

面向对象与泛型编程
OOP是将data与method封装在一个class中,STL是将container容器与algorithms算法分开,容器和算法可以“闭门造车,互不干扰”,他们两个的交流通过迭代器完成。
分配器
为容器提供内存。在vc系列的编译器中使用的分配器是allocator,这些编译器中分配器的关键部分源码如下
template <typename T> class allocator{ ..... pointer allocate(需要的空间); //归根结底是调用malloc() void deallocate(指针,要归还的空间大小);//调用free(); ... } //根据源码举个例子 int *p = allocator<int>().allocate(10,(int*)0); allocator<int>.deallocate(p,10); //需要指明归还的大小
主要就是对malloc()和free()进行包装再包装,不光浪费空间还影响效率。每malloc一次就会有额外的开销,其中就有cookie来记录每次malloc的大小,由free()来找到cookie,精准释放这块内存。
而G2.9所使用的是分配器是alloc,由于容器中的元素大小都是一样的,所以没有必要记录每个元素的大小,也就不需要这么多的额外开销。G2.9的分配器有16条链表,每一个链表负责某一种特定大小的区块,比如第0号链表负责8字节大小的区块,第1号链表负责16字节大小的区块,第15号负责128字节大小的区块。容器中元素的大小都会被调整成8的倍数,由16条链表中的某一条负责,比如,容器中的元素大小为15字节,就会调整为16字节,如果这1号链表没有区块,就需要向操作系统一次mallco()要多个16字节的内存(16*20字节),把这么多内存切成20个区块,每个区块16字节,给出去一块,剩余19个区块连接起来。这些区块不需要每一个都有cookie,因此减少了浪费。
迭代器(iterators)的设计原则
迭代器是算法和容器之间的桥梁,算法想要操作容器就需要迭代器提供的“指针”,通过这个“指针”来处理对应的元素。算法需要知道迭代器的特性(以下三种),由此来选择一个更高效的方式。
1、iteratiors的5个属性
iteratior_category()是指"指针"的移动性质,有的容器只允许"指针"做++操作,比如list,有的容器允许"指针"+n操作,跳跃访问比如vector;
vaule_type:迭代器所指向的元素是什么类型的;
difference_type:两个迭代器之间的距离用什么类型来表现;
reference
pointer
源码展示算法和容器之间的问与答,算法想要知道迭代器的几个性质。
//算法的提问,想要知道迭代器的五种特性,I表示iteratior template<typename I> inline void algorithm(I frist,I last) { ... I::iterator_category; I::pointer; I::reference; I::value_type; I::deference_type; ... } //某种容器(list)的迭代器的回答 template<class T,class Ref,class Ptr> struct __list_iterator { ... typedef bidirectional_iterator_tag iterator_category; //告诉算法list容器的iterator_category是可以双向移动 typedef T value_type; //告诉迭代器所指的元素是什么类型 typedef Ptr pointer; typedef Ref reference; typedef ptrdiff_t difference_type; //告诉两个迭代器之间距离是什么类型 ... }
