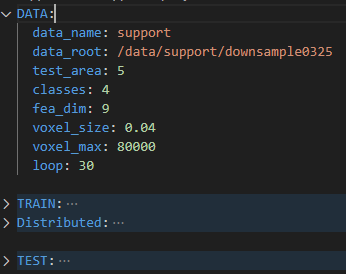
该配置文件通过util下的config.py的load_cfg_from_cfg_file函数进行解析,然后传入到训练和验证中。
2.2 Data
主要用于控制数据加载,以下几项要按实际数据进行配置
DATA:
data_name: seg # 数据名称
data_root: /data/seg/downsample0325 # 数据存放路径
classes: 4 # 数据类别数
fea_dim: 12 # 每个点云特征维度
2.3 Train
涉及网络结构、批处理大小,学习率,迭代次数等
TRAIN:
arch: pointtransformer_seg_repro # 该代码只实现了这个结构,其他的需要自己添加
batch_size: 2 # 训练时批处理大小
batch_size_val: 1 # 验证时批处理大小
base_lr: 0.5 # 学习率
epochs: 200 # 迭代次数
resume: "exp/seg/pt1_repro/model/model_best.pth" # 预训练权重,默认为None
eval_freq: 1 # 验证频次
2.4 Test
TEST:
test_data_root: /data/seg/0321/ # 测试数据路径
model_path: exp/seg/pt1_repro/model/model_last.pth # 测试模型
names_path: data/seg/seg_names.txt # 数据集标签名
三、 数据集
3.1 数据加载器
在util目录下建立自己的数据加载器,主要返回点云坐标、除坐标外的特征,标签。特征维度是fea_dim - 3,3表示xyz坐标。
def __getitem__(self, idx):
data_idx = self.data_idx[idx % len(self.data_idx)]
data = SA.attach("shm://{}".format(self.data_list[data_idx])).copy()
coord, feat, label = data[:, 0:3], data[:, 3:6], data[:, 6]
coord, feat, label = data_prepare(coord, feat, label, self.split, self.voxel_size, self.voxel_max, self.transform, self.shuffle_index)
return coord, feat, label
data_prepare主要是将numpy数据转为了Torch的Tensor格式
coord_min = np.min(coord, 0)
coord -= coord_min
coord = torch.FloatTensor(coord)
feat = torch.FloatTensor(feat) / 255.
label = torch.LongTensor(label)
3.2 数据对齐
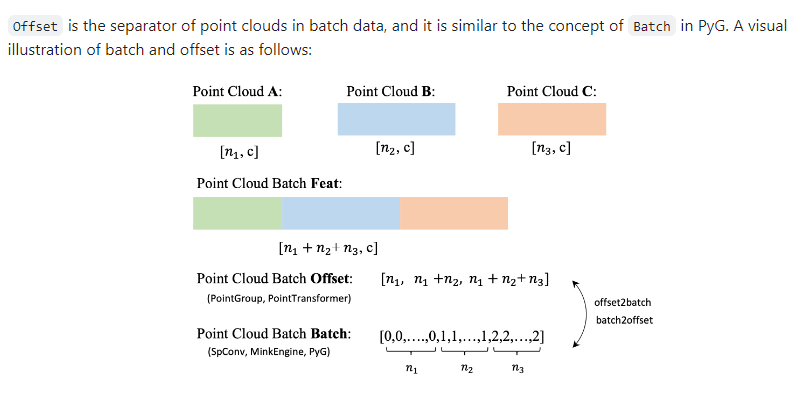
假设一个批次包含2个样本:
样本1:100个点 → coord1.shape=(100, 3)
样本2:150个点 → coord2.shape=(150, 3)
经过collate_fn处理后:
coord = torch.cat([coord1, coord2]) # 形状: (250, 3)
offset = [100, 250] # 表示第一个样本结束于索引100,第二个结束于250
def collate_fn(batch):
coord, feat, label = list(zip(*batch))
offset, count = [], 0
for item in coord:
count += item.shape[0]
offset.append(count)
return torch.cat(coord), torch.cat(feat), torch.cat(label), torch.IntTensor(offset)
四、训练
4.1 训练脚本
sh tool/train.sh seg pointtransformer_repro
训练的时候选择好数据集(seg)和配置名(pointtransformer_repro),然后会按照以下方式在指定目录下寻找模型、配置文件等。
dataset=$1
exp_name=$2
exp_dir=exp/${dataset}/${exp_name}
model_dir=${exp_dir}/model
result_dir=${exp_dir}/result
config=config/${dataset}/${dataset}_${exp_name}.yaml
4.2 训练步骤
先在config目录下新建自己的文件夹和对应的配置文件
在utils目录下新建自己的数据加载器,主要实现__init__、__getitem__、__len__方法,getitem返回coord(3D点坐标)、feat(除坐标外的特征)、label(点标签)
在train.py中对应位置添加数据加载器
if args.data_name == 's3dis':
train_data = S3DIS(split='train', data_root=args.data_root, test_area=args.test_area, voxel_size=args.voxel_size, voxel_max=args.voxel_max, transform=train_transform, shuffle_index=True, loop=args.loop)
elif args.data_name == 'seg':
train_data = SemSegSegtDataset(split='train', root=args.data_root, npoints=args.npoints, n_class=args.classes, f_cols=args.fea_dim)
weights = torch.Tensor(train_data.label_weights).cuda()
criterion = nn.CrossEntropyLoss(weight=weights, ignore_index=args.ignore_label).cuda()
else:
raise NotImplementedError()
最后在启动训练脚本,训练结果如下

五、测试
在配置文件中配置好测试参数
TEST:
test_list:
test_list_full:
split: val # split in [train, val and test]
test_gpu: [0]
test_workers: 4
batch_size_test: 4
test_data_root: /data/seg/0321/
model_path: exp/seg/pt1_repro/model/model_best_0.9.pth
save_folder:
names_path: data/seg/seg_names.txt
可以直接运行以下脚本执行
CUDA_VISIBLE_DEVICES=0 sh tool/test.sh seg pointtransformer_repro
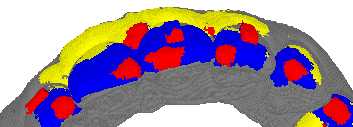
这里为了进一步可视化,新建inference.py,测试单个点云数据并显示
import os
import time
import random
import numpy as np
import logging
import pickle
import argparse
