卷积神经网络(CNN)
卷积神经网络(CNN)
卷积神经网络(CNN)概述
卷积神经网络是深度学习在计算机视觉领域的突破性成果,专门用于处理图像、视频、语音等具有网格结构数据的神经网络。
在计算机视觉领域,输入的图像通常较大,使用全连接网络会产生巨大的计算代价。此外,全连接网络难以有效保留图像的空间特征,导致图像处理的准确率不高。
卷积神经网络(Convolutional Neural Network)是含有卷积层的神经网络。卷积层的主要作用是自动学习和提取输入数据的局部特征。
典型的CNN网络主要由三部分构成:卷积层、池化层和全连接层:
- 卷积层:负责提取图像中的局部特征
- 池化层:用来大幅降低参数量级(降维)
- 全连接层:类似传统神经网络,用于输出最终结果
卷积神经网络应用领域
- 图像分类:识别图像中的物体类别(如猫、狗、车辆等)
- 目标检测:检测图像中物体的位置和类别(如YOLO、Faster R-CNN)
- 图像分割:将图像分成多个区域,用于语义分割或实例分割
- 人脸识别:识别和验证图像中的人脸身份
- 医学图像分析:检测医学图像中的异常(如肿瘤检测、骨折识别)
- 自动驾驶:识别交通标志、车辆、行人等道路元素
- 自然语言处理:文本分类、情感分析(使用一维卷积)
卷积层
卷积层(Convolutional Layer)通过卷积操作提取输入数据中的局部特征(如边缘、纹理、形状等)。卷积层利用卷积核(滤波器)对输入进行处理,生成特征图(feature map)。通过堆叠多个卷积层,网络能够从低级特征(边缘)逐渐提取到高级特征(物体形状)。
