
[AI开发]小型数据集解决实际工程问题——交通拥堵、交通事故实时告警
这篇文章其实主要是想介绍在深度学习过程中如何使用小型数据集,这种数据集样本数量一般在1000以下,有时候甚至只有几百。一般提到神经网络,大家都会说数据量越丰富,准确性越高,但是实际工作中,可能收集不了大量的训练样本,那么这时候该如何利用有限的数据集去实现我们想要的功能,并且还能得到相对不错的效果呢?本篇文章以拥堵(事故)检测为例,为大家介绍小型数据集在深度学习中的应用,这是一个二分类的分类任务,最终分类结果为“拥堵(疑似事故)”和“正常”,分别包含大约500个样本(包含训练、验证和最后拿来测试模型的样本)。下面是最终效果:

上图显示路况由“通畅”慢慢变成“拥堵”,然后再由“拥堵”变为“通畅”,顶部显示判断拥堵的概率(1.0最高),可以看到在两种状态切换过程中,并不是平滑切换,而是有一个来回抖动的过渡期。下图显示发生追尾车祸时出现拥堵的过程:

上图刚开始车辆行驶缓慢,检测结果不断在两种状态之间切换,之后出现追尾事故,发生拥堵,检测状态稳定。实际使用过程中,我们需要增加一个状态缓存逻辑,去避免这种来回抖动的问题。
小型数据集存在的问题
机器学习包括现在流行的深度学习(关于两者的区别后面打算专门写一篇文章介绍一下),都是在已有数据集中学习规律,然后再将学习到的经验应用到其他数据上,这种经验应用效果的好坏我们称之为“泛化能力”的强弱。如果一个算法学习过大量数据,充分找到了其中规律,那么它的泛化能力可能就比较强,因为见多识广;相反,如果用于学习的数据集不大,那么就不会见多识广了,泛化能力就比较弱,小型数据集就存在这种缺陷。
神经网络的训练过程就是找到合适的参数,让神经网络的预测值和实际值误差最小,如果一个神经网络很复杂,层数多,那么相应需要训练的参数也就多,这时候训练时需要的数据集就必须大一些,否则很难将每个参数调成相对最好的值。
对于小型数据集,有两种方式可以去尝试规避它的缺陷,一种就是使用迁移学习(transfer learning),在已经训练好的复杂模型(参数)基础上,做一些调整,让其适应自己的任务,这种方式的原理就是使用一部分预训练的模型参数,参数训练无需从零开始,这就可以避免前面提到的数据集太小参数调整困难的问题。另外一种方式就是使用简单网络,不要使用类似ResNet、Inception等系列这些比较复杂的卷积网络,这些网络适用于大型数据集,参数多,如果数据量不够,很难训练好它,我们可以根据需要自定义网络结构,比如本篇文章我自定义了一个类似AlexNet的网络结构,5个卷积层外加3个全连接层,相对来说要简单很多。
迁移学习
前面说过,神经网络学习的过程其实就是找到最合适的参数,让网络的预测结果和实际结果之间的误差尽量最小,这个过程一般以优化损失函数的方式来完成(比如寻找损失函数的最小值),为了简化说明,假设我们神经网络最终的损失函数为Loss=W^2-2W+1,形状是一个抛物线:

如上图所示,当W=1时,Loss的值最小,也就是说我们需要通过不断训练,去调整参数W,使其尽量靠近W=1的位置。神经网络在初始化时,参数W的值是随机初始化的,假设随机初始化W=5,那么我们需要一步一步去调整W,使其让左慢慢移动(比如使用梯度下降优化算法),最终W有可能不能刚好落到W=1的位置,但是如果非常接近就已经足够好了,比如W=1.1的时候。注意这里,我们初始化的W=5,它往W=1的位置移动时,距离为4,如果我们每步走的步长(学名叫学习率)比较小,比如为0.0001,那么调整W的次数就需要非常多了(比如4/0.0001),这时候就说明训练很困难。那么如何快速学习、能让W尽快落到W=1的位置呢?答案就在W初始化这一步,我们可以不随机初始化W,而是使用之前训练好的W来初始化,如下图:

如上图,如果我们初始化W=3,那么使其往W=1的位置移动的次数就要少很多了(2/0.001次),这样相比随机初始化W的做法要好很多了。
迁移学习的做法其实说白了就是上面提到初始化W的过程。如果从零开始训练一个网络,那么W可能初始化为5(甚至更大w=10),如果使用迁移学习的方法训练一个网络,那么W可以初始化为3,这个3就是预训练好的参数,然后我们根据实际情况看是否需要再继续调整W(甚至直接使用初始化的W即可,不用再调了)。
迁移学习的前提是,这个预训练的模型要和我们待解决的问题有一定的联系,比如预训练的模型使用的数据集是各种自然花朵的照片,主要用于花型识别,而我们要解决的问题是手工绘图分类,那么这两种任务其实联系不是很大(自然花朵和手工绘图特征相差明显),这时候迁移学习没什么意义(或者说价值不大),这个时候如果使用迁移学习,那么上面W初始化的值可能就不是3了,很可能是20,那么还不如随机初始化W那种方法有效。
Tensorflow2.0中迁移学习的实现过程很简单,有很多内置的网络结构,比如ResNet、Inception系列等等,实例化对应网络类型的对象,加载预训练的权重值,然后截取该网络的一部分(主要是前面提取特征的卷积层),然后在截取的网络之上再新增自定义的分类层,主要是全连接层就行了。最后冻结截取下来的层(不用更新参数),直接用小型数据集训练新增的层参数即可。根据实际情况,我们有时候还需要解冻截取下来的若干层,让其参与一起训练,这个要看具体情况。
使用简单网络
对于我们本篇文章的二分类问题,我们只需要定义一个相对简单的网络结构就可以了,比如类似AlexNet的网络结构(甚至LeNet-5可能也可以),然后我们使用已有的小型数据集从零开始训练这个网络即可。因为网络足够简单,所以相对更容易训练好。
本次任务中,我们判断道路拥堵与否,是不需要颜色信息的,因此在自定义的简单网络结构中,我们增加了一个Lambda层,该层能将输入进行一些变换,产生输出,不需要训练任何参数。这里Lambda层主要负责去色功能,将输入的RGB图片转成灰度图片,然后再参与后面的特征提取环节。下面是我自定义的简单网络结构:

