
从零开始实现lmax-Disruptor队列(三)多线程消费者WorkerPool原理解析
MyDisruptor V3版本介绍
在v2版本的MyDisruptor实现多消费者、消费者组间依赖功能后。按照计划,v3版本的MyDisruptor需要支持多线程消费者的功能。
由于该文属于系列博客的一部分,需要先对之前的博客内容有所了解才能更好地理解本篇博客
- v1版本博客:从零开始实现lmax-Disruptor队列(一)RingBuffer与单生产者、单消费者工作原理解析
- v2版本博客:从零开始实现lmax-Disruptor队列(二)多消费者、消费者组间消费依赖原理解析
MyDisruptor支持多线程消费者
- 之前的版本中我们已经实现了单线程消费者串行的消费,但在某些场景下我们需要更快的消费速度,所以disruptor也提供了多线程的消费者机制。
- 多线程消费者对外功能上和单线程消费者基本一样,也是全量的消费从序列0到序列N的完整事件,但内部却是局部并行乱序消费的。在一定的范围内,具体哪个线程消费哪个事件是通过CAS争抢随机获得的。
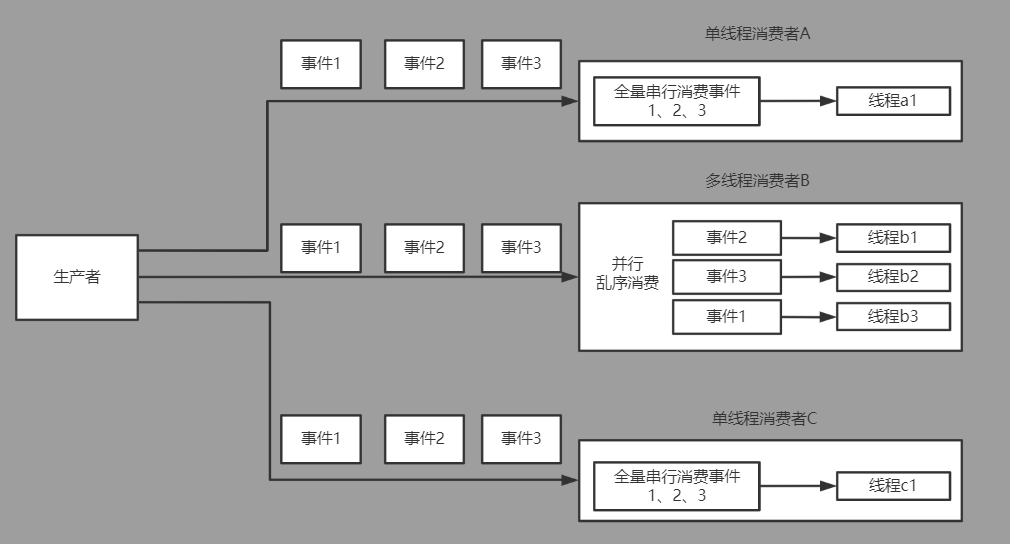
WorkerPool实现解析
- disruptor中多线程消费者的载体是WorkerPool。
- 在V3版本的MyDisruptor中,MyWorkerPool和单线程消费者MyBatchEventProcessor一样,构造函数都是传入三个关键组件:RingBuffer、序列屏障mySequenceBarrier和用户自定义的事件处理器。
- 和单线程消费者不同,多线程消费者允许传入一个用户自定义的事件处理器MyWorkHandler集合。传入的每个MyWorkHandler都会创建一个MyWorkProcessor对象将其封装、包裹起来(下文会展开介绍MyWorkProcessor)。
- 虽然同为用户自定义的消费处理器接口,disruptor中WorkHandler和单线程消费者中传入的EventHandler有些不一样。其消费处理接口只传入了事件对象本身,并没有sequence和endOfBatch参数。
主要原因是因为多线程消费者内部的消费是并行、乱序的,因此sequence序列号意义不大,且endOfBatch也无法准确定义。 - WorkerPool对外提供了一个用于启动消费者的方法start,要求外部传入一个juc下的Executor实现用于启动所有的MyWorkProcessor任务。
/**
* 多线程消费者(仿Disruptor.WorkerPool)
* */
public class MyWorkerPool<T> {
private final MySequence workSequence = new MySequence(-1);
private final MyRingBuffer<T> myRingBuffer;
private final List<MyWorkProcessor<T>> workEventProcessorList;
public MyWorkerPool(
MyRingBuffer<T> myRingBuffer,
MySequenceBarrier mySequenceBarrier,
MyWorkHandler<T>... myWorkHandlerList) {
this.myRingBuffer = myRingBuffer;
final int numWorkers = myWorkHandlerList.length;
this.workEventProcessorList = new ArrayList<>(numWorkers);
// 为每个自定义事件消费逻辑MyEventHandler,创建一个对应的MyWorkProcessor去处理
for (MyWorkHandler<T> myEventConsumer : myWorkHandlerList) {
workEventProcessorList.add(new MyWorkProcessor<>(
myRingBuffer,
myEventConsumer,
mySequenceBarrier,
this.workSequence));
}
}
/**
* 返回包括每个workerEventProcessor + workerPool自身的序列号集合
* */
public MySequence[] getCurrentWorkerSequences() {
final MySequence[] sequences = new MySequence[this.workEventProcessorList.size() + 1];
for (int i = 0, size = workEventProcessorList.size(); i < size; i++) {