list容器的迭代器是用class封装好的,但是如果是自然指针,算法怎么知道它的几个特性?指针怎么回答?这时候就需要Iterator Traits(萃取机)。当传递给traits是class封装好迭代器,算法问class来回答,就像上面一样。如果是自然指针就用另外一种方式来得到五种特性。
template<typename I,...> //I是某个迭代器,可能是封装好的,也可能是自然指针 void algorithm() { typename iterayor_traits<I>::value_type; //算法问traits这iterator的value_type是什么 } //如果class iterator 进入下面 template <class I> struct iterator_traits{ typedef typename I::value_type value_type; } //如果是自然指针 template <class T> struct iterator_traits<T*> { typedef T value_type; //T就是value_type }
总的来说traits会分辨出class_iterator和 non class_iterator,让算法知道他想知道的特性。
list
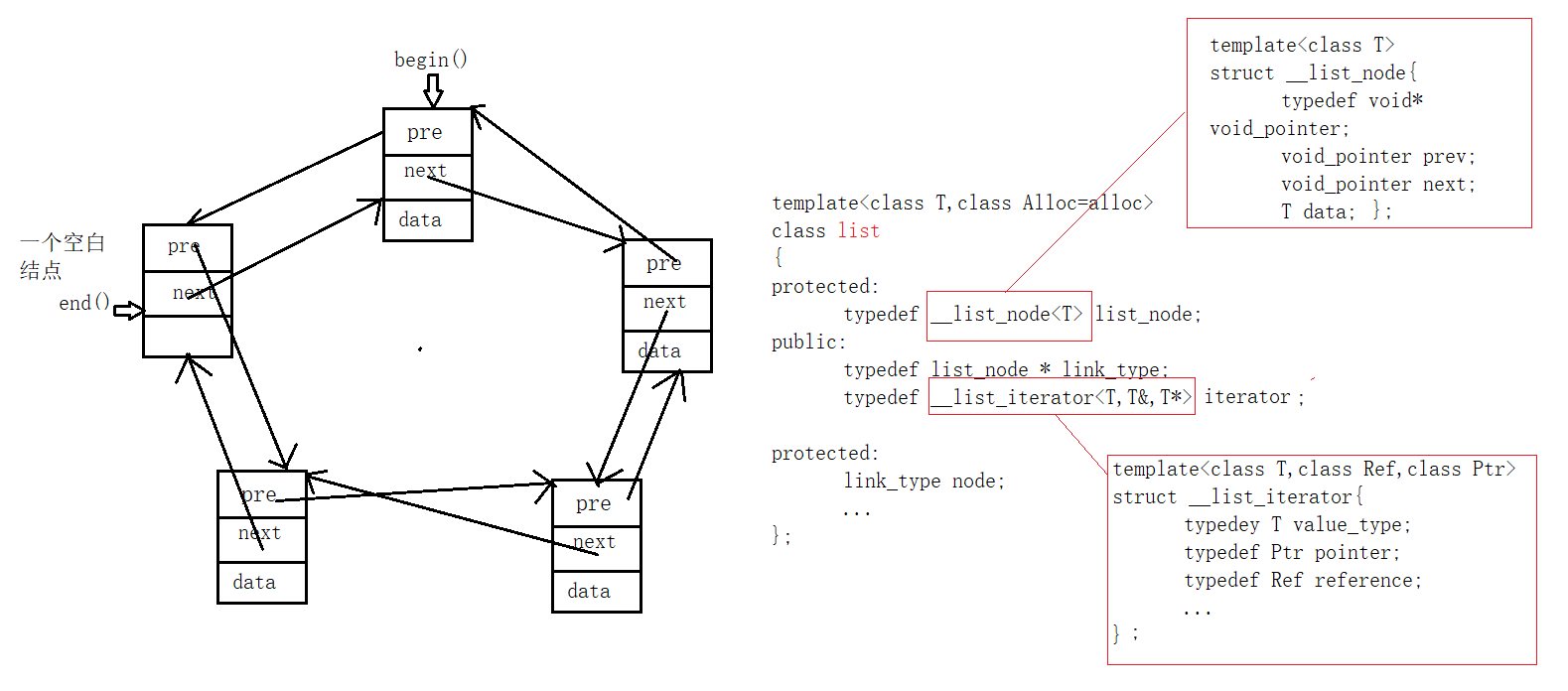
链表是一个非连续空间,所以list的iterator不能是一个自然指针,但是我们希望list的iterator能够模拟指针的动作,比如++操作,iterator能够找到next指向的结点,所以iterator必须得是一个class,才能完成复杂的动作,里面必然有大量的操作符重载。
reference operator*() const //iterator的解引用 { return (*node).data; } pointer operator->() const{ return &(operator*());} //返回结点data域的地址,通过->可以访问data域中的成员 self &operator++() //前置++ { node = (link_type)((*node).next); return *this; } self operator++(int) //后置++ { self tmp = *this; ++*this; return temp; }
总的来说list的iterator里面有两大部分,一部分是typedef,另外一部分是操作符重载。
vector容器源码分析
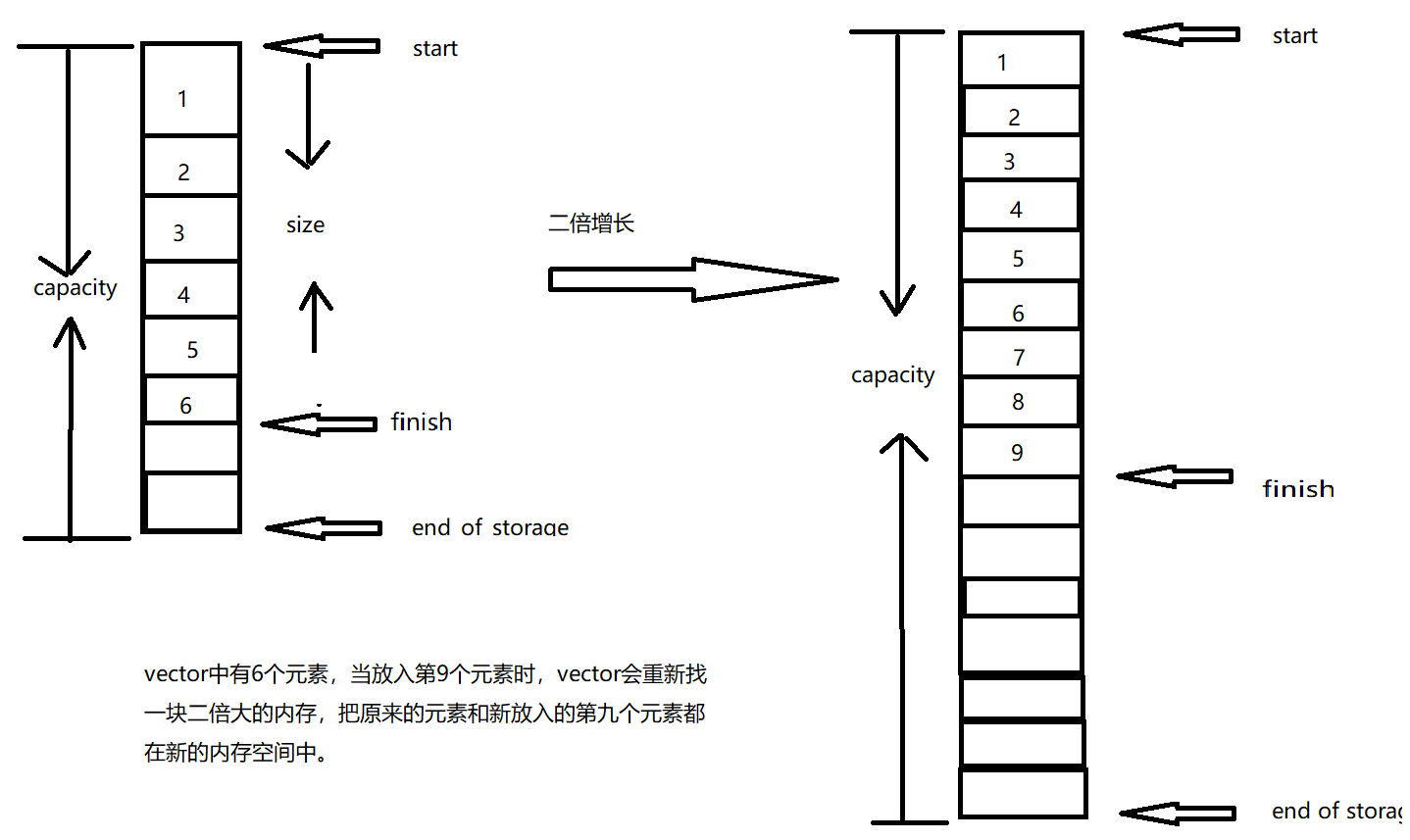
template <class T,class Alloc= alloc> class vector{ public: typedef T value_type; typedef value_type * iterator; typedef value_type& reference; typedef size_t size_type; protected: iterator start; iterator finish; iterator end_of_storage; public: iterator begin() { return start; } iterator end() { return finish; } size_type size() const { return size_type(end()-begin()); } size_type