
文章标题
Introducing DataFrames in Apache Spark for Large Scale Data Science
一个用于大规模数据科学的API——DataFrame
作者介绍
文章正文
Today, we are excited to announce a new DataFrame API designed to make big data processing even easier for a wider audience.
今天,我们正式宣布Spark新的API——DataFrame 。作为2014–2015年Spark最大的API改动,DataFrame能够使得大数据更为简单,从而拥有更广泛的受众群体。
When we first open sourced Apache Spark, we aimed to provide a simple API for distributed data processing in general-purpose programming languages (Java, Python, Scala). Spark enabled distributed data processing through functional transformations on distributed collections of data (RDDs). This was an incredibly powerful API: tasks that used to take thousands of lines of code to express could be reduced to dozens.
我们最早在设计Spark的时候,其中一个很重要的目标就是给大数据生态圈提供基于通用编程语言的(Java、Scala、Python)简单易用的API。Spark原本的RDD API通过函数式编程的模式把分布式数据处理转换成分布式数据集(distributed collections)。原本需要上千行用Hadoop MapReduce实现的代码,在Spark这个API上减少到了数十行。
- dozens ['dʌznz] 几十,许多;(一)打,十二个( dozen的名词复数 )
As Spark continues to grow, we want to enable wider audiences beyond “Big Data” engineers to leverage the power of distributed processing. The new DataFrames API was created with this goal in mind. This API is inspired by data frames in R and Python (Pandas), but designed from the ground-up to support modern big data and data science applications. As an extension to the existing RDD API, DataFrames feature:
然后随着Spark的不断壮大,我们希望拥有更广泛的受众群体利用其进行分布式处理,不局限于“大数据”工程师。这个新的DataFrame API在R和Python data frame的设计灵感之上,专门为了数据科学应用设计,具有以下功能特性:
- leverage [ˈli:vərɪdʒ] 杠杆作用;影响力;优势,力量;举债经营
- ground-up 碾碎的;磨成粉的 重新
- Ability to scale from kilobytes of data on a single laptop to petabytes on a large cluster
- Support for a wide array of data formats and storage systems
- State-of-the-art optimization and code generation through the Spark SQL Catalystoptimizer
- Seamless integration with all big data tooling and infrastructure via Spark
- APIs for Python, Java, Scala, and R (in development via SparkR)
- 从KB到PB级的数据量支持;
- 多种数据格式和多种存储系统支持;
- 通过Spark SQL的Catalyst优化器进行先进的优化,生成代码;
- 通过Spark无缝集成所有大数据工具与基础设施;
- 为Python、Java、Scala和R语言(SparkR)API。
For new users familiar with data frames in other programming languages, this API should make them feel at home. For existing Spark users, this extended API will make Spark easier to program, and at the same time improve performance through intelligent optimizations and code-generation.
对于之前熟悉其他语言中data frames的新用户来说,这个新的API可以让Spark的初体验变得更加友好。而对于那些已经在使用的用户来说,这个API会让基于Spark的编程更加容易,同时其智能优化和代码生成也能帮助用户获得更好的性能。
1、What Are DataFrames?
In Spark, a DataFrame is a distributed collection of data organized into named columns. It is conceptually equivalent to a table in a relational database or a data frame in R/Python, but with richer optimizations under the hood. DataFrames can be constructed from a wide array of sources such as: structured data files, tables in Hive, external databases, or existing RDDs.
在Spark中,DataFrame是一个以命名列方式组织的分布式数据集,等同于关系型数据库中的一个表,也相当于R/Python中的data frames(但是进行了更多的优化)。DataFrames可以由结构化数据文件转换而来,也可以从Hive中的表得来,以及可以转换自外部数据库或现有的RDD。
- conceptually [kən'septʃʊrlɪ] 概念地 从概念上讲
- equivalent [ɪˈkwɪvələnt] 相等的,相当的,等效的;等价的,等积的;[化学]当量的
The following example shows how to construct DataFrames in Python. A similar API is available in Scala and Java.