import collections
from pathlib import Path
import torch
import torch.nn as nn
import torch.nn.parallel
import torch.optim
import torch.utils.data
import sys
sys.path.append("/home/learn/point-transformer/")
from util import config
from util.common_util import AverageMeter, intersectionAndUnion, check_makedirs
from util.voxelize import voxelize
random.seed(123)
np.random.seed(123)
def get_parser():
parser = argparse.ArgumentParser(description='PyTorch Point Cloud Semantic Segmentation')
parser.add_argument('--config', type=str, default='config/seg/seg_pt1_repro.yaml', help='config file')
parser.add_argument('opts', help='see config/s3dis/s3dis_pointtransformer_repro.yaml for all options', default=None, nargs=argparse.REMAINDER)
parser.add_argument('--model_path', type=str, default="exp/seg/pt1_repro/model/model_best_0.9.pth", help='model path', nargs=argparse.REMAINDER)
args = parser.parse_args()
assert args.config is not None
cfg = config.load_cfg_from_cfg_file(args.config)
if args.opts is not None:
cfg = config.merge_cfg_from_list(cfg, args.opts)
return cfg
def get_logger():
logger_name = "main-logger"
logger = logging.getLogger(logger_name)
logger.setLevel(logging.INFO)
handler = logging.StreamHandler()
fmt = "[%(asctime)s %(levelname)s %(filename)s line %(lineno)d %(process)d] %(message)s"
handler.setFormatter(logging.Formatter(fmt))
logger.addHandler(handler)
return logger
def main():
global args, logger
args = get_parser()
logger = get_logger()
logger.info(args)
assert args.classes > 1
logger.info("=> creating model ...")
logger.info("Classes: {}".format(args.classes))
if args.arch == 'pointtransformer_seg_repro':
from model.pointtransformer.pointtransformer_seg import pointtransformer_seg_repro as Model
else:
raise Exception('architecture not supported yet'.format(args.arch))
model = Model(c=args.fea_dim, k=args.classes).cuda()
# logger.info(model)
criterion = nn.CrossEntropyLoss(ignore_index=args.ignore_label).cuda()
names = [line.rstrip('\n') for line in open(args.names_path)]
print("model_path: ", args.model_path)
if os.path.isfile(args.model_path):
logger.info("=> loading checkpoint '{}'".format(args.model_path))
checkpoint = torch.load(args.model_path)
state_dict = checkpoint['state_dict']
new_state_dict = collections.OrderedDict()
for k, v in state_dict.items():
name = k[7:]
new_state_dict[name] = v
model.load_state_dict(new_state_dict, strict=True)
logger.info("=> loaded checkpoint '{}' (epoch {})".format(args.model_path, checkpoint['epoch']))
args.epoch = checkpoint['epoch']
else:
raise RuntimeError("=> no checkpoint found at '{}'".format(args.model_path))
test(model, criterion, names)
def data_prepare():
if args.data_name == 's3dis':
data_list = sorted(os.listdir(args.data_root))
data_list = [item[:-4] for item in data_list if 'Area_{}'.format(args.test_area) in item]
elif args.data_name == 'seg':
data_list = Path(args.test_data_root).glob("*point.npy")
else:
raise Exception('dataset not supported yet'.format(args.data_name))
return data_list
def pc_normalize(pc):
centroid = np.mean(pc, axis=0)
pc = pc - centroid
m = np.max(np.sqrt(np.sum(pc ** 2, axis=1)))
pc = pc / m
return pc
def data_load(data_name, f_cols):
data = np.load(data_name).astype(np.float32)
ori_normal_data = data[data[:, 5] >= 0][:, :4]
ori_normal_data[:, -1] = 0
# print(data.shape)
data = data[data[:, 5] < 0] # remove nz > 0
# print("---", data.shape)
np.random.shuffle(data)
