


SELECT TOP 1 比不加TOP 1 慢的原因分析以及SELECT TOP 1语句执行计划预估原理
本文出处:http://www.cnblogs.com/wy123/p/6082338.html
现实中遇到过到这么一种情况:
在某些特殊场景下:进行查询的时候,加了TOP 1比不加TOP 1要慢(而且是慢很多)的情况,
也就是说对于符合条件的某种的数据,查询1条(符合该条件)数据比查询所有(符合该条件)数据慢的情况,
这种情况往往只有在某些特殊条件下会出现,那么,就有两个问题:为什么加了TOP 1 会比不加TOP 1慢?这种“特殊条件”是什么条件?
本文将对此情况进行演示和原理分析,以及针对此种情况采用什么方法来解决。
按照一贯风格,先造一个测试环境:1000W+的数据
数据的特点为:
1,表中有一个状态列BusinessStatus ,这个列的分布为1,2,3,4,5
2,表中有一个 业务ID列BusinessId , BusinessId列是呈递增趋势
CREATE TABLE TestTOP ( Id INT IDENTITY(1,1) primary key, BusinessColumn VARCHAR(50), BusinessId INT, BusinessStatus TINYINT, CreateDate DATETIME ) GO
--5年的时间,一分钟六条数据的数据频率 DECLARE @i int = 0 WHILE @i<24*60*365*5 BEGIN INSERT INTO TestTOP VALUES (NEWID(),@i,RAND()*5+1, DATEADD(SS,@i,DATEADD(YEAR,-5,GETDATE()))) INSERT INTO TestTOP VALUES (NEWID(),@i,RAND()*5+1, DATEADD(SS,@i,DATEADD(YEAR,-5,GETDATE()))) INSERT INTO TestTOP VALUES (NEWID(),@i,RAND()*5+1, DATEADD(SS,@i,DATEADD(YEAR,-5,GETDATE()))) INSERT INTO TestTOP VALUES (NEWID(),@i,RAND()*5+1, DATEADD(SS,@i,DATEADD(YEAR,-5,GETDATE()))) INSERT INTO TestTOP VALUES (NEWID(),@i,RAND()*5+1, DATEADD(SS,@i,DATEADD(YEAR,-5,GETDATE()))) INSERT INTO TestTOP VALUES (NEWID(),@i,RAND()*5+1, DATEADD(SS,@i,DATEADD(YEAR,-5,GETDATE()))) SET @i=@i+1 END
另外,在此表中查询一小部分BusinessStatus=0的分布较少的数据,且分布在最大的BusinessId上,这里暂定为5000行,利用如下脚本生成
DECLARE @i int = 15768000 WHILE @i<15768000+5000 BEGIN INSERT INTO TestTOP VALUES (NEWID(),@i,0, DATEADD(SS,@i,GETDATE())) SET @i=@i+1 END