capacity() const { return size_type(end_of_storage-begin()); } bool empty() const { return begin()==end(); } reference operator[] (size_type n) { return *(begin()+n); } reference front() { return *begin(); } reference back() { return *(end()-1); } };
如上图所示,当我们要插入第九个元素时,vector内部是如何做到二倍增长,以下是源码实现
void push_back(const T &x) { if(finish!=end_of_storage) //还有空闲空间 { construct(finish,x);//全局函数,在尾部插入 ++finish; } else insert_aux(end(),x); //没有空闲空间,需要扩充 } template <class T,class Alloc> void vector<T,Alloc>::insert_aux(iterator position,const T&x) { if(...) { ... } else { //扩充 const size_type old_size = size(); //保存原有的大小 const size_type len = old_size!=0?2*old_size:1;//初始size为0,分配一个元素大小 //如果不为0,分配两倍 iterator new_start = data_allocator::allocate(len); //开始分配 iterator new_finish=new_start; //重新分配了16个元素大小的空间,new_start和new_finish都指向了空间起始位置 try{ //将原来的内容拷贝到新的空间中,new_finish指向最后一个元素的下一个位置 new_finish=uninitialized_copy(start,position,new_start); construct(new_finish,x);//将第九个元素插入 ++new_finish; //拷贝安插点后的原内容,会被insert(pos,x)调用 //比如在第三位插入新元素,把前两个元素移动到新地方,在两个元素后插入新元素,再把原来内存中第三个到最后一个元素拷贝到新内存中 new_finish=uninitialized_copy(postion,finish,new_finish) } catch{ ... } //释放原来的空间 destroy(begin(),end()) deallocate(); //调整 start=new_start; finish=new_finish; end_of_storage=new_start+len; } }
vector的每次扩充会大量调用拷贝和析构
vector iterator是一个指针,换句话说指针可以充当vector的迭代器,算法通过traits得到iterator的几个特性。
template<class T> struct iterator_traits<T*> { typedef random_access_iterator_tag iterator_category; //特性1 typedef T valuetype;//特性2 typedef T* pointer; //特性3 typedef T& reference; //特性4 typedef ptrdifft differencetype; //特性5 }
