OmniParser
配置omniparser
- 把omniparser项目拉下来;
- 官方推荐安装Miniconda作为依赖安装环境,需要预装python3.12版本的;注意安装时选择安装到用户路径下,以及添加环境变量。
- 打开Anconda Prompt,敲入
conda create -n "omni" python==3.12创建python3.12环境- 遇到网络访问问题时注意把安装文件位置下的
.condarc配置文件用国内源代替; - 遇见ssl verify问题可以配置成:
conda config --set ssl_verify false; - 若安装时没有自动添加环境变量,可以手动把miniconda添加到环境变量;
- conda 创建好之后,打开conda prompt,先输入
:d,使之跨盘符,然后输入cd加项目路径进入到项目; - 输入
conda activate omni; - 安装
pip install -r requirements.txt;
- 遇到网络访问问题时注意把安装文件位置下的
- 下载模型文件方法A:
- 官方下载文件
microsoft/OmniParser-v2.0,官方地址https://huggingface.co,如果进不去,地址选择https://hf-mirror.com/microsoft/OmniParser-v2.0/tree/main - 找到
microsoft/OmniParser-v2.0 - 进去之后点击
icon_caption和icon_detect,分别下载里面的文件
- 下载的文件如下:
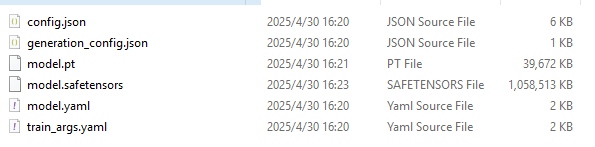
- 项目目录下新建两个目录:
mkdir -p weights/icon_detectmkdir -p weights/icon_caption_florence。
mkdir -p weights/icon_detect下面放:model.pt,model.yaml,train_args.yaml;
