循环神经网络(RNN)
循环神经网络(RNN)
RNN概念
循环神经网络(Recurrent Neural Network, RNN)是一种专门处理序列数据的神经网络。与传统的前馈神经网络不同,RNN具有“循环”结构,能够处理和记住前面时间步的信息,使其特别适用于时间序列数据或有时序依赖的任务。
序列数据是指数据点之间存在顺序关系的数据,例如时间序列数据(股票价格、气温变化)或文本序列(句子、文章)。序列数据的一个关键特点是后面的数据跟前面的数据有关系。
RNN的基本结构包含一个循环单元,该单元在每个时间步接收当前输入和上一个时间步的隐藏状态,并输出当前时间步的隐藏状态和可能的输出。
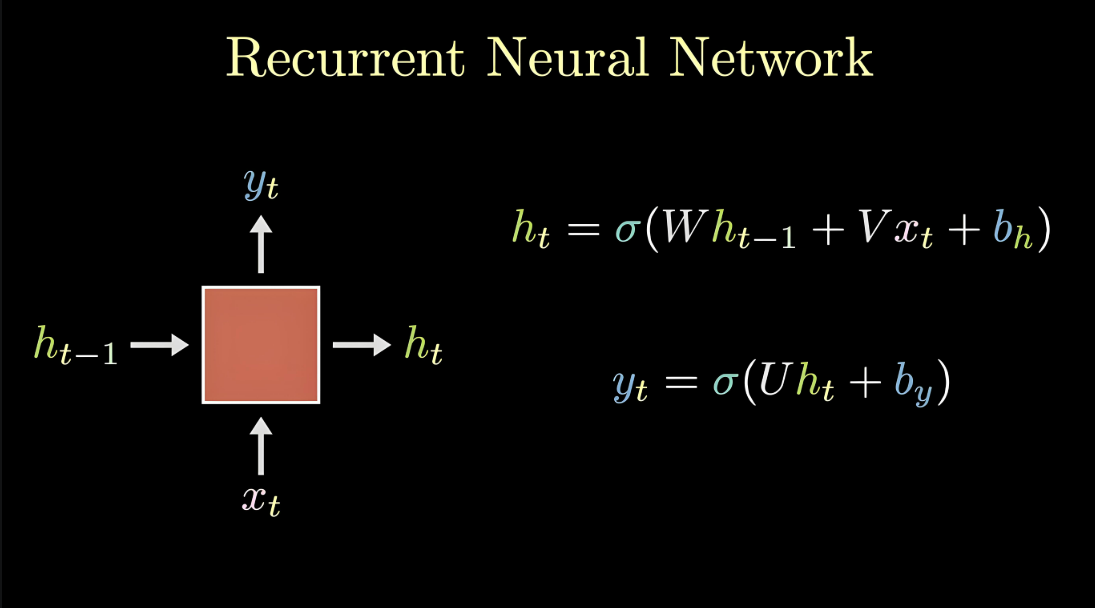
其中:
- \(x_t\) 表示当前时刻的输入
- \(h_{t-1}\) 表示上一时刻的隐藏状态
- \(h_t\) 表示当前时刻的隐藏状态
- \(y_t\) 表示当前时刻的输出
- \(W, V\) 为权重矩阵
- \(b\) 为偏置项
- \(\sigma\) 为激活函数
RNN应用场景
- 自然语言处理(NLP):文本生成、语言建模、机器翻译、情感分析等。
- 时间序列预测:股市预测、气象预测、传感器数据分析等。
- 语音识别:将语音信号转换为文字。
- 音乐生成:通过学习音乐的时序模式来生成新乐曲。
自然语言处理概述
自然语言处理(Natural Language Processing, NLP)是人工智能的一个重要分支,其主要目标是通过计算机算法来理解、解释和生成自然语言。
自然语言处理的数据主要是人类的语言(如汉语、英语等),这类数据不像结构化数据或图像数据那样容易进行数值化表示。NLP的目标是让机器能够“听懂”和“读懂”自然语言,并进行有效的交流和分析。
NLP涵盖了从文本到语音、从语音到文本的各个方面,涉及多种技术,包括语法分析、语义理解、情感分析、机器翻译等。

词嵌入层
在RNN中,词嵌入层(Word Embedding Layer) 是处理自然语言数据的关键组成部分。它将输入的离散单词(通常是词汇表中的索引)转换为连续的、低维的向量表示,从而使神经网络能够理解和处理这些词汇的语义信息。
词嵌入层的主要目的是将每个词映射为一个固定长度的稠密向量,这些向量能够捕捉词与词之间的语义关系。传统的文本表示方法(如one-hot编码)无法反映单词之间的相似性,因为每个单词都被表示为一个高维稀疏向量,而词嵌入通过低维稠密向量表示单词,能够更好地捕捉词汇之间的语义相似性。
词嵌入层首先会根据输入的词的数量构建一个词向量矩阵。例如,如果有100个词,每个词用128维的向量表示,那么构建的矩阵形状即为100×128。输入的每个词都对应了该矩阵中的一个向量。
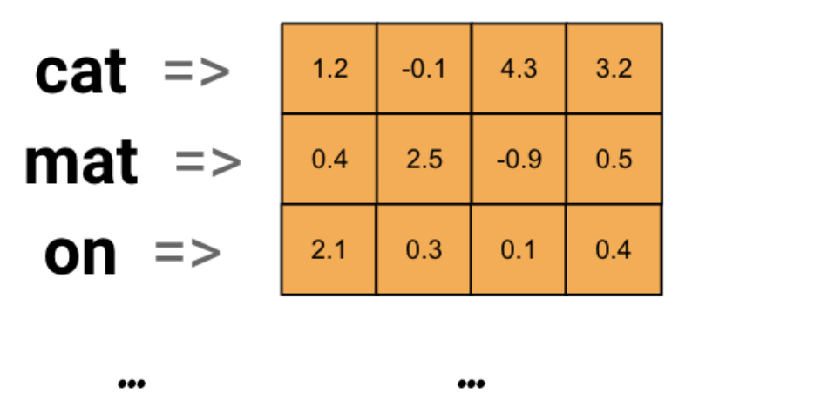
词嵌入层在RNN中的作用
- 输入表示:RNN通常用于处理序列数据。在处理文本时,RNN的输入是由单词构成的序列。由于神经网络不能直接处理离散的单词标识符(如整数索引或字符),因此需要通过词嵌入层将每个单词转换为一个固定长度的稠密向量。这些向量作为RNN的输入,帮助RNN理解词语的语义。
- 降低维度:词嵌入层将原本高维的稀疏表示(如one-hot编码)转化为低维的稠密向量,减少了计算量,同时保持了词汇之间的语义关系。
- 捕捉语义相似性:通过训练,词嵌入能够学习到词语之间的关系。例如,语义相似的词(如“猫”和“狗”)在向量空间中会比较接近,而语义不相关的词(如“猫”和“汽车”)则会较为遥远。
