
MySQL复制相关技术的简单总结
MySQL有很多种复制,至少从概念上来看,传统的主从复制,半同步复制,GTID复制,多线程复制,以及组复制(MGR)。
咋一看起来很多,各种各样的复制,其实从原理上看,各种复制的原理并无太大的异同。
每一种复制的出现都是有其原因的,是解决(或者说是弥补)前一种的复制方案的潜在的问题的。
新的复制方式的出现,是基于对原复制某一方面增强或者是优化的结果,而不是全新的一种方案或者技术,所以就不难理解为什么有这么多中复制。
其实搞出来这么多概念,个人觉得是源于开源的原因吧,不同复制版本的出现,因为是一个不断发现问题就解决问题的过程。
如果是闭源的数据库,你只管打补丁就行了,SP1,SP2,SP3……,应该不会出现这么多概念上的东西。
本文仅从原理上粗略总结各种复制技术的特点以及解决的问题,不涉及太多的细节问题。
MySQL复制的原理图(图片来源于深入浅出MySQL)
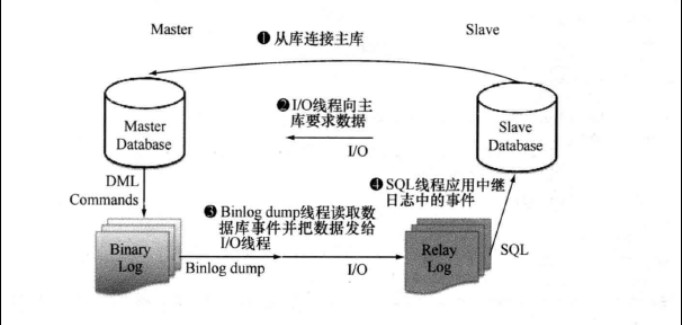
大致的流程如下:
1,搭建完主从之后,slave连接至master,slave的io_thread等待主库的binlog信息
2,master上执行各种DDL或者DML命令,执行完成执行生成binlog
3,master上的binlog_dump线程将生成的binlog传送给slave的slave的io_thread
4,slave的io_thread接受到master上的binlog之后将binlog写入本地的中继日志文件
5,slave本地的sql_thread应用中继日志到本地数据库中
传统的主从复制
对于传统的主从复制,Slave连接至master的典型操作如下,就是手工指定slave要从master的哪个文件的哪个点开始执行其二进制日志。
CHANGE MASTER TO MASTER_HOST='***.***.***.***', MASTER_USER='username', MASTER_PASSWORD='pwd', MASTER_PORT = 3306, MASTER_LOG_FILE='mysql-bin.000047', MASTER_LOG_POS=3112;
潜在的问题:
1,数据异步复制,master提交事物并不需要与slave确认,binlog以异步的方式传送到slave,很明显,潜在的问题就是如果master宕机,可能存在没有传递到slave的binlog,造成事物的丢失。
2,需要手工确认logfile以及logfile的偏移量
半同步复制
半同步复制最大的特点就是改进了传统的主从复制潜在的主从不一致的问题,
半同步复制要求master提交事务之后,等到至少一台slave接收到binlog并且成功写入到中继日志中才算返回给客户端成功提交的消息。
这样就确保了master上所有的事物,都可以传递至至少一个slave,master宕机的情况下并不会丢失事物,解决了传统复制潜在的问题1 ,但是问题2依旧。
潜在的问题:
1,依旧需要手工确认logfile以及logfile的偏移量
GTID复制
GTID是一个基于原始mysql服务器生成的一个已经被成功执行的全局事务ID,它由服务器ID以及事务ID组合而成。
这个全局事务ID不仅仅在原始服务器器上唯一,在所有存在主从关系 的mysql服务器上也是唯一的。
正是因为这样一个特性使得mysql的主从复制变得更加简单,以及数据库一致性更可靠。
典型的GTIDslave启动脚本如下
CHANGE MASTER TO
MASTER_HOST='***.***.***.***',
MASTER_PORT=3306,
MASTER_USER='repl',
MASTER_PASSWORD='repl',
master_auto_position = 1;