sequences[i] = workEventProcessorList.get(i).getCurrentConsumeSequence();
}
sequences[sequences.length - 1] = workSequence;
return sequences;
}
public MyRingBuffer<T> start(final Executor executor) {
final long cursor = myRingBuffer.getCurrentProducerSequence().get();
workSequence.set(cursor);
for (MyWorkProcessor<?> processor : workEventProcessorList) {
processor.getCurrentConsumeSequence().set(cursor);
executor.execute(processor);
}
return this.myRingBuffer;
}
}
/**
* 多线程消费者-事件处理器接口
* */
public interface MyWorkHandler<T> {
/**
* 消费者消费事件
* @param event 事件对象本身
* */
void consume(T event);
}
MyWorkProcessor实现解析
接下来是本篇博客的重点部分,MyWorkProcessor的实现。
/**
* 多线程消费者工作线程 (仿Disruptor.WorkProcessor)
* */
public class MyWorkProcessor<T> implements Runnable{
private final MySequence currentConsumeSequence = new MySequence(-1);
private final MyRingBuffer<T> myRingBuffer;
private final MyWorkHandler<T> myWorkHandler;
private final MySequenceBarrier sequenceBarrier;
private final MySequence workGroupSequence;
public MyWorkProcessor(MyRingBuffer<T> myRingBuffer,
MyWorkHandler<T> myWorkHandler,
MySequenceBarrier sequenceBarrier,
MySequence workGroupSequence) {
this.myRingBuffer = myRingBuffer;
this.myWorkHandler = myWorkHandler;
this.sequenceBarrier = sequenceBarrier;
this.workGroupSequence = workGroupSequence;
}
public MySequence getCurrentConsumeSequence() {
return currentConsumeSequence;
}
@Override
public void run() {
long nextConsumerIndex = this.currentConsumeSequence.get() + 1;
// 设置哨兵值,保证第一次循环时nextConsumerIndex <= cachedAvailableSequence一定为false,走else分支通过序列屏障获得最大的可用序列号
long cachedAvailableSequence = Long.MIN_VALUE;
// 最近是否处理过了序列
boolean processedSequence = true;
while (true) {
try {
if(processedSequence) {
// 争抢到了一个新的待消费序列,但还未实际进行消费(标记为false)
processedSequence = false;
// 如果已经处理过序列,则重新cas的争抢一个新的待消费序列
do {
nextConsumerIndex = this.workGroupSequence.get() + 1L;
// 由于currentConsumeSequence会被注册到生产者侧,因此需要始终和workGroupSequence worker组的实际sequence保持协调
// 即当前worker的消费序列currentConsumeSequence = 当前消费者组的序列workGroupSequence
this.currentConsumeSequence.lazySet(nextConsumerIndex - 1L);
// 问题:只使用workGroupSequence,每个worker不维护currentConsumeSequence行不行?
