BERT
BERT
1 BERT简介
BERT(Bidirectional Encoder Representations from Transformers)是由Google在2018年提出的一种预训练语言模型。它通过在大规模语料上预训练,然后在特定任务上微调,在多项自然语言处理任务中取得了突破性的性能。
BERT的核心创新在于其双向上下文理解能力,通过两个预训练任务(掩码语言建模和下一句预测)来学习文本的深层语义表示。
2 BERT的架构
BERT的总体架构如下图所示。最左边是BERT的架构图,可以清楚地看到BERT采用了Transformer的Encoder块进行连接,是一个典型的双向编码模型。
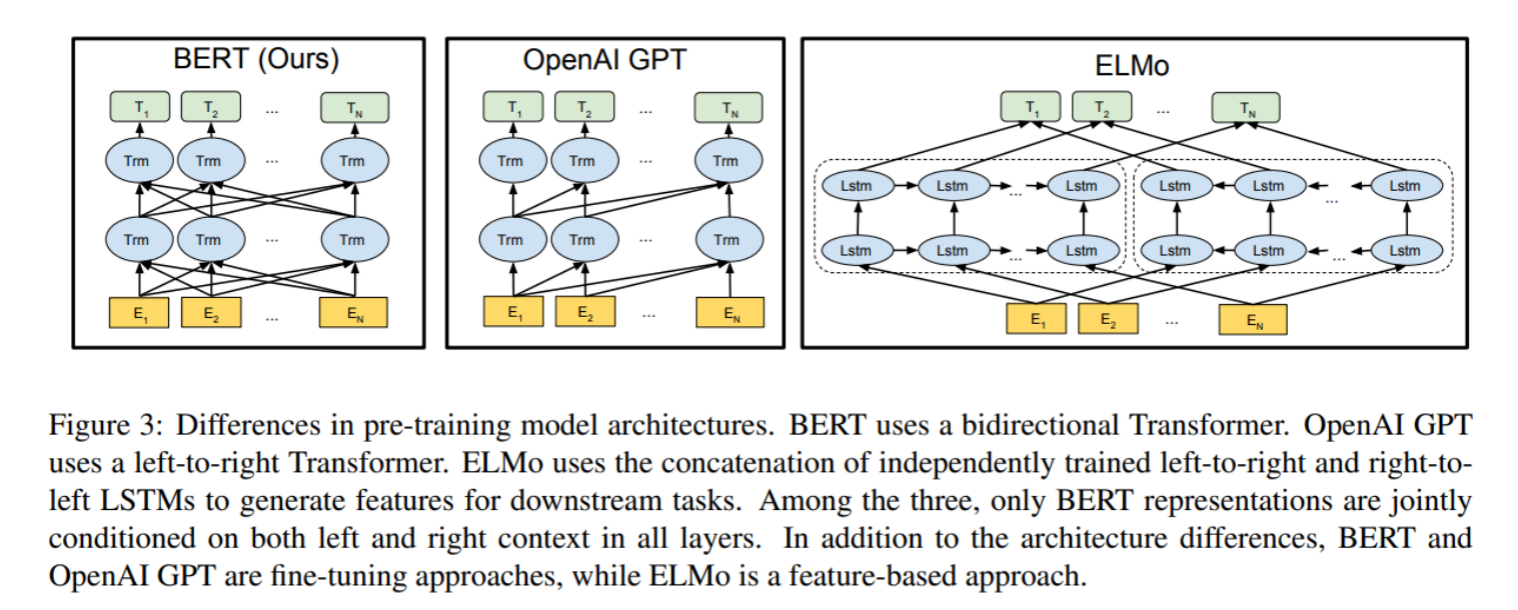
从架构图中可以看到,BERT在宏观上分为三个主要模块:
- 最底层(黄色标记):Embedding模块
- 中间层(蓝色标记):Transformer模块
- 最上层(绿色标记):预微调模块
2.1 Embedding模块
BERT的Embedding模块由三种Embedding共同组成,如下图所示。
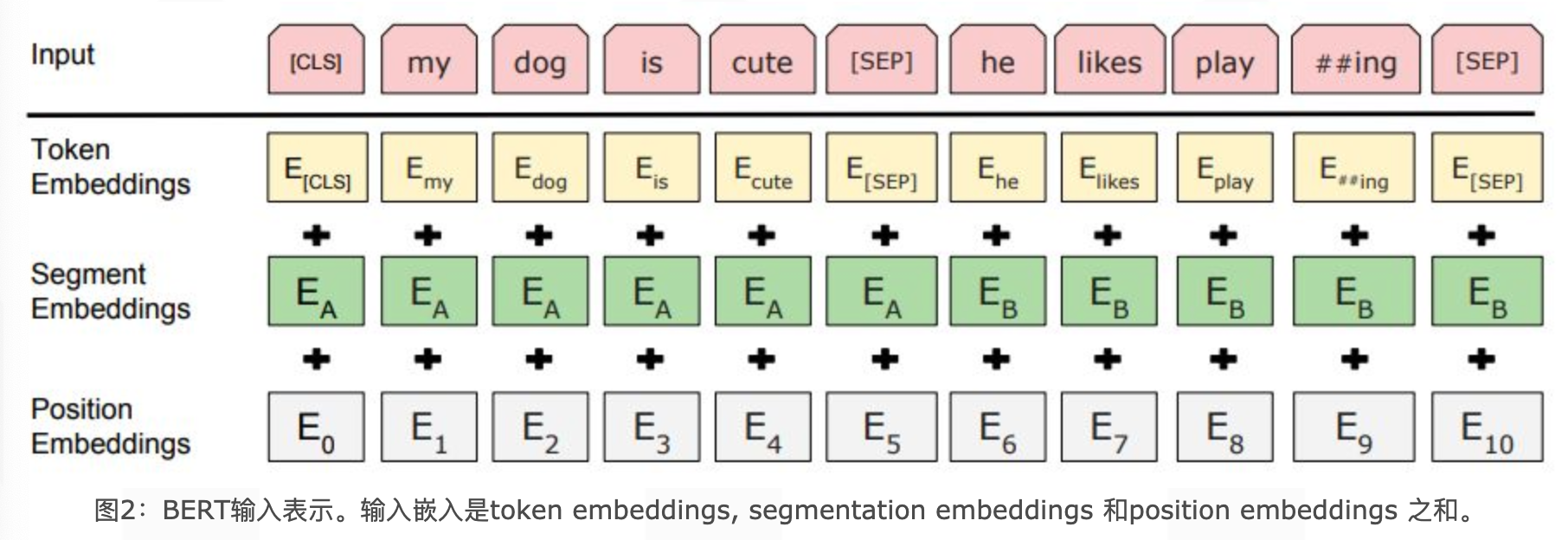
三种Embedding分别为:
-
Token Embeddings(词嵌入张量):将每个token(单词或字)映射为一个固定维度的向量。序列的第一个token是特殊的[CLS]标志,可用于后续的分类任务。
-
Segment Embeddings(句子分段嵌入张量):用于区分两个句子(如句子A和句子B)。在预训练任务中,用于标记每个token属于哪个句子。
-
Position Embeddings(位置编码张量):与传统的Transformer使用三角函数计算固定位置编码不同,BERT的位置编码是通过学习得到的。
整个Embedding模块的输出张量是这三个张量的直接加和结果:
2.2 双向Transformer模块
BERT中只使用了经典Transformer架构中的Encoder部分,完全舍弃了Decoder部分。BERT-base模型包含12个Transformer Encoder层,BERT-large模型包含24个Transformer Encoder层。
