

centos7安装Hadoop
[spark环境搭建链接]https://www.cnblogs.com/xiaozhounandu/p/17643226.html
(这篇博客是本人csdn原创)
虚拟机的创建(可以自行百度)
虚拟机静态网络的设置
1:首先更改虚拟机的名字
hostnamectl set-hostname hadoop2
2:进入network配置文件夹中,配置你的虚拟网卡
cd /etc/sysconfig/network-scripts/
vim ifcfg-ens33
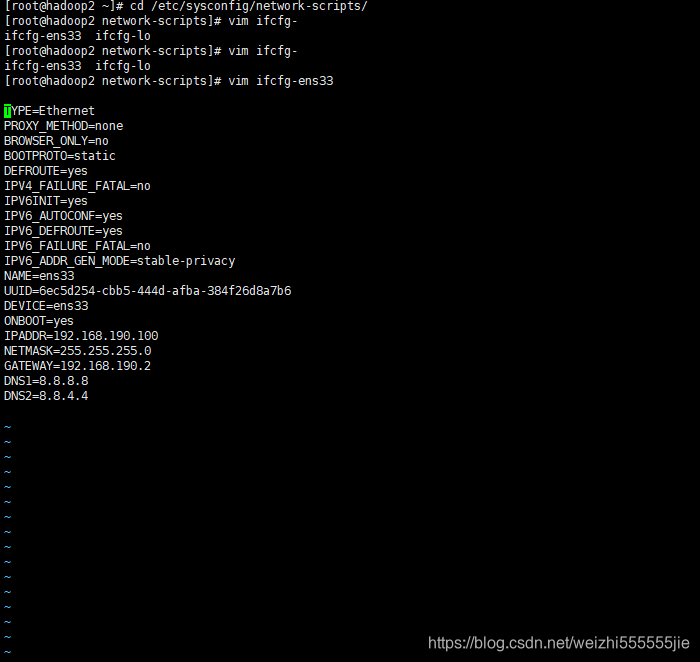
3:在系统原来的配置上,改
BOOTPROTO=static
ONBOOT=yes
4:添加配置(记得和你的相应配置相对应)
IPADDR=192.168.72.100
NETMASK=255.255.255.0
GATEWAY=192.168.72.2
DNS1=8.8.4.4
5:下面就有一些长得比较帅的小同学问了,上面这些东西我从哪里来呢?,别着急,这就一步一步告诉你
首先,打开Vmware,点击编辑,
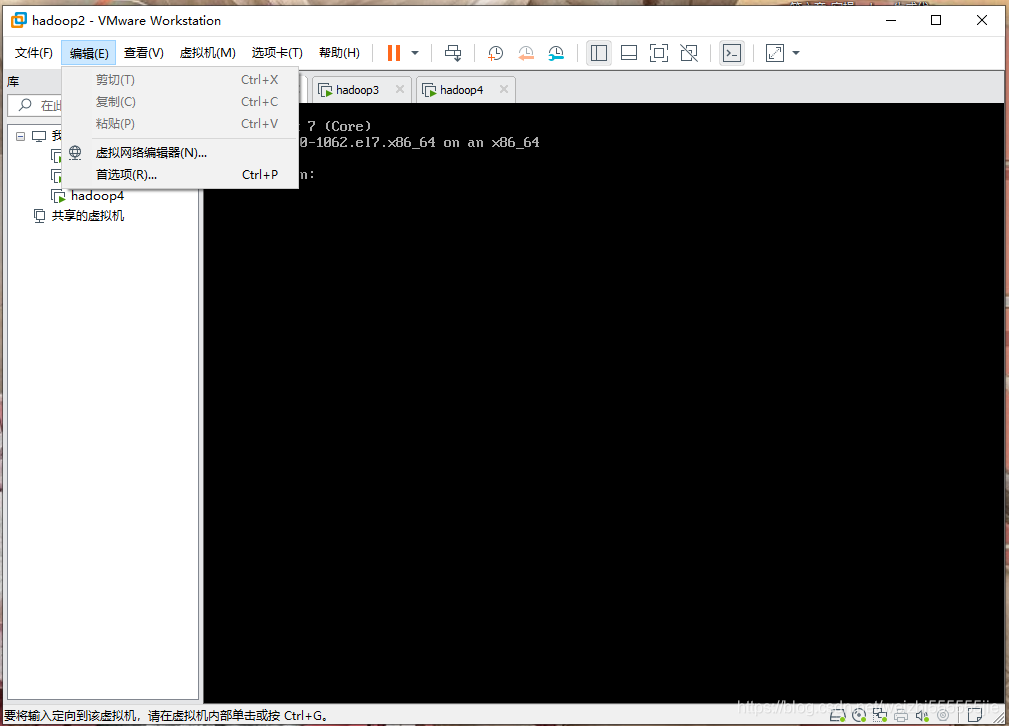
点击虚拟网络编辑器

点击vMent8,再点击net设置即可
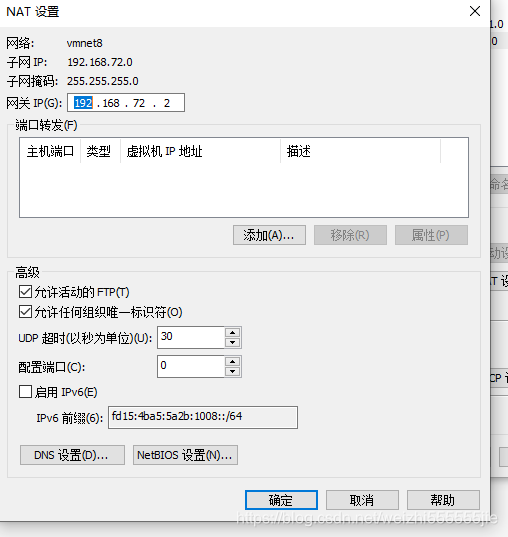
IPADDR 代表你的新的ip
NETMASK 代表子网掩码
GATEWAY 你的网关
DNS1 你的 DNS(默认填写8.8.8.8)

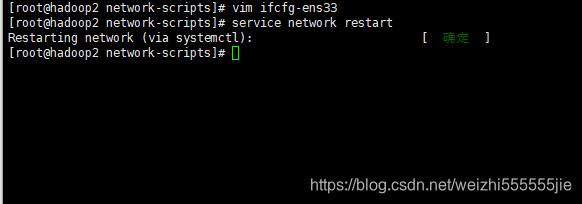
配置好网络之后,记得重启网络服务
service network restart
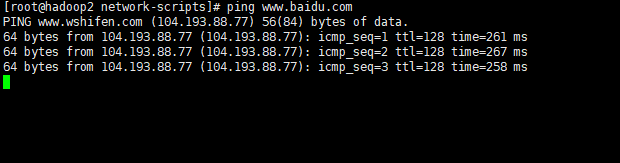
尝试ping百度
ping www.baidu.com
最后使用yum源安装你的vim,让你的字体拥有颜色
yum -y install vim
xshell连接你的虚拟机,使用scp 命令从Windows上传文件到虚拟机
对于Hadoop的搭建来说,只需要上传JDK和Hadoop文件,但是如果你要搭建spark环境的话,就需要上传搭建环境所需要的下列四个文件
scp hadoop-2.7.7.tar.gz root@192.168.2.100:/
scp jdk-8u171-linux-x64.tar.gz root@192.168.2.100:/
scp scala-2.11.8.tgz root@192.168.2.100:/
scp spark-2.2.0-bin-hadoop2.7.tgz root@192.168.2.100:/

开始解压java和hadoop的安装包
使用cd / 来查看文件是否被传递到相关的虚拟机内
cd /
在当前目录下创建software文件夹来存放上传文件的解压文件
mkdir software