卷积层的主要作用如下:
- 特征提取:从输入数据中提取不同层次的特征
- 权重共享:同一个卷积核在整个输入上共享权重,大幅减少参数数量
- 局部连接:每个神经元只与输入的一个小区域连接,符合图像的空间结构特性
- 平移不变性:由于权重共享,卷积层对物体位置变化具有一定的鲁棒性
卷积计算
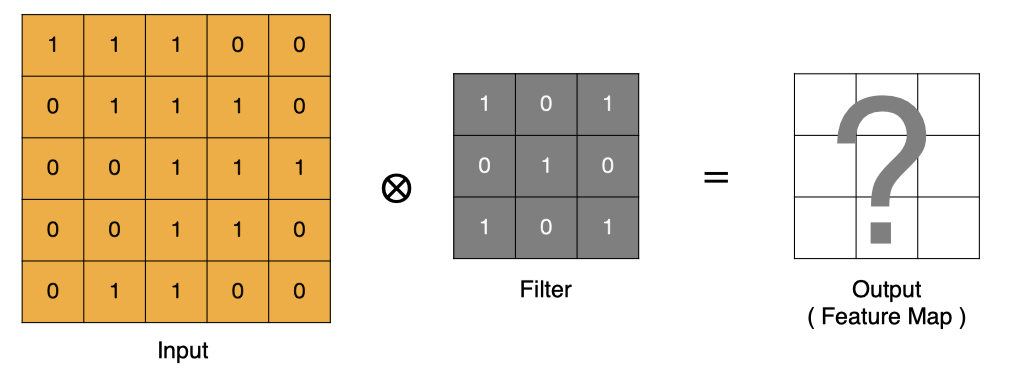
-
input 表示输入的图像
-
filter 表示卷积核, 也叫做滤波器(滤波矩阵)
- 一组固定的权重,因为每个神经元的多个权重固定,所以又可以看做一个恒定的滤波器filter
- 非严格意义上来讲,下图中红框框起来的部分便可以理解为一个滤波器,即带着一组固定权重的神经元。多个滤波器叠加便成了卷积层
- 一个卷积核就是一个神经元
-
input 经过 filter 得到输出为最右侧的图像,该图叫做特征图
卷积运算本质上就是在滤波器和输入数据的局部区域间做点积。
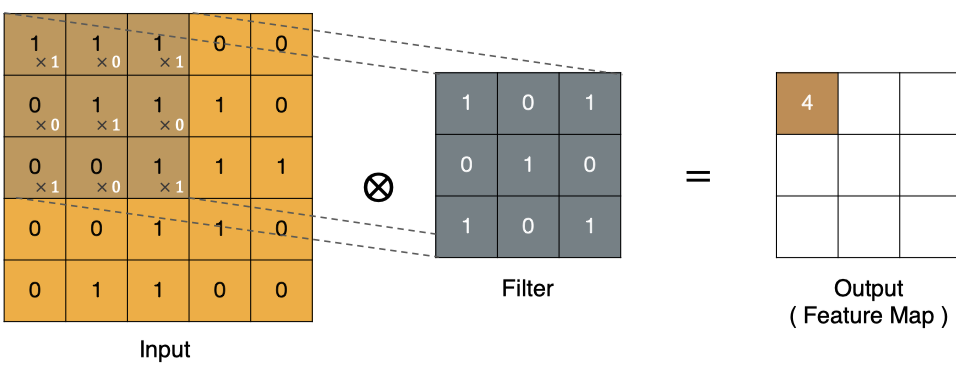
左上角的点计算方法:
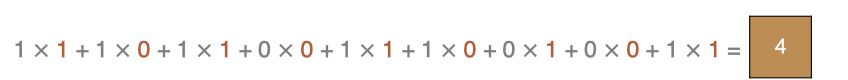
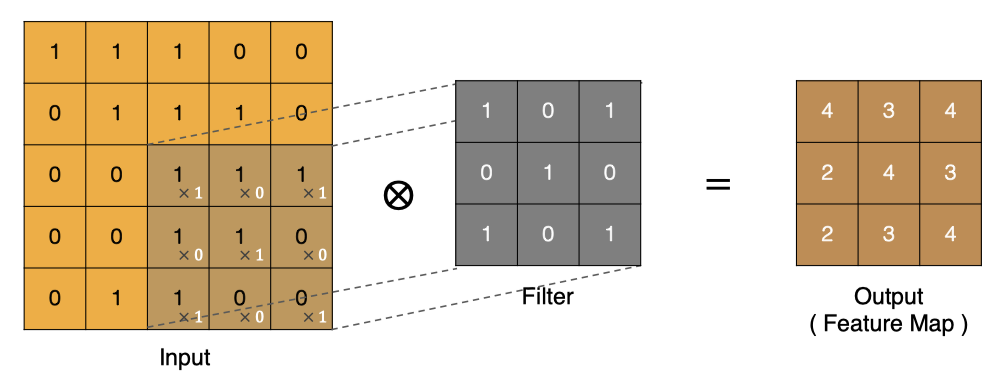
按照上面的计算方法可以得到最终的特征图为:
图像上的卷积:
在下图对应的计算过程中,输入是一定区域大小(width*height)的数据,和滤波器filter(带着一组固定权重的神经元)做内积后得到新的二维数据。
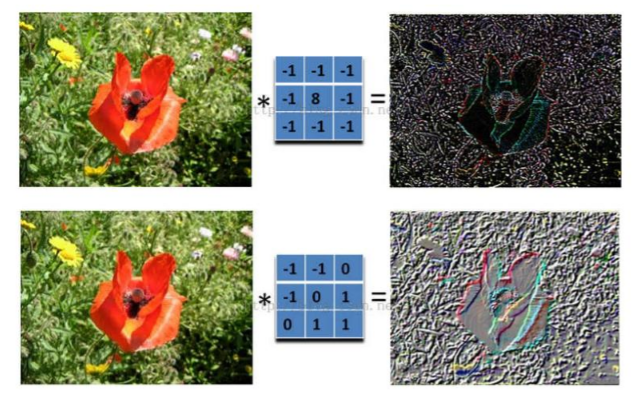
具体来说,左边是图像输入,中间部分就是滤波器filter(带着一组固定权重的神经元),不同的滤波器filter会得到不同的输出数据,比如颜色深浅、轮廓。相当于如果想提取图像的不同特征,则用不同的滤波器filter,提取想要的关于图像的特定信息:颜色深浅或轮廓。
Padding(填充)
通过上面的卷积计算过程,最终的特征图比原始图像小很多,如果想要保持经过卷积后的图像大小不变, 可以在原图周围添加 Padding 来实现。Padding是在输入特征图边界周围添加额外像素(通常为0)的操作。
Padding的主要作用:
- 保持空间维度:防止多次卷积后特征图尺寸过小
- 保留边缘信息:增加边缘像素在卷积中的参与度
- 控制输出尺寸:灵活调整特征图大小
Padding的类型:
- Valid Padding(无填充):不添加填充,输出尺寸小于输入
- Same Padding:添加填充使输出尺寸与输入相同
- Full Padding:添加足够填充使卷积核能覆盖输入边缘多次
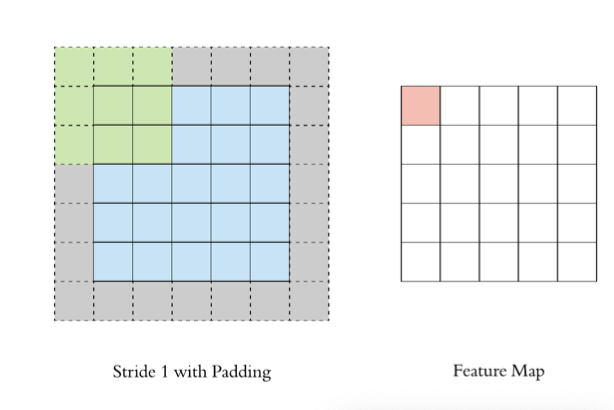
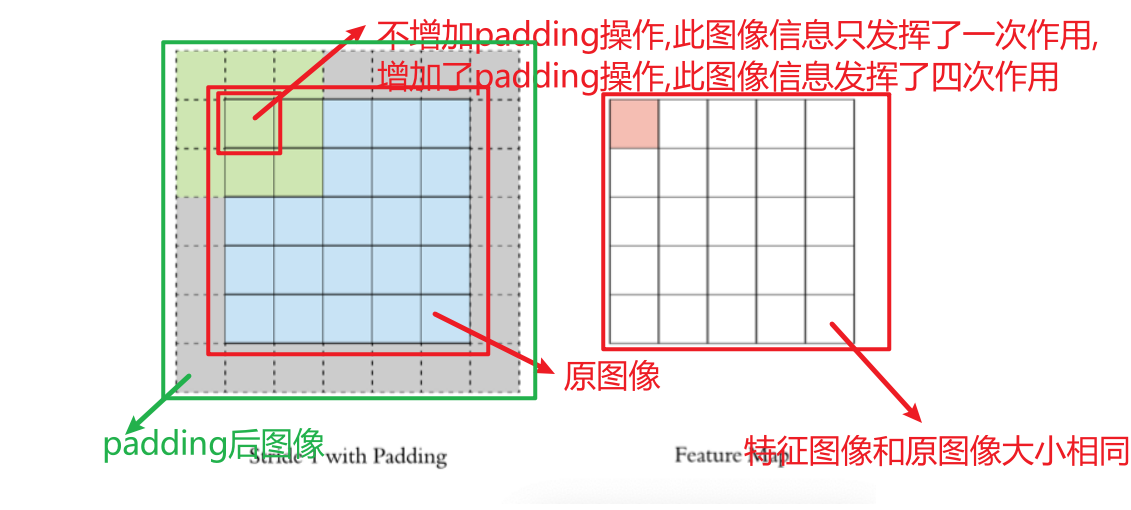