Transformer Encoder层的结构与标准Transformer相同,包含:
- 多头自注意力机制(Multi-Head Self-Attention)
- 前馈神经网络(Feed-Forward Network)
- 残差连接(Residual Connection)和层归一化(Layer Normalization)
BERT的两大预训练任务(掩码语言模型和下一句预测)集中体现在训练Transformer模块中。
2.3 预微调模块
经过中间层Transformer处理后,BERT的最后一层根据任务的不同需求而做不同的调整。
对于不同的下游任务,微调都集中在预微调模块。几种重要的NLP微调任务架构图展示如下:
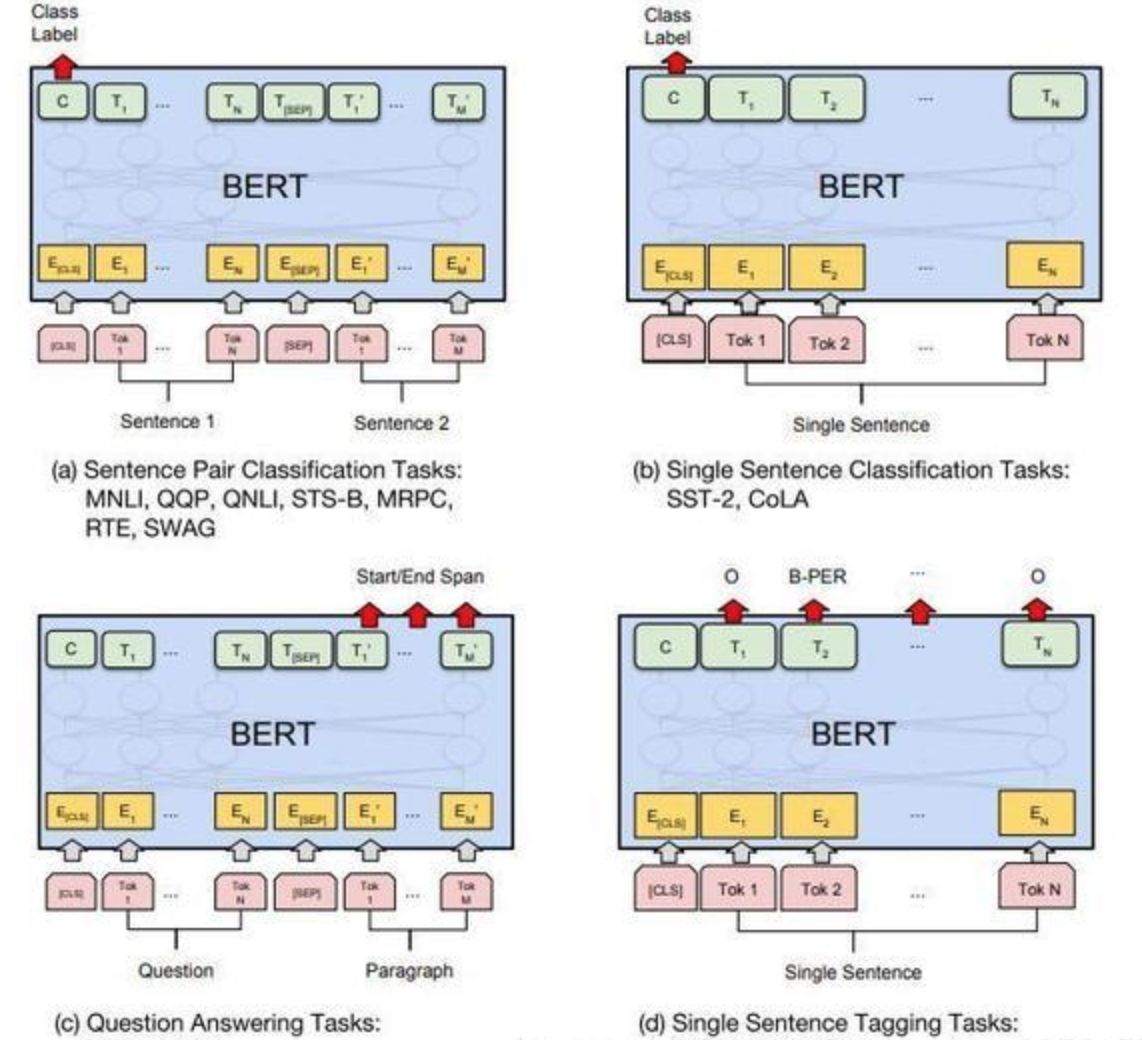
常见的下游任务调整方式:
-
序列分类任务(如情感分析):取第一个[CLS] token的最终隐藏状态,加一层全连接层后进行softmax分类。
-
句子对分类任务(如自然语言推理):将两个句子拼接输入,取[CLS] token的表示进行分类。
-
问答任务(QA):在文本段落上预测答案的开始和结束位置。
-
命名实体识别(NER):对每个token进行分类,识别其实体类型。
在进行微调时,若干可选的超参数建议如下:
- Batch size: 16, 32
- Learning rate (Adam): 5e-5, 3e-5, 2e-5
- Epochs: 3, 4
3 BERT的预训练任务
BERT包含两个预训练任务:
3.1 任务一:Masked Language Model (MLM)
掩码语言模型任务旨在训练模型理解双向上下文信息。传统的语言模型训练采用从左到右或双向拼接的方式,但这种单向方式或拼接方式提取特征的能力有限。为此,BERT提出深度双向表达模型,采用掩码任务来训练模型。
具体步骤:
-
选择掩码token:在原始训练文本中,随机抽取15%的token作为参与掩码任务的对象。
-
掩码策略:在这些被选中的token中,采用以下三种策略:
- 80%的概率:用[MASK]标记替换该token,例如:"my dog is hairy" → "my dog is [MASK]"