解压jdk-8u261-linux-x64.tar.gz到software目录
tar -zxvf jdk-8u171-linux-x64.tar.gz -C software
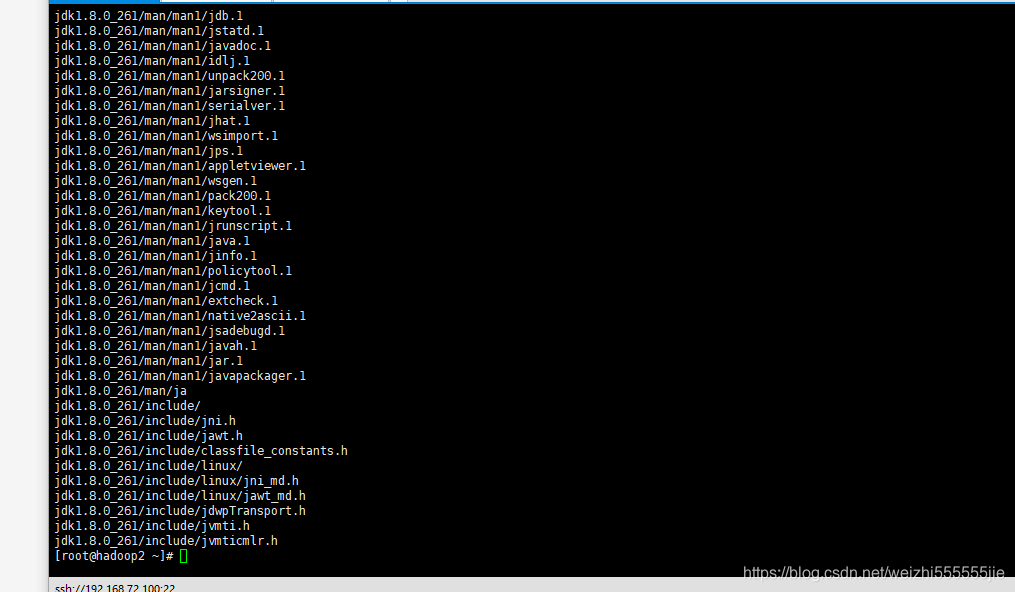
解压hadoop-2.7.7.tar.gz到software目录
tar -zxvf hadoop-2.7.7.tar.gz -C software
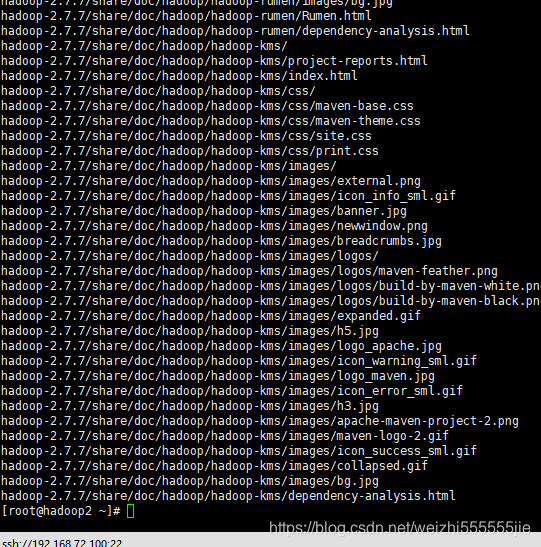
查看是否解压成功
进入sorfware文件夹查看是否有相关的解压文件(我的Scala和spark的解压文件是为后面的spark环境做准备,如果你只需要搭建hadoop ,请忽略这两个文件)

将Hadoop和JAVA添加到环境变量(请记住他们的安装位置,后续的配置文件需要它们(o_0))
获取 Hadoop 安装路径
/software/hadoop-2.7.7

获取Java的 安装路径
/software/jdk1.8.0_171

现在我们需要设置相关Java和Hadoop的配置文件
vim /etc/profile
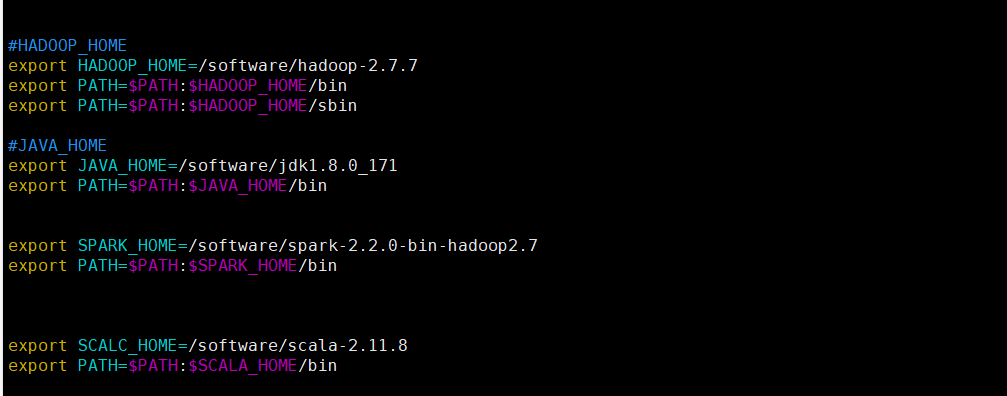
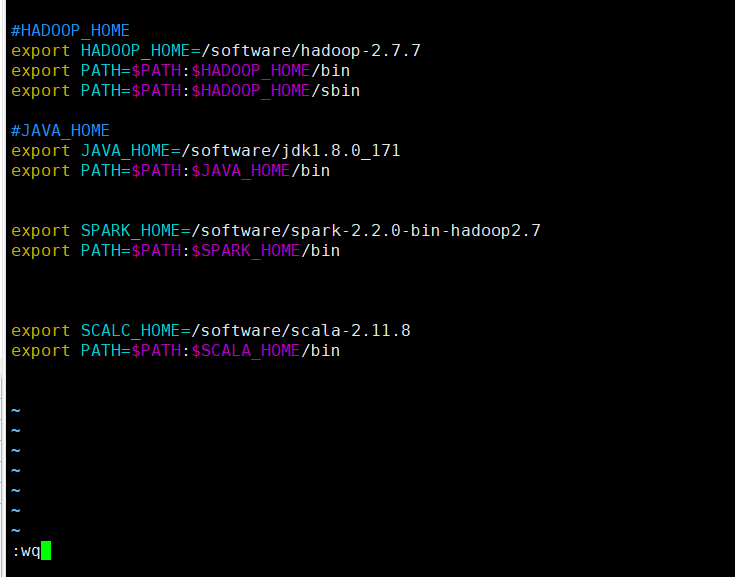
将下列的配置粘贴到文件末尾(注意:相关的HADOOP_HOME和JAVA_HOME需要替换成自己的安装路径)
#HADOOP_HOME
export HADOOP_HOME=/software/hadoop-2.7.7
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
#JAVA_HOME
export JAVA_HOME=/software/jdk1.8.0_171
export PATH=$PATH:$JAVA_HOME/bin
我下图是已经添加过Scala和spark的相关目录,如果你只是想要配置hadoop 你只需要添加相关的Java和Hadoop的配置即可
退出保存(按下esc键之后)
:wq
使用下列命令来使配置文件生效
source /etc/profile
测试Java环境和Hadoop环境
Java测试
java -version

hadoop测试
hadoop version

开始hadoop完全分布式的搭建
集群规划部署
| hadoop2 | hadoop3 | hadoop4 | |
|---|---|---|---|
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | NodeManager ResourceManager | NodeManager NodeManager |
配置集群(进入Hadoop的配置文件目录)注意是Hadoop文件夹下etc下的hadoop目录(别进错了!!!!!!)
cd software/hadoop-2.7.7/etc/hadoop/

