
爬虫作业
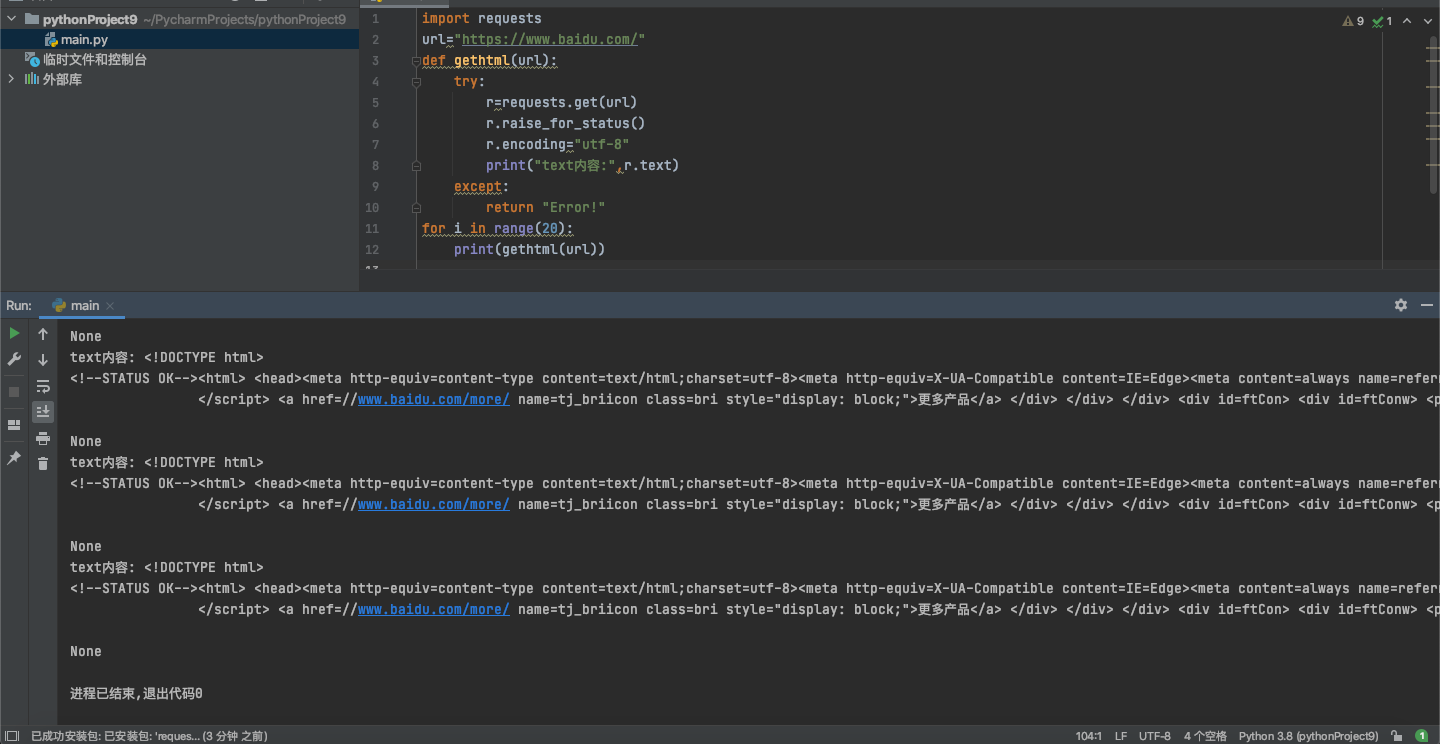
请用requests库的get()函数访问如下一个网站20次,打印返回状态,text()内容,计算text()属性和content属性所返回网页内容的长度。
1 import requests 2 url="https://www.baidu.com/" 3 def gethtml(url): 4 try: 5 r=requests.get(url) 6 r.raise_for_status() 7 r.encoding="utf-8" 8 print("text内容:",r.text) 9 except: 10 return "Error!" 11 for i in range(20): 12 print(gethtml(url))
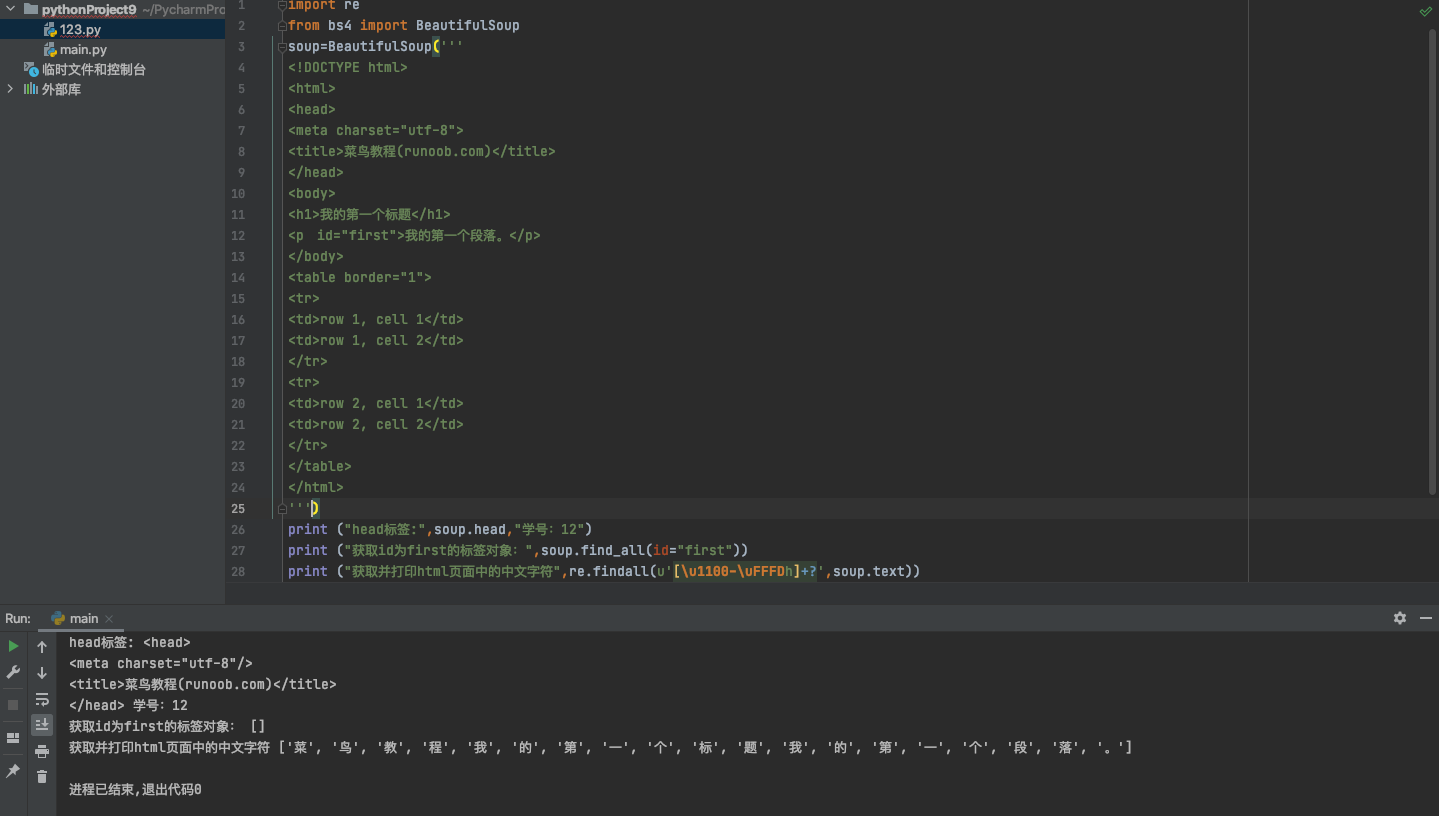
1 import re 2 from bs4 import BeautifulSoup 3 soup=BeautifulSoup(''' 4 <!DOCTYPE html> 5 <html> 6 <head> 7 <meta charset="utf-8"> 8 <title>菜鸟教程(runoob.com)</title> 9 </head> 10 <body> 11 <h1>我的第一个标题</h1> 12 <p id="first">我的第一个段落。</p> 13 </body> 14 <table border="1"> 15 <tr> 16 <td>row 1, cell 1</td> 17 <td>row 1, cell 2</td> 18 </tr> 19 <tr> 20 <td>row 2, cell 1</td> 21 <td>row 2, cell 2</td> 22 </tr> 23 </table> 24 </html> 25 ''') 26 print ("head标签:",soup.head,"学号:12") 27 print ("获取id为first的标签对象:",soup.find_all(id="first")) 28 print ("获取并打印html页面中的中文字符",re.findall(u'[\u1100-\uFFFDh]+?',soup.text))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号