// 回答:这是不行的。因为和单线程消费者的行为一样,都是具体的消费者eventHandler/workHandler执行过之后才更新消费者的序列号,令其对外部可见(生产者、下游消费者)
// 因为消费依赖关系中约定,对于序列i事件只有在上游的消费者消费过后(eventHandler/workHandler执行过),下游才能消费序列i的事件
// workGroupSequence主要是用于通过cas协调同一workerPool内消费者线程序列争抢的,对外的约束依然需要workProcessor本地的消费者序列currentConsumeSequence来控制
// cas更新,保证每个worker线程都会获取到唯一的一个sequence
} while (!workGroupSequence.compareAndSet(nextConsumerIndex - 1L, nextConsumerIndex));
}else{
// processedSequence == false(手头上存在一个还未消费的序列)
// 走到这里说明之前拿到了一个新的消费序列,但是由于nextConsumerIndex > cachedAvailableSequence,没有实际执行消费逻辑
// 而是被阻塞后返回获得了最新的cachedAvailableSequence,重新执行一次循环走到了这里
// 需要先把手头上的这个序列给消费掉,才能继续拿下一个消费序列
}
// cachedAvailableSequence只会存在两种情况
// 1 第一次循环,初始化为Long.MIN_VALUE,则必定会走到下面的else分支中
// 2 非第一次循环,则cachedAvailableSequence为序列屏障所允许的最大可消费序列
if (nextConsumerIndex <= cachedAvailableSequence) {
// 争抢到的消费序列是满足要求的(小于序列屏障值,被序列屏障允许的),则调用消费者进行实际的消费
// 取出可以消费的下标对应的事件,交给eventConsumer消费
T event = myRingBuffer.get(nextConsumerIndex);
this.myWorkHandler.consume(event);
// 实际调用消费者进行消费了,标记为true.这样一来就可以在下次循环中cas争抢下一个新的消费序列了
processedSequence = true;
} else {
// 1 第一次循环会获取当前序列屏障的最大可消费序列
// 2 非第一次循环,说明争抢到的序列超过了屏障序列的最大值,等待生产者推进到争抢到的sequence
cachedAvailableSequence = sequenceBarrier.getAvailableConsumeSequence(nextConsumerIndex);
}
} catch (final Throwable ex) {
// 消费者消费时发生了异常,也认为是成功消费了,避免阻塞消费序列
// 下次循环会cas争抢一个新的消费序列
processedSequence = true;
}
}
}
}
- WorkProcessor和单线程消费者BatchEventProcessor有不少相似之处:
- 也实现了Runnable接口,作为一个独立的线程通过一个主循环不断的监听上游进度而进行工作。
- 也通过构造函数传入的sequenceBarrier来控制消费速度。
- WorkProcessor是隶属于特定WorkerPool的,一个WorkerPool下的所有WorkProcessor线程都通过WorkerPool的序列号对象workSequence来协调争抢序列。
- WorkerPool内的每个MyWorkProcessor线程都可以通过CAS争抢到一个消费者内独一无二的序列号,保证不会出现多线程间的重复消费
(假设一个WorkPool有三个WorkProcessor线程A、B、C,如果workerA线程争抢到了序列号1,则workerB、workerC线程就不会再处理序列号1,而是去争抢序列号2了)
虽然disruptor一直在努力避免使用CAS,但多线程消费者并发争抢序列号的场景下也没有特别好的办法了。 - CAS争抢到了一个序列号后,如果当前序列号可用(小于或等于序列屏障给出的当前最大可消费序列号),则会调用用户自定义消费逻辑myWorkHandler进行业务处理。
如果当前序列号不可用,则会被阻塞于序列屏障的getAvailableConsumeSequence方法中。 - WorkerPool通过getCurrentWorkerSequences对外暴露workerSequence和每个worker线程的本地消费序列合并在一起的集合。
因此CAS争抢时,通过this.currentConsumeSequence.lazySet(nextConsumerIndex - 1L),保证当前workerProcessor的消费序列不会落后WorkerPool的序列太多
只使用workGroupSequence,每个MyWorkProcessor不单独维护currentConsumeSequence行不行?