现在这个测试环境已经搭建完成,现在创建两个非聚集索引,一个是在BusinessStatus上,一个是在BusinessId
CREATE INDEX idx_BusinessStatus ON TestTOP(BusinessStatus) CREATE INDEX idx_BusinessId on TestTOP(BusinessId)
下面开始测试:
说明:1,以下测试,不用考虑缓存之类的因素,本机测试,内存也足够大,全部缓存这么点数据还是够的。也暂不分析IO具体值,粗看执行时间已经很明显了
2,读者要对SQL Server索引结构,统计信息,执行计划,执行计划预估等知识有一定的认识,否则很多理论上的东西就看的云里雾里
3,本文测试数据库为SQL Server 2012,SQL Server每个版本的预估算法可能都不一样,具体环境具体分析
SELECT TOP 1 比不加 TOP 1慢
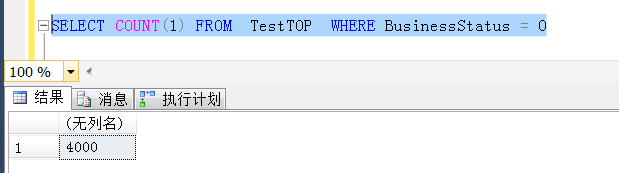
1,首先执行TOP 1 *的查询,耗时13秒

2,然后执行不加TOP 1 *的查询,也即SELECT * ,如下,耗时0秒(当然不是0秒,意思是很快就可以完成这个查询)

3,上面两个查询就可以重现第一个问题了,也就是说在当前这种查询条件下,TOP 1要比不加TOP 1慢很多
分析两者的执行计划:
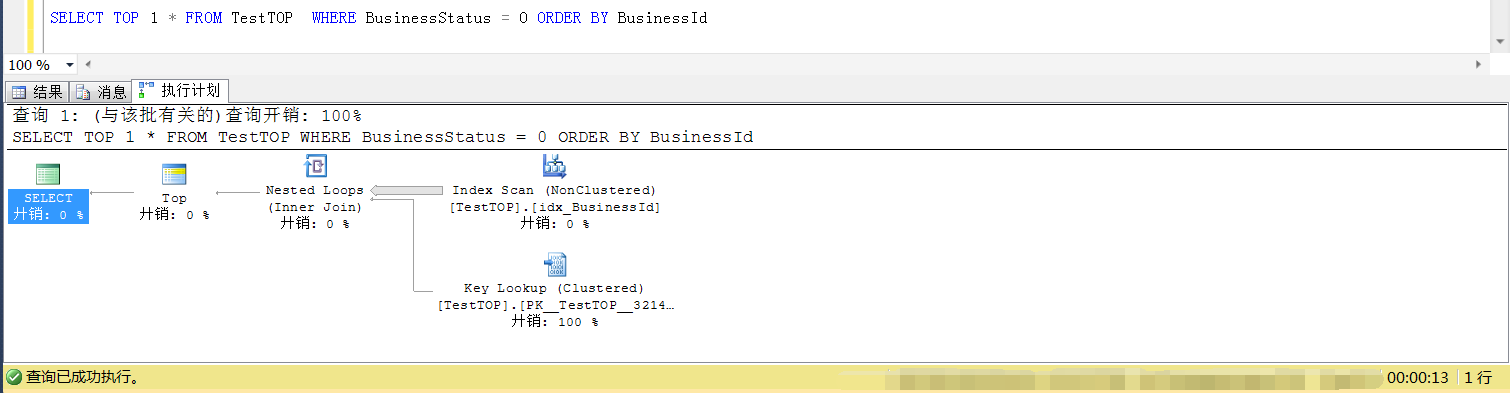
首先看加了 TOP 1 的执行计划:可以看到走的是idx_BusinessId的索引扫描
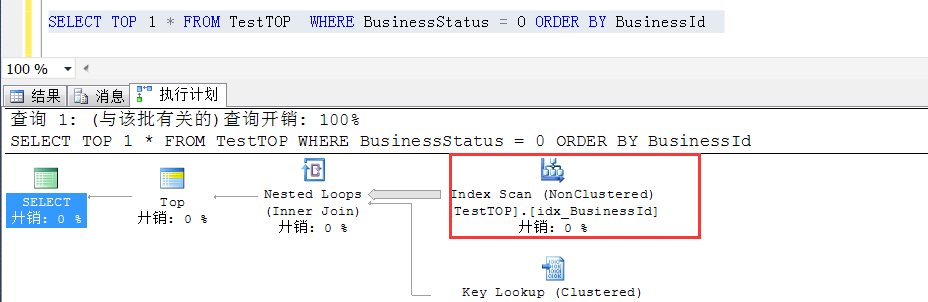
接着看不加TOP 1 的执行计划:可以看到走的是idx_BusinessStatus这个索引的索引查找

原因分析:
那么为什么加了TOP 1就走BusinessId列上的索引扫描,不加TOP 1就走BusinessStatus上的索引扫描?
因为在加了TOP 1之后,只要求返回一条数据,
优化器认为(应该说是误认为)可以很快找到符合条件的那条记录,采用了idx_BusinessId列上的索引扫描
由于数据的分布可知,符合BusinessStatus=0的BusinessId,是分布在BusinessId值最大的一小部分数据中,而BusinessId又是递增的,
也就是说复合条件的数据是集中分布在idx_BusinessId索引树的一个很小的特定区域,
采用的是与idx_BusinessId顺序一致的(ForWard顺序)索引扫描,有数据分布特点可知,一开始找到的绝大多数的BusinessId,都不是符合BusinessStatus=0的
以至于几乎要扫描整个idx_BusinessId索引树才能找到符合BusinessStatus=0条件的数据,因此效率就会很低
反观不加TOP 1的时候,因为是要找所有符合BusinessStatus=0的数据,优化器就索引采取了idx_BusinessStatus索引查找的方式,至此,原因大概是这样的。
问题到这里才刚刚开始
如果说上述推断不足以说明问题,那么我们继续看在加了TOP 1的时候,执行计划是怎么预估的?
