
从零开始实现lmax-Disruptor队列(一)RingBuffer与单生产者、单消费者工作原理解析
1.lmax-Disruptor队列介绍
disruptor是英国著名的金融交易所lmax旗下技术团队开发的一款java实现的高性能内存队列框架
其发明disruptor的主要目的是为了改进传统的内存队列实现如jdk的ArrayBlockingQueue、LinkedBlockingQueue等在现代CPU硬件上的一些缺陷
1. 伪共享问题
现代的CPU都是多核的,每个核心都拥有独立的高速缓存。高速缓存由固定大小的缓存行组成(通常为32个字节或64个字节)。
CPU以缓存行作为最小单位读写,且一个缓存行通常会被多个变量占据(例如32位的引用指针占4字节,64位的引用指针占8个字节)。
这样的设计导致了一个问题:即使缓存行上的变量是无关联的(比如不属于同一个对象),但只要缓存行上的某一个共享变量发生了变化,则整个缓存行都会进行缓存一致性的同步。
而CPU间缓存一致性的同步是有一定性能损耗的,能避免则尽量避免。这就是所谓的“伪共享”问题。
disruptor通过对队列中一些关键变量进行了缓存行的填充,避免其因为不相干的变量读写而无谓的刷新缓存,解决了伪共享的问题。
关于CPU间缓存一致性相关的内容可以参考下我以前的博客:高速缓存一致性协议MESI与内存屏障
2. 队头、队尾引用等共享变量过多的的争抢
传统的内存队列由于生产者、消费者都会并发的读写队列头、队列尾的引用和更新队列size,
因此被迫使用了如ReentrantLock等基于上下文切换的悲观锁或是CAS机制的乐观锁等互斥机制来保证队列关键数据的并发安全,但即使是CAS这样非阻塞的机制,由于存在失败重试机制和高速缓存间强一致地同步操作,其性能损耗在追求极限性能的高并发队列中间件上也是不容忽视的。
disruptor在实现过程中巧妙的通过全局有序增长的序列号机制代替了显式的队列头、队列尾更新,极大的减少了需要并发更新共享变量的场合,从而提高了高并发场景下队列的吞吐量。
3. 入队、出队时队列元素产生大量垃圾
juc包下的阻塞队列队列元素会在入队时被创建、出队被消费后就不再被引用而产生大量的垃圾。
disruptor通过基于数组的环形队列,在开始运行前用空的事件对象填充好整个队列,后续的生产与消费则不新增或者删除队列元素,而是配合序列号机制,修改队列元素中的属性进行生产者和消费者的交互。
通过固定队列中的对象,disruptor避免了入队、出队时产生不必要的垃圾。
除此之外,disruptor还允许设置消费者间消费的依赖关系(例如A、B消费者消费完毕后,C才能消费),构造高效的事件传输管道,实现1对1,1对多,多对1等模式的组合。
更详细的内容可以参考disruptor的官方文档:https://lmax-exchange.github.io/disruptor/disruptor.html
上面虽然介绍了有关disruptor的各种特点,但只有详细的研究源码后才能更好地理解disruptor的原理,体会其整体设计思路以及代码层面微观实现的精妙之处。
2.MyDisruptor介绍
编程和画画很类似,比起对着已经完工的画作进行分析,我更喜欢参考着原画从设计者的角度出发自己临摹出一副属于自己的画。在这个过程中,可以看到程序从简单到复杂的全过程,能更清楚得知道哪些是核心功能而哪些是相对边缘的逻辑,从而获得一条平滑的学习曲线。
MyDisruptor就是我按照上述学习方式自己临摹出来的结果,按照功能模块大致分为六个迭代版本逐步完成,最终实现了一个和disruptor相差无几的队列。
在这个过程中,低版本的代码是相对精简的,可以让读者更容易理解当前功能的实现原理,不会被其余旁路代码的复杂度给绕晕。
- ringBuffer + 单线程生产者 + 单线程消费者
- 多线程消费者 + 消费者组依赖关系(A/B -> C, AB消费成功后C才能消费)
- worker线程组消费者
- 多线程生产者
- disruptor dsl(提供简单易用的接口,屏蔽掉人工组装依赖链的复杂度)
- ringBuffer等关键组件解决伪共享问题 + 参考disruptor对特定的数据结构做进一步优化
3.MyDisruptor v1版本详细解析
v1版本是整个项目的基石,所以在这里先介绍disruptor的核心设计思想和各关键组件的整体关联以帮助大家更好地理解。
3.1 disruptor核心设计思想
volatile + 并发写变量的分离
我们知道基于阻塞/唤醒的悲观锁和基于CAS的乐观锁都是并发编程中常见地同步机制,但是其在高并发场景下都有一定的性能损耗。那么有没有开销更低地线程间同步机制呢?