ori_neg_data = data[:, :3]
# print(fn, data.shape)
point_set = data[:, 0:f_cols]
label = data[:, -2].astype(np.int32)
label[label < 1] = 0
# label[label == 3] = 1
coord = pc_normalize(point_set[:, 0:3])
feat = pc_normalize(point_set[:, 3:f_cols])
# print("after_pc_normalize:", point_set.shape, label.shape)
coord_min = np.min(coord, 0)
coord -= coord_min
coord = torch.FloatTensor(coord)
feat = torch.FloatTensor(feat)
label = torch.LongTensor(label)
idx_data = []
idx_data.append(np.arange(label.shape[0]))
return coord, feat, label, idx_data, ori_normal_data, ori_neg_data
def input_normalize(coord, feat):
coord_min = np.min(coord, 0)
coord -= coord_min
feat = feat / 255.
return coord, feat
def show_pcl_data(data, label_cls=-1):
import vedo
points = data[:, 0:3]
colours = ["grey", "red", "blue", "yellow", "brown", "green", "black", "pink"]
labels = data[:, label_cls] # 鏈€鍚庝竴鍒椾负鏍囩鍒? diff_label = np.unique(labels)
print("res_label: ", diff_label)
group_points = []
group_labels = []
for label in diff_label:
point_group = points[labels == label]
group_points.append(point_group)
# print(point_group.shape)
group_labels.append(label)
show_pts = []
for i, point in enumerate(group_points):
pt = vedo.Points(point.reshape(-1, 3)).c((colours[int(group_labels[i]) % len(colours)]))
vedo.show(show_pts)
def test(model, criterion, names):
logger.info('>>>>>>>>>>>>>>>> Start Evaluation >>>>>>>>>>>>>>>>')
args.batch_size_test = 1
model.eval()
data_list = data_prepare()
for idx, item in enumerate(data_list):
if "XX8V3_VS_SET_VSc1_Subsetup1_Maxillar__X90_point" not in item.name: # "shouban_kedaya_0_point"
continue
coord, feat, label, idx_data, ori_normal_data, ori_neg_data = data_load(item, args.fea_dim)
print(coord.shape, feat.shape, label.shape, idx_data)
idx_size = len(idx_data)
idx_list, coord_list, feat_list, offset_list = [], [], [], []
for i in range(idx_size):
idx_part = idx_data[i]
coord_part, feat_part = coord[idx_part], feat[idx_part]
idx_list.append(idx_part), coord_list.append(coord_part), feat_list.append(feat_part), offset_list.append(idx_part.size)
batch_num = int(np.ceil(len(idx_list) / args.batch_size_test))
for i in range(batch_num):
s_i, e_i = i * args.batch_size_test, min((i + 1) * args.batch_size_test, len(idx_list))
idx_part, coord_part, feat_part, offset_part = idx_list[s_i:e_i], coord_list[s_i:e_i], feat_list[s_i:e_i], offset_list[s_i:e_i]
idx_part = np.concatenate(idx_part)
coord_part = torch.FloatTensor(np.concatenate(coord_part)).cuda(non_blocking=True)
feat_part = torch.FloatTensor(np.concatenate(feat_part)).cuda(non_blocking=True)
offset_part = torch.IntTensor(np.cumsum(offset_part)).cuda(non_blocking=True)
with torch.no_grad():
pred_part = model([coord_part, feat_part, offset_part]) # (n, k)
print("pred_part: ", pred_part, pred_part.shape)
probs = torch.exp(pred_part)
print(probs.shape)
max_values, max_indices = torch.max(probs, dim=1)
print(max_values, max_values.shape, max_indices, max_indices.shape)
pred_labels = max_indices.cpu().numpy()
# nms_3d_point_cloud(ori_normal_neg_data[:, :3], labels, max_values[0].cpu().numpy())
show_data = np.c_[ori_neg_data, pred_labels]
print(show_data.shape, ori_normal_data.shape)
show_data = np.vstack((show_data, ori_normal_data))
print(show_data, show_data.shape)
show_pcl_data(show_data)
torch.cuda.empty_cache()
if __name__ == '__main__':
main()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号