下面代码演示了如何使用Python构造DataFrames,而在Scala和Java中也有类似的API可以调用。
// Constructs a DataFrame from the users table in Hive. users = context.table(“users”) // from JSON files in S3 logs = context.load(“s3n://path/to/data.json”, “json”)
2、How Can One Use DataFrames?
Once built, DataFrames provide a domain-specific language for distributed data manipulation. Here is an example of using DataFrames to manipulate the demographic data of a large population of users:
一经构建,DataFrames就会为分布式数据处理提供一个指定的DSL(domain-specific language )。
- demographic [ˌdemə'ɡræfɪk] 人口统计学的;人口统计的
// Create a new DataFrame that contains “young users” only young = users.filter(users.age < 21) // Alternatively, using Pandas-like syntax young = users[users.age < 21] // Increment everybody’s age by 1 young.select(young.name, young.age + 1) // Count the number of young users by gender young.groupBy(“gender”).count() // Join young users with another DataFrame called logs young.join(logs, logs.userId == users.userId, “left_outer”)
You can also incorporate SQL while working with DataFrames, using Spark SQL. This example counts the number of users in the young DataFrame.
通过Spark SQL,你还可以用SQL的方式操作DataFrames。下面这个例子统计了“young” DataFrame中的用户数量。
young.registerTempTable(“young”) context.sql(“SELECT count(*) FROM young”)
In Python, you can also convert freely between Pandas DataFrame and Spark DataFrame:
在Python中,Pandas DataFrame和Spark DataFrame还可以自由转换。
// Convert Spark DataFrame to Pandas pandas_df = young.toPandas() // Create a Spark DataFrame from Pandas spark_df = context.createDataFrame(pandas_df)
Similar to RDDs, DataFrames are evaluated lazily. That is to say, computation only happens when an action (e.g. display result, save output) is required. This allows their executions to be optimized, by applying techniques such as predicate push-downs and bytecode generation, as explained later in the section “Under the Hood: Intelligent Optimization and Code Generation”. All DataFrame operations are also automatically parallelized and distributed on clusters.
类似于RDD,DataFrame同样使用了lazy的方式。也就是说,只有动作真正发生时(如显示结果,保存输出),计算才会进行。从而,通过一些技术,比如predicate push-downs和bytecode generation,执行过程可以进行适当的优化(详情见下文)。同时,所有的DataFrames也会自动的在集群上并行和分布执行。
3、Supported Data Formats and Sources
Modern applications often need to collect and analyze data from a variety of sources. Out of the box, DataFrame supports reading data from the most popular formats, including JSON files, Parquet files, Hive tables. It can read from local file systems, distributed file systems (HDFS), cloud storage (S3), and external relational database systems via JDBC. In addition, through Spark SQL’s external data sources API, DataFrames can be extended to support any third-party data formats or sources. Existing third-party extensions already include Avro, CSV, ElasticSearch, and Cassandra.
现代的应用程序通常需要收集和分析来自各种不同数据源的数据,而DataFrame与生俱来就支持读取最流行的格式,包括JSON文件、Parquet文件和Hive表格。DataFrame还支持从多种类型的文件系统中读取,比如本地文件系统、分布式文件系统(HDFS)以及云存储(S3)。同时,配合JDBC,它还可以读取外部关系型数据库系统。此外,通过Spark SQL的外部数据源(external data sources) API,DataFrames可以更广泛地支持任何第三方数据格式和数据源。值得一提的是,当下的第三方扩展已经包含Avro、CSV、ElasticSearch和Cassandra。
- out of the box [aʊt ʌv ði bɑks] (澳/新西兰,非正式)非常好

DataFrames’ support for data sources enables applications to easily combine data from disparate sources (known as federated query processing in database systems). For example, the following code snippet joins a site’s textual traffic log stored in S3 with a PostgreSQL database to count the number of times each user has visited the site.