deque
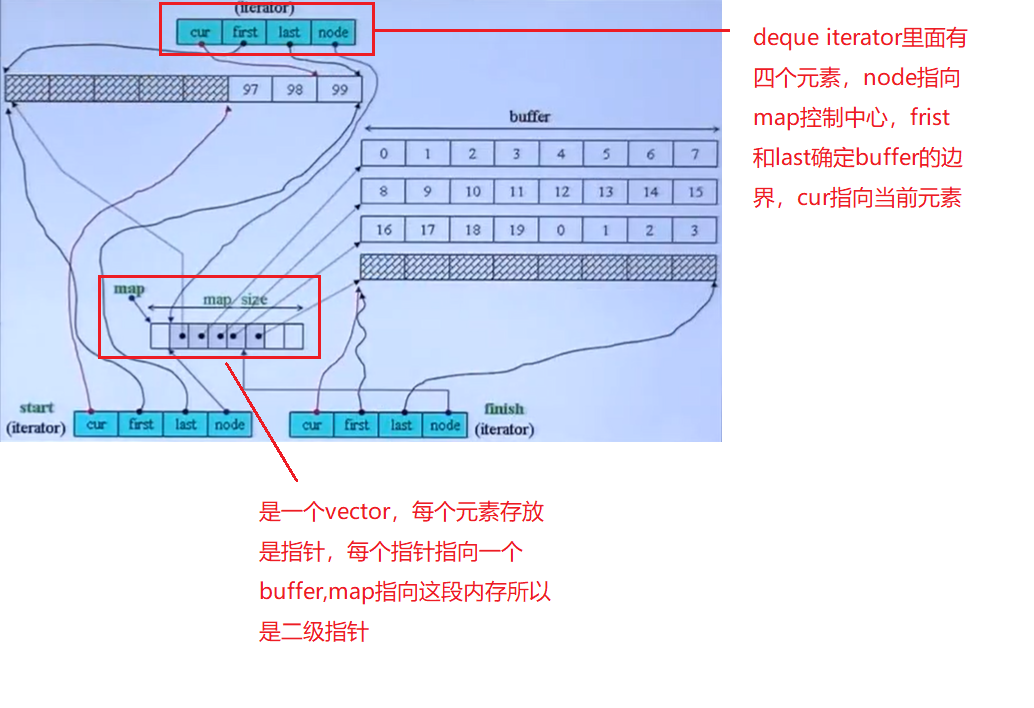
deque是一个分段连续的容器,连续是假象,分段是事实,迭代器在移动的时候要维持连续的假象,当迭代器走到边界无论是first还是last,他都要通过node回到控制中心,跳到下一个buffer中去。
//bufsize为每个buffer容纳的元素个数,如果bufsiz指定为5,说明每个buffer长度为5,如果是0,要知道一个元素是多大
,如果不超过512B,就用512/elemsize。例如:元素类型为int,一个buffer长度为512/4=103 template<class T,class Alloc=alloc,size_t BufSiz=0> class deque { public: typedef T value_type; typedef __deque_iterator<T,T&,T*,BufSize> iterator; protected: typedef pointer* map_pointer; //T** iterator start; iterator finish; map_pointer map; size_type map_size; public: ... }
//deque迭代器源代码 template<class T,class Ref,class Ptf,size_t BufSiz> Struct __deque_iterator{ typedef random_access_iterator_tag iterator_category; //特性1,制造出连续的假象,可以随机访问 typedef T valuetype;//特性2 typedef Ptr pointer; //特性3 typedef Ref reference; //特性4 typedef size_t sizetype typedef ptrdifft differencetype; //特性5 typedef T** map_pointer; typedef __deque_iterator self; T* cur; T* first; T* last; map_pointer node; //二级指针 ... }
我们在可以使用insert(pos,elem);在某个位置插入一个元素。如果pos指定插入为最前面的位置,insert函数内部会调用push_front(elem)把元素插到最前方;如果pos为最后位置会调用push_back(elem)把元素插入末端。以上两种情况是刚好在两端插入元素,如果在中间,deque会判断出要插入的位置是离头部近还是离尾部近,假设有一百个元素,我们要在第5个位置插入元素,deque就会把前面4个元素元素向前推,而不是把后面的96个元素向后推,这就是deque的高明之处。
//insert函数实现 iterator insert(iterator position,const value_type &x) if(position.cur==start.cur) //判断插入的元素是否在最前端 { push_front(x); //调用push_front() return start; } else if(position.cur==finish.cur) //是否在最末端 { push_back(x); //调用push_back() iterator tmp = finish; --tmp; return tmp; } else //在中间插入 { return insert_aux(positon,x); //判断插入元素离哪一端近 }
deque怎么模拟连续空间,迭代器++和--是怎么跳到下一个缓冲区?