- 这是不行的。因为和单线程消费者的行为一样,都是具体的消费者eventHandler/workHandler执行过之后才更新消费者的序列号,令其对外部可见(生产者、下游消费者)。
消费依赖关系中约定,对于序列i事件只有在上游的消费者消费过后(eventHandler/workHandler执行过),下游才能消费序列i的事件。 - 如果只使用workGroupSequence,则cas争抢成功后(但具体的消费者还未消费),其对应的消费序列便立即对外部可见了,这是不符合上述约定的。
- workGroupSequence主要是用于通过cas协调同一workerPool内消费者线程序列争抢,对外的约束依然需要每个workProcessor内部的消费者序列currentConsumeSequence来控制。
MyDisruptor v3版本demo解析
v3版本支持了多线程消费者功能,下面通过一个demo来展示如何使用该功能。
public class MyRingBufferV3Demo {
/**
* -> 多线程消费者B(依赖A)
* 单线程消费者A -> 单线程消费者D(依赖B、C)
* -> 单线程消费者C(依赖A)
* */
public static void main(String[] args) throws InterruptedException {
// 环形队列容量为16(2的4次方)
int ringBufferSize = 16;
// 创建环形队列
MyRingBuffer<OrderEventModel> myRingBuffer = MyRingBuffer.createSingleProducer(
new OrderEventProducer(), ringBufferSize, new MyBlockingWaitStrategy());
// 获得ringBuffer的序列屏障(最上游的序列屏障内只维护生产者的序列)
MySequenceBarrier mySequenceBarrier = myRingBuffer.newBarrier();
// ================================== 基于生产者序列屏障,创建消费者A
MyBatchEventProcessor<OrderEventModel> eventProcessorA =
new MyBatchEventProcessor<>(myRingBuffer, new OrderEventHandlerDemo("consumerA"), mySequenceBarrier);
MySequence consumeSequenceA = eventProcessorA.getCurrentConsumeSequence();
// RingBuffer监听消费者A的序列
myRingBuffer.addGatingConsumerSequenceList(consumeSequenceA);
// ================================== 消费者组依赖上游的消费者A,通过消费者A的序列号创建序列屏障(构成消费的顺序依赖)
MySequenceBarrier workerSequenceBarrier = myRingBuffer.newBarrier(consumeSequenceA);
// 基于序列屏障,创建多线程消费者B
MyWorkerPool<OrderEventModel> workerPoolProcessorB =
new MyWorkerPool<>(myRingBuffer, workerSequenceBarrier,
new OrderWorkHandlerDemo("workerHandler1"),
new OrderWorkHandlerDemo("workerHandler2"),
new OrderWorkHandlerDemo("workerHandler3"));
MySequence[] workerSequences = workerPoolProcessorB.getCurrentWorkerSequences();
// RingBuffer监听消费者C的序列
myRingBuffer.addGatingConsumerSequenceList(workerSequences);
// ================================== 通过消费者A的序列号创建序列屏障(构成消费的顺序依赖),创建消费者C
MySequenceBarrier mySequenceBarrierC = myRingBuffer.newBarrier(consumeSequenceA);
MyBatchEventProcessor<OrderEventModel> eventProcessorC =
new MyBatchEventProcessor<>(myRingBuffer, new OrderEventHandlerDemo("consumerC"), mySequenceBarrierC);
MySequence consumeSequenceC = eventProcessorC.getCurrentConsumeSequence();