配置文件的每一个标签必须完整
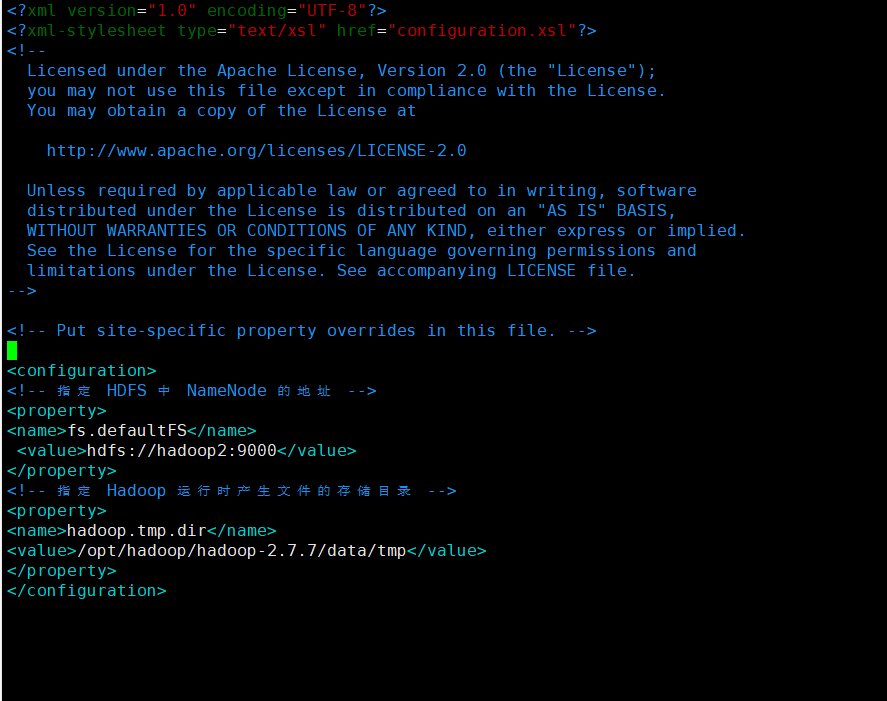
配置 core-site.xml
vim core-site.xml
在该文件中编写如下配置
<!-- 指定 HDFS 中 NameNode 的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop2:9000</value>
</property>
<!-- 指定 Hadoop 运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/hadoop-2.7.7/data/tmp</value>
</property>
配置HDFS 配置文件
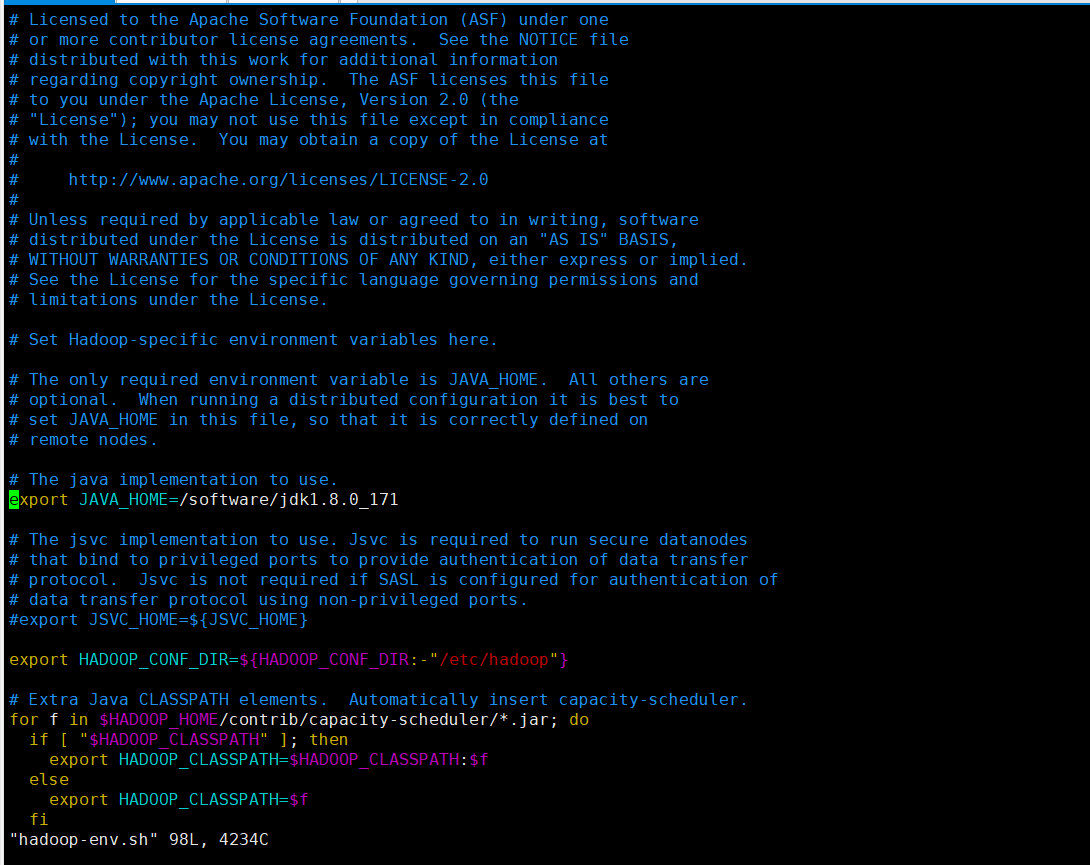
配置 hadoop-env.sh
vim hadoop-env.sh
export JAVA_HOME=/software/jdk1.8.0_171
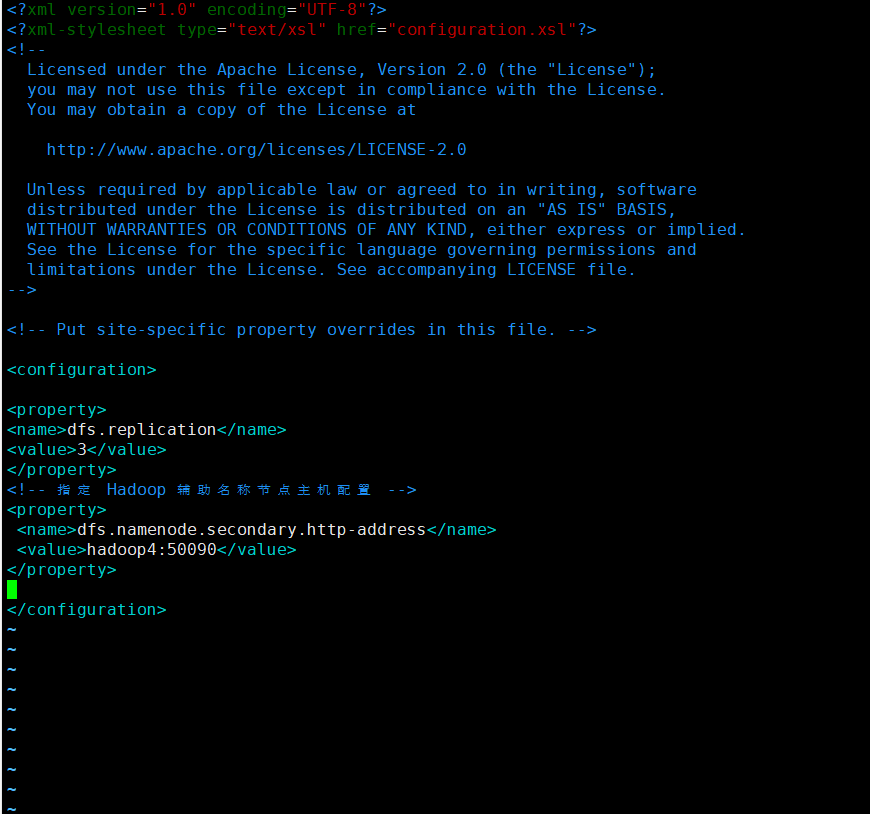
配置 hdfs-site.xml
vim hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 指定 Hadoop 辅助名称节点主机配置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop4:50090</value>