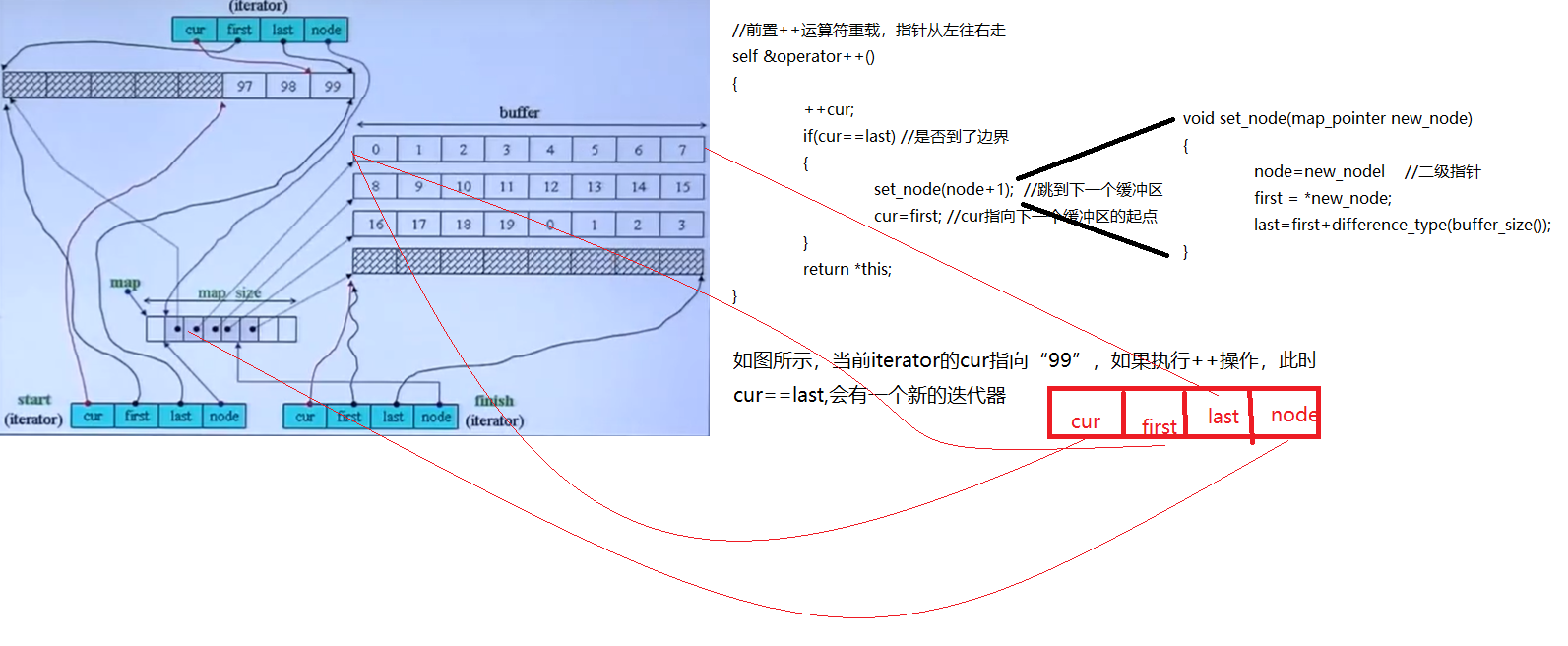
那么--操作也和++操作类似,指针从右到左移动,先要判断是否到了边界(cur==frist),如果到了边界,就会回到控制中心,找到前一个缓冲区的位置,把迭代器中的cur修改为新buffer的last,frist和last指向新buffer的两端,node指向控制中心原来元素的上一个位置。
deque的如此设计让用户感觉不到他的分段。如果用户需要一次跳跃n个位置,deque的设计思想:不管是往前跳跃还是往后跳跃,deque内部都会判断是否会跨越缓冲区,跨越几个缓冲区,然后退回控制中心,找到目的缓冲区,再决定还剩几个元素要走。
self& operator+=(difference_type n) { //假设是在连续空间,+n操作目的元素编号 difference_type offset=n+(cur-frist); //目标位置在同一个buffer中 if(offset>=0&&offset<difference_type(buffer_size())) cur+=n; else //目标位置不在同一个buffer中 { //计算需要跨越几个缓冲区 difference_type node_offset=offset>0?offset/difference_type(buffer_size()) :-difference_type((-offset-1)/buffer_size())-1; set_node(node+node_offset) //回到控制中心切换到正确的buffer //在本buffer中还需要跳跃几个元素 cur = first+(offset-node_offset*difference_type(buffer_size())); } return *this; }
stack与queue
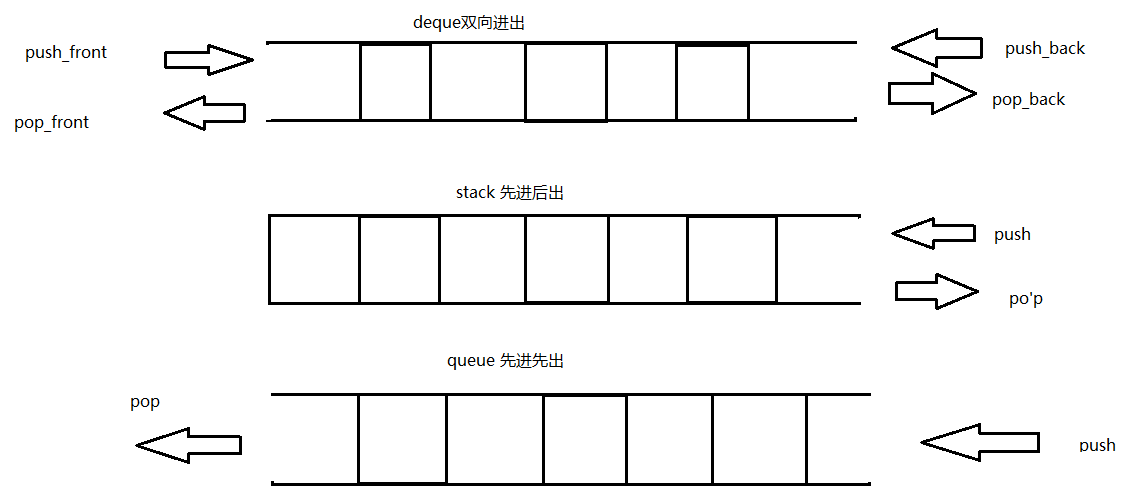
从图中可以看出,queue和stack是包含于deque,只需要关闭deque个几个功能就可以创建出queue和stack,所以不需要重写queue和stact内部功能,只需让他们内含一个deque,然后封掉某些功能。
//queue源码,内部有一个deque,调用deque的功能 template<class T,class Sequence=deque<T>> class queue { public: ... protected: Sequence c; //底层容器 public: bool empty() const{return c.empty();} size_type