关于Windows环境下安装spark的问题
最近刚入spark门,所以一切都要从零开始说,视频看的是B站尚硅谷的,说实话,视频没有从头开始,对于初学者很难把握,后面改成spark:从入门到实战;
言归正传,刚开始安装spark,因为一直用的Windows而且想用单机入手,所以安装的是Windows单机版,详细安装见Windows环境下的spark安装
安装之后,按照视频中的代码去写一个WordCount代码,然后一跑,就出问题了,报错为我没有配置hadoop的环境变量,首先我只装了spark没有装对应版本的hadoop导致运行不了HDFS,后面按照默认的下载了spark-3.1.1-bin-hadoop2.7.7-tgz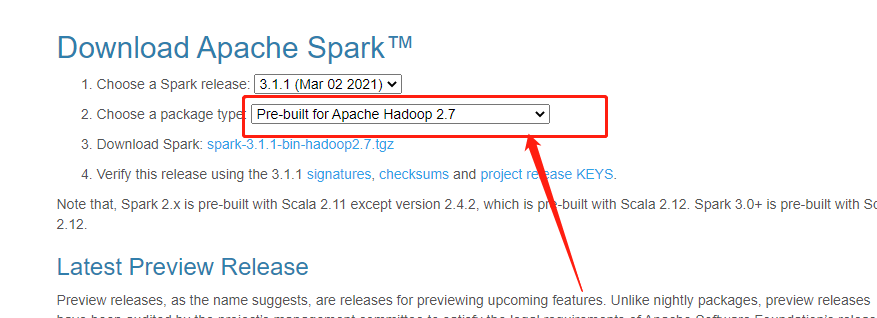
后面安装hadoop就按照这个版本安装的2.7的hadoopwindow下的hadoop安装,但是后面运行WordCount还是报错,错误变成启动spark报找不到可执行的hadoop winutils.exe,然后我又去找winutils下载下来直接替换hadoop中的bin文件包,在这里值得一说的我hadoop2.7.7版本,发现竟然没有对应版本的,那就取2.7.1吧,发现有点问题,然后就取2.8.0发现hadoop像他们描述的一样,应该是没什么问题了,但是WordCount还是报错如下:

在网上疯狂寻求答案,说是winutils和hadoop.dll版本不一致导致的,各种说法都试了一遍方法一、方法二,最后发现还是没有啥用,最后发现小丑竟是我自己,在方法二中人家就提到pom文件中的hadoop版本号和Windows下的hadoop是否一致;我在idea中的外部依赖包中看到hadoop版本竟然是3.2.0!,那只能把hadoop版本换一换了,但是得下好久hadoop依赖包
我还是太年轻,跟着尚硅谷的视频走,走着走着就丢了,后面在从入门到实战发现,hadoop版本直接在pom文件中约束就可以了。浪费我宝贵的时间,这焦急的智商。只能说还是太年轻了。最重要的还是要版本之间的对应关系,包括前面安装scala版本,竟然发现依赖找不到2.13的包后面只能将scala版本降为2.12的。在各种框架和软件配合使用的情况下还是要多注意版本之间的匹配。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号