答案是有的,即单纯依靠内存屏障提供的多线程间的内存可见性能力。
这里纠正一个部分人理解上的误区:java中volatile修饰的变量具备多线程间的可见性能力,但不提供原子性更新的功能,所以无法保证线程安全。这段概述是不全面的,确实在多线程并发读写时,由于缺少原子性的更新机制,单靠volatile是无法做到线程安全的。
但在单写者多读者这一更为特殊的场景下,仅靠volatile提供的内存可见性能力就可以做到并发场景下的线程安全,且其性能开销比CAS更低。
一写多读的序列号机制
为了解决上述传统队列中共享变量高并发时过多争抢的问题,disruptor从设计一开始就引入了单调递增的序列号机制,每个生产者、消费者线程都有自己独立所属的序列号变量(volatile修饰),其只能由序列号所属的线程写入,其它线程只能去读取,做到一写多读。
- 生产者和消费者通过写自己独占的序列号,读其它线程序列号的方式进行通信
- 序列号对队列长度取余,可以得到其在环形队列中的实际下标位置
- 生产者每进行一次生产发布,生产者序列号就加1;消费者每进行一次消费,消费者序列号也加1。
- 当生产者的序列号超过消费者时,说明当前生产速度超过了消费速度;当生产者超过最慢消费者的序列之差和队列容量相等时,需要阻塞生产者,等待消费者消费(逻辑上等于队列已满)
- 当消费者的序列号即将超过生产者时(临界状态恰好等于),则需要阻塞当前消费者,等待生产者生产(逻辑上等于队列为空)
- 在消费者间存在依赖的场景下,不同于消费者间通过传递队列元素对象来实现依赖关系。当前消费者除了需要关注生产者的序列号,也关注其依赖的上游消费者。使自己的序列号始终不超过上游消费者的序列号,巧妙地实现依赖关系。
disruptor拆分了传统队列中多写多读的队列头、尾等多读多写的变量,仅凭借内存可见性就完成了生产者和消费者间的通信
disruptor简要架构图
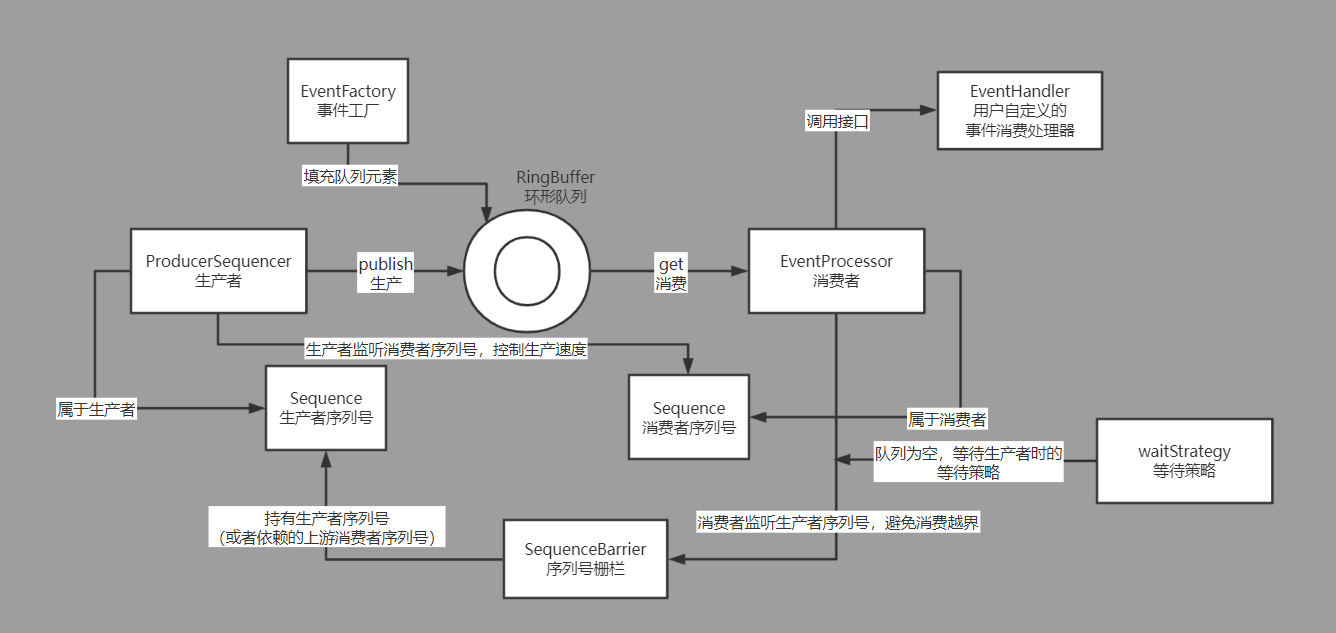
下面我们基于源码分析MyDisruptor,为了和lmax-Disruptor作区分MyDisruptor内各个组件都在disruptor对应组件名称的基础上加了My前缀。
3.2 MyDisruptor核心组件解析
MySequence序列号对象
- 序列号Sequence是disruptor实现生产者、消费者间互相通信的关键,因此在Sequence内部有一个volatile修饰的long变量value(long类型足够大,可以不考虑溢出),用于标识单调递增的序列号。
- 为了在特定的场景下避免对volatile变量更新时不必要的CPU缓存刷新,通过unsafe的putOrderedLong方法来优化性能(具体用到的地方会在后面章节中展开)。