mkdir -p weights/icon_caption_florence下面放:config.json,generation_config.json,model.safetensors;
- 官方下载文件
- 下载模型文件方法B:
- 也可以在
OmniParser-master目录下新建一个py文件用来下载权重,如下,下载完成后依旧需要把文件名icon_caption改成icon_caption_florence:
- 也可以在
from huggingface_hub import snapshot_download
#下载整个仓库
model_path = snapshot_download(
repo_id="microsoft/OmniParser-v2.0",
local_dir="./weights",
repo_type="model"
)
print(f"model downlod to:{model_path}")
-
解决huggfacing连接问题方法A:
- 更改环境变量,可以避免改动py文件中的内容:
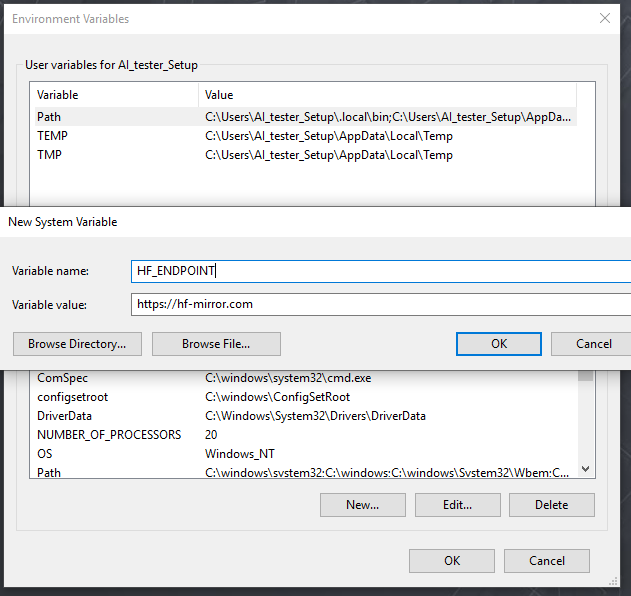
- 更改环境变量,可以避免改动py文件中的内容:
-
解决huggfacing连接问题方法B:
- 如果运行
python gradio_demo.py出错,那是因为访问不到https://huggingface.co的原因,打开constants.py文件,把里面的https://huggingface.co改成https://hf-mirror.com,另外在constants.py的最前面加上os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'。

- constants.py文件的位置如下:
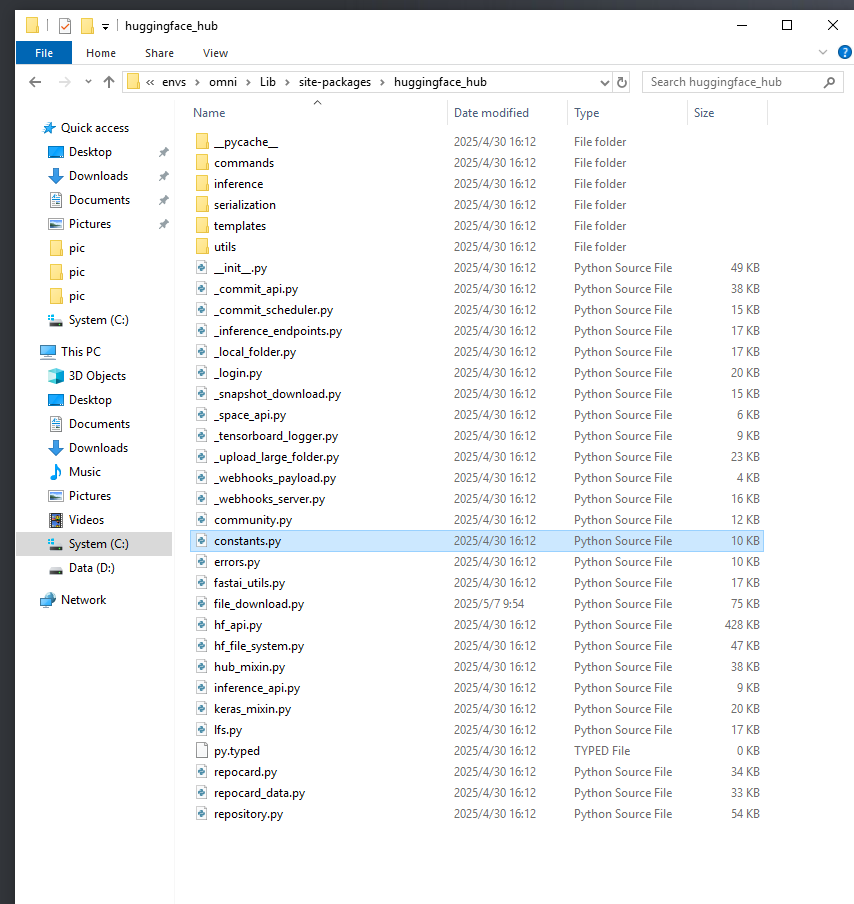
- 为了保险起见,同时替换了hub中的链接:
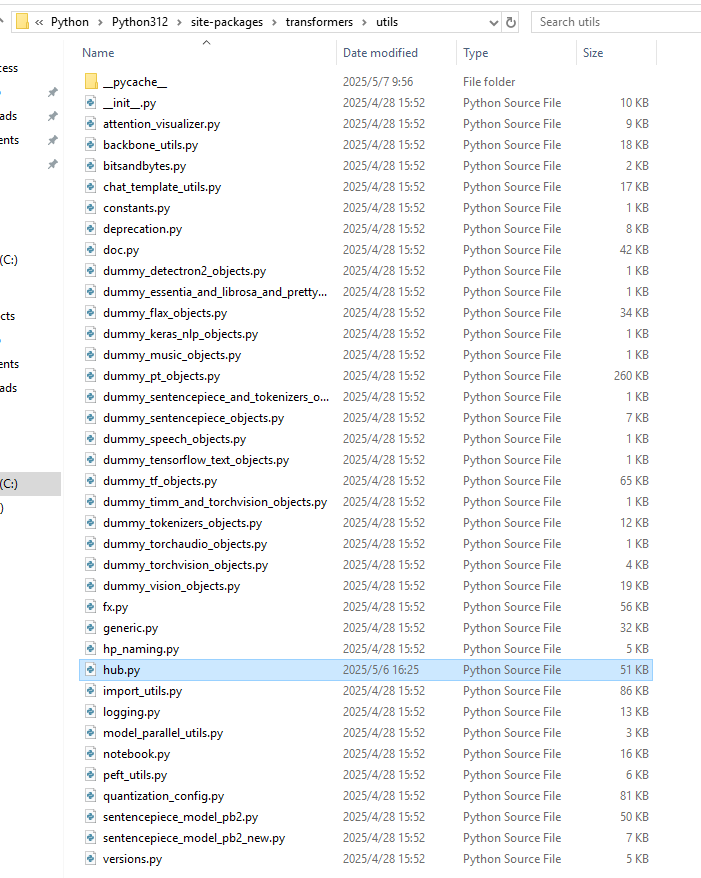