Stride(步长)
Stride是卷积核在输入上滑动时的移动步长。
Stride的影响:
- 控制输出尺寸:步长越大,输出特征图尺寸越小
- 降低计算复杂度:大步长减少计算量,加速训练和推理
- 增大感受野:大步长使每个神经元感受更大输入区域
Stride的选择:取决于具体的应用场景和网络架构
- Stride = 1: 这是最常见的设置,尤其是在网络的早期层。它允许保留更多的空间细节。
- Stride > 1: 通常用于减小特征图的尺寸和增大感受野,例如在网络的后期层或需要进行快速降维时。 常见的设置包括 stride=2 或 stride=4。
按照步长为1来移动卷积核,计算特征图如下所示:

如果把Stride增大为2,也是可以提取特征图的,如下图所示:

多通道卷积计算
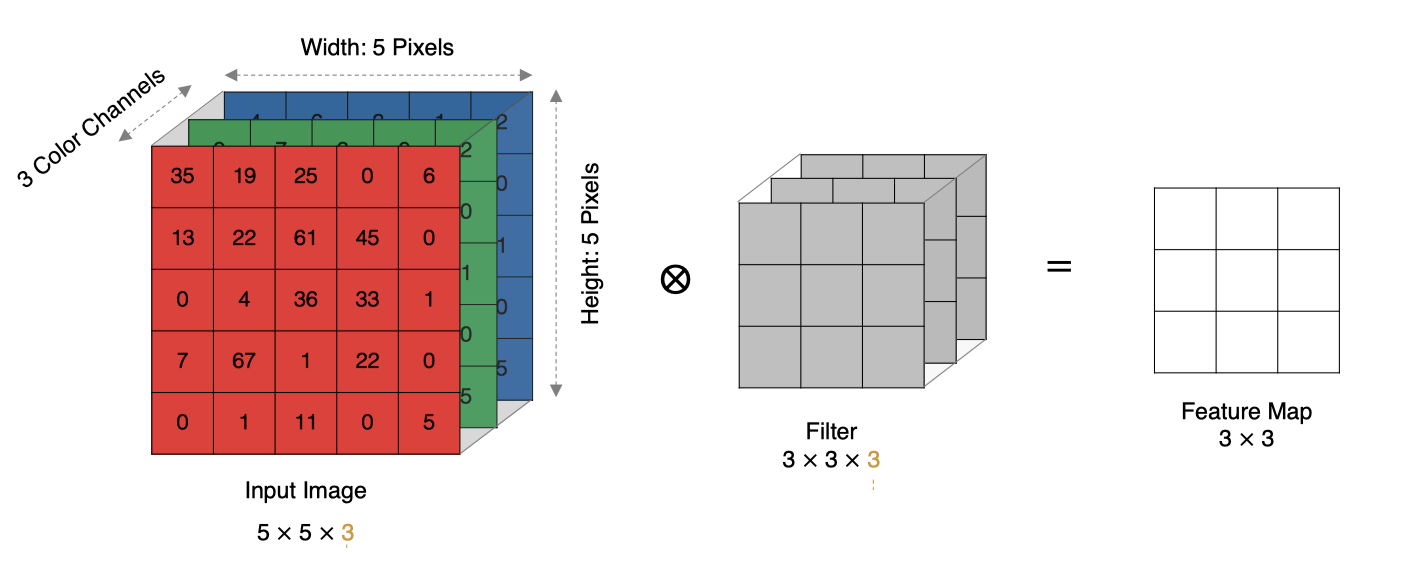
当输入有多个通道(如RGB图像的3个通道)时:
- 卷积核需要与输入通道数相同
- 每个卷积核通道与对应输入通道分别卷积
- 将所有通道的卷积结果相加得到单个输出特征图
如下图所示:
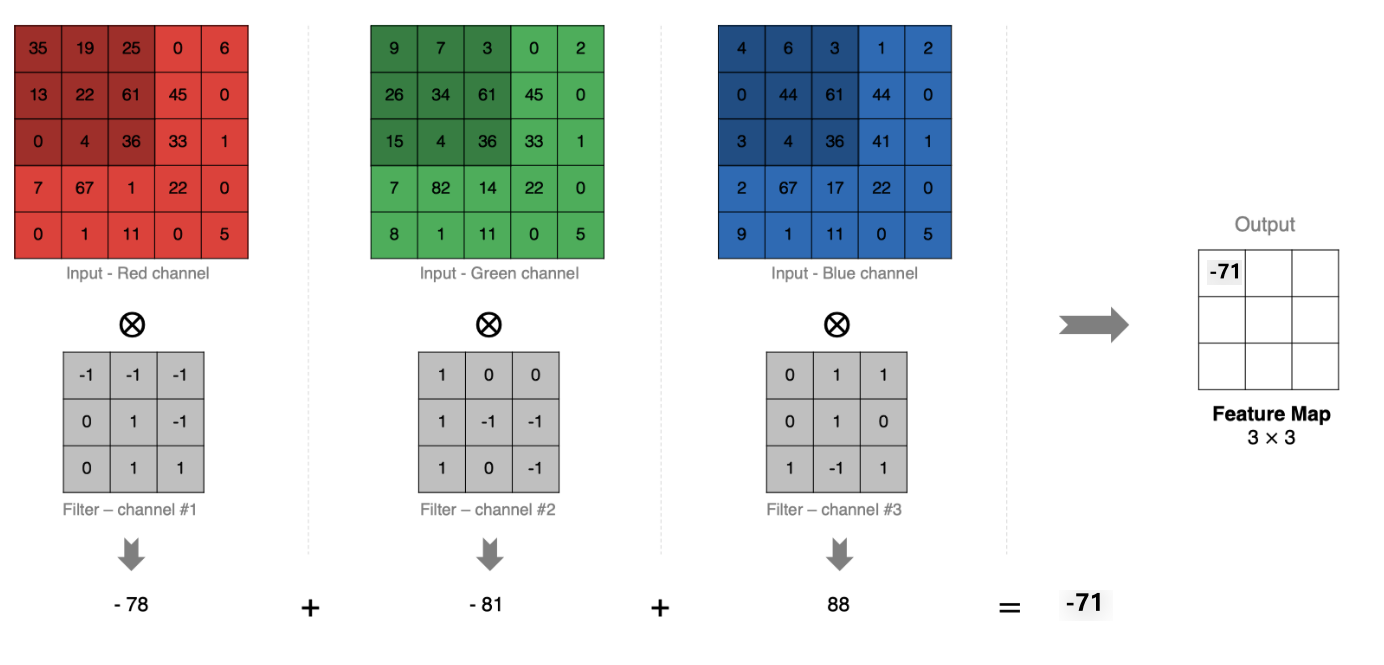
多卷积核卷积计算
上面的例子里我们只使用一个卷积核进行特征提取, 实际对图像进行特征提取时, 我们需要使用多个卷积核进行特征提取. 这个多个卷积核可以理解为从不同到的视角、不同的角度对图像特征进行提取.