</property>
配置 yarn-env.sh
vim yarn-env.sh
export JAVA_HOME=/software/jdk1.8.0_171
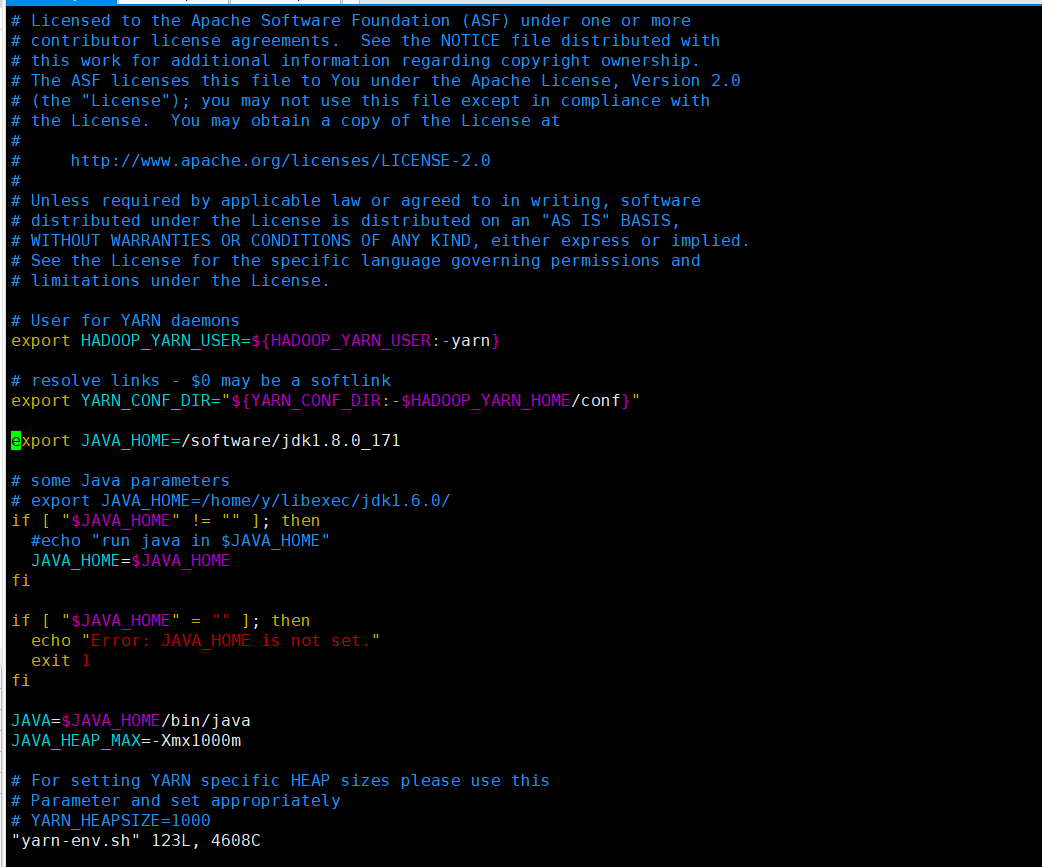
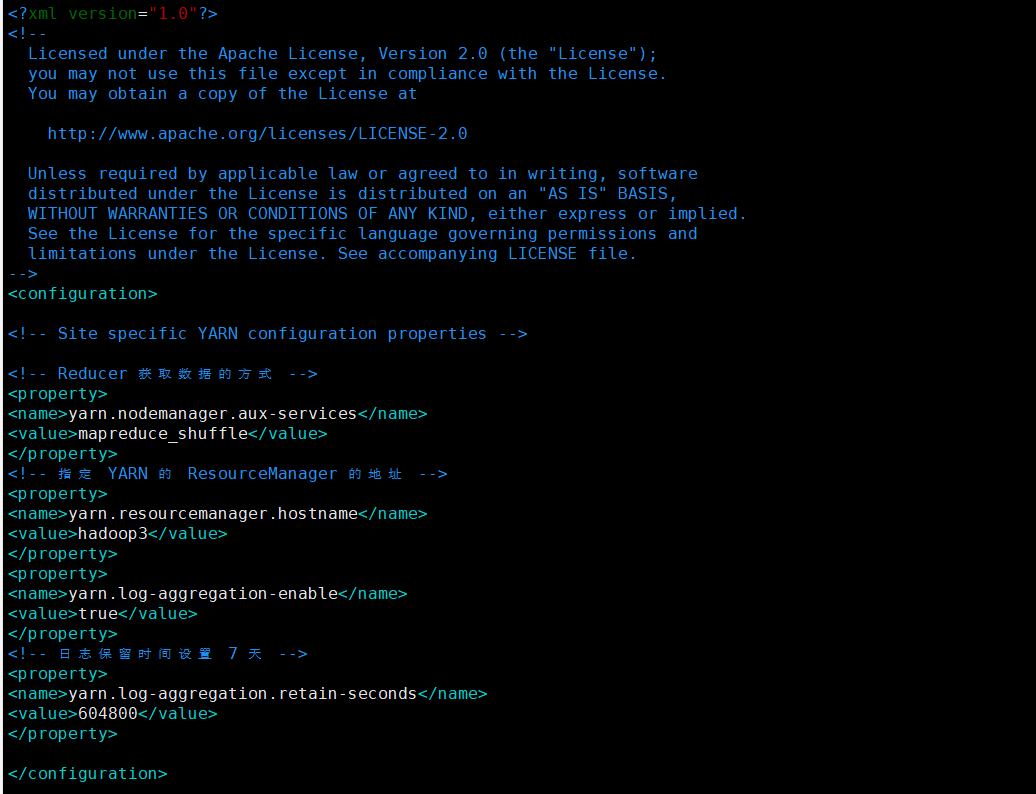
配置 yarn-site.xml
vim yarn-site.xml
<!-- Reducer 获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定 YARN 的 ResourceManager 的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop3</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置 7 天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
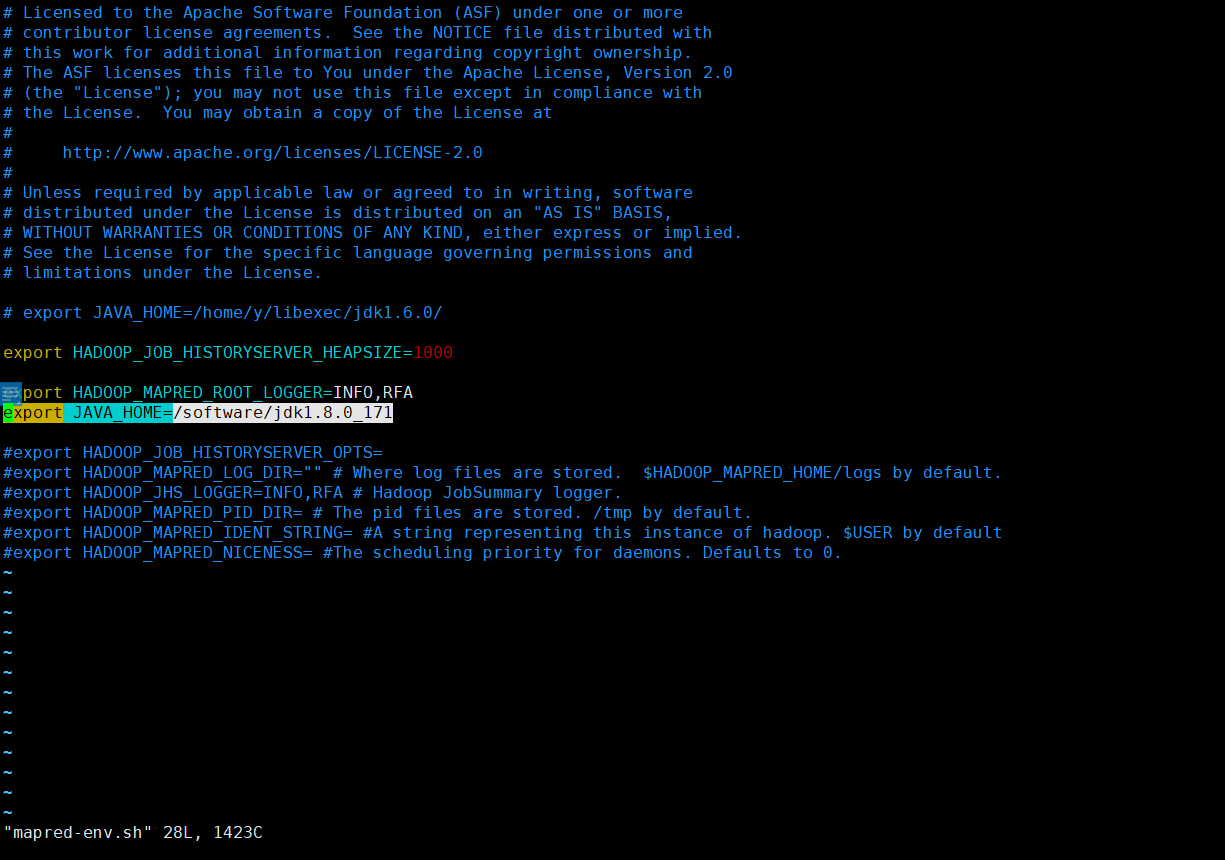
MapReduce 配置文件
vim mapred-env.sh
export JAVA_HOME=/software/jdk1.8.0_171