词嵌入层工作流程
- 初始化词向量:词嵌入层的初始词向量通常会使用随机初始化或者通过加载预训练的词向量(如Word2Vec或GloVe)进行初始化。
- 输入索引:每个单词在词汇表中都有一个唯一的索引。输入文本(例如一个句子)会先被分词,然后每个单词会被转换为相应的索引。
- 查找词向量:词嵌入层将这些单词索引映射为对应的词向量。这些词向量是一个低维稠密向量,表示该词的语义。
- 输入到RNN:这些词向量作为RNN的输入,RNN处理它们并根据上下文生成一个序列的输出。
词嵌入层使用
在PyTorch中,我们可以使用nn.Embedding词嵌入层来实现输入词的向量化。
nn.Embedding对象构建时,最主要有两个参数:
num_embeddings:表示词的数量embedding_dim:表示用多少维的向量来表示每个词
import torch.nn as nn
embedding = nn.Embedding(num_embeddings=10, embedding_dim=4)
循环网络层
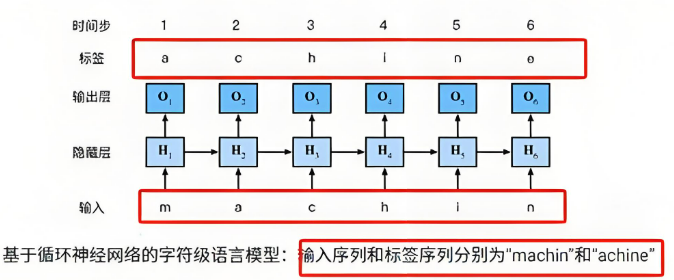
文本数据具有序列特性,例如:“我爱你”,这串文本中“爱”需要在“我”之后,“你”需要在“爱”之后。如果颠倒了顺序,可能表达不同的意思。
为了表示数据的序列关系,我们需要使用循环神经网络(Recurrent Neural Networks, RNN)来对数据进行建模。RNN是一个具有记忆功能的网络,它用于处理带有序列特点的样本数据。
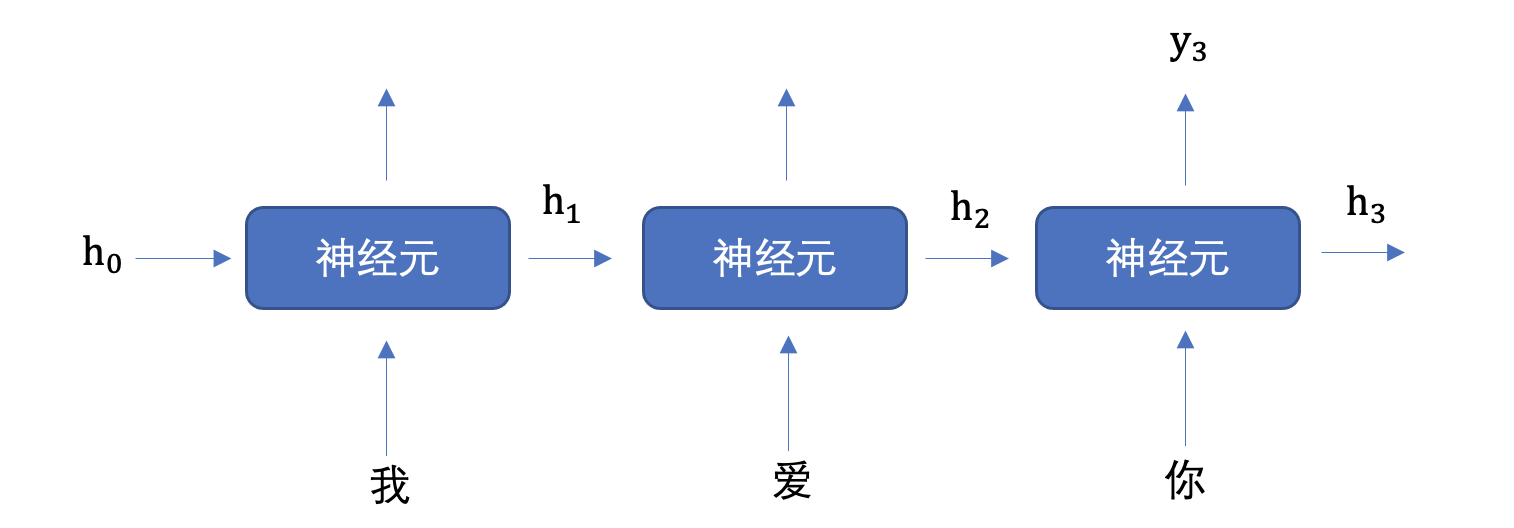
上图中,\(h\)表示隐藏状态。隐藏状态保存了序列数据中的历史信息,并将这些信息传递给下一个时间步,从而允许RNN处理和预测序列数据中的元素。
每一个时间步的输入包含两个值:上一个时间步的隐藏状态和当前状态的输入值\(x\)。
每一个时间步的输出包含两个值:当前时间步的隐藏状态和当前时间步的预测结果\(y\)。
隐藏状态作用
- 记忆功能:隐藏状态就像RNN的记忆,它能够在不同的时间步之间传递信息。当一个新的输入进入网络时,当前的隐藏状态会结合这个新输入来生成新的隐藏状态。
- 上下文理解:由于隐藏状态携带了过去的信息,它可以用于理解和生成与上下文相关的输出。这对于语言模型、机器翻译等任务尤其重要。
- 连接不同时间步:隐藏状态通过网络内部的循环连接将各个时间步连接起来,使得网络可以处理变长的序列数据。
为了更好地理解,我们可以将RNN在不同时间步的重复计算看作同一个神经元在不同时间步被重复使用。例如,在“我爱你”三个字的输入中,虽然看起来有三个神经元,但实际上只有一个神经元,“我爱你”三个字是重复输入到同一个神经元中。
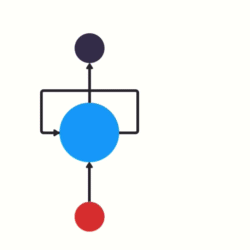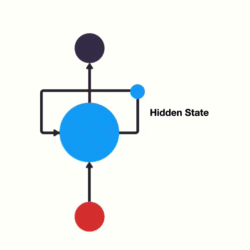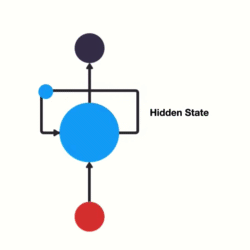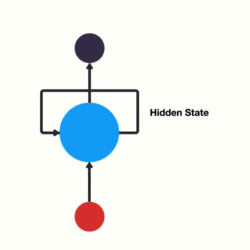
RNN神经元内部计算
1. 计算隐藏状态
每个时间步的隐藏状态\(h_t\)是根据当前输入\(x_t\)和前一时刻的隐藏状态\(h_{t-1}\)计算的。
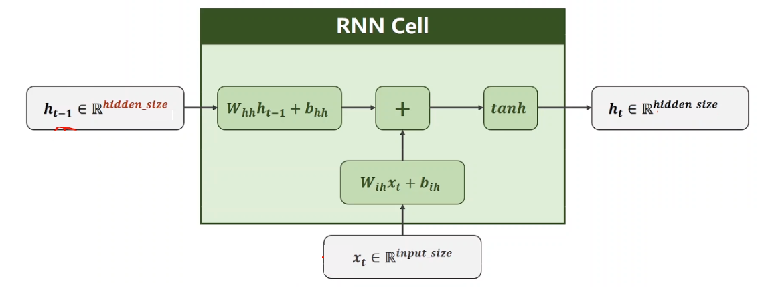
