

spark环境搭建
我们在上一篇文章中搭建了相关的Hadoop,现在我们来搭建spark环境
Hadoop搭建 [https://www.cnblogs.com/xiaozhounandu/p/14166282.html]
前言(注意,spark和Scala环境及配置文件必须每个节点都必须要有!!!)
Spark必须在Hadoop集群上,它的数据来源是HDFS,本质上是Yarn上的一个计算框架,像MR一样。所以在安装Spark之前我们必须准备一个Hadoop集群(Hadoop集群的搭建参考上一篇文章)。
在安装Spark之前我们需要确保服务器上有Java,Scala环境,Java环境的安装配置已经在上一篇文章中提及,接下来的内容是Scala环境的安装配置
Scala环境的安装配置
首先跟之前相同,我们需要上传相关的Scala和spark文件 使用scp 命令从Windows上传文件到虚拟机
但是如果你要搭建spark环境的话,就需要上传搭建环境所需要的spark和Scala文件
scp scala-2.11.8.tgz root@192.168.2.100:/
scp spark-2.2.0-bin-hadoop2.7.tgz root@192.168.2.100:/


开始解压spark和Scala的安装包
使用cd / 来查看文件是否被传递到相关的虚拟机内
cd /

解压spark-2.2.0-bin-hadoop2.7.tgz到software目录
tar -zxvf spark-2.2.0-bin-hadoop2.7.tgz -C software
解压scala-2.11.8.tgz到software目录
tar -zxvf scala-2.11.8.tgz -C software
查看是否解压成功
进入sorfware文件夹查看是否有相关的解压文件(我的Scala和spark解压完成)

将spark和Scala添加到环境变量(请记住他们的安装位置,后续的配置文件需要它们(o_0))
获取 spark 安装路径
/software/spark-2.2.0-bin-hadoop2.7

获取Scala的安装路径
/software/scala-2.11.8

现在我们需要设置相关spark和Scala的配置文件
vim /etc/profile
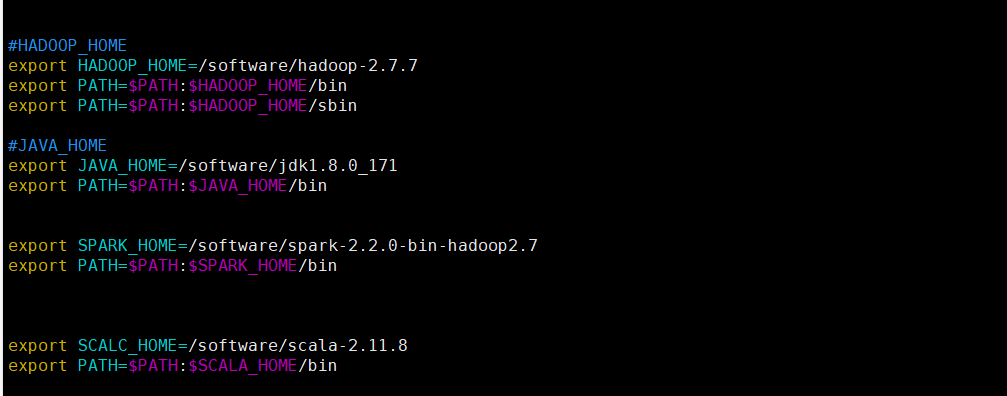
将下列的配置粘贴到文件末尾(注意:相关的HADOOP_HOME和JAVA_HOME需要替换成自己的安装路径)
export SPARK_HOME=/software/spark-2.2.0-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin
export SCALA_HOME=/software/scala-2.11.8
export PATH=$PATH:$SCALA_HOME/bin
我下图是已经添加过Scala和spark的相关目录,如果你只是想要配置hadoop 你只需要添加相关的Java和Hadoop的配置即可
退出保存(按下esc键之后)
:wq
使用下列命令来使配置文件生效
source /etc/profile
检查是否安装成功