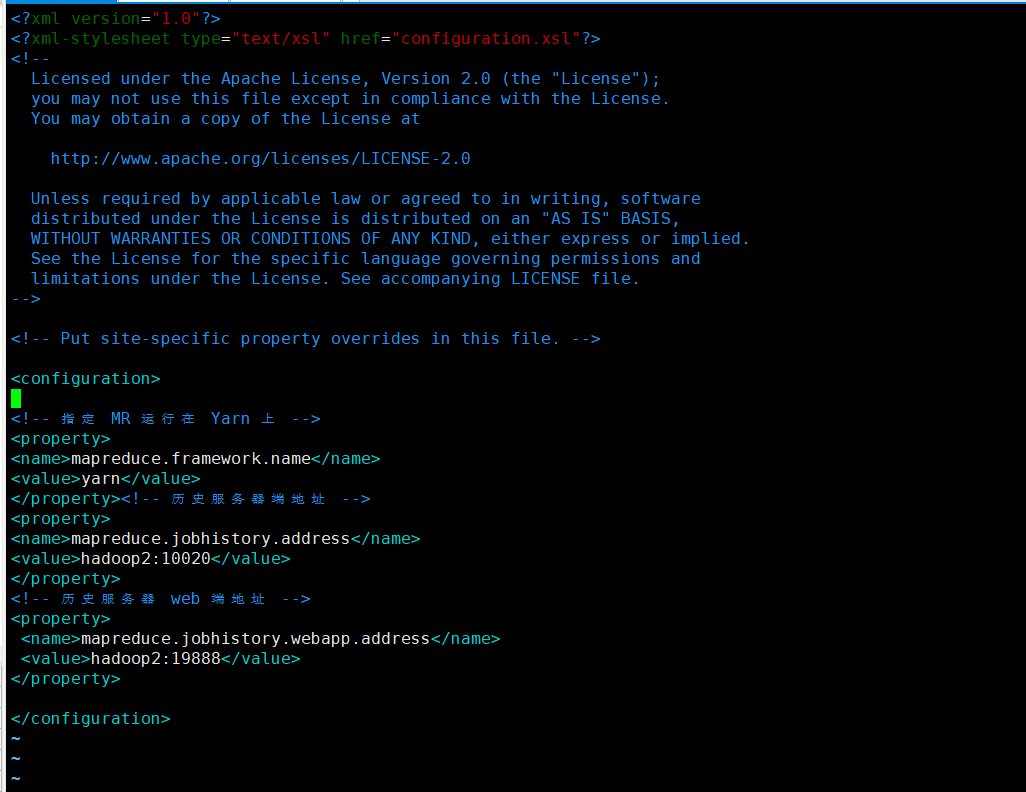
配置 mapred-site.xml
从模板复制一份并改名为 mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
编辑 mapred-site.xml
vi mapred-site.xml
<!-- 指定 MR 运行在 Yarn 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property><!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop2:10020</value>
</property>
<!-- 历史服务器 web 端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop2:19888</value>
</property>
将配置好的虚拟机克隆为三台(如何克隆?不会?别慌!这就来教你)
1:首先,关闭你创建好的虚拟机
shutdown -h now
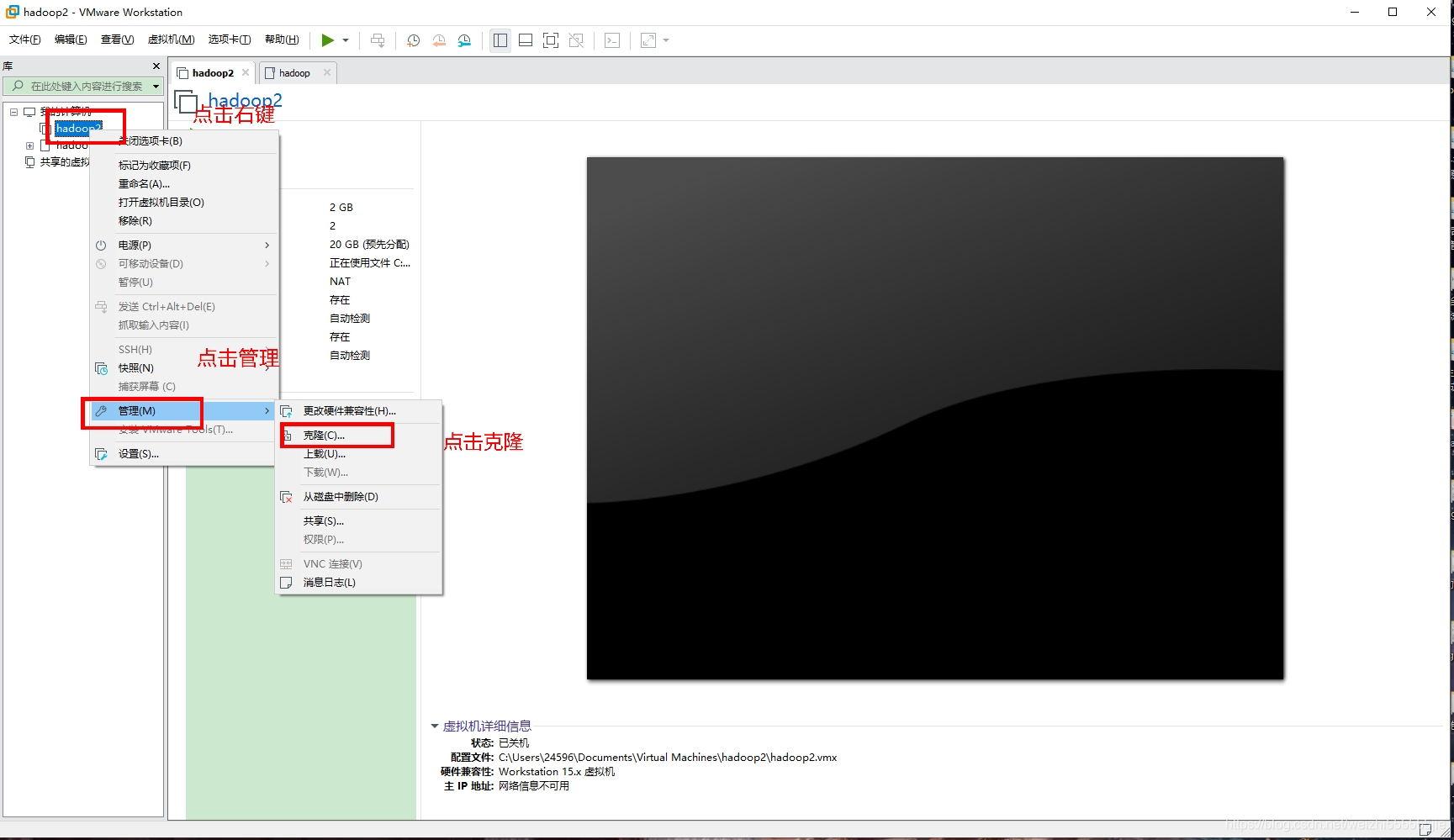
2 点击下一步
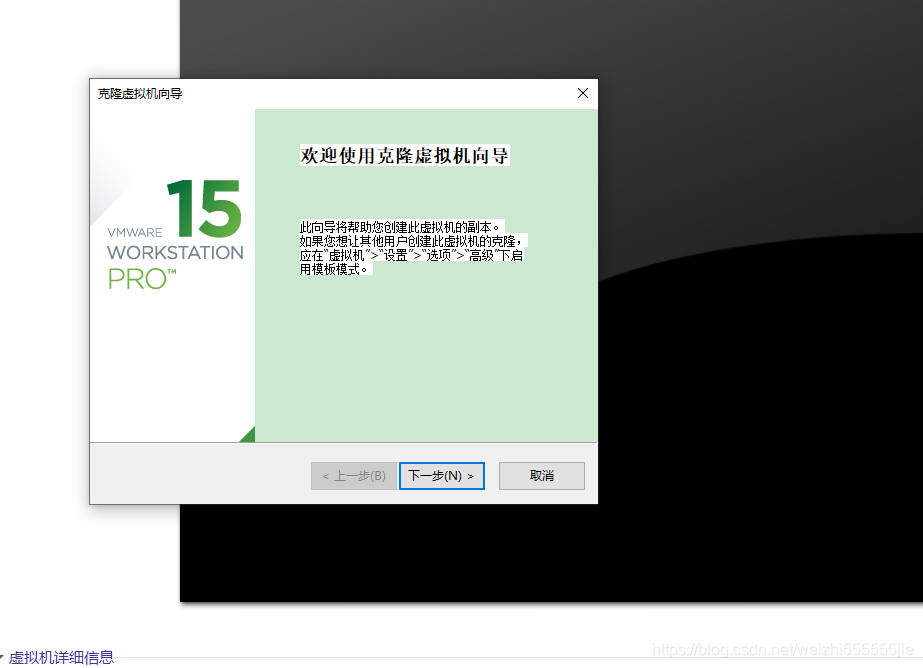
3 点击下一步
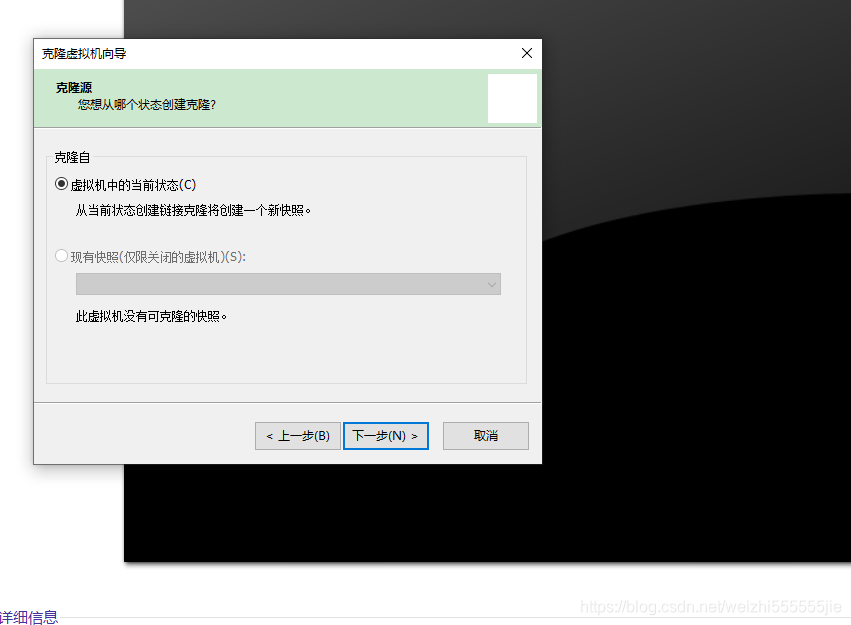