相对于传统的主从复制,或者是提高了安全性的半同步复制,在搭建主从,或者是改变主从的时候,
操作方式都是需要手动指定binlog的文件以及文件的偏移量,说白了就是人为地去判断slave应该从从master的哪个binlog中的哪个位置开始重放二进制日志中的内容。
这样势必会增加手动操作以及人为判断错误的可能性,不是太方便做主从或者故障转移操作。
相对传统的复制,GTID的优势:
1、更简单的搭建主从复制,以及实现故障转移,不用以前那样在需要手工指定log_file和log_pos。
2,正常情况下,GTID是连续没有空洞的,因此主从库出现数据冲突时,可以用添加空事物的方式进行跳过,跳过错误的事物更加方便。
多线程复制
半同步复制解决了传统复制潜在的slave丢失master事物的问题,GTID复制简化复制的实现,解决了传统复制过于复杂的的问题,算是原始复制的两个补丁。
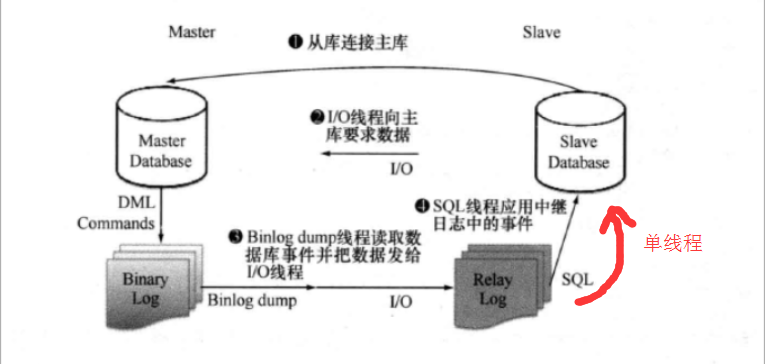
从安全性和复杂程度两个纬度改进了传统复制,但是传统复制依然潜在一个致命的问题,就是主从复制的延迟。
slave上的sql_thread应用中继日志到本地数据库中,是一个单线程的操作,这样面对大量的binlog,就可能存在效率上的问题,
多线程复制就是通过并行解析中继日志的方式,提要slave上sql_thread的执行效率,从而改善主从复制延迟的问题(当然也需要master的binlog做一定的优化)
MGR(MySQL Group Replication)
MGR,MySQL的组复制,不仅仅是复制的问题,可以认为是结合了传统的复制,半同步复制(机制不一样,多数节点同步提交),GTID复制等一系列特性的一种高可用解决方案,并且具备故障探测功能,自动检测并剔除发生了故障的节点
因此说是一种高可用以及高扩展的解决方案,而不仅仅是完成复制的功能。
对于MGR的一些特性,一下引用自https://blog.csdn.net/jssg_tzw/article/details/69791330
高一致性,基于原生复制及paxos协议的组复制技术,并以插件的方式提供,提供一致数据安全保证;
高容错性,只要不是大多数节点坏掉就可以继续工作,有自动检测机制,当不同节点产生资源争用冲突时,不会出现错误,按照先到者优先原则进行处理,并且内置了自动化脑裂防护机制;
高扩展性,节点的新增和移除都是自动的,新节点加入后,会自动从其他节点上同步状态,直到新节点和其他节点保持一致,如果某节点被移除了,其他节点自动更新组信息,自动维护新的组信息;
高灵活性,有单主模式和多主模式,单主模式下,会自动选主,所有更新操作都在主上进行;多主模式下,所有server都可以同时处理更新操作。
对于MGR,笔者仅简单做过测试,搭建起来一如跟普通的复制并无太大差异,并不复杂,网络上的评价也很高,大有一统各种第三方高可用技术的趋势。
缺点是出来的时间太短(MGR是是MySQL官方于2016年12月推出的,对于互联网来说,个人感觉超过已经不短了),可能存在这某些位置的问题。
总结
MySQL的复制,任何一种新方案的出现,其原理差异不大,都是为了解决前一种方案潜在的问题的,是作为前一种复制的提升或者说增强,开源没有完美的解决方案,但是有不断完善的解决方案,这不是开源的魅力之一吗?
不同的复制其技术细节上可能有差异,但是本质性的东西是一样的。
当然每一种复制都有其自身的细节上的特性,只能在实际应用中实践了。
这也不由得令人想到各种数据中的各种隔离级别(isolation),虽然不能完全做类比,与复制一样,每一种增强的隔离级别的,都是为解决前一种隔离级别中存在的问题而出现的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号