- putOrderedLong操作在实际更新前会插入store-store屏障(保证与之前发生的写操作的有序性,不会重排序导致乱序),比起对volatile修饰的value=xxx时设置的store-load屏障性能要好一些。
其带来的后果就是putOrderedLong更新后,不会立即强制CPU刷新更新后在缓存中的数据到主内存,导致其修改的最新值对其它CPU核心(其它线程)来说不是立即可见的(但延迟很低,一般在纳秒级别)。
/**
* 序列号对象(仿Disruptor.Sequence)
* 由于需要被生产者、消费者线程同时访问,因此内部是一个volatile修饰的long值
* */
public class MySequence {
/**
* 序列起始值默认为-1,保证下一序列恰好是0(即第一个合法的序列号)
* */
private volatile long value = -1;
private static final Unsafe UNSAFE;
private static final long VALUE_OFFSET;
static {
try {
// 由于提供给cas内存中字段偏移量的unsafe类只能在被jdk信任的类中直接使用,这里使用反射来绕过这一限制
Field getUnsafe = Unsafe.class.getDeclaredField("theUnsafe");
getUnsafe.setAccessible(true);
UNSAFE = (Unsafe) getUnsafe.get(null);
VALUE_OFFSET = UNSAFE.objectFieldOffset(MySequence.class.getDeclaredField("value"));
}
catch (final Exception e) {
throw new RuntimeException(e);
}
}
public MySequence() {
}
public MySequence(long value) {
this.value = value;
}
public long get() {
return value;
}
public void set(long value) {
this.value = value;
}
public void lazySet(long value) {
UNSAFE.putOrderedLong(this, VALUE_OFFSET, value);
}
}
看完MySequence的实现后你可能会有一个疑问,这不就是一个简易版的AtomicLong吗,为什么disruptor还要自己造一个出来呢?