4:选择完整克隆
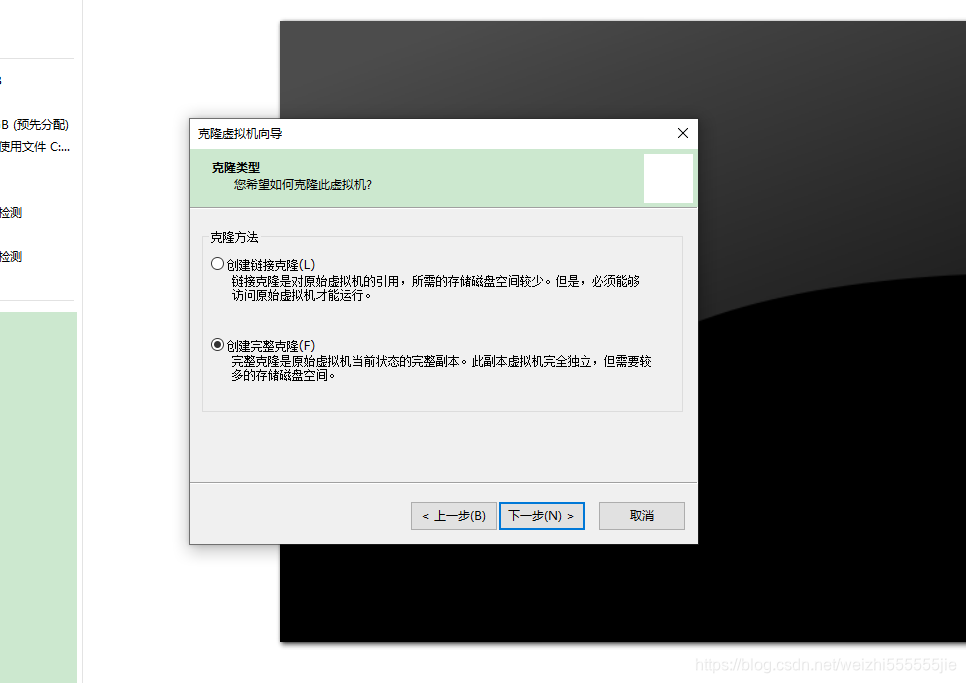
配置另外两台虚拟机的ip和主机名
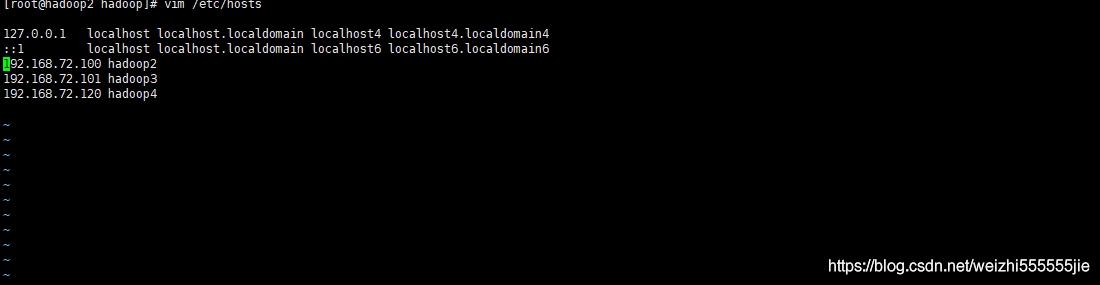
把已经克隆的两台机子的主机名和ip添加在etc下面的hosts
vim /etc/hosts
添加另外两台的主机名和ip(注意,你这里配置的主机IP 和主机名应该是一致的,如何配置主机IP在开头就介绍了,你可以去看看如何配置)
最后三台虚拟机的hosts内容应当一致(注意,这里的主机名和主机IP应该是你自己的,而且主机IP一定在主机名的前面,注意别弄错了!)
配置相关的ssh免密钥登录(为什么要配置ssh免密钥登录)
单节点启动太麻烦!!!
生成公钥和私钥:
ssh-keygen -t rsa
然后敲(三个回车),就会生成两个文件 id_rsa(私钥)、id_rsa.pub(公钥)
将公钥拷贝到要免密登录的目标机器上
ssh-copy-id hadoop2
ssh-copy-id hadoop3
ssh-copy-id hadoop4
群起节点最后的准备
配置 slaves
cd /opt/soft/hadoop-2.7.t/etc/hadoop/slaves
编辑salves
vim slaves
在该文件中增加如下内容:(创建的三台虚拟机都要添加)
hadoop2
hadoop3
hadoop4

