spark集群环境搭建
环境搭建
系统环境:
虚拟机*3
CentOS8系统
JDK环境安装:
虚拟机环境是CentOS8,java环境安装可以直接联网安装;直接运行命令
yum -y list java //查看Java版本列表
yum -y install java-1.8.0-openjdk* //安装java1.8.0版本所有包
这样也不用设置环境变量了。当然,有个缺点是,你现在不知道安装目录在哪。
如何知道我们的安装目录在哪呢,根据这篇博客就可以找到啦.
spark环境:
在官网下载的spark安装包,具体下载的见这里我用的是spark-3.1.1-bin-hadoop2.7.7-tgz,这里要说的是,spark是可以独立运行的,在不适用存储功能下是不需要hadoop支持的。
在路径上解压后,我们可以得到以下目录:

其中examples是官方给的一些例子,conf中是一些配置文件,jars中是一些外部依赖其中就有对scala的支持,Python中是用Python来启动spark的环境和入口,sbin是运行spark的入口。
其中需要修改两处配置,自然是打开conf,发现都是template为后缀的,我们要将其后缀去掉,变成有效文件。
我们要修改的是spark-evn.sh,这是启动时调用的配置文件,先去掉后缀
mv spark-evn.sh.template spark-evn.sh
vim spark-evn.sh
在最后添加三条配置:

第一个很明显是java安装路径,第二个是确定master是谁,这里我是将ip映射为主机名了(每台机器都要进行相同映射),可以在/etc/hosts中配置,第三个就是master端口配置了。
同样的方法去掉workers的后缀,并打开编辑,添加上worker的主机名

将配置好的spark拷贝给其他机器
这里因为有多台机器可以用shell命令进行循环拷贝:
for i in {2..3}; do scp -r /bigdata/spark-2.2.0-bin-hadoop2.7/ node-$i:/bigdata; done
完成以上操作就可以开始启动spark环境了。
在spark文件目录下运行:
sbin/start-all.sh
有兴趣的可以看看sbin中都有哪些脚本入口。
启动后我们可以输入
jsp
查看当前运行任务有哪些:

我这里一台主机即作为master又是worker,说明已经启动,在你所配置的worker的系统中智慧存在worker
在web中访问$masterIP:8080,masterIp为你配置的master的IP地址:
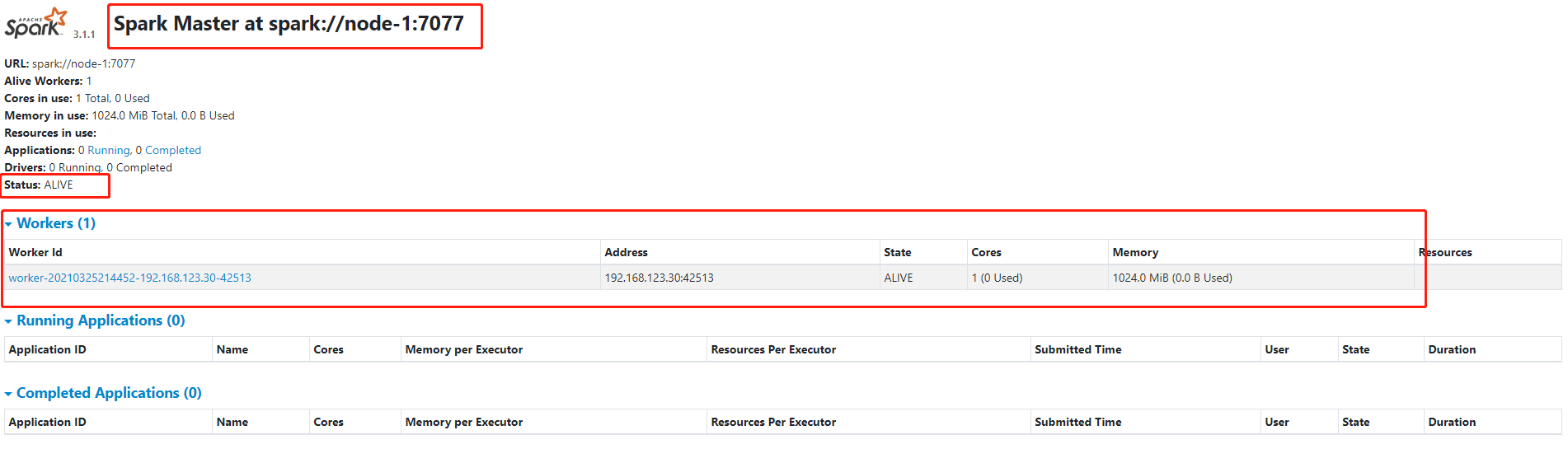
我这里只起来了一台机器,所以是一个worker,一般worker的个数是我们之前配置的worker的个数。这说明环境已经搭建好
免密配置
当然,你会发现你每次启动和关闭的时候都会让你验证每台机器的密码,在这里我们可以配置免密登录,见这篇博客
主要分为下面三步:
1、生成公钥:
ssh-keygen -t rsa
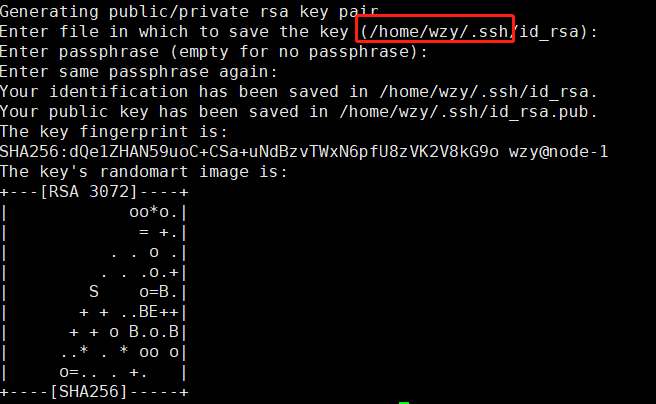
2、在存储文件的~/.ssh 目录下将公钥复制为authorized_keys文件
cp id_rsa.pub authorized_keys
3、将每台主机都进行以上操作
4、使用命令将本机的公钥拷贝到指定的文件中,
ssh-copy-id -i hostname
使用ssh hostname测试,可以免密登录了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号