数学公式如下:
其中:
- \(W_{ih}\) 表示输入数据的权重矩阵
- \(b_{ih}\) 表示输入数据的偏置项
- \(W_{hh}\) 表示隐藏状态的权重矩阵
- \(b_{hh}\) 表示隐藏状态的偏置项
- \(h_{t-1}\) 表示上一时刻的隐藏状态
- \(h_t\) 表示当前时刻的隐藏状态
- \(\tanh\) 是激活函数,用于引入非线性
2. 计算当前时刻的输出
网络的输出\(y_t\)是当前时刻的隐藏状态经过一个线性变换得到的。
其中:
- \(y_t\) 是当前时刻的输出(通常是一个向量,表示当前时刻的预测值)
- \(h_t\) 是当前时刻的隐藏状态
- \(W_{hy}\) 是从隐藏状态到输出的权重矩阵
- \(b_y\) 是输出层的偏置项
3. 词汇表映射
输出\(y_t\)是一个向量,该向量经过全连接层后得到最终预测结果\(y_{\text{pred}}\)。\(y_{\text{pred}}\)中每个元素代表当前时刻生成词汇表中某个词的得分(或概率,通过激活函数如softmax转换为概率)。词汇表有多少个词,\(y_{\text{pred}}\)就有多少个元素值,最大元素值对应的词就是当前时刻预测生成的词。
神经元工作机制总结
- 接收输入:每个RNN神经元接收来自输入数据\(x_t\)和前一时刻的隐藏状态\(h_{t-1}\)。
- 更新隐藏状态:神经元通过一个加权和(由权重矩阵和偏置项组成)更新当前时刻的隐藏状态\(h_t\),该隐藏状态包含了来自过去的记忆以及当前输入的信息。
- 输出计算:基于当前隐藏状态\(h_t\),神经元生成当前时刻的输出\(y_t\),该输出可以用于任务的最终预测。
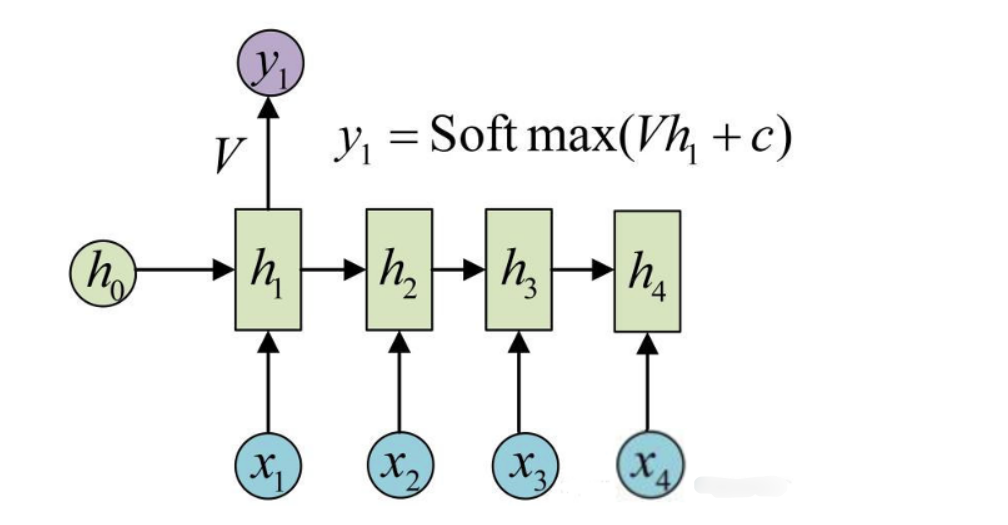
文本生成示例
假设我们使用RNN进行文本生成,输入是一个初始词语或一段上下文(例如,“m”)。RNN会通过隐藏状态逐步生成下一个词的概率分布,然后根据概率选择最可能的下一个词。
步骤:
- 输入:“m” → 词向量输入\(x_1\)(对应“m”)
- 初始化隐藏状态\(h_0\),一般初始值为0
- 隐藏状态更新为\(h_1\),并计算输出\(y_1\)
- 经过全连接层输出层计算输出\(y_{\text{pred}}\),使用softmax函数将\(y_{\text{pred}}\)转换为概率分布
- 选择概率最高的词作为输出词(例如“a”)
- 输入新的词“a”,继续处理下一个时间步,直到生成完整的词或句子
小结:在循环神经网络中,词与输出的对应关系通常通过以下几个步骤建立:
- 词嵌入:将词转化为向量表示(词向量)。
- RNN处理:通过RNN层逐步处理词向量,生成每个时间步的隐藏状态。
- 输出映射:通过线性变换将隐藏状态映射到输出,通常是一个词汇表中的词的概率分布。
PyTorch RNN层的使用
在PyTorch中,RNN层可以通过torch.nn.RNN实现。
import torch
import torch.nn as nn
# 参数1: 词向量的维度 参数2: 隐藏状态向量维度 参数3: 隐藏层数量
rnn = nn.RNN(input_size=128, hidden_size=256, num_layers=1)
# 输入数据:每个句子的词的个数(长度)为5,句子的数量(批量大小)为32,词向量的维度为128
# 形状: (seq_len, batch_size, input_size)
x = torch.randn(size=(5, 32, 128))