继续观察加了TOP 1的时候的预估,发现此时走idx_BusinessId的索引扫描,预估行数为3154.6行,这个数字是怎么得到的?
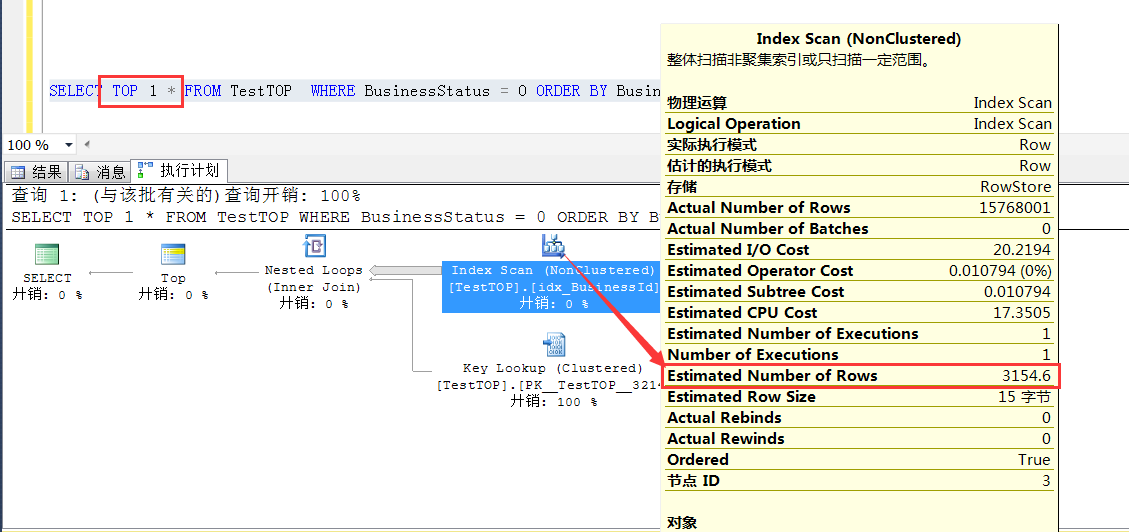
现在观察idx_BusinessStatus列上的统计信息,统计信息是100%取样的,先不考虑统计信息不准确的问题
因为在加了TOP 1的时候,优化器认为符合条件的数据是平均分布在整个表中的,
也就是说BusinessStatus=0的5000行数据是平均分布在15773000行数据中,查询条件又要求按照BusinessId正向排序,
那么干脆走BusinessId列上的索引扫描,(误以为)平均找15773000/5000 行数据,就可以找到一条(TOP 1)符合条件的数据
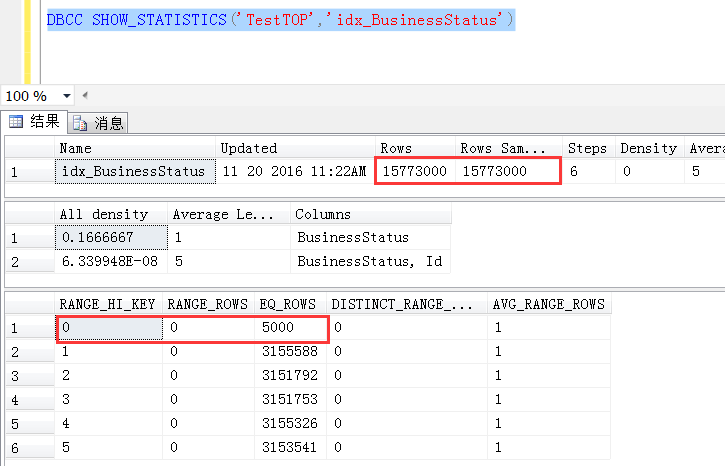
实际上是不是这样子呢?用总行数处于BusinessStatus=0的行数,与预估的值比较,都是3154.6呢?那么上面的推断也就是成立的
这里查询加了TOP 1比不加TOP 1慢的根本原因就是如下:
事实情况下是复合条件的数据分布是不均匀的,而优化器误以为符合条件的数据分布(在整张表中)是均匀的,
正是因为有了这么一个矛盾,所以在加了TOP 1 的时候,优化器采用非最优化的方式造成的。
继续测试 TOP N
为了证明上述推断,关于TOP的预估,我再补充一个小例子,希望各位看官能明白
当符合条件的数据(BusinessStatus=0)为15000行的时候,我们看看TOP 1与TOP 2,以及继续增加TOP N的值得预估的行数,就大概明白了
DECLARE @i int = 15768000 WHILE @i<15768000+15000 BEGIN INSERT INTO TestTOP VALUES (NEWID(),@i,0, DATEADD(SS,@i,GETDATE())) SET @i=@i+1 END
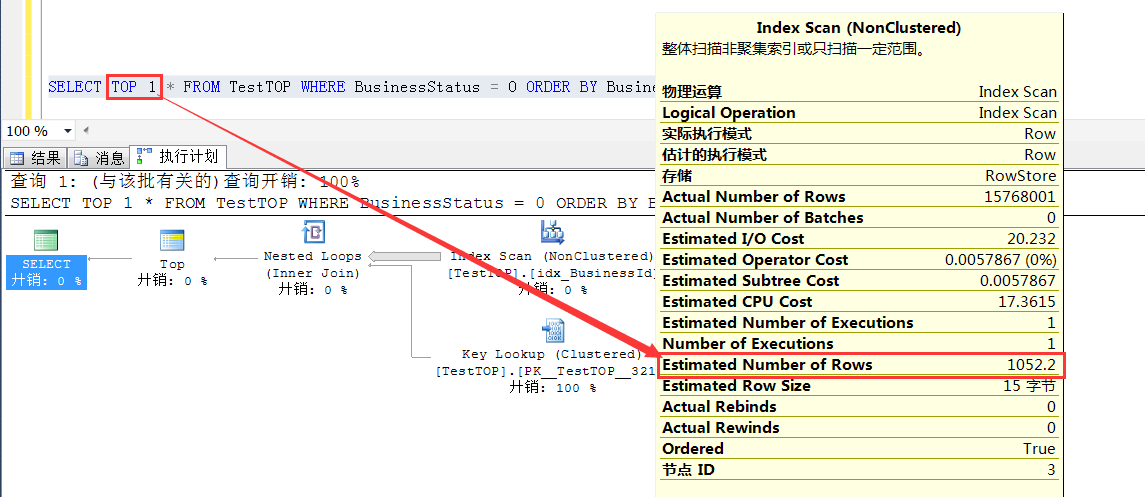
TOP 1 的预估1052.2 = 1 * RowCount/15000
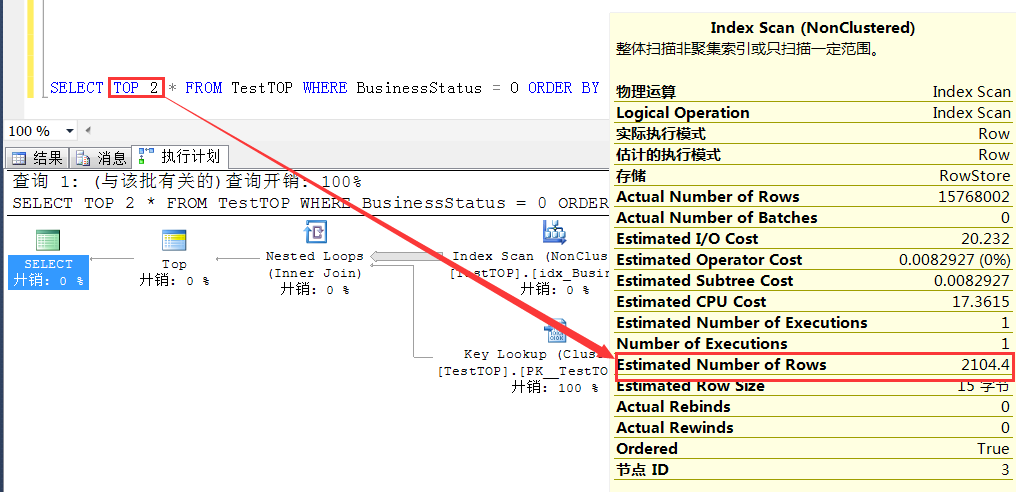