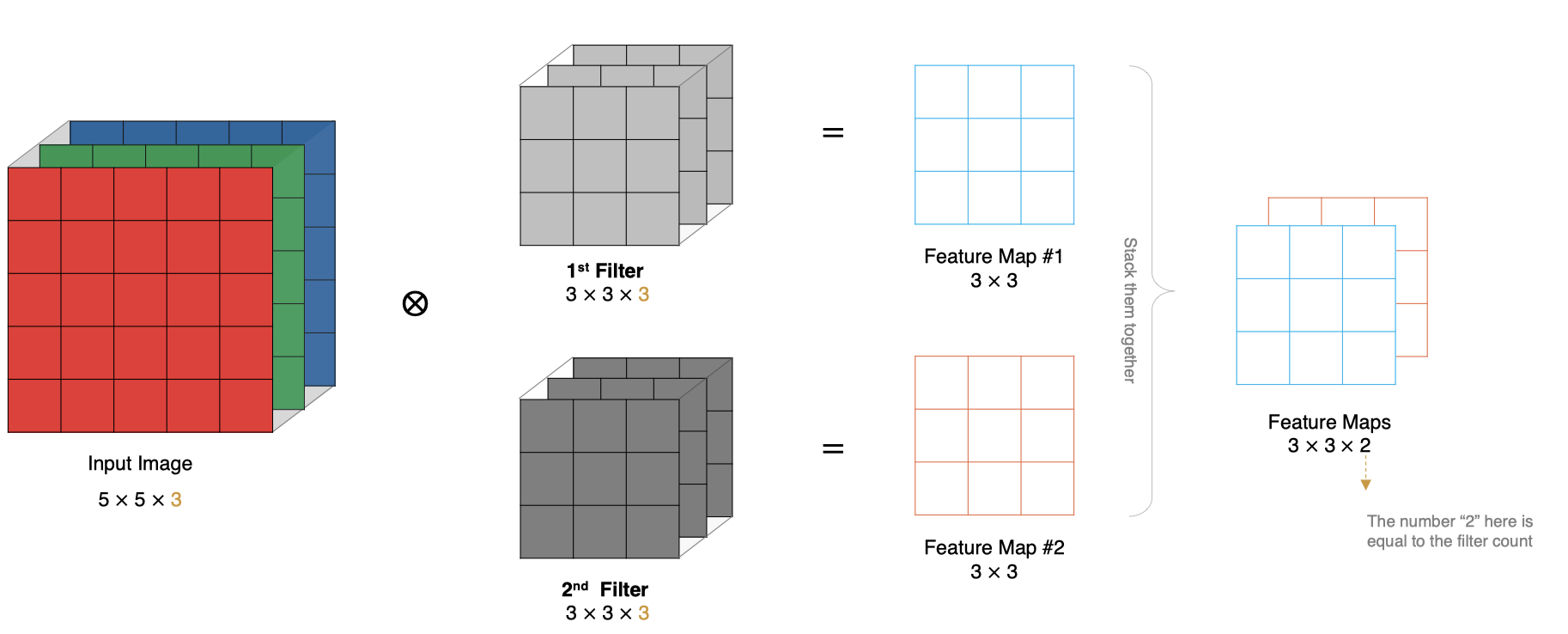
-
设输入特征图大小为 \(W \times W\),卷积核大小为 \(F \times F\),步长为 \(S\),填充为 \(P\),则输出特征图大小 \(N \times N\) 为:
\[N = \left\lfloor \frac{W - F + 2P}{S} \right\rfloor + 1 \]其中 \(\lfloor \cdot \rfloor\) 表示向下取整。
对于非正方形输入和卷积核,分别计算高度和宽度:
- 输入尺寸:\(H_{in} \times W_{in}\)
- 卷积核尺寸:\(K_h \times K_w\)
- 步长:\(S_h \times S_w\)
- 填充:\(P_h \times P_w\)
输出尺寸为:
\[H_{out} = \left\lfloor \frac{H_{in} - K_h + 2P_h}{S_h} \right\rfloor + 1 \]\[W_{out} = \left\lfloor \frac{W_{in} - K_w + 2P_w}{S_w} \right\rfloor + 1 \]
PyTorch卷积层API
在PyTorch中进行卷积的API是:
conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
"""
参数说明:
in_channels: 输入通道数,RGB图片一般是3
out_channels: 输出通道,也可以理解为卷积核kernel的数量
kernel_size:卷积核的高和宽设置,一般为3,5,7...
stride:卷积核移动的步长
整数stride:表示在所有维度上使用相同的步长 stride=2 表示在水平和垂直方向上每次移动2个像素
元组stride: 允许在不同维度上设置不同的步长 stride=(2, 1) 表示在水平方向上步长为2,在垂直方向上步长为1
padding:在四周加入padding的数量,默认补0
padding=0:不进行填充。
padding=1:在每个维度上填充 1 个像素(常用于保持输出尺寸与输入相同 padding=输入形状大小-输出形状大小)。
padding='same'(从 PyTorch 1.9+ 开始支持):让输出特征图的尺寸与输入保持一致。PyTorch会自动计算需要的填充量。stride必须等于1,不支持跨行,因为计算padding时可能出现小数
padding=kernel_size-1:Full Padding 完全填充
"""
img = plt.imread("data/img.png")
print(img.shape) # (640, 640, 3)
# plt.imshow(img)
# plt.show()
# 卷积层 参数1:输入通道数 参数2:输出通道数,即kernel数量 参数3:卷积核大小 参数4:步长 参数5:填充
conv = nn.Conv2d(in_channels=3, out_channels=4, kernel_size=3, stride=1, padding=0)
# tensor -> HWC -> CHW -> NCHW N 是 batch size,即样本数量
img_tensor = torch.from_numpy(img).permute(2, 0, 1).unsqueeze(0).float()
print("input tensor shape:", img_tensor.shape)
out = conv(img_tensor) # 计算公式: (W−K+2P)/S+1
print("output tensor shape:", out.shape)
# 查看特征图
out_img = out.squeeze(0).permute(1, 2, 0).detach().numpy()
print("output image shape:", out_img.shape) # (638, 638, 3)
plt.imshow(out_img[:, :, 0]) # 只看第一个通道