确实在v1版本中,MySequence类比起juc的AtomicLong只是名字上更加贴合业务场景而已,能被AtomicLong完全的代替。
但Disruptor通过填充多余的字段解决了Sequence中value变量的伪共享问题,MyDisruptor中伪共享的实现放在了后面的版本,所以v1版本在这里提前进行了抽象,目的是方便大家后续的理解。
MySingleProducerSequencer单线程生产者
- disruptor中生产者的发布是分为两个阶段的,一阶段根据next方法获得可用的1个或者多个连续的序列号准备发布(可以理解为获得了存放货品的权限,但还没把货品实际上架),
根据序列号更新队列中下标对应的事件对象;二阶段通过publish方法更新生产者序列号进行实际发布,令新生产的动作可以被消费者感知到。 - 生产者内部维护了消费者的序列号对象。next方法获取可用的序列号时需要避免消费者的序列号落后所要申请的最大序列号一圈。
因为在逻辑上消费者序列对应的位置可以视为队列头,而生产者序列对应的位置可以视为队列尾,当队列尾与队列头之差超过了队列本身长度时,就说明逻辑上队列已满。
此时生产者应该阻塞等待消费者,否则生产者将会覆盖还未被消费者确认消费完成的事件。
/**
* 单线程生产者序列器(仿Disruptor.SingleProducerSequencer)
* 只支持单消费者的简易版本(只有一个consumerSequence)
*
* 因为是单线程序列器,因此在设计上就是线程不安全的
* */
public class MySingleProducerSequencer {
/**
* 生产者序列器所属ringBuffer的大小
* */
private final int ringBufferSize;
/**
* 当前已发布的生产者序列号
* (区别于nextValue)
* */
private final MySequence currentProducerSequence = new MySequence();
/**
* 生产者序列器所属ringBuffer的消费者的序列(后续多消费者版本会改为用数组存储多个消费者序列)
* */
private MySequence consumerSequence;
private final MyWaitStrategy myWaitStrategy;
/**
* 当前已申请的序列(但是是否发布了,要看currentProducerSequence)
* 单线程生产者内部使用,所以就是普通的long,不考虑并发
* */
private long nextValue = -1;
/**
* 当前已缓存的消费者序列
* 单线程生产者内部使用,所以就是普通的long,不考虑并发
* */
private long cachedConsumerSequenceValue = -1;
public MySingleProducerSequencer(int ringBufferSize, MyWaitStrategy myWaitStrategy) {
this.ringBufferSize = ringBufferSize;
this.myWaitStrategy = myWaitStrategy;
}
/**
* 申请可用的1个生产者序列号
* */
public long next(){
return next(1);
}
/**
* 一次性申请可用的n个生产者序列号
* */
public long next(int n){
// 申请的下一个生产者位点
long nextProducerSequence = this.nextValue + n;
// 新申请的位点下,生产者恰好超过消费者一圈的环绕临界点序列
long wrapPoint = nextProducerSequence - this.ringBufferSize;
// 获得当前已缓存的消费者位点
long cachedGatingSequence = this.cachedConsumerSequenceValue;
// 消费者位点cachedValue并不是实时获取的(因为在没有超过环绕点一圈时,生产者是可以放心生产的)
// 每次发布都实时获取反而会触发对消费者sequence强一致的读,迫使消费者线程所在的CPU刷新缓存(而这是不需要的)
if(wrapPoint > cachedGatingSequence){
// 比起disruptor省略了if中的cachedGatingSequence > nextProducerSequence逻辑
// 原因请见:https://github.com/LMAX-Exchange/disruptor/issues/76
// 比起disruptor省略了currentProducerSequence.set(nextProducerSequence);
// 原因请见:https://github.com/LMAX-Exchange/disruptor/issues/291
long minSequence;
// 当生产者发现确实当前已经超过了一圈,则必须去读最新的消费者序列了,看看消费者的消费进度是否推进了
// 这里的consumerSequence.get是对volatile变量的读,是实时的、强一致的读
while(wrapPoint > (minSequence = consumerSequence.get())){
// 如果确实超过了一圈,则生产者无法获取可用的队列空间,循环的间歇性park阻塞
LockSupport.parkNanos(1L);
}
// 满足条件了,则缓存获得最新的消费者序列
// 因为不是实时获取消费者序列,可能cachedValue比上一次的值要大很多
// 这种情况下,待到下一次next申请时就可以不用去强一致的读consumerSequence了
this.cachedConsumerSequenceValue = minSequence;
}
// 记录本次申请后的,已申请的生产者位点
this.nextValue = nextProducerSequence;
return nextProducerSequence;
}
public void publish(long publishIndex){
// 发布时,更新生产者队列
// lazySet,由于消费者可以批量的拉取数据,所以不必每次发布时都volatile的更新,允许消费者晚一点感知到,这样性能会更好
// 设置写屏障