- 如果运行
-
运行demo:
python gradio_demo.py配置web工具:- 下载frpc_windows_amd64.exe,并重命名为frpc_windows_amd64_v0.3;进不去提示给的链接,可以在github上找frpc_windows_amd64_v0.2。
- 移动至目标文件夹
C:\Users\AI_tester_Setup\AppData\Roaming\Python\Python312\site-packages\gradio;

- 重新输入
http://0.0.0.0:7861/或者http://localhost:7861/;
-
运行时出现错误
500 Server Error TypeError: argument of type 'bool' is not iterable:- 执行
pip install --upgrade gradio升级解决。
- 执行
-
简单测试
python gradio_demo.py:
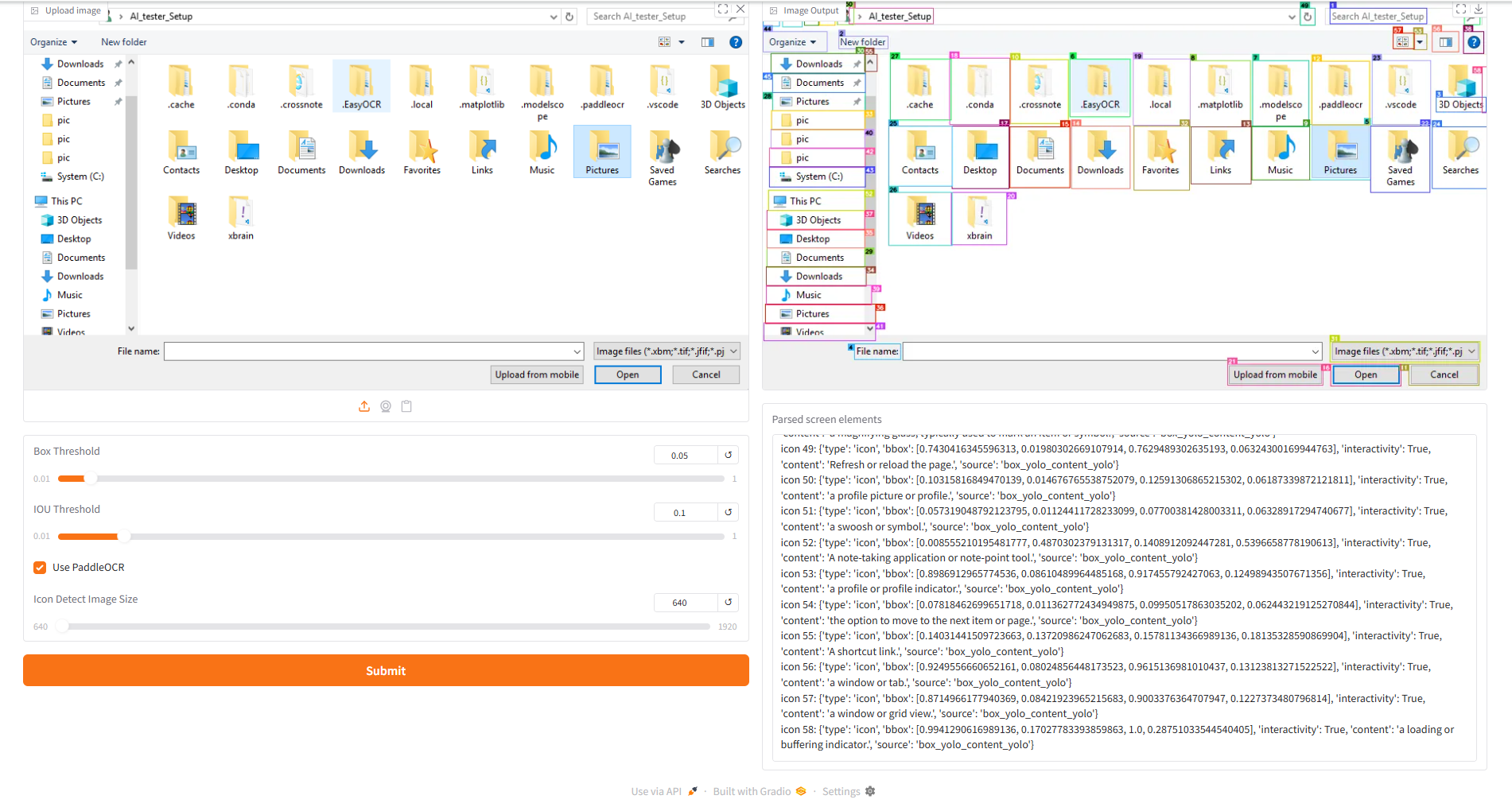
注意:omniparser只能实现屏幕元素坐标的解析,自动化操作还需要配合其他工具。
omniparser v2.0 + pyautogui实现自动化点击
- 基于
gradio_demo.py + pyautoGUI测试使用的代码:- 得到omniparser捕获到的坐标,把它替换到
示例 bbox (来自您提供的数据),并启动该python文件,即可自动化操作(双击/点击/单击事件需要写好代码)。
- 得到omniparser捕获到的坐标,把它替换到
# pip install pyautogui
from time import sleep
import pyautogui
import time
def bbox_to_coords(bbox, screen_width, screen_height):
"""将 bbox 坐标转换为屏幕坐标."""