TOP 2的预估行数 2014.4 = 2 * RowCount/15000
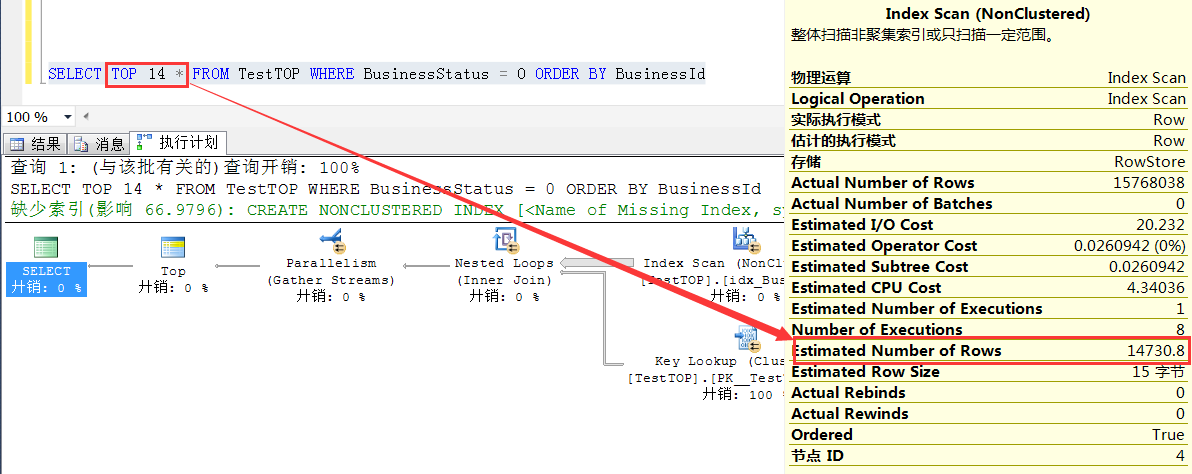
TOP 14 的预估行数 2014.4 = 14 * RowCount/15000
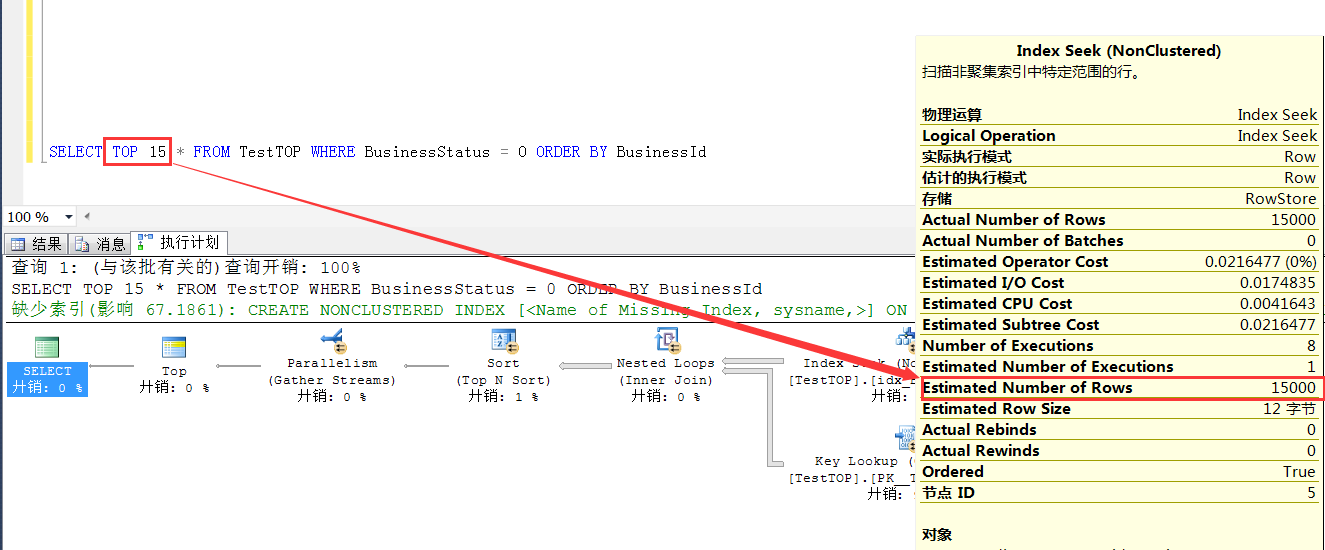
为什么TOP 15开始峰回路转,执行计划也变成index seek了,打破 N * RowCount/15000这个规律??请自行思考
优化器会根据预估返回行数,因为TOP 15的时候,预估行数 =15 * RowCount/15000 =15783.0 >15000 ,
优化器会回头选择一种他自己的预估方式较低的方式执行,选择一个它认为代价较小(预估行数较小)的执行方式.也即idx_BusinessStatus索引的Index Seek
什么情况下才会发生TOP 1要比不加TOP 1慢(或者慢很多)
事实上,类似结构的数据分布,并非所有的情况下都会出现TOP 1比不加TOP 1慢的情况
那么什么时候TOP 1 可以选择正确的执行计划,而非采用低效的执行计划(排序列上的索引扫描)?