# 初始隐藏状态:隐藏层的层数为1,句子的数量(批量大小)为32,隐藏状态向量维度为256
# 形状: (num_layers, batch_size, hidden_size)
h0 = torch.randn(size=(1, 32, 256))
# 前向传播
# output: 所有时间步的隐藏状态,形状为(seq_len, batch_size, hidden_size)
# h1: 最后1个时间步的隐藏状态,形状为(num_layers, batch_size, hidden_size)
output, h1 = rnn(x, h0)
print(f'output shape: {output.shape}') # [5, 32, 256]
print(f'h1 shape: {h1.shape}') # [1, 32, 256]
通过上述代码,我们可以了解如何使用PyTorch构建和运行RNN模型。RNN层能够处理序列数据,并输出每个时间步的隐藏状态和最后一个时间步的隐藏状态,这些隐藏状态可以用于后续的任务,如分类或序列生成。
RNN 文本生成案例
"""
实现一个基于RNN的文本生成模型,用于生成歌词
"""
import torch
import re
import jieba
from torch.utils.data import DataLoader
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import time
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
def build_vocab():
unique_words, all_words = [], [] # unique_words存放不重复的词,all_words存放所有词
for line in open('data/jaychou_lyrics.txt', 'r', encoding='utf-8'):
words = jieba.lcut(line) # 分词
all_words.append(words) # 把当前行的词加入到所有词列表中
for word in words:
if word not in unique_words:
unique_words.append(word)
# print('unique_words: ', len(unique_words))
word2idx = {word: idx for idx, word in enumerate(unique_words)}
corpus_idx = []
for words in all_words:
tmp = [word2idx[word] for word in words]
tmp.append(word2idx[' ']) # 添加空格作为每行的结束符
corpus_idx.extend(tmp)
return unique_words, word2idx, len(unique_words), corpus_idx
class LyricsDataset(torch.utils.data.Dataset):
def __init__(self, corpus_idx, num_chars):