DataFrames对数据源的支持能力允许应用程序可以轻松地组合来自不同数据源的数据。下面的代码片段则展示了存储在S3上网站的一个文本流量日志(textual traffic log)与一个PostgreSQL数据库的join操作,目的是计算网站用户访问该网站的次数。
- disparate ['dɪspərət] 完全不同的;从根本上种类有区分或不同的
users = context.jdbc(“jdbc:postgresql:production”, “users”)
logs = context.load(“/path/to/traffic.log”)
logs.join(users, logs.userId == users.userId, “left_outer”) \
.groupBy(“userId”).agg({“*”: “count”})
4、Application: Advanced Analytics and Machine Learning
Data scientists are employing increasingly sophisticated techniques that go beyond joins and aggregations. To support this, DataFrames can be used directly in MLlib’s machine learning pipeline API. In addition, programs can run arbitrarily complex user functions on DataFrames.
当下,数据科学家们使用的技术已日益复杂,超越了joins和aggregations。为了更好地支持他们的使用,DateFrames可以直接在MLlib的machine learning pipeline API中使用。此外,在DataFrames中,程序还可以运行任意复杂的用户函数。
- sophisticated [səˈfɪstɪˌketɪd] 复杂的;精致的;富有经验的;深奥微妙的
- arbitrarily [ˌɑrbəˈtrɛrəlɪ] 任意地;武断地;反复无常地;肆意地
Most common advanced analytics tasks can be specified using the new pipeline API in MLlib. For example, the following code creates a simple text classification pipeline consisting of a tokenizer, a hashing term frequency feature extractor, and logistic regression.
通过Spark,用户可以使用MLlib中新的pipelineAPI来指定高级分析任务。例如,下面的代码创建了一个简单的文本分类(text classification)管道。该管道由一个tokenizer,一个hashing term frequency feature extractor和logistic regression组成。
tokenizer = Tokenizer(inputCol=”text”, outputCol=”words”) hashingTF = HashingTF(inputCol=”words”, outputCol=”features”) lr = LogisticRegression(maxIter=10, regParam=0.01) pipeline = Pipeline(stages=[tokenizer, hashingTF, lr])
Once the pipeline is setup, we can use it to train on a DataFrame directly:
一旦管道设置好,我们可以直接使用它在DataFrame上进行训练。
df = context.load(“/path/to/data”) model = pipeline.fit(df)
For more complicated tasks beyond what the machine learning pipeline API provides, applications can also apply arbitrarily complex functions on a DataFrame, which can also be manipulated using Spark’s existing RDD API. The following snippet performs a word count, the “hello world” of big data, on the “bio” column of a DataFrame.
对于那些复杂程度超出了machine learning pipeline API能力的任务,应用程序也可以通过DataFrames提供任意复杂的函数,当然这也可以通过Spark已有的RDD API来实现。下面代码段实现的是一个DataFrame“bio”列上的word count(大数据时代的Hello World)。
- manipulate [məˈnɪpjəˌlet] 操纵;操作,处理;巧妙地控制;[医] 推拿,调整
- snippet [ˈsnɪpɪt] 小片,片段;不知天高地厚的年轻人
df = context.load(“/path/to/people.json”)
// RDD-style methods such as map, flatMap are available on DataFrames // Split the bio text into multiple words. words = df.select(“bio”).flatMap(lambda row: row.bio.split(” “))
// Create a new DataFrame to count the number of words words_df = words.map(lambda w: Row(word=w, cnt=1)).toDF() word_counts = words_df.groupBy(“word”).sum()
5、Under the Hood: Intelligent Optimization and Code Generation
Unlike the eagerly evaluated data frames in R and Python, DataFrames in Spark have their execution automatically optimized by a query optimizer. Before any computation on a DataFrame starts, the Catalyst optimizer compiles the operations that were used to build the DataFrame into a physical plan for execution. Because the optimizer understands the semantics of operations and structure of the data, it can make intelligent decisions to speed up computation.