size() const {return c.size();} reference front(){return c.front();} const_reference front() const {return c.front();} reference back(){return c.back();} const_reference back(){return c.back();} void push(const value_type&x){c.push_back(x);} void pop(){c.pop_front();} }
可以看出queue和stack并不是严格意义上的容器,更像是一个适配器,他把别的容器改装一下成为自己。
template<class T,class Sequence=deque<T>> class stack { public: ... protected: Sequence c; //底层容器 public: bool empty() const{return c.empty();} size_type size() const {return c.size();} reference top(){return c.back();} const_reference top() const{return c.back();} void push(const value_type&x){c.push_back(x);} void pop(){c.pop_front();} }
除了可以用deque作为底层结构,list容器也可以
void test01() { stack<int, list<int>> s; //list为底层结构 for (size_t i = 0; i < 10; i++) { s.push(i); } cout << "stack的size=" << s.size() << endl; cout << "top=" << s.top() << endl; s.pop(); cout << "stack的size=" << s.size() << endl; cout << "top=" << s.top() << endl; }
void test02() { queue<int, list<int>>q; //使用list作为queue的底层结构 for (size_t i = 0; i < 10; i++) { q.push(i); } cout << "size=" << q.size() << endl; cout << "front=" << q.front() << endl; q.pop(); cout << "size=" << q.size() << endl; cout << "front=" << q.front() << endl; cout << "back=" << q.back() << endl; }