- 10%的概率:用一个随机的单词替换该token,例如:"my dog is hairy" → "my dog is apple"
- 10%的概率:保持该token不变,例如:"my dog is hairy" → "my dog is hairy"
-
训练目标:模型需要预测被掩码的原始token。这种设计迫使模型学习每个token的分布式上下文语义,同时因为只有15%的token参与了掩码操作,不会破坏原语言的表达能力和语言规则。
损失函数采用交叉熵损失,只计算被掩码位置的损失:
3.2 任务二:Next Sentence Prediction (NSP)
下一句预测任务旨在让模型理解句子之间的关系,这对问答、自然语言推理等任务至关重要。
具体步骤:
-
构建训练样本:
- 50%的正样本:句子B是句子A的真实下一句话(标记为IsNext)
- 50%的负样本:句子B是从语料库中随机抽取的句子(标记为NotNext)
-
输入格式:[CLS] 句子A [SEP] 句子B [SEP]
-
训练目标:模型根据[CLS] token的表示预测句子B是否是句子A的下一句。
损失函数为二分类交叉熵损失:
其中\(y\)是真实标签,\(\hat{y}\)是模型预测的概率。
BERT的总损失为两个任务的损失之和:
4 BERT模型优缺点
BERT模型的优点和缺点?
4.1 BERT的优点
-
强大的性能:通过预训练加微调的方式,在11项NLP任务上取得最优结果。
-
双向上下文理解:BERT采用了Transformer的Encoder模块,获得了真正意义上的双向上下文信息,能够捕捉长距离的语义和结构依赖。
-
并行化处理:基于Transformer架构,相比传统RNN更加高效,可以并行化处理序列。
-
通用性强:预训练模型可以适应多种下游任务,只需微调最后一层或几层即可。
4.2 BERT的缺点
-
模型庞大:BERT-base有1.1亿参数,BERT-large有3.4亿参数,不利于资源紧张的应用场景和实时处理。
-
中文处理以字为单位:BERT的中文模型以字为基本token单位,对需要词向量的应用支持不够好,且无法识别很多生僻词,只能以[UNK]代替。
-
预训练与微调不一致:MLM任务中的[MASK]标记只在训练阶段出现,预测阶段不会出现,造成一定的信息偏差。