启动集群
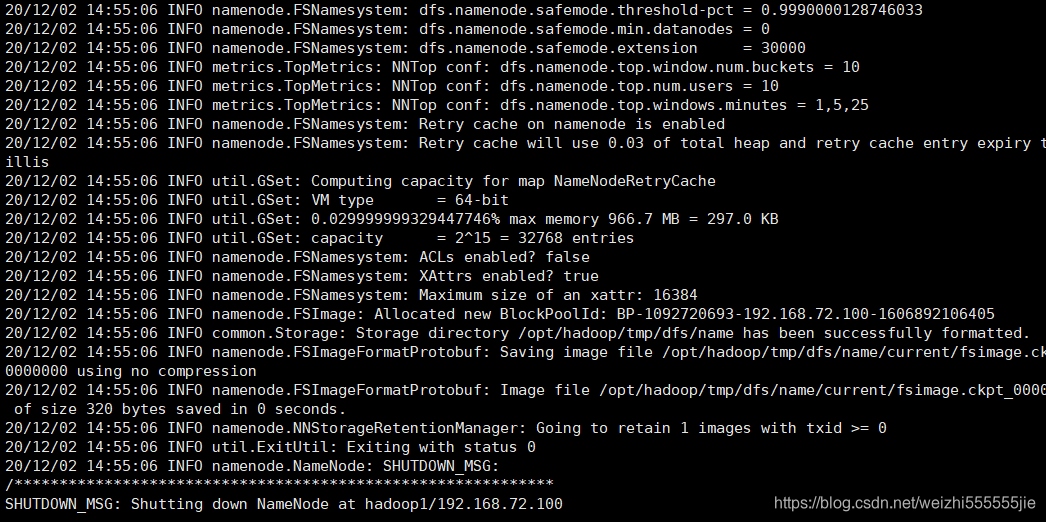
如果集群是第一次启动,需要格式化 NameNode(注意格式化之前,一定要先停
止上次启动的所有 namenode 和 datanode 进程,然后再删除 data 和 log 数据)
hdfs namenode -format
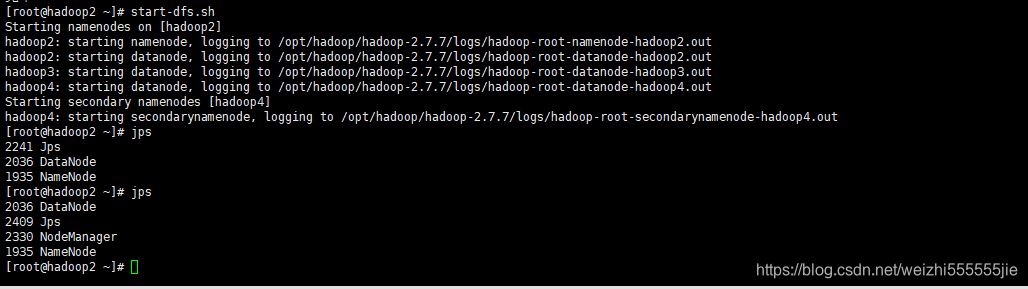
在你的主节点上启动dfs(上面的查看进程没有启动yarn)
start-dfs.sh
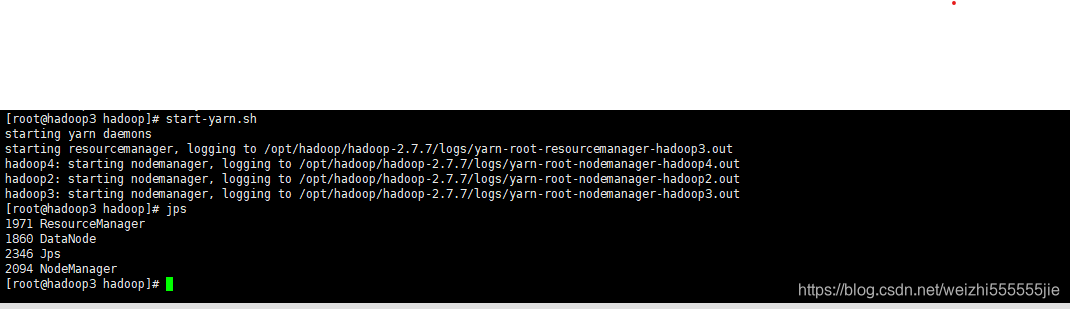
在你配置yarn的机子上启动yarn
start-yarn.sh
最后记得关闭你的三台机子的防火墙(每一台机子都要关闭防火墙)
systemctl stop firewalld
最后查看每一个节点是否与自己设置的配置文件相同(请忽略master 和worker)
jps
hadoop2