this.currentProducerSequence.lazySet(publishIndex);
// 发布完成后,唤醒可能阻塞等待的消费者线程
this.myWaitStrategy.signalWhenBlocking();
}
public MySequenceBarrier newBarrier(){
return new MySequenceBarrier(this.currentProducerSequence,this.myWaitStrategy);
}
public void setConsumerSequence(MySequence consumerSequence){
this.consumerSequence = consumerSequence;
}
public int getRingBufferSize() {
return ringBufferSize;
}
}
生产者自旋性能隐患
上述MySingleProducerSequencer的实现中,生产者是通过park(1L)自旋来等待消费者的。如果消费者消费速度比较慢,那么生产者线程将长时间的处于自旋状态,严重浪费CPU资源。因此使用next方式获取生产者序列号时,用户必须保证消费者有足够的消费速度。
disruptor和juc下很多并发工具类一样,除了提供内部自动阻塞的next方法外,还提供了非阻塞的tryNext方法。tryNext在消费者速度偏慢无法获得可用的生产序列时直接抛出特定的异常,用户在捕获异常后可以灵活的控制重试的间隔。tryNext原理和next是相同的,限于篇幅在v1版本中就先不实现该方法了。
MyBatchEventProcessor单线程消费者
- disruptor单线程消费者是以一个独立的线程运行的(实现了runnable接口),通过一个主循环不断的监听生产者的生产进度,批量获取已经发布可以访问、消费的事件对象。
- 消费者通过序列屏障MySequenceBarrier感知生产者的生产进度,控制自己的消费序列不超过生产者,避免越界访问。
- 实际的消费逻辑由用户实现MyEventHandler接口的处理器控制
/**
* 单线程消费者(仿Disruptor.BatchEventProcessor)
* */
public class MyBatchEventProcessor<T> implements Runnable{
private final MySequence currentConsumeSequence = new MySequence(-1);
private final MyRingBuffer<T> myRingBuffer;
private final MyEventHandler<T> myEventConsumer;
private final MySequenceBarrier mySequenceBarrier;
public MyBatchEventProcessor(MyRingBuffer<T> myRingBuffer,
MyEventHandler<T> myEventConsumer,
MySequenceBarrier mySequenceBarrier) {
this.myRingBuffer = myRingBuffer;
this.myEventConsumer = myEventConsumer;
this.mySequenceBarrier = mySequenceBarrier;
}
@Override
public void run() {
// 下一个需要消费的下标
long nextConsumerIndex = currentConsumeSequence.get() + 1;
// 消费者线程主循环逻辑,不断的尝试获取事件并进行消费(为了让代码更简单,暂不考虑优雅停止消费者线程的功能)
while(true) {
try {
long availableConsumeIndex = this.mySequenceBarrier.getAvailableConsumeSequence(nextConsumerIndex);
while (nextConsumerIndex <= availableConsumeIndex) {
// 取出可以消费的下标对应的事件,交给eventConsumer消费
T event = myRingBuffer.get(nextConsumerIndex);
this.myEventConsumer.consume(event, nextConsumerIndex, nextConsumerIndex == availableConsumeIndex);
// 批处理,一次主循环消费N个事件(下标加1,获取下一个)
nextConsumerIndex++;
}
// 更新当前消费者的消费的序列(lazySet,不需要生产者实时的强感知刷缓存性能更好,因为生产者自己也不是实时的读消费者序列的)
this.currentConsumeSequence.lazySet(availableConsumeIndex);
LogUtil.logWithThreadName("更新当前消费者的消费的序列:" + availableConsumeIndex);
} catch (final Throwable ex) {
// 发生异常,消费进度依然推进(跳过这一批拉取的数据)(lazySet 原理同上)
this.currentConsumeSequence.lazySet(nextConsumerIndex);
nextConsumerIndex++;
}
}
}
public MySequence getCurrentConsumeSequence() {
return this.currentConsumeSequence;
}
}
/**
* 事件处理器接口
* */
public interface MyEventHandler<T> {
/**
* 消费者消费事件
* @param event 事件对象本身
* @param sequence 事件对象在队列里的序列
* @param endOfBatch 当前事件是否是这一批处理事件中的最后一个
* */
void consume(T event, long sequence, boolean endOfBatch);
}
新生产的队列元素可见性问题
disruptor中对入队元素对象是没有任何要求的,那么disruptor是如何保证生产者对新入队对象的改动对消费者线程是可见的,且不会由于高速缓存的刷新延迟而读到旧值呢?