另外stack可以用vector作为底层结构,queue不能。因为在queue想要出队pop(),会调用pop_front()函数,而vector没有这个功能。
stack和queue不能遍历,不提给迭代器,如果可以访问任意一个元素,就破坏了先进后出和先进先出的行为模式。
set/mutiset
set/multiset和map/multimap底层都是红黑树结构。
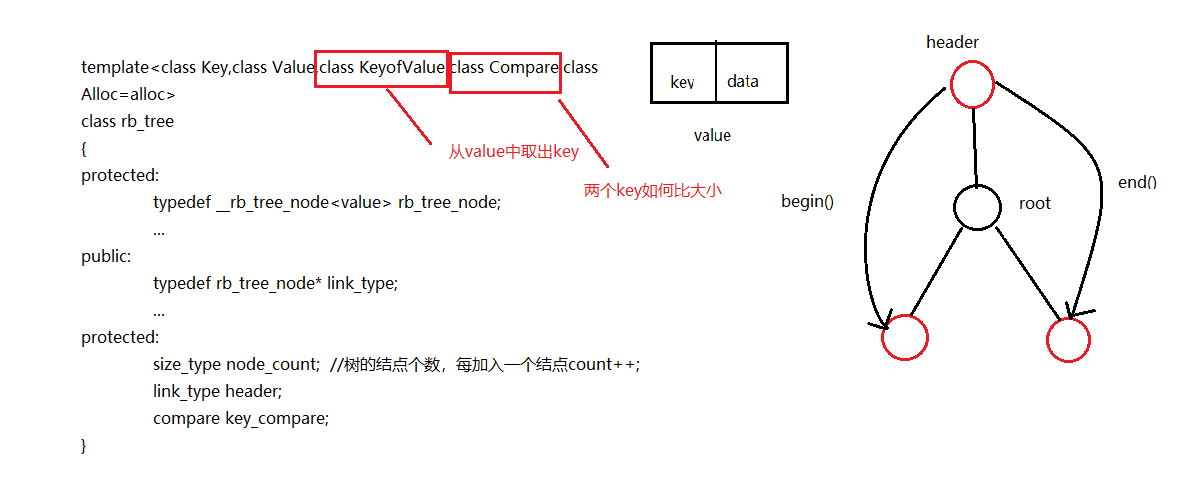
set/multiset是rb_tree为底层结构,因此有自动排序的特性,排序的依据是key,而set/multiset的元素的value和key合一:value就是key。无法使用set/multiset的iterator来改变元素值,iterator是其底部的RB tree的const iterator,就是为了禁止用户对元素赋值。
set容器的key必须是独一无二,他所调用的insert()方法用的是rb_tree的insert_unique()。
multiset容器的key可以重复,是因为他调用的insert()是rb_tree的insert_equal()。
set源代码

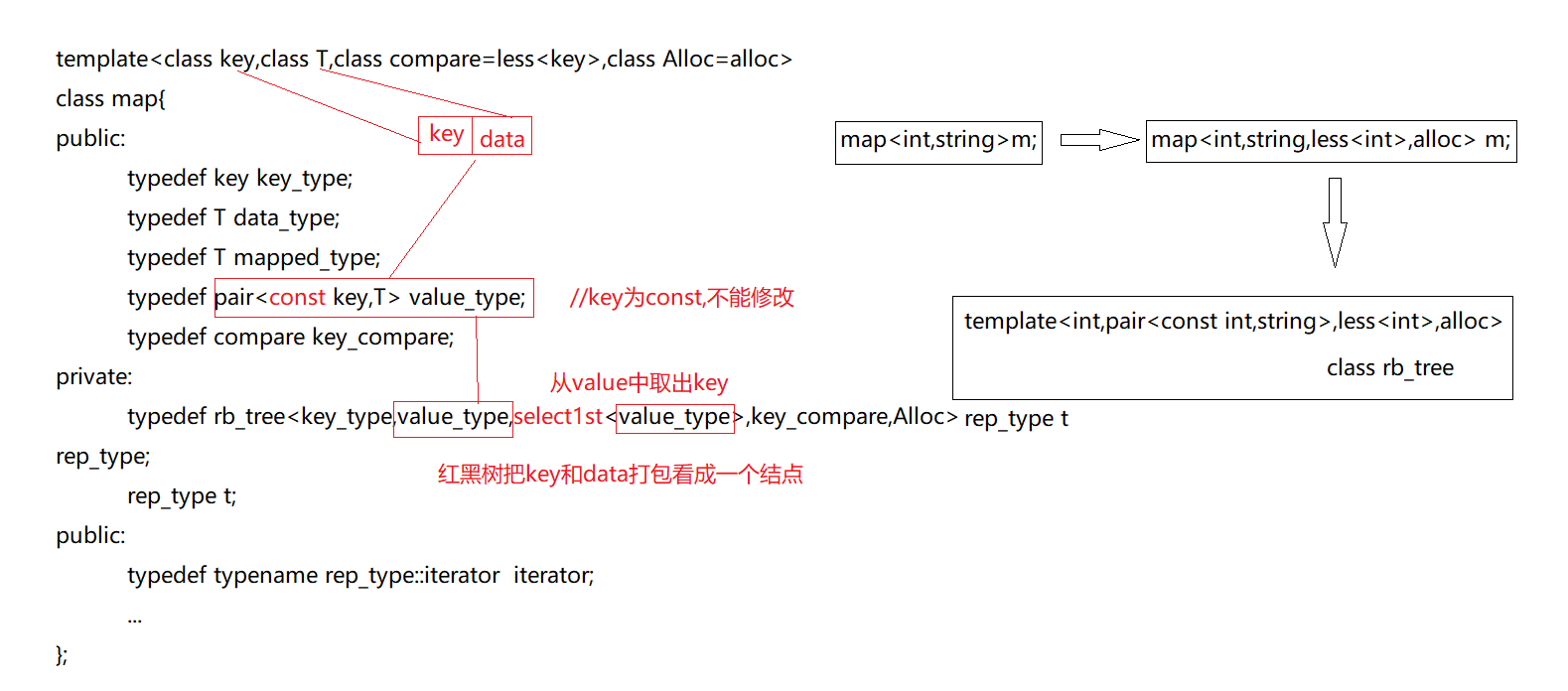
map/multimap
map/mutimap是以rb_tree为底层结构,因此有自动排序的特性,排序的依据是key。
我们无法通过它的迭代器来改变key,rb_tree把key_type设定为const,但是可以通过key来修改后面的data(key和data组成了value),这一点与set/mutiset不同。set是通过把iterator设为const iterator来禁止修改key,而map是在打包过程中把key设置为const,而包里的data可以修改。
map容器的key必须是独一无二,他所调用的insert()方法用的是rb_tree的insert_unique()。
multimap容器的key可以重复,是因为他调用的insert()是rb_tree的insert_equal()。
map源码
map与multimap关于[]的使用差别