self.corpus_idx = corpus_idx # 整个语料库的索引列表
self.num_chars = num_chars # 每个句子中的词个数
self.word_count = len(corpus_idx) # 词典大小
self.num_words = self.word_count // self.num_chars # 句子数量
def __len__(self):
return self.num_words # 返回句子数量
def __getitem__(self, idx):
start = min(max(0, idx ), self.word_count - self.num_chars - 1) # 当前样本起始索引
end = start + self.num_chars # 当前样本结束索引
input_seq = torch.tensor(self.corpus_idx[start:end]) # 输入序列
target_seq = torch.tensor(self.corpus_idx[start + 1:end + 1]) # 目标序列,向后移动一个词
return input_seq, target_seq
class TextGeneratorRNN(nn.Module):
def __init__(self, unique_word_count):
super(TextGeneratorRNN, self).__init__()
self.embedding = nn.Embedding(unique_word_count, 128) # 词嵌入层
self.rnn = nn.RNN(128, 256, 1) # RNN层
self.dropout = nn.Dropout(0.2)
self.fc = nn.Linear(256, unique_word_count) # 全连接层
def forward(self, x, hidden):
x = self.embedding(x) # 词嵌入 格式:(batch句子的数量,句子长度,每个词的维度)
out, hidden = self.rnn(x.transpose(0, 1), hidden) # RNN计算 格式:(句子长度, batch句子的数量,隐藏状态维度)
out = self.dropout(out)
out = out.reshape(shape=(-1, out.shape[-1])) # 调整输出形状
out = self.dropout(out)
out = self.fc(out) # 全连接层
return out, hidden
def init_hidden(self, batch_size):
return torch.zeros(1, batch_size, 256) # 初始化隐藏状态
def train():
unique_words, word2idx, vocab_size, corpus_idx = build_vocab()
lyrics_dataset = LyricsDataset(corpus_idx, 32)
dataloader = DataLoader(lyrics_dataset, batch_size=32, shuffle=True)
model = TextGeneratorRNN(vocab_size).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.0001)