plt.show()
池化层
池化层(Pooling Layer)用于降低特征图的空间维度,减少计算量、内存消耗,并提高模型对输入变化的鲁棒性。
池化层通常位于卷积层之后,它通过对卷积层输出的特征图进行下采样,保留最重要的特征信息,同时丢弃一些不重要的细节。
池化层的主要作用:
-
降维和减少计算量:缩小特征图尺寸,降低后续层计算复杂度
-
提高模型鲁棒性:对输入的小变化、平移和旋转不敏感
-
防止过拟合:减少参数数量,降低模型复杂度
-
特征抽象:提取更高级、更抽象的特征表示
池化层计算
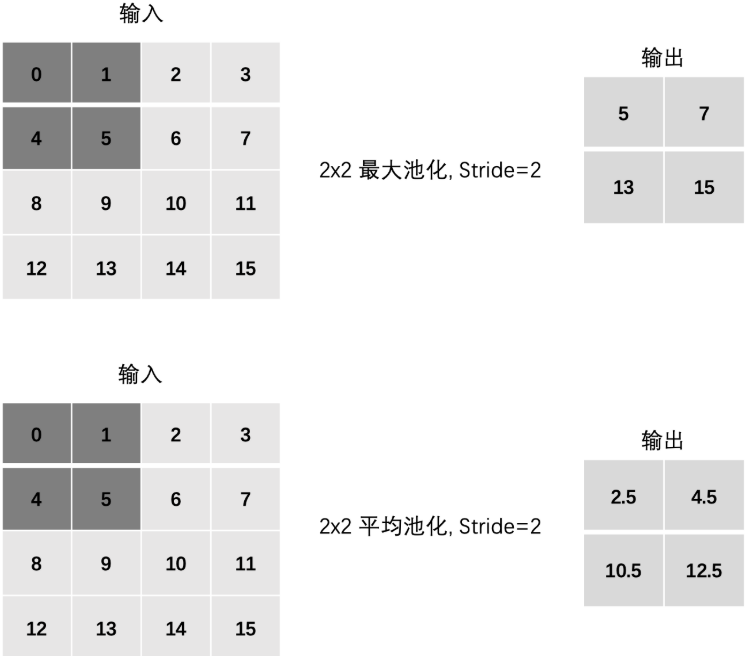
- 最大池化(Max Pooling) :通过池化窗口进行最大池化,取窗口中的最大值作为输出

- 平均池化(Avg Pooling) :取窗口内的所有值的均值作为输出
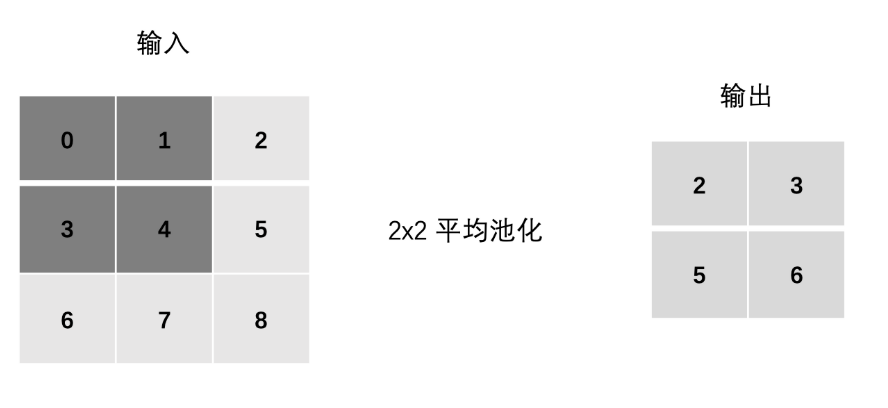
Padding(填充)
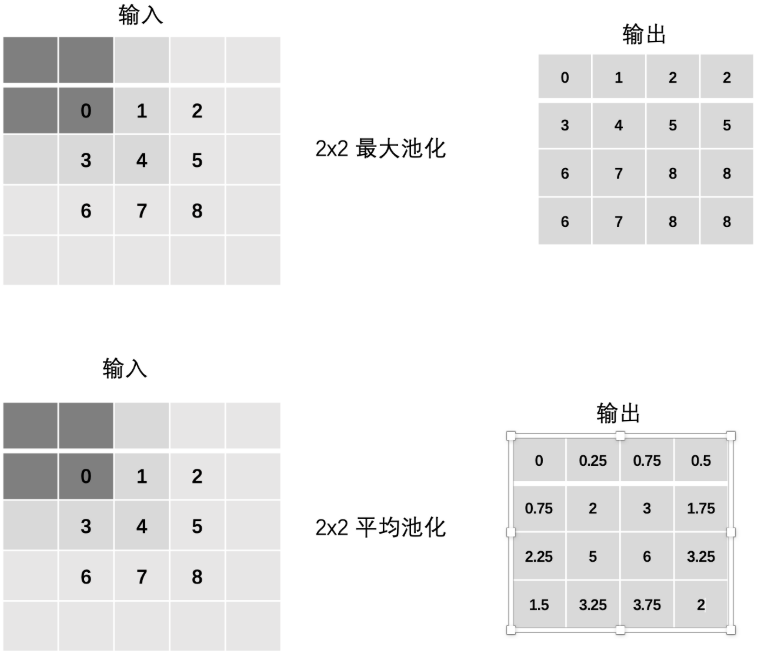
Stride(步长)
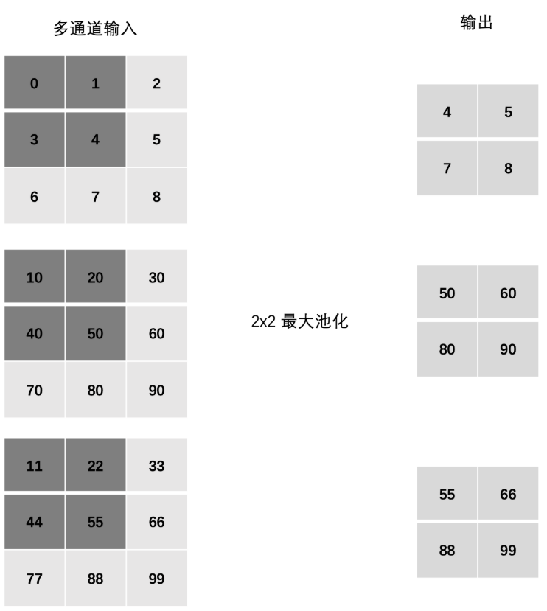
多通道池化计算
池化层独立处理每个输入通道:
- 输入通道数 = 输出通道数
- 每个通道分别进行池化操作
- 不跨通道混合信息
PyTorch池化层API
在PyTorch中进行池化的API是:
# 最大池化
nn.MaxPool2d(kernel_size=2, stride=2, padding=1)
# 平均池化
nn.AvgPool2d(kernel_size=2, stride=1, padding=0)
"""
参数说明:
kernel_size:核的高和宽设置,一般为3,5,7...
stride:核移动的步长
padding:在四周加入padding的数量,默认补0
"""
inputs = torch.tensor([[[1, 2, 3], [4, 5, 6], [7, 8, 9]]]).float() # shape: (1, 3, 3) 多通道可改 (3, 3, 3)
pool = nn.MaxPool2d(2, 1, 0) # kernel_size=2, stride=1, padding=0
out = pool(inputs)
print("最大池化:", out)
pool = nn.AvgPool2d(2, 1, 0)
out = pool(inputs)
print("平均池化:", out)
CNN案例
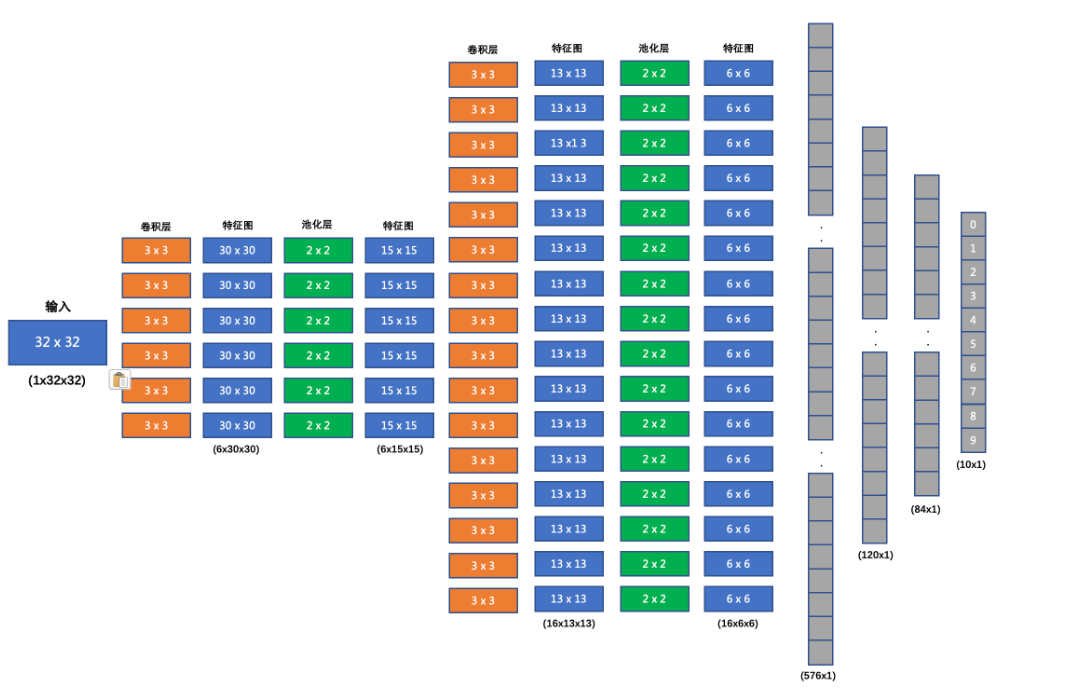
搭建的网络结构如下:
- 输入形状: 32x32
- 第一个卷积层输入 3 个 Channel, 输出 6 个 Channel, Kernel Size 为: 3x3
- 第一个池化层输入 30x30, 输出 15x15, Kernel Size 为: 2x2, Stride 为: 2
- 第二个卷积层输入 6 个 Channel, 输出 16 个 Channel, Kernel Size 为 3x3
- 第二个池化层输入 13x13, 输出 6x6, Kernel Size 为: 2x2, Stride 为: 2
- 第一个全连接层输入 576 维, 输出 120 维
- 第二个全连接层输入 120 维, 输出 84 维
- 最后的输出层输入 84 维, 输出 10 维
我们在每个卷积计算之后应用 relu 激活函数来给网络增加非线性因素。
"""
CNN:图像分类
"""
import torch
import torch.nn as nn
from torchvision.datasets import CIFAR10
from torchvision.transforms import ToTensor
import torch.optim as optim
from torch.utils.data import DataLoader
import time
import matplotlib.pyplot as plt
