
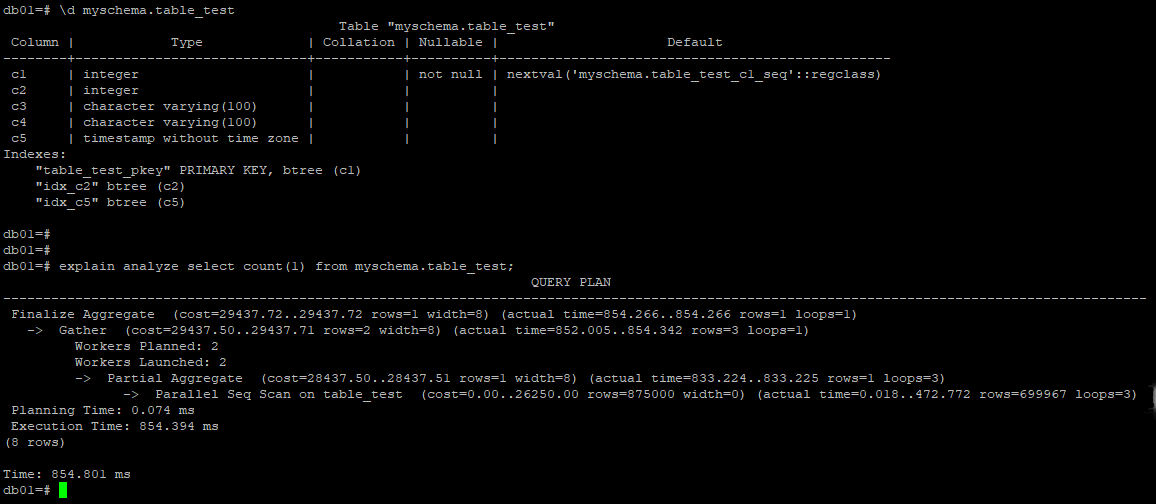
PostgreSQL MVCC原理以及事务可见性对执行计划的影响
不同的数据库的MVCC机制实现是不同的,MySQL或者Oracle中是通过将历史记录写入undo表空间实现,Postgresql是直接在当前页面保留这个数据的历史版本。
可以直观地想象一下Postgresql中修改一条记录事生成的“undo”记录的实现,(当然除此之外这个undo记录与xlog有关)

数据删除操作:这里示例删除上面修改后的记录的过程
删除操作是类似的一个过程,仅标记原始记录被删除(set t_xmax),但此时记录还保存在原地。

大量的历史版本会造成表膨胀的问题,不过目前看来应该不是问题,绝大多数情况下后台清理进程完全可以hold的住。
其实这个问题源自于MVCC需要保留不同版本数据的机制造成的,是一个支持MVCC的共性问题,MySQL中也有类似问题,MySQL 5.7之前undo 表空间膨胀且无法装直接收缩,业内也为此整出来各种奇淫巧技来处理该问题、所以某些问题是必须要经历或者说面对的,没有绝对好或者绝对坏的方法。
参考前面统计新信息更新时涉及到的vacuum自动化机制:https://www.cnblogs.com/wy123/p/13347176.html
多版本的只能在数据行级别体现,而无法在索引树中体现出来,也就是说索引上是没有版本信息的,删除一条记录会标记一条记录删除前的版本,以及将新写入一个条记录并标记为删除,这个过程可以认为该表上的索引是无感知的,或者对应的索引键是无法直接知道“我对应的记录被删除了”,这一点是postgresql所特有的。如果索引想知道其某个键值对应的数据行有没有发生变化或者被删除,是需要结合clog,也就是commit log(新版本中叫xact log)的,通过索引键访问数据行的时候,需要经过xlog做一次验证,才能决定该索引键是否发生了变换(增删改)。
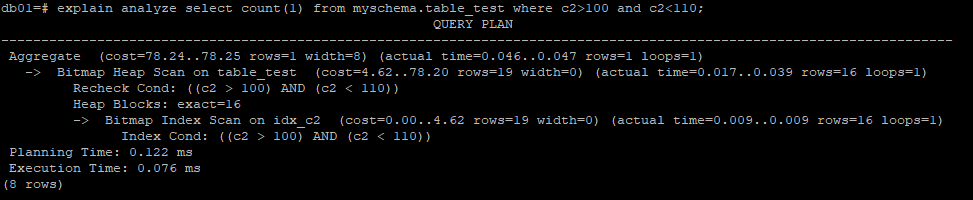
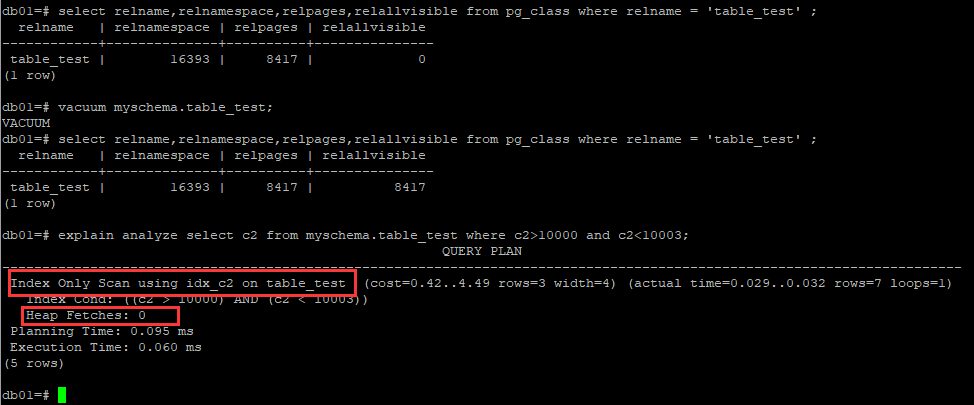
可以发现其执行过程中虽然是index only scan,但Heap Fetches标明依旧进行了回表(验证索引上符合条件数据的可见性),因此这里的执行计划显式的index only scan并不合适。