当然是跟符合条件的数据BusinessStatus=0的数据行数有关,只有符合条件的数据(BusinessStatus=0)达到一定数量之后才会发生(TOP 1比不加TOP 1慢)
上面说了,优化器误以为符合条件的数据(BusinessStatus=0)分布是均匀的,采用了排序列上的索引扫描的执行方式,
即便是优化器误以为符合条件的数据(BusinessStatus=0)分布是均匀的,
采用一开始的预估算法(平均分布:总行数/符合条件的数据行数)得到一个值,与符合条件的数据的行数本身对比,如果前者较大,就不会采用排序列上的索引扫描
这里太拗口了也很难表达清楚,直接上例子吧。
首先我改变符合条件(BusinessStatus=0)的数据的行数,让复合条件的数据变的少一些,
这里删除原来的BusinessStatus=0的5000行数据,插入符合条件的数据为1000行,然后重建索引,试试看TOP 1 的效果
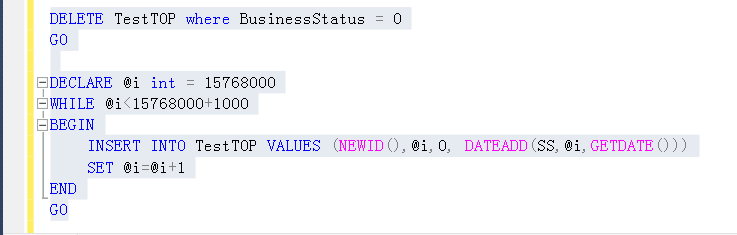
(插入之后注意重建一下BusinessStatus上的索引,得到最准确的统计信息)
此时再看SELECT TOP 1的查询方式,不会走排序列上的索引扫描了,走了查询条件列(idx_BusinessStatus)的索引查找,效率也上来了。
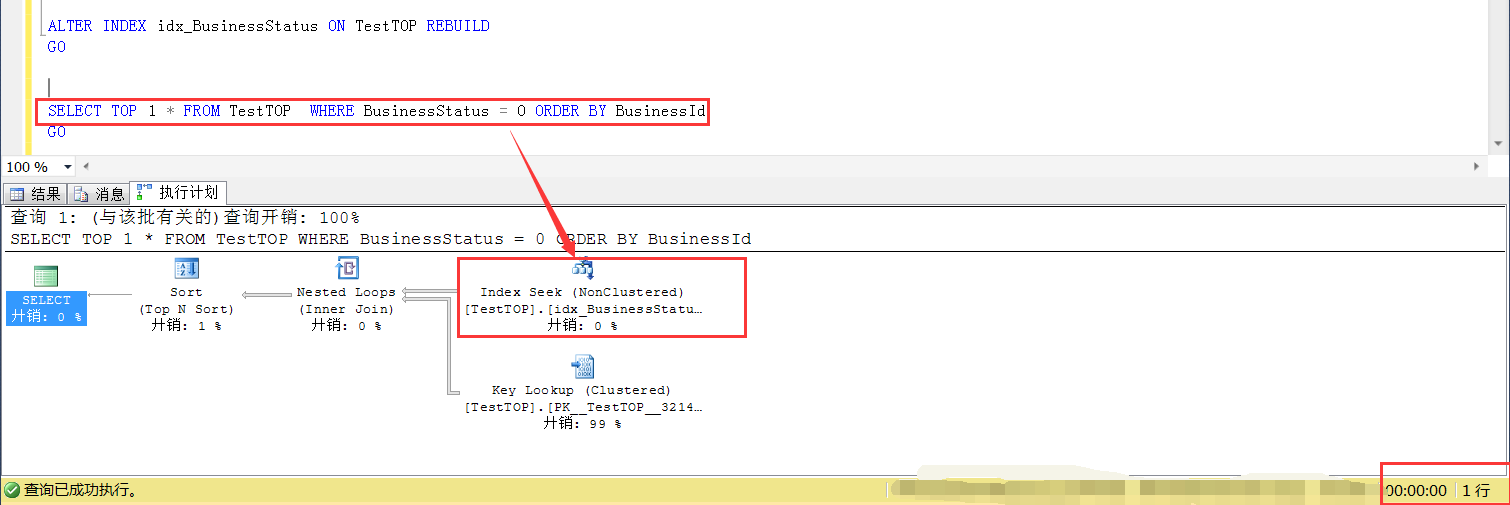
事实上我这里说了这么多,一直在想引出一个问题,那么符合条件(BusinessStatus=0)这个数据分布多少,SELECT TOP 1不会引起问题(比不加TOP 1慢)?