-
训练效率低:每个batch中只有15%的token参与MLM训练,收敛速度比从左到右模型慢。
-
最大序列长度限制:BERT最大支持512个token的序列长度,对长文本处理需要特殊处理。
5 BERT的MLM任务策略解释
BERT的MLM任务中为什么采用了80%, 10%, 10%的策略?
在BERT的MLM任务中,采用80%、10%、10%的策略,原因如下:
-
80%使用[MASK]:让模型学会预测被掩码的单词,学习上下文信息。如果全部使用[MASK],在微调时模型将无法利用单词本身的信息,因为微调时没有[MASK]标记。
-
10%使用随机单词:防止模型过度依赖当前位置的单词信息,迫使模型学习单词周边的语义表达和远距离依赖,建模完整的语言信息。
-
10%保持原词:保留语言本来的面貌,让模型能够"看清"真实的语言结构,避免过度依赖掩码模式。
这种策略平衡了模型的学习目标:既学习预测掩码单词,又不过度适应掩码模式。
6 BERT处理长文本的方法
长文本预测任务如果想用BERT来实现, 要如何构造训练样本?
BERT预训练模型所接收的最大序列长度是512个token。对于长文本(超过512个token),需要特殊处理:
6.1 截断方法
-
head-only方式:只保留长文本头部信息,保存前510个token(留两个位置给[CLS]和[SEP])。
-
tail-only方式:只保留长文本尾部信息,保存最后510个token(留两个位置给[CLS]和[SEP])。
-
head+tail方式:结合头部和尾部信息:
- 文本总长度在800以内:选择前128个token和最后382个token
- 文本总长度大于800:选择前256个token和最后254个token
6.2 滑动窗口方法
对于需要完整上下文的任务,可以采用滑动窗口的方法:
- 将长文本分割为多个512 token的片段
- 对每个片段单独处理
- 整合各片段的结果
6.3 使用长文本变体
可以使用专门处理长文本的BERT变体,如:
- Longformer:使用稀疏注意力机制处理长序列
- BigBird:结合局部、全局和随机注意力处理长序列

 浙公网安备 33010602011771号
浙公网安备 33010602011771号