hadoop3

hadoop4

打开你的浏览器输入ip+端口(端口是50070)可以看到hadoop对应的界面
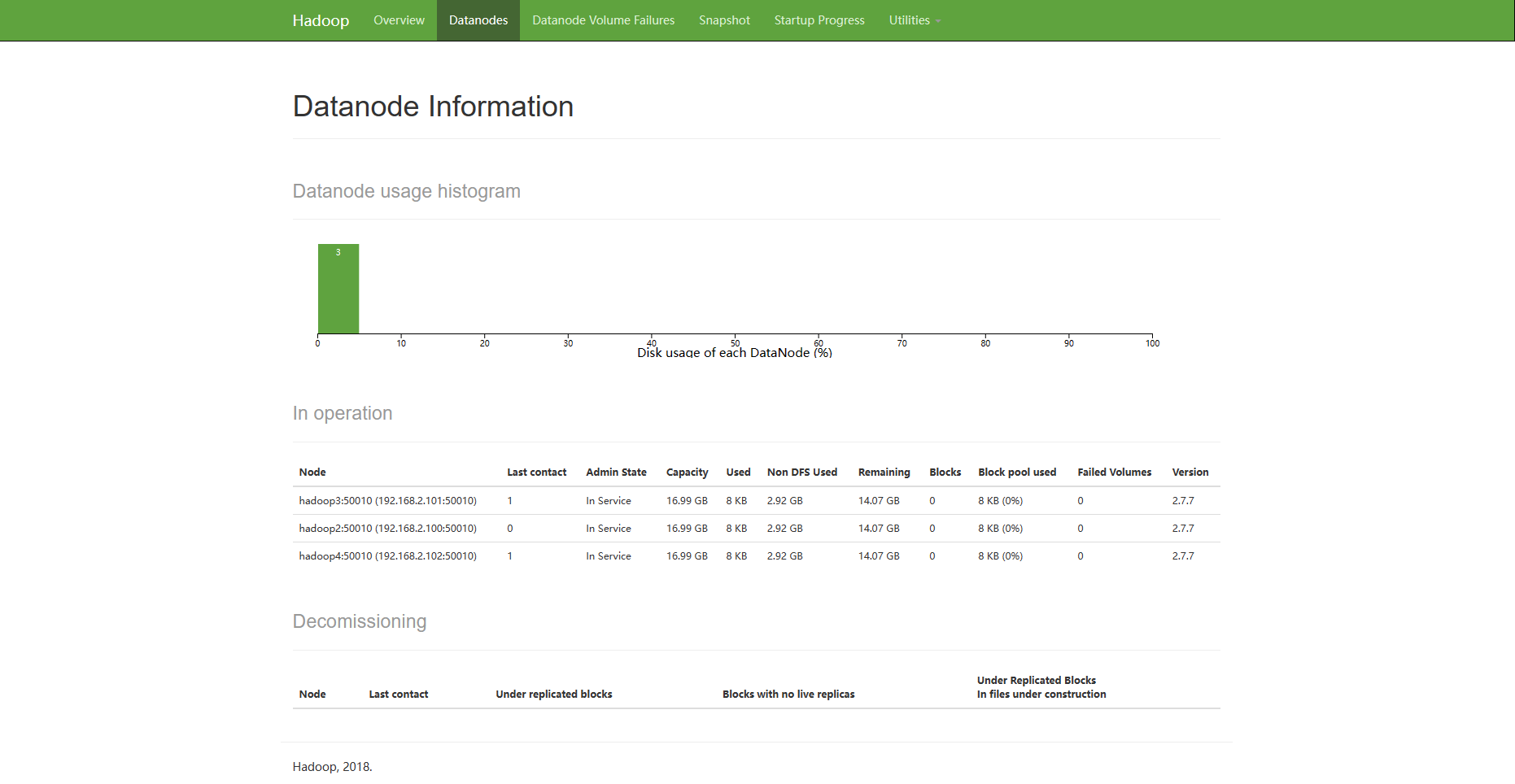
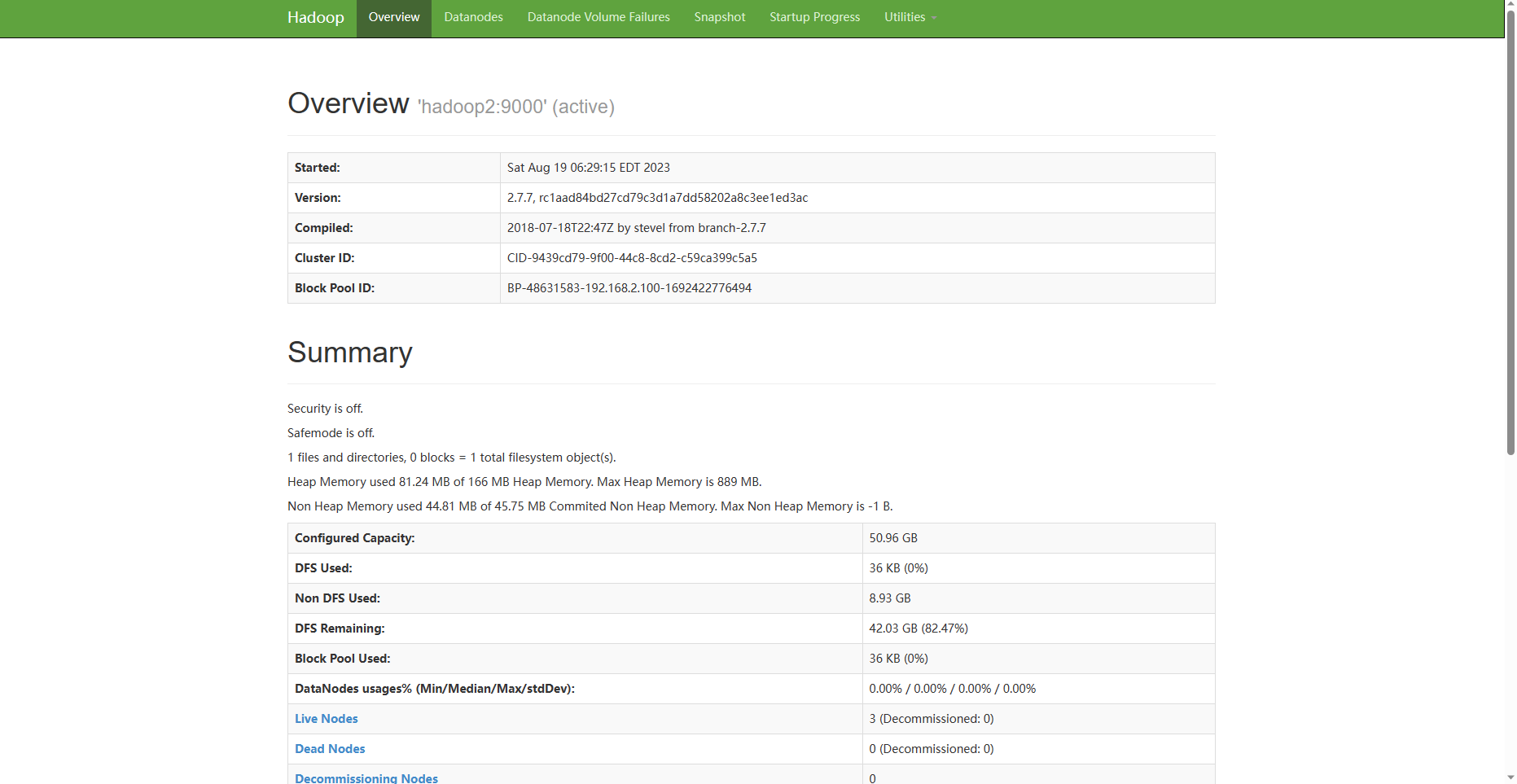
配置你yarn的主机名+8088端口号即可访问下列页面
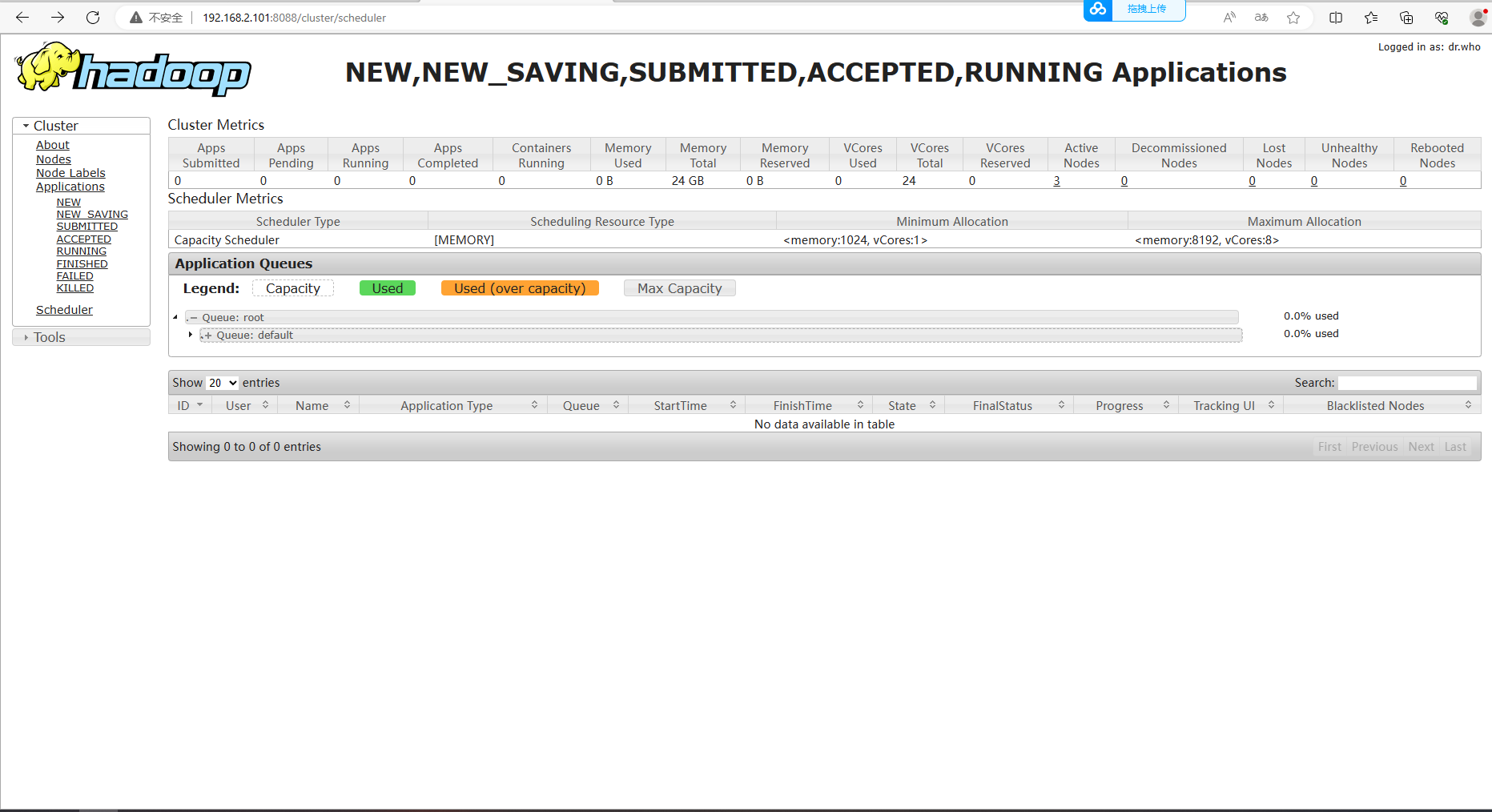
** 下一篇文章我们来学习相关的spark搭建**

 浙公网安备 33010602011771号
浙公网安备 33010602011771号