from torchsummary import summary
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
BATCH_SIZE = 8 # 批次大小
def create_dataset():
# 下载CIFAR10数据集 参数1:存放路径 参数2:是否为训练集 参数3:转换为tensor 参数4:是否下载
train_data = CIFAR10(root='data/', train=True, transform=ToTensor(), download=True)
test_data = CIFAR10(root='data/', train=False, transform=ToTensor(), download=True)
return train_data, test_data
class ImageModel_CNN(nn.Module):
def __init__(self):
super(ImageModel_CNN, self).__init__() # 调用父类的构造函数
# 卷积层(加权求和) + 激励层(激活函数) + 池化层(降采样)
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
)
self.conv2 = nn.Sequential(
nn.Conv2d(6, 16, 3, 1, 0),
nn.ReLU(),
nn.MaxPool2d(2, 2)
)
self.fc1 = nn.Linear(6 * 6 * 16, 120) # 全连接层
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10) # 输出10类
# 优化 dropout
self.dropout = nn.Dropout(p=0.5) # 随机失活50%的神经元
def forward(self, x):
x = self.conv1(x) # 相当于 x = self.pool(self.relu(self.conv(x)))
x = self.conv2(x)
# 全连接层需要输入二维张量 (batch_size, features)
# [8, 16, 6, 6] -> [8, 16*6*6] = [8, 576] ->8个样本,每个样本576个特征
x = x.view(x.size(0), -1) # 参数1: 样本数(行数) 参数2: 列数(特征数) -1表示自动计算
# 全连接层 + 激励层
x = torch.relu(self.fc1(x))
x = self.dropout(x) # dropout层
x = torch.relu(self.fc2(x))
x = self.dropout(x) # dropout层
x = self.fc3(x) # 最后一层不需要激活函数,交给损失函数处理CrossEntropyLoss
return x
def train(train_data):
dataloader = DataLoader(train_data, batch_size=BATCH_SIZE, shuffle=True)
model = ImageModel_CNN().to(device)
criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001)
num_epochs = 100
start = time.time()
for epoch in range(num_epochs):
model.train() # 训练模式
running_loss = 0.0
start_time = time.time()
for i, data in enumerate(dataloader):
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs) # 前向传播
loss = criterion(outputs, labels) # 计算损失