答案是通过生产者的publish方法中对生产者Sequence对象lazySet操作中设置的写屏障。lazySet设置了一个store-store的屏障禁止了写操作的重排序,保证了publish方法执行前生产者对事件对象更新的写操作一定先于对生产者Sequence的更新。因此当消费者线程volatile强一致的读取到新的序列号时,就一定能正确的读取到序列号对应的事件对象。
MySequenceBarrier序列屏障
- 在v1版本中消费者的消费速度只取决于生产者的生产速度,而由于disruptor还实现了消费者间的依赖(比如A,B,C都消费完序号10,D才能消费序号10),因此引入了SequenceBarrier序列屏障机制。
由于v1版本只支持单消费者,因此v1的序列屏障中只包含了当前生产者的序列号。后续版本支持多消费者后,序列屏障还会维护当前消费者所依赖的消费者序列集合用于实现多消费者间的依赖关系。
/**
* 序列栅栏(仿Disruptor.SequenceBarrier)
* */
public class MySequenceBarrier {
private final MySequence currentProducerSequence;
private final MyWaitStrategy myWaitStrategy;
public MySequenceBarrier(MySequence currentProducerSequence, MyWaitStrategy myWaitStrategy) {
this.currentProducerSequence = currentProducerSequence;
this.myWaitStrategy = myWaitStrategy;
}
/**
* 获得可用的消费者下标
* */
public long getAvailableConsumeSequence(long currentConsumeSequence) throws InterruptedException {
// v1版本只是简单的调用waitFor,等待其返回即可
return this.myWaitStrategy.waitFor(currentConsumeSequence,currentProducerSequence,this);
}
}
MyWaitStrategy等待策略
- 消费者在队列为空,需要阻塞等待生产者生产新的事件。等待的策略可以有很多,比如无限循环的自旋,基于条件变量的阻塞/唤醒等。
为此disruptor抽象出了WaitStrategy接口允许用户自己实现来精细控制等待逻辑,同时也提供了很多种现成的阻塞策略(比如无限自旋的BusySpinWaitStrategy,基于条件变量阻塞/唤醒的BlockingWaitStrategy等)。 - disruptor的等待策略抽象出了两个方法,一个是被消费者调用,用于阻塞等待的方法waitFor(类似jdk Condition的await);另一个是被生产者在publish发布时调用的方法signalWhenBlocking,用于唤醒可能阻塞于waitFor的消费者(类似jdk Condition的signal)
/**
* 消费者等待策略(仿Disruptor.WaitStrategy)
* */
public interface MyWaitStrategy {
/**
* 类似jdk Condition的await,如果不满足条件就会阻塞在该方法内,不返回
* */
long waitFor(long currentConsumeSequence, MySequence currentProducerSequence) throws InterruptedException;
/**
* 类似jdk Condition的signal,唤醒waitFor阻塞在该等待策略对象上的消费者线程
* */
void signalWhenBlocking();
}
阻塞等待策略实现
限于篇幅,v1版本只实现了具有代表性的,基于条件变量阻塞/唤醒的等待策略来展示等待策略具体是如何工作的。
/**
* 阻塞等待策略
* */
public class MyBlockingWaitStrategy implements MyWaitStrategy{
private final Lock lock = new ReentrantLock();
private final Condition processorNotifyCondition = lock.newCondition();
@Override
public long waitFor(long currentConsumeSequence, MySequence currentProducerSequence) throws InterruptedException {
// 强一致的读生产者序列号
if (currentProducerSequence.get() < currentConsumeSequence) {
// 如果ringBuffer的生产者下标小于当前消费者所需的下标,说明目前消费者消费速度大于生产者生产速度
lock.lock();
try {
//
while (currentProducerSequence.get() < currentConsumeSequence) {
// 消费者的消费速度比生产者的生产速度快,阻塞等待
processorNotifyCondition.await();
}
}
finally {
lock.unlock();
}
}
// 跳出了上面的循环,说明生产者序列已经超过了当前所要消费的位点(currentProducerSequence > currentConsumeSequence)
return currentConsumeSequence;