如上图所示,网络开始一个Lambda层,直接将输入的RGB图片(224*224*3)转换成灰度图片(224*224*1),然后紧接着5个卷积层(包含其他池化、归一化等层),最后加2个全连接层(神经元分别为4096和1000),最后是我们的输出层,包含2个神经元,输出一个2维向量,代表每个分类的概率。注意这里的二分类,我们也可以使用一个神经元,但是需要将输出层的softmax激活函数换成sigmoid函数,后者能将任何输入映射到0~1之间,0和1分别代表2个不同分类,同时在模型训练时我们需要选择另外一个损失函数binary_crossentropy(二分交叉熵损失函数)代替现在的categories_crossentropy损失函数(分类交叉熵损失函数)。机器学习中损失函数主要是用来衡量损失大小,也就是实际值和预测值之间的误差。再看看我们训练过程,loss值和accuracy的变化过程:
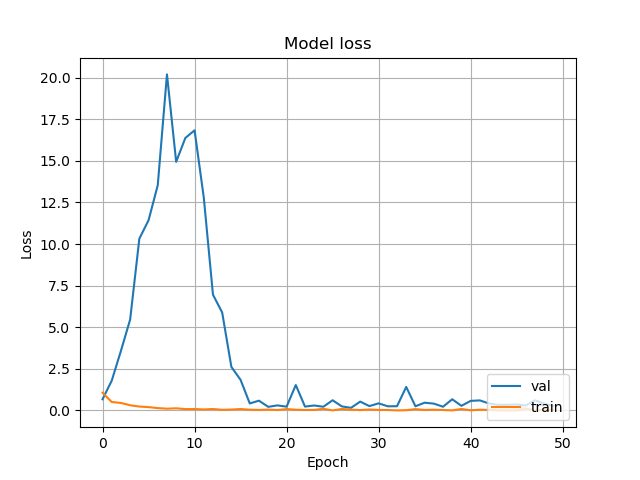
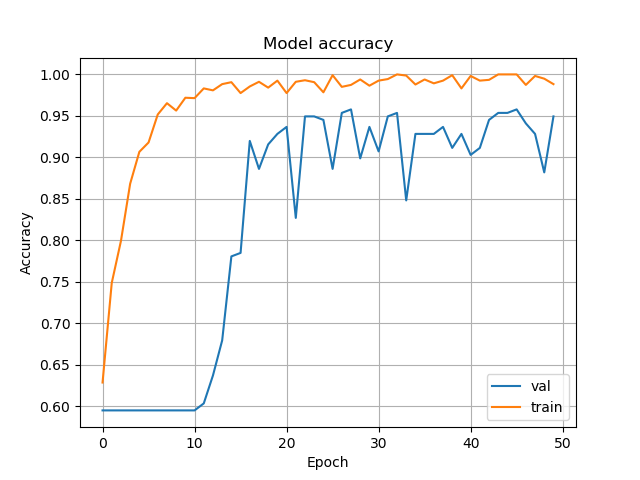
效果还不错,验证准确率最后可以到达95%,再来看看100多张测试集上的效果:

可以看到测试集上的准确率在95.8%,已经不错了。
上面这个截图主要是为了说明如何使用小型数据集,可能网络设计、数据集丰富性上还不够完善,后面在实际工程中使用时,还需要根据需要增加部分场景的训练素材(同样,少量即可)。
数据集的‘数量’和‘质量’
深度学习中的数据集不仅对数量有要求,对质量同样有要求。数量一般是越大越好,同样要求样本标注准确,比如目标检测数据集,要求标注的矩形方框大小、位置都要尽量合理,能完整将目标包含进来,同样数据集应该尽可能包含各种场景,也就是数据集的丰富性要高,就是前面提到的“见多识广”。对于监督学习而言,主要是通过训练素材得到X->Y的映射关系,如果你给出的训练样本本身不具备X->Y的映射关系,或者说这种映射关系没有任何规律、甚至掺杂了很多错误映射关系,那么数据集在怎么大,都没有什么用处,因为你这是在愚弄神经网络,会把它整懵逼了,最后得不偿失。对于深度学习来讲,数据集的数量、质量都同等重要。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号