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播
optimizer.step() # 更新参数
running_loss += loss.item()
if i % 1000 == 999: # 每1000个小批量输出一次loss
print(f'[Epoch {epoch + 1}, Batch {i + 1}] loss: {running_loss / 1000:.3f}')
running_loss = 0.0
end_time = time.time()
print(f'Epoch {epoch + 1} completed in {end_time - start_time:.2f} seconds')
end = time.time()
print(f'Training finished in {end - start:.2f} seconds')
torch.save(model.state_dict(), 'model/image_cnn_model.pth')
def evaluate(test_data):
dataloader = DataLoader(test_data, batch_size=BATCH_SIZE, shuffle=True)
model = ImageModel_CNN().to(device)
model.load_state_dict(torch.load('model/image_cnn_model.pth'))
model.eval() # 评估模式
correct = 0
total = 0
with torch.no_grad(): # 评估时不需要计算梯度
for data in dataloader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = model(images)
# 由于训练中使用了CrossEntropyLoss损失函数,搭建神经网络时最后一层没有使用softmax激活函数, 要使用torch.max获取预测结果
_, predicted = torch.max(outputs.data, 1) # 获取预测结果
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'Accuracy of the model on the test images: {100 * correct / total:.2f}%')
if __name__ == '__main__':
# train_data, test_data = create_dataset()
# print("训练集:", train_data.data.shape) # (50000, 32, 32, 3)
# print("测试集:", test_data.data.shape) # (10000, 32, 32, 3)
# # 类别名称: ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
# print(f'类别数量: {len(train_data.classes)} 类别名称: {train_data.classes}')
# plt.imshow(train_data.data[0]) # 显示第一张图片
# plt.title(f'类别: {train_data.classes[train_data.targets[0]]}')
# plt.show()
# model = ImageModel_CNN().to(device)
# summary(model, (3, 32, 32), batch_size=BATCH_SIZE, device=str(device)) # 输入图片尺寸为 (3, 32, 32)
train_data, test_data = create_dataset()
# train(train_data)
evaluate(test_data)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号