}
@Override
public void signalWhenBlocking() {
lock.lock();
try {
// signal唤醒所有阻塞在条件变量上的消费者线程(后续支持多消费者时,会改为signalAll)
processorNotifyCondition.signal();
}
finally {
lock.unlock();
}
}
}
需要注意的是,并不是所有的等待策略都需要去实现signalWhenBlocking方法。
例如在disruptor内置的基于自旋的等待策略BusySpinWaitStrategy中,消费者线程并没有陷入阻塞态,自己能够及时的发现生产者新发布时序列的变化,所以其signalWhenBlocking是一个空实现。
MyRingBuffer环形队列
- 生产者、消费者通过序列号进行通信,但最终事件消息存放的载体依然是RingBuffer环形队列。v1版本的环形队列由三大核心组件组成:对象数组(elementList)、生产者序列器(mySingleProducerSequencer)、事件工厂(myEventFactory)。
- 初始化时,构造函数中通过MyEventFactory预先将整个队列填满事件对象,后续生产发布时只更新属性,不新增、删减队列中的事件对象。
- 序列号对队列长度ringBufferSize-1求余,可以获得序列号在对象数组中的实际下标(比如队列长度8,序列号25,则序列号25对应的实际下标为25%8=1)。
由于计算机二进制存储的特性,对2的幂次方长度-1进行求余可以优化为位运算。
例如序列号25的二进制值为11001,对7求余可以转换为对00111进行且运算得到后三位001(1),对15求余可以转换为对01111进行且运算得到后4位1001(9),在CPU硬件上作位运算会比普通的除法运算更快(这也是jdk HashMap中容量设置为2次幂的一个重要原因)。
/**
* 环形队列(仿Disruptor.RingBuffer)
* */
public class MyRingBuffer<T> {
private final T[] elementList;
private final MySingleProducerSequencer mySingleProducerSequencer;
private final int ringBufferSize;
private final int mask;
public MyRingBuffer(MySingleProducerSequencer mySingleProducerSequencer, MyEventFactory<T> myEventFactory) {
int bufferSize = mySingleProducerSequencer.getRingBufferSize();
if (Integer.bitCount(bufferSize) != 1) {
// ringBufferSize需要是2的倍数,类似hashMap,求余数时效率更高
throw new IllegalArgumentException("bufferSize must be a power of 2");
}
this.mySingleProducerSequencer = mySingleProducerSequencer;
this.ringBufferSize = bufferSize;
this.elementList = (T[]) new Object[bufferSize];
// 回环掩码
this.mask = ringBufferSize-1;
// 预填充事件对象(后续生产者/消费者都只会更新事件对象,不会发生插入、删除等操作,避免GC)
for(int i=0; i<this.elementList.length; i++){
this.elementList[i] = myEventFactory.newInstance();
}
}
public T get(long sequence){
// 由于ringBuffer的长度是2次幂,mask为2次幂-1,因此可以将求余运算优化为位运算
int index = (int) (sequence & mask);
return elementList[index];
}
public long next(){
return this.mySingleProducerSequencer.next();
}
public long next(int n){
return this.mySingleProducerSequencer.next(n);
}
public void publish(Long index){
this.mySingleProducerSequencer.publish(index);
}
public void setConsumerSequence(MySequence consumerSequence){
this.mySingleProducerSequencer.setConsumerSequence(consumerSequence);
}
public MySequenceBarrier newBarrier() {
return this.mySingleProducerSequencer.newBarrier();
}
public static <E> MyRingBuffer<E> createSingleProducer(MyEventFactory<E> factory, int bufferSize, MyWaitStrategy waitStrategy) {
MySingleProducerSequencer sequencer = new MySingleProducerSequencer(bufferSize, waitStrategy);