num_epochs = 100
for epoch in range(num_epochs):
model.train()
start_time = time.time()
for inputs, targets in dataloader:
hidden = model.init_hidden(inputs.size(0)).to(device) # 初始化隐藏状态
inputs, targets = inputs.to(device), targets.to(device)
outputs, hidden = model(inputs, hidden)
targets = torch.transpose(targets, 0, 1).reshape(shape=(-1, )) # 调整目标形状
loss = criterion(outputs, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}, Time: {time.time() - start_time:.2f}')
torch.save(model.state_dict(), 'model/lyrics_rnn_model.pth')
def evaluate(start_word, sentence_len):
unique_words, word2idx, vocab_size, corpus_idx = build_vocab()
model = TextGeneratorRNN(vocab_size).to(device)
model.load_state_dict(torch.load('model/lyrics_rnn_model.pth'))
model.eval()
hidden = model.init_hidden(1).to(device)
word_idx = word2idx[start_word] # 获取起始词
generate_sentence = [word_idx] # 产生词的索引
for i in range(sentence_len):
output, hidden = model(torch.tensor([[word_idx]]).to(device), hidden)
word_idx = torch.argmax(output) # 获取概率最大的词的索引
generate_sentence.append(word_idx) # 把预测结果添加到列表中
for idx in generate_sentence:
print(unique_words[idx], end=' ')
if __name__ == '__main__':
# unique_words, word2idx, vocab_size, corpus_idx = build_vocab()
# print(f'词典大小: {vocab_size}')
# dataset = LyricsDataset(corpus_idx, num_chars=5)
# print(f'<UNK>: {len(dataset)}')
# train()
evaluate(start_word='星星', sentence_len=50)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号