spark的相关配置
首先,进入spark目录

然后需要配置spark-env.sh和slaves这两个文件 。
首先我们把缓存的文件spark-env.sh.template改为Spark能识别的文件spark-env.sh:
cp spark-env.sh.template spark-env.sh
修改spark-env.sh文件:
vim spark-env.sh
在spark-env.sh文件末尾添加如下代码:
export JAVA_HOME=/software/jdk1.8.0_171
export SCALA_HOME=/software/scala-2.11.8
export HADOOP_HOME=/software/hadoop-2.7.7
export HADOOP_CONF_DIR=/software/hadoop-2.7.7/etc/hadoop
export SPARK_MASTER_IP=192.168.2.100
export SPARK_WORKER_MEMORY=4g
export SPARK_WORKER_CORES=2
export SPARK_WORKER_INSTANCES:1
变量说明 :
- JAVA_HOME:Java安装目录 ;
- SCALA_HOME:Scala安装目录 ;
- HADOOP_HOME:Hadoop安装目录;
- HADOOP_CONF_DIR:Hadoop集群的配置文件的目录;
- SPARK_MASTER_IP:Spark集群的Master节点的IP地址 ;
- SPARK_WORKER_MEMORY:每个worker节点能够最大分配给exectors的内存大小;
- SPARK_WORKER_CORES:每个worker节点所占有的CPU核数目 ;
- SPARK_WORKER_INSTANCES:每台机器上开启的worker节点的数目
修改slaves文件(这个文件是从slaves.template复制来的,所以要先执行
cp slaves.template slaves
编辑slaves文件
vim slaves
在slaves文件末尾添加如下代码:
hadoop3
hadoop4

最后我们把这个配置好的文件发送到另外两台虚拟机上
scp -r spark-2.2.0-bin-hadoop2.7 root@192.168.2.101:/software
scp -r spark-2.2.0-bin-hadoop2.7 root@192.168.2.102:/software
我们查看相关的文件
hadoop3