xmin, ymin, xmax, ymax = bbox
x_center = int((xmin + xmax) / 2 * screen_width)
y_center = int((ymin + ymax) / 2 * screen_height)
return x_center, y_center
def click_bbox(bbox):
"""点击指定的 bbox."""
screen_width, screen_height = pyautogui.size()
x, y = bbox_to_coords(bbox, screen_width, screen_height)
# 移动鼠标到指定位置
pyautogui.moveTo(x, y, duration=0.2) # duration 是移动时间,单位为秒
# 点击鼠标
pyautogui.click()
print(f"点击了坐标: x={x}, y={y}")
if __name__ == '__main__':
sleep(5)
# 示例 bbox (来自您提供的数据)
bbox = [0.36728453636169434, 0.9408491849899292, 0.39909330010414124, 0.9875121712684631] # chrome
# 点击 bbox
click_bbox(bbox)
omniTool - omniparserserver
- 进入服务:
cd OmniParser/omnitool/omniparserserver - 启动服务:
python -m omniparserserver
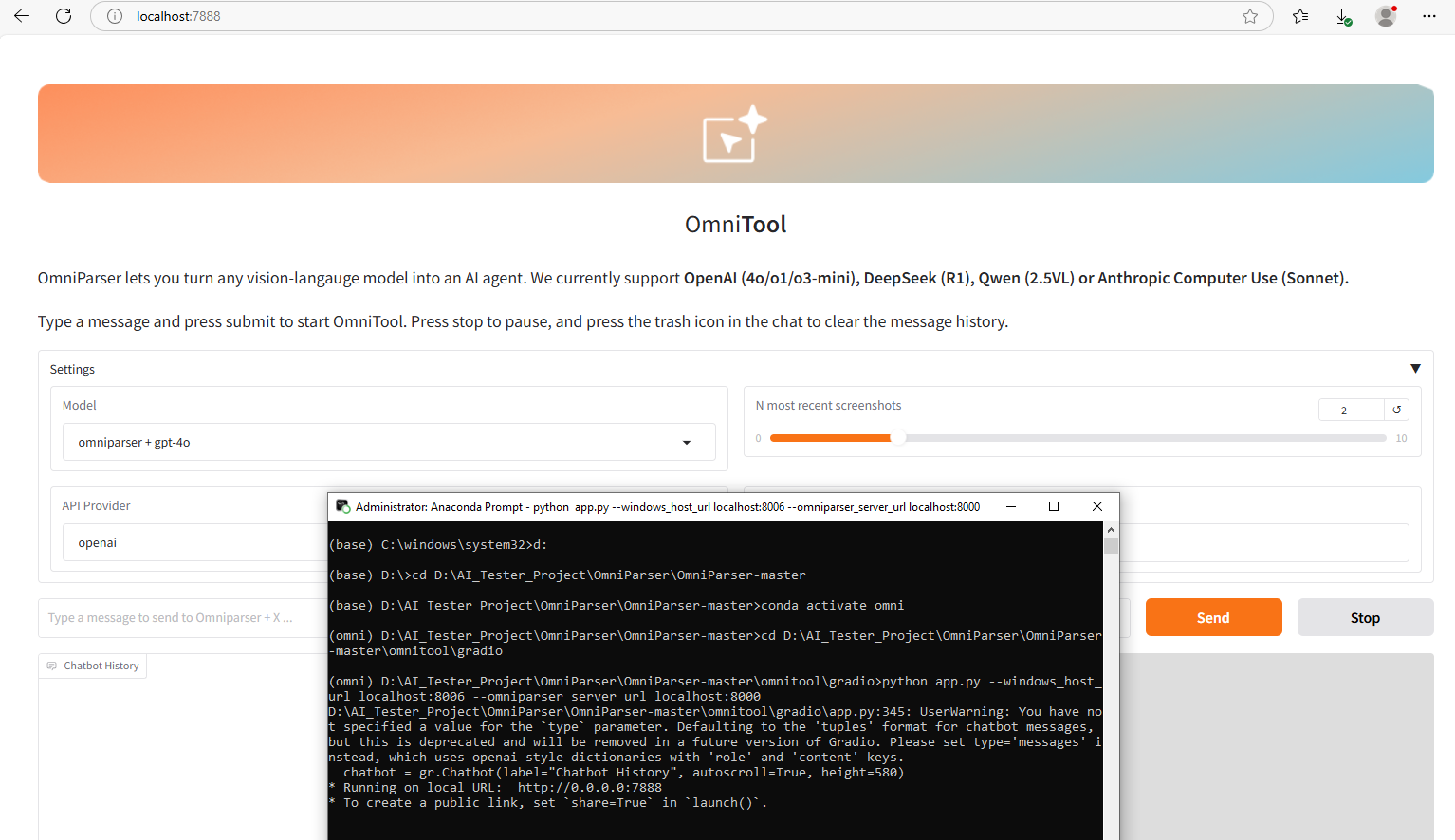
omniTool - gradio
- 进入界面:
cd OmniParser/omnitool/gradio - 激活环境:
conda activate omni; - 启动服务:
python app.py --windows_host_url localhost:8006 --omniparser_server_url localhost:8000; - 打开终端显示的url,设置API Key即可使用
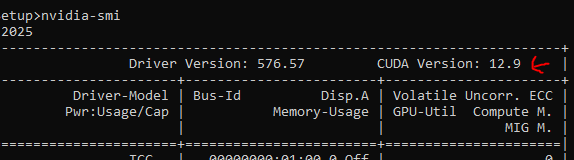
GPU启动(nvidia) - 安装显卡驱动及cuda
- 需要根据显卡型号安装具体驱动,根据自己显卡型号官网查找驱动。
- 驱动装好后,
nvidia-smi获得CPU和GPU使用情况。
- 检查cuda驱动安装情况,cuda下载,选择自己显卡支持的范围内。不要选太高的版本,注意和pytorch支持的版本匹配。具体安装教程:cuda下载安装方法参考。
- 使用
nvcc -V查看cuda安装情况。 - 安装完成cuda之后还需要安装cuDNN
建议通过conda环境单独安装PyTorch:conda install pytorch torchvision torchaudio -c pytorch;需要去pytorch官网根据自己电脑系统选择不同的下载版本。- 更新后若出现下报错:
Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.

- 解决方案:
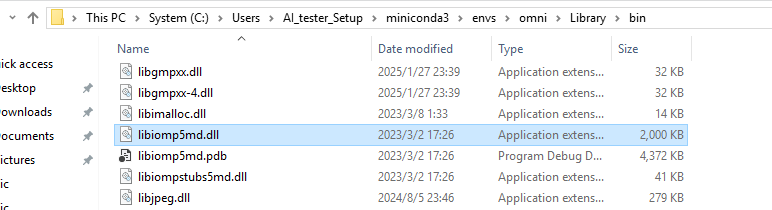
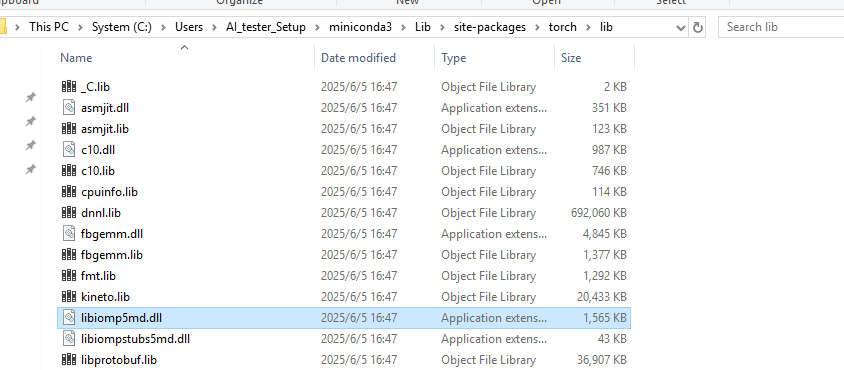
- 查找文件
libiomp5md.dll发现conda环境下出现了两同名文件,一个是位于conda下的,一个是位于torch下的。

- 给conda虚拟环境下的文件换一个路径保存就行。
- 查找文件
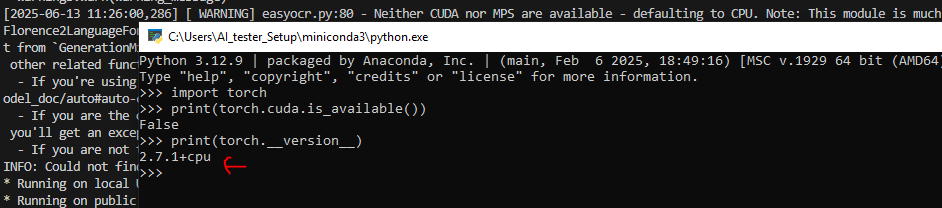
解决easyocr.py:80问题
- 问题描述:Neither CUDA nor MPS are available - defaulting to CPU. Note: This module is much faster with a GPU.