return new MyRingBuffer<>(sequencer,factory);
}
}
MyDisruptor使用Demo介绍
Disruptor的各个组件设计的较为独立,需要以特定的方式将其组合起来实现我们的业务。这里展示一个简单的v1版本的MyDisruptor使用demo,希望通过对demo的分析加深读者对disruptor整体的理解。
public class MyRingBufferV1Demo {
public static void main(String[] args) {
// 环形队列容量为16(2的4次方)
int ringBufferSize = 16;
// 创建环形队列
MyRingBuffer<OrderModel> myRingBuffer = MyRingBuffer.createSingleProducer(
new OrderEventProducer(), ringBufferSize, new MyBlockingWaitStrategy());
// 获得ringBuffer的序列屏障(v1版本的序列屏障内只维护生产者的序列)
MySequenceBarrier mySequenceBarrier = myRingBuffer.newBarrier();
// 基于序列屏障,创建消费者
MyBatchEventProcessor<OrderModel> eventProcessor =
new MyBatchEventProcessor<>(myRingBuffer, new OrderEventConsumerDemo(), mySequenceBarrier);
// RingBuffer设置消费者的序列,用于控制生产速度
MySequence consumeSequence = eventProcessor.getCurrentConsumeSequence();
myRingBuffer.setConsumerSequence(consumeSequence);
// 启动消费者线程
new Thread(eventProcessor).start();
// 生产者发布100个事件
for(int i=0; i<100; i++) {
long nextIndex = myRingBuffer.next();
OrderModel orderEvent = myRingBuffer.get(nextIndex);
orderEvent.setMessage("message-"+i);
orderEvent.setPrice(i * 10);
System.out.println("生产者发布事件:" + orderEvent);
myRingBuffer.publish(nextIndex);
}
}
}
/**
* 订单事件对象
* */
public class OrderEventModel {
private String message;
private int price;
public String getMessage() {
return message;
}
public void setMessage(String message) {
this.message = message;
}
public int getPrice() {
return price;
}
public void setPrice(int price) {
this.price = price;
}
}
/**
* 订单事件工厂
* */
public class OrderEventFactoryDemo implements MyEventFactory<OrderEventModel> {
@Override
public OrderEventModel newInstance() {
return new OrderEventModel();
}
}
/**
* 订单事件处理器
* */
public class OrderEventHandlerDemo implements MyEventHandler<OrderEventModel> {
@Override
public void consume(OrderEventModel event, long sequence, boolean endOfBatch) {
System.out.println("消费者消费事件" + event + " sequence=" + sequence + " endOfBatch=" + endOfBatch);
}
}
总结
- 作为disruptor学习系列博客的第一篇,介绍了lmax-disruptor的整体架构和主要设计思想,同时也对自己实现的MyDisruptor v1版本进行了详细的分析。
- MyDisruptor的v1版本所支持的功能比起disruptor要少很多,相比disruptor在保持整体架构不变的同时裁剪掉了很多当前不必要的逻辑,保证低复杂度。
阅读MyDisruptor源码时可以找到disruptor对应组件的源码一起对照着看,从相对复杂的disruptor源码中找到其核心逻辑,加深理解。 - 后续会按照文章开头的计划逐步迭代,最终实现一个完整的disruptor队列,敬请期待。
disruptor无论在整体设计还是最终代码实现上都有很多值得反复琢磨和学习的细节,希望能帮助到对disruptor感兴趣的小伙伴。
本篇博客的完整代码在我的github上:https://github.com/1399852153/MyDisruptor 分支:feature/lab1

 浙公网安备 33010602011771号
浙公网安备 33010602011771号