与R/Python中data frame使用的eager方式不同,Spark中的DataFrames执行会被查询优化器自动优化。在DataFrame上的计算开始之前,Catalyst优化器会编译操作,这将把DataFrame构建成物理计划来执行。因为优化器清楚操作的语义和数据的结构,所以它可以为计算加速制定智能的决策。
- eagerly [ˈiɡɚlɪ] 渴望地,热切地
At a high level, there are two kinds of optimizations. First, Catalyst applies logical optimizations such as predicate pushdown. The optimizer can push filter predicates down into the data source, enabling the physical execution to skip irrelevant data. In the case of Parquet files, entire blocks can be skipped and comparisons on strings can be turned into cheaper integer comparisons via dictionary encoding. In the case of relational databases, predicates are pushed down into the external databases to reduce the amount of data traffic.
在高等级上,这里存在两种类型的优化。首先,Catalyst提供了逻辑优化,比如谓词下推(predicate pushdown)。优化器可以将谓词过滤下推到数据源,从而使物理执行跳过无关数据。在使用Parquet的情况下,更可能存在文件被整块跳过的情况,同时系统还通过字典编码把字符串对比转换为开销更小的整数对比。在关系型数据库中,谓词则被下推到外部数据库用以减少数据传输。
- irrelevant [ɪˈrɛləvənt] 不相干的;不恰当;缺乏时代性的,落后于潮流的;牛头不对马嘴
- traffic [ˈtræfɪk] 交通,运输量;(非法的)交易;通信量;交际 传输
Second, Catalyst compiles operations into physical plans for execution and generates JVM bytecode for those plans that is often more optimized than hand-written code. For example, it can choose intelligently between broadcast joins and shuffle joins to reduce network traffic. It can also perform lower level optimizations such as eliminating expensive object allocations and reducing virtual function calls. As a result, we expect performance improvements for existing Spark programs when they migrate to DataFrames.
第二,为了更好地执行,Catalyst将操作编译为物理计划,并生成JVM bytecode,这些通常会比人工编码更加优化。例如,它可以智能地选择broadcast joins和shuffle joins来减少网络传输。其次,同样存在一些较为低级的优化,如消除代价昂贵的对象分配及减少虚拟函数调用。因此,我们认为现有的Spark项目迁移到DataFrames后,性能会有所改观。
- hand-written code 人工编码 手写代码
- network traffic 网络传输
- perform [pərˈfɔ:rm] 执行;履行;表演;扮演
Since the optimizer generates JVM bytecode for execution, Python users will experience the same high performance as Scala and Java users.
同时,鉴于优化器为执行生成了JVM bytecode,Python用户将拥有与Scala和Java用户一样的高性能体验。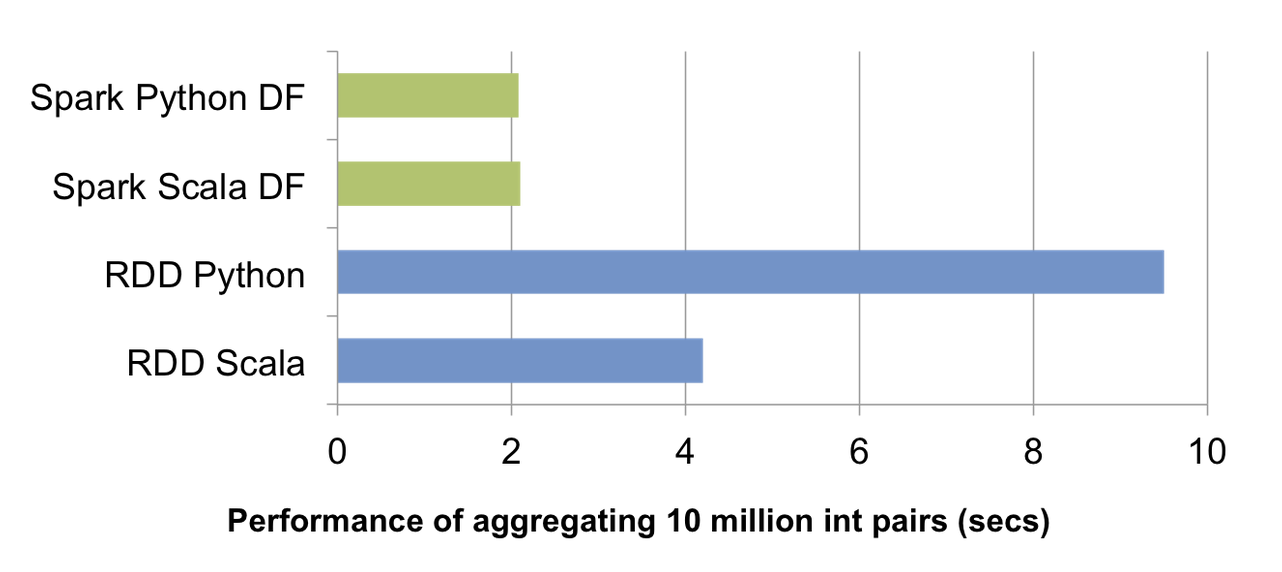
The above chart compares the runtime performance of running group-by-aggregation on 10 million integer pairs on a single machine (source code). Since both Scala and Python DataFrame operations are compiled into JVM bytecode for execution, there is little difference between the two languages, and both outperform the vanilla Python RDD variant by a factor of 5 and Scala RDD variant by a factor of 2.