hadoop4

我们可以看见所有的文件都完成了
完成以上两步之后,便可重新使用start-dfs.sh脚本启动HDFS文件系统。启动之后使用jps命令可以查看到SparkMaster已经启动了NameNode,
Hadoop3和Hadoop4都启动了DataNode,说明Hadoop的HDFS文件系统已经启动了。
因为hadoop/sbin以及spark/sbin均配置到了系统的环境中,它们同一个文件夹下存在同样的start-all.sh文件,所以最好是进入spark目录,在文件下面运行该脚本:(我最后为了区分把spark sbin 下的start-all.sh 通过mv命令重命名为 start-spark.sh),这个可有可无!!!
./sbin/start-all.sh
成功启动之后,使用jps命令在hadoop2、hadoop3和hadoop4节点上分别可以看到新开启的Master和Worker进程。
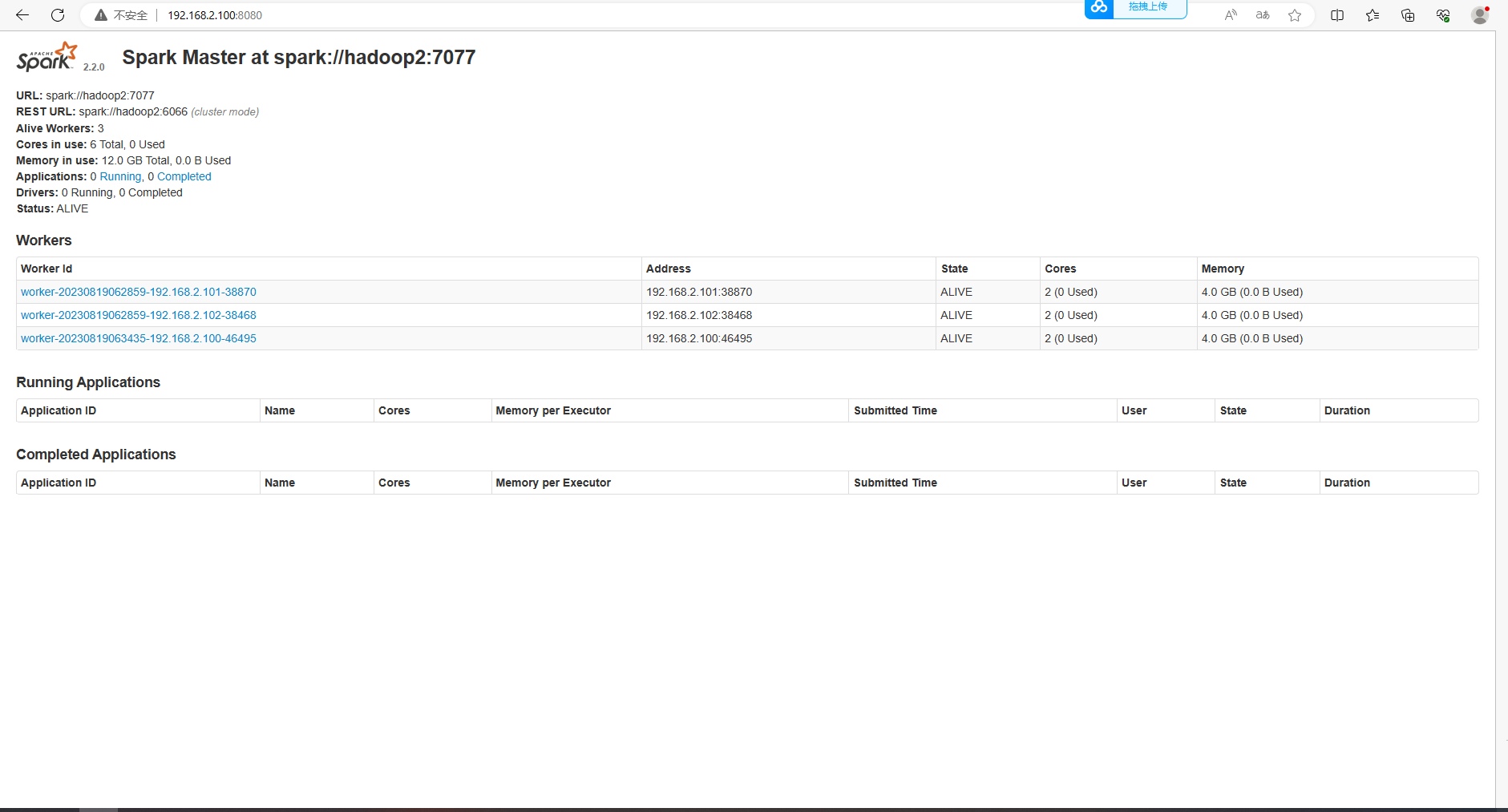
成功启动之后,可以进入Spark的WebUI界面,可以通过主节点IP:8080访问,可见有两个正在运行的Worker节点
查询进程
Hadoop2
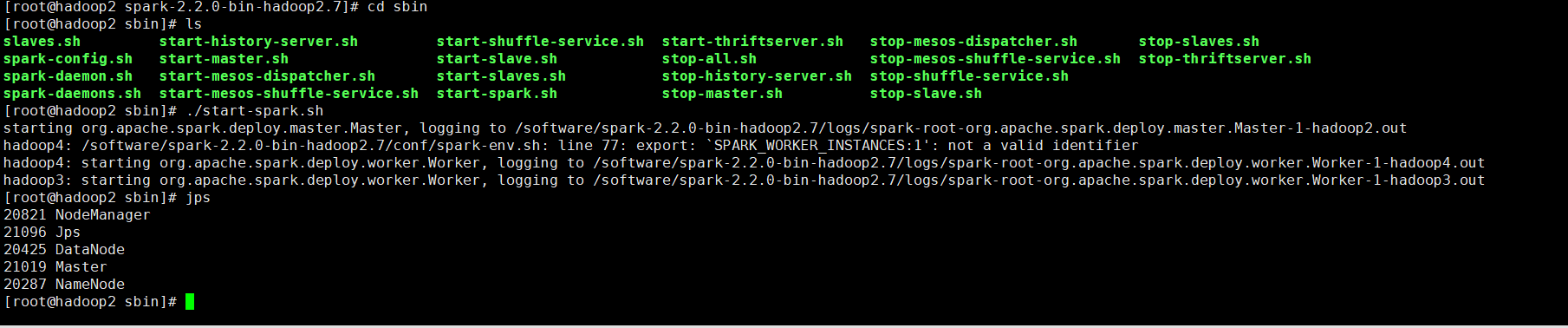
hadoop3

hadoop4

访问相关的端口

 浙公网安备 33010602011771号
浙公网安备 33010602011771号