// RingBuffer监听消费者C的序列
myRingBuffer.addGatingConsumerSequenceList(consumeSequenceC);
// ================================== 基于多线程消费者B,单线程消费者C的序列屏障,创建消费者D
MySequence[] bAndCSequenceArr = new MySequence[workerSequences.length+1];
// 把多线程消费者B的序列复制到合并的序列数组中
System.arraycopy(workerSequences, 0, bAndCSequenceArr, 0, workerSequences.length);
// 数组的最后一位是消费者C的序列
bAndCSequenceArr[bAndCSequenceArr.length-1] = consumeSequenceC;
MySequenceBarrier mySequenceBarrierD = myRingBuffer.newBarrier(bAndCSequenceArr);
MyBatchEventProcessor<OrderEventModel> eventProcessorD =
new MyBatchEventProcessor<>(myRingBuffer, new OrderEventHandlerDemo("consumerD"), mySequenceBarrierD);
MySequence consumeSequenceD = eventProcessorD.getCurrentConsumeSequence();
// RingBuffer监听消费者D的序列
myRingBuffer.addGatingConsumerSequenceList(consumeSequenceD);
// 启动消费者线程A
new Thread(eventProcessorA).start();
// 启动workerPool多线程消费者B
workerPoolProcessorB.start(Executors.newFixedThreadPool(100, new ThreadFactory() {
private final AtomicInteger mCount = new AtomicInteger(1);
@Override
public Thread newThread(Runnable r) {
return new Thread(r,"worker" + mCount.getAndIncrement());
}
}));
// 启动消费者线程C
new Thread(eventProcessorC).start();
// 启动消费者线程D
new Thread(eventProcessorD).start();
// 生产者发布100个事件
for(int i=0; i<100; i++) {
long nextIndex = myRingBuffer.next();
OrderEventModel orderEvent = myRingBuffer.get(nextIndex);
orderEvent.setMessage("message-"+i);
orderEvent.setPrice(i * 10);
System.out.println("生产者发布事件:" + orderEvent);
myRingBuffer.publish(nextIndex);
}
}
}
- WorkPool对外直接面向用户,而WorkProcessor则被封装隐藏起来,对用户不可见。
- WorkPool作为一个消费者有着自己的消费序列,其也是通过往ringBuffer的生产者中注册消费序列限制生产速度,让下游消费者维护消费序列实现上下游依赖关系的。
但WorkPool是多线程的,其消费序列是一个包含WorkPool总序列号和各个子线程内序列号的集合。因此在上述场景中,需要将这个集合(数组)视为一个整体维护起来。
总结
- 在v3版本中我们实现了多线程的消费者。多线程消费者中,每个worker线程通过cas排它的争抢序列号,因此多线程消费者WorkPool可以在同一时刻并发的同时消费多个事件。
在消费逻辑较耗时的场景下,可以考虑使用disruptor的多线程消费者来加速消费。 - 由于java中线程调度主要由操作系统控制,在某一线程cas争抢到序列号n后但还未实际调用workerHandler的用户自定义消费接口前,可能会被操作系统暂时挂起,此时争抢到更大序列号n+1的其它线程则可以先调用workerHandler的用户自定义消费接口。
带来的直接影响就是多线程消费者内部的消费是局部乱序的(可能n+1序列的事件先消费、n序列的事件后消费)。
disruptor无论在整体设计还是最终代码实现上都有很多值得反复琢磨和学习的细节,希望能帮助到对disruptor感兴趣的小伙伴。
本篇博客的完整代码在我的github上:https://github.com/1399852153/MyDisruptor 分支:feature/lab3

 浙公网安备 33010602011771号
浙公网安备 33010602011771号