上图是在单个机器上对1000万个整数进行分组聚合(group-by-aggregation)的运行时性能对比。在绿色部分,为了更好地执行,Scala和Python的DataFrame操作都被编译成了JVM bytecode,导致这两种语言在性能上基本有着同样的表现。同时,两者性能均优于普通Python RDD实现的4倍,也达到了Scala RDD实现的两倍。
DataFrames were inspired by previous distributed data frame efforts, including Adatao’s DDF and Ayasdi’s BigDF. However, the main difference from these projects is that DataFrames go through the Catalyst optimizer, enabling optimized execution similar to that of Spark SQL queries. As we improve the Catalyst optimizer, the engine also becomes smarter, making applications faster with each new release of Spark.
不管选择了哪种语言,Catalyst优化器都实现了DataFrame程序的优化执行。同时,随着Catalyst优化器的不断改善,引擎也会变得更智能,从而对比已有版本,Spark的每一个新版本都会有性能上的提升。
Our data science team at Databricks has been using this new DataFrame API on our internal data pipelines. It has brought performance improvements to our Spark programs while making them more concise and easier to understand. We are very excited about it and believe it will make big data processing more accessible to a wider array of users.
在Databricks,数据科学家团队已经将DataFrame API搭载在内部的数据管道上。Spark程序性能的改进已经在我们内部得到证实,而程序也更加的简洁易懂。毫无疑问,这将大幅度地降低大数据使用门槛,让大数据技术为更多人使用。
- concise [kənˈsaɪs] 简约;简明的,简洁的;精炼
This API will be released as part of Spark 1.3 in early March. If you can’t wait, check out Spark from GitHub to try it out. If you are in the Bay Area at the Strata conference, please join us on Feb 17 in San Jose for a meetup on this topic.
这个API将在3月初作为Spark1.3版本的一部分发布。如果你迫不及待,可以关注Spark在GitHub上的进展。如果你在加州湾区参加Strata conference,2月17日圣何塞有一个关于这个主题的Meetup。
- bay [be] 湾,海湾;犬吠声;月桂树;吊窗,凸窗
- San Jose [sɑnhoˈze] 圣何塞(美国城市)
This effort would not have been possible without the prior data frame implementations, and thus we would like to thank the developers of R, Pandas, DDF and BigDF for their work.
To try out DataFrames, get a free trial of Databricks or use the Community Edition.
参考文献
- https://databricks.com/blog/2015/02/17/introducing-dataframes-in-spark-for-large-scale-data-science.html
- https://blog.csdn.net/mt0803/article/details/50464124
- https://blog.csdn.net/yhao2014/article/details/44979041
如果,您认为阅读这篇博客让您有些收获,不妨点击一下右下角的【推荐】。
如果,您希望更容易地发现我的新博客,不妨点击一下左下角的【关注我】。
如果,您对我的博客所讲述的内容有兴趣,请继续关注我的后续博客,我是【虾皮★csAxp】。
如果,您还想与更多的爱好者进一步交流,不防加入QQ群【虾皮工作室-ABC大数据(232658451)】。
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号