根据上述推论,这个值是动态的,大概如下:
假如:X=总行数/符合条件数据行数,Y = 符合条件数据行数
在统计信息完全准确的请下
如果X>Y,也即:总行数/符合条件数据行数>符合条件数据行数,则会导致在SELECT TOP 1的时候使用排序列的索引扫描替代查询列的索引查找。
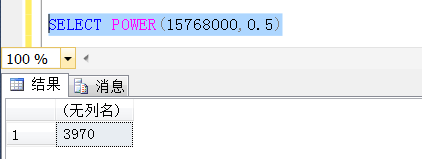
那么这个阈值是多少?按照这种算法推论,理论上讲,就是符合条件的数据的行数等于总行数的平方根,数学推到也很简单,事实上下面也测试了。
这个阈值在理论上是:3970行左右,
那么插入符合条件的数据为3900的时候(小于阈值,也即小于总行数的平方根),SELECT TOP 1是可以走索引的,如下两个截图

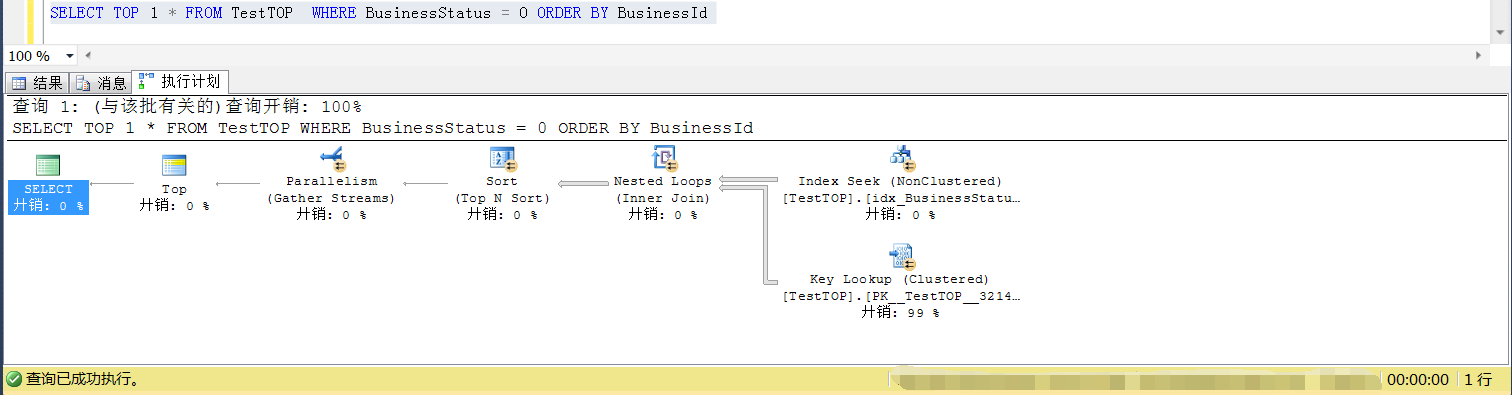
修改符合条件(BusinessStatus=0)的数据分布
而符合条件的数据大于阈值(大于阈值,也即大于总行数的平方根,)的时候,SELECT TOP 1 就开始走排序列的索引扫描,效率开始变慢
事实上导致SELECT TOP 1执行计划发生变化的这个阈值,具体的数值可以弄得更加精确,可以做到大于总行数的平方根一行,或者小于总行数的平方根一行。
但实际上测试发现,这个误差在三行左右,也就是说阈值具体的值为总行数的平方根加减三条:POWER(TableRowCount,0.5)±3左右。
当然也不是说“SELECT TOP 1的时候使用排序列的索引扫描替代查询列的索引查找”永远是低效的,
想象一下,整个表中绝大多数数据是复合条件的(BusinessStatus=0)的条件下,SELECT TOP 1可以很快地找到符合条件的一条数据
只是说,在某个阈值区间内,SQL Server查询引擎在生成执行计划的时候有一个盲区,此时查询引擎无法做出最明智的决定。
实际条件是千变万化的,规律是可寻的,不能认死了规律而不考虑实际情况。
如何解决SELECT TOP 1比不加TOP 1慢的情况:
上文中说了,查询加了TOP 1比不加TOP 1慢的根本原因就是如下:
事实情况下是复合条件的数据分布是不均匀的,而优化器误以为符合条件的数据分布(在整张表中)是均匀的,
正是因为有了这么一个矛盾,所以在加了TOP 1 的时候,优化器采用非最优化的方式造成的。
此时复合条件(BusinessStatus=0)为一开始的5000行,大于上述阈值
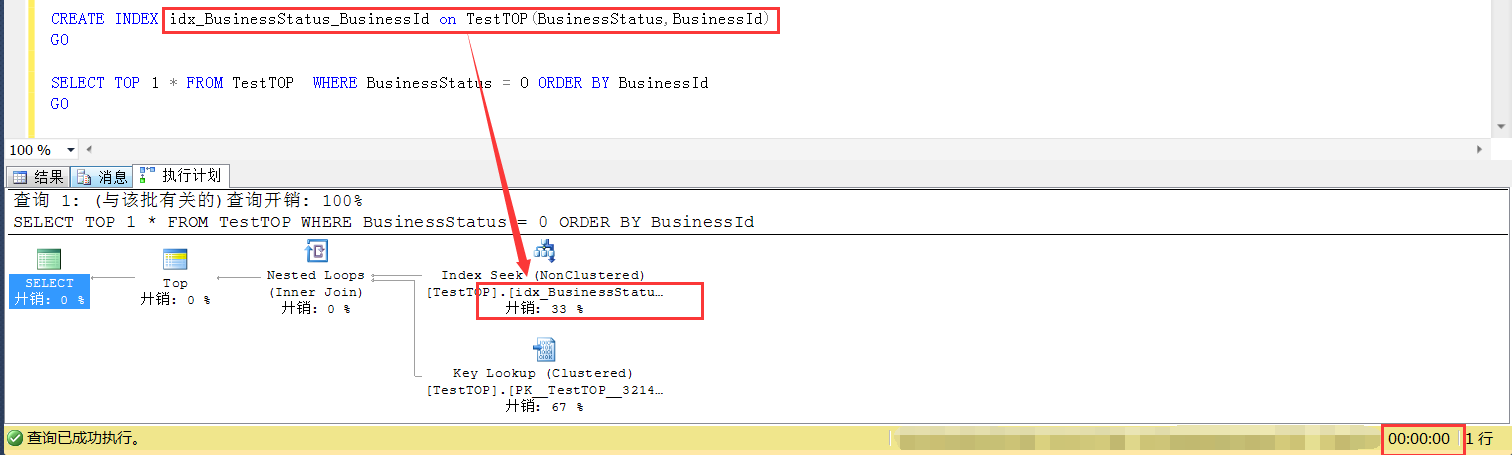
如果此时将查询条件列和排序列做成一个复合索引,就可以避免这种情况,
目的是走这个索引之后,找到的第一条复合条件的数据一定是拍序列上最小的,并且不会因为找多而再次排序浪费CPU时间
比如 create index ix_indexName on TableName(查询字段列,排序字段列),且复合索引的顺序不能改变,自己结合B树索引的结构想清楚为什么
具体原因,就不多说了,非要说的话,合理的索引就是让优化器更加清楚地弄清楚数据分布,可以做出更加明智的选择。
另外可以针对具体情况做filter索引,使得索引更加精确
当然也有其他办法,比如强制索引等,但是一旦加了强制索引就屏蔽掉优化器的作用了,如果没办法保证索引实在任何时候都是比较高效的情况下,不建议加强制索引。
总结:
本文分析了在某些特定的场景下,重现了SELCET TOP 1比不加TOP 1慢的场景,导致的原因分析以及解决办法。
事实上为了简明期间,还有非常多有意思的问题尚未展开,怕是写的越多,本文的主题就凸显不出来,有机会再对此尚未展开的问题继续进行分析。
补充一点:事实上真要是测试的话,任何一点点小小的改变,
比如查询语句中BusinessId排序改为DESC,甚至没有BusinessId上的索引,或者聚集索引建立在其他列上
都可以避免TOP 1比不加TOP 1慢的问题,这里的目的是为了重现TOP 1比不加TOP 1慢的现象条件和原因,以及不改变外因的情况下如何解决这一问题
谢谢。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号