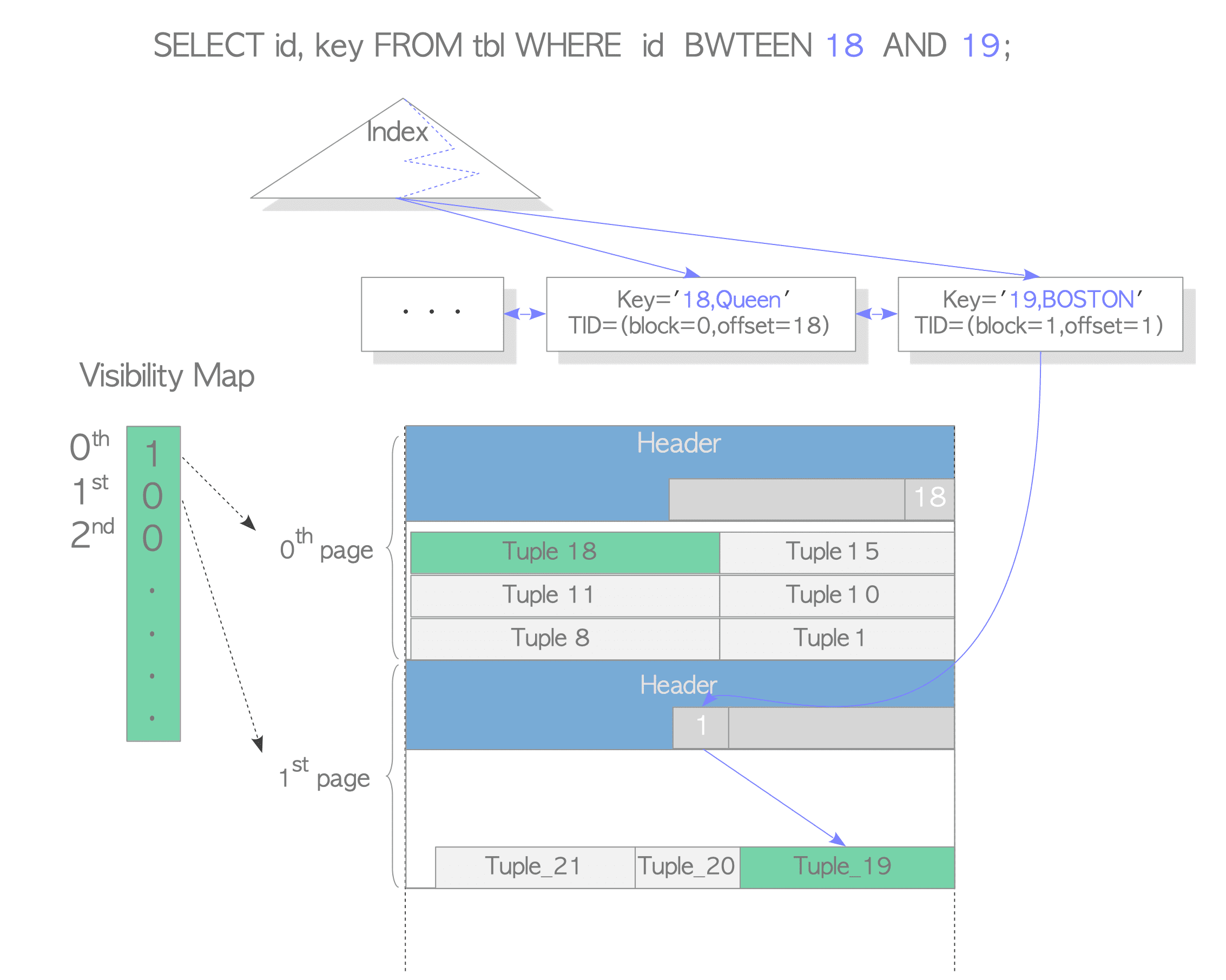
什么是heap fetch
参考这里:https://www.pgmustard.com/docs/explain/heap-fetches
The number of rows Postgres had to look up in the table, rather than the index, during an index-only scan.
Postgres still needs to be sure that the row is visible before it can return it, and that information is on the heap, not in the index. It can get around going to the heap for a particular row by checking the visibility map, which records whether or not each page has been changed recently.
If the page has changed, then that means a trip to the heap, the same as if we were doing a normal index scan — in fact it’s slightly worse than an index scan, because we’ve added in an extra check of the visibility map.
Heap fetches can sometimes be reduced by vacuum, or adjusting autovacuum settings to keep the visibility map more up to date.