map<int, string>m1; m1.insert(make_pair(1,"liming")); m1[2] = string("jenny");//map容器在insert时并没有报错 multimap<int, string>m2; m2.insert(make_pair(2, "jenny")); m2[1] = string("zhang"); //error:没有与这些操作数匹配的[]运算符
由此可见operator[]是map容器所特有的。他要完成:返回与key相对应的data,如果指定的key不存在的话(在上面例子中,m1没有2这个key),会创建出这个key,放在容器中。
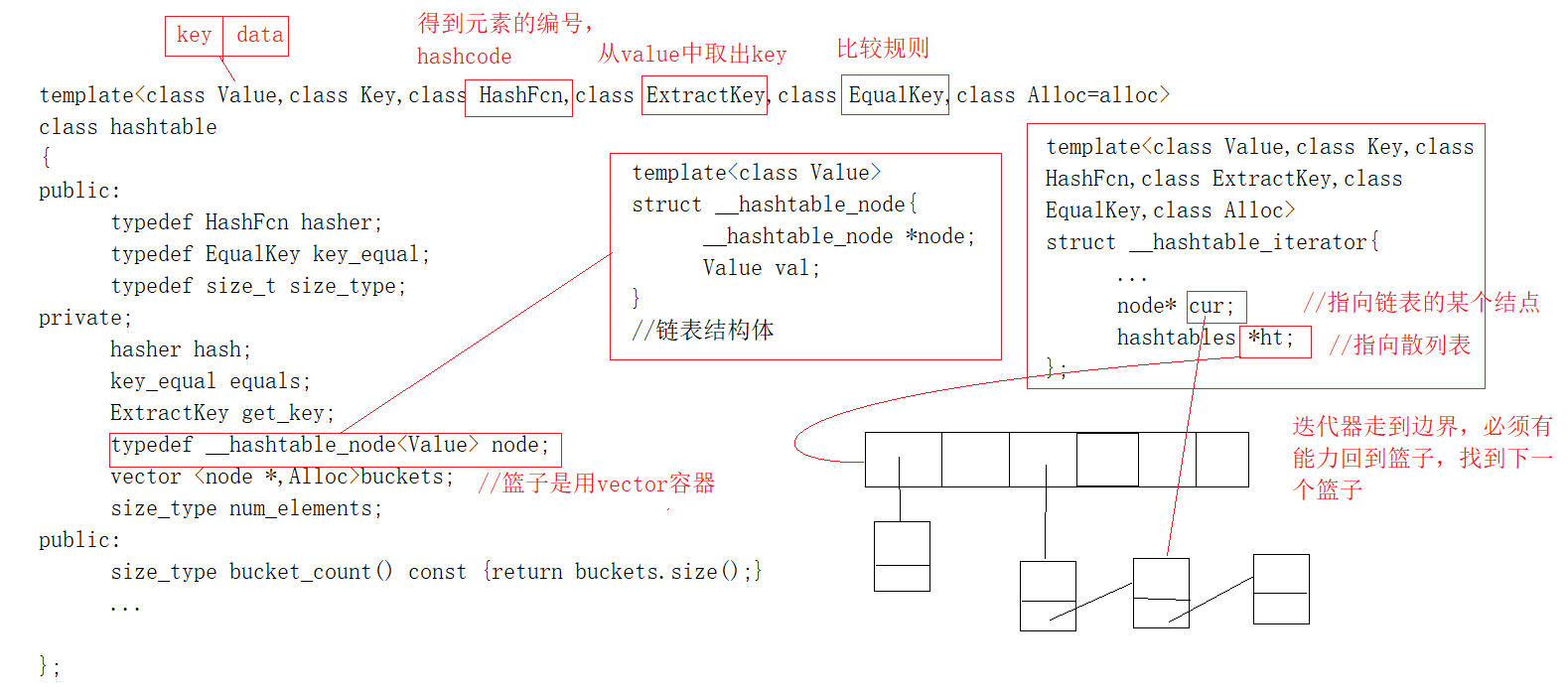
unordered set/multiset与unordered map/multimap
这个两个容器与上面两个的最大差别是底层的数据结构不同,unordered系列容器使用的是hash table(散列表),散列表理想状态下查找的时间复杂度能达到O(1),并使用拉链法来处理哈希碰撞,当容器的填装因子过大,也就是说元素的个数大于篮子的个数时,容器会把原来散列表打散再扩大重新散列,防止篮子后面的链表结点过长,影响查找效率。
unordered_set<int> set; for (int i = 0; i < 10; i++) { set.insert(rand() % 30); } cout << "set.size: "<<set.size() << endl;//容器的大小 cout << "set.bucket_count:"<<set.bucket_count()<< endl;//篮子的个数 for (size_t i = 0; i < set.bucket_count(); i++) { cout << "bucket: 第" << i << "个篮子有" << set.bucket_size(i)<<"个元素" << endl; }
set.size: 8 set.bucket_count:8 bucket: 第0个篮子有1个元素 bucket: 第1个篮子有1个元素 bucket: 第2个篮子有0个元素 bucket: 第3个篮子有2个元素 bucket: 第4个篮子有1个元素 bucket: 第5个篮子有0个元素 bucket: 第6个篮子有1个元素 bucket: 第7个篮子有2个元素 请按任意键继续. . .
这时候把元素曾多
set.size: 14 //容器里的元素 set.bucket_count:64 //篮子个数
hash_table容器分析


 浙公网安备 33010602011771号
浙公网安备 33010602011771号