- 验证pytourch是否装成了CPU版本:
- 验证pytorch最高能支持的cuda版本,太高了出现兼容性问题;
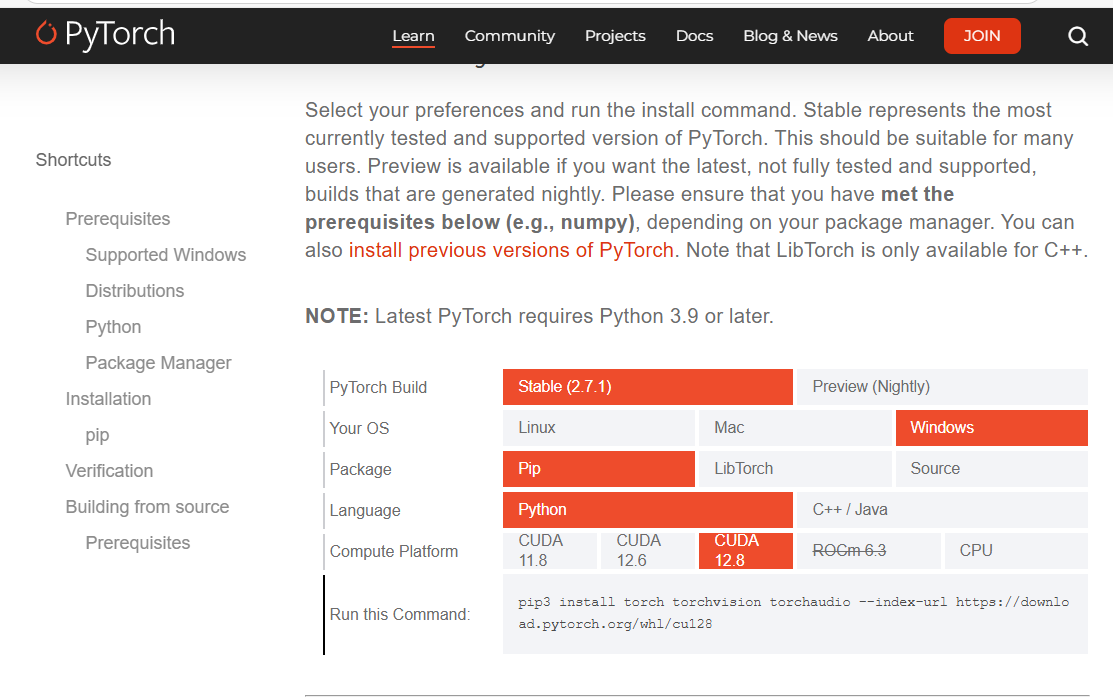
复制下载command
- 重装cuda:
- 安装新cuda之前需要卸载原有的cuda
- 安装完成cuda之后需要下载cuDNN并把相应文件放置在指定文件夹中。
- 根据自己的cuda版本和其他方式在pytorch官网选择指定pytorch版本,如上截图。
- 验证安装结果:
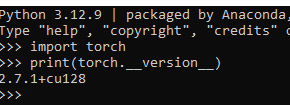
- 注意:即使从pytorch官网指令安装的torchvision也可能和cuda不匹配,报错如:
NotImplementedError: Could not run 'torchvision::nms' with arguments from the 'CUDA' backend. This could be because the operator doesn't exist for this backend, or was omitted during the selective/custom build process... - 解决方案如下:
- 先卸载torchvision:
pip uninstall torchvision - 再重装torchvision:
pip install torchvision - -index-url https://download.pytorch.org/whl/cu128,其中的cu128改成实际的cuda版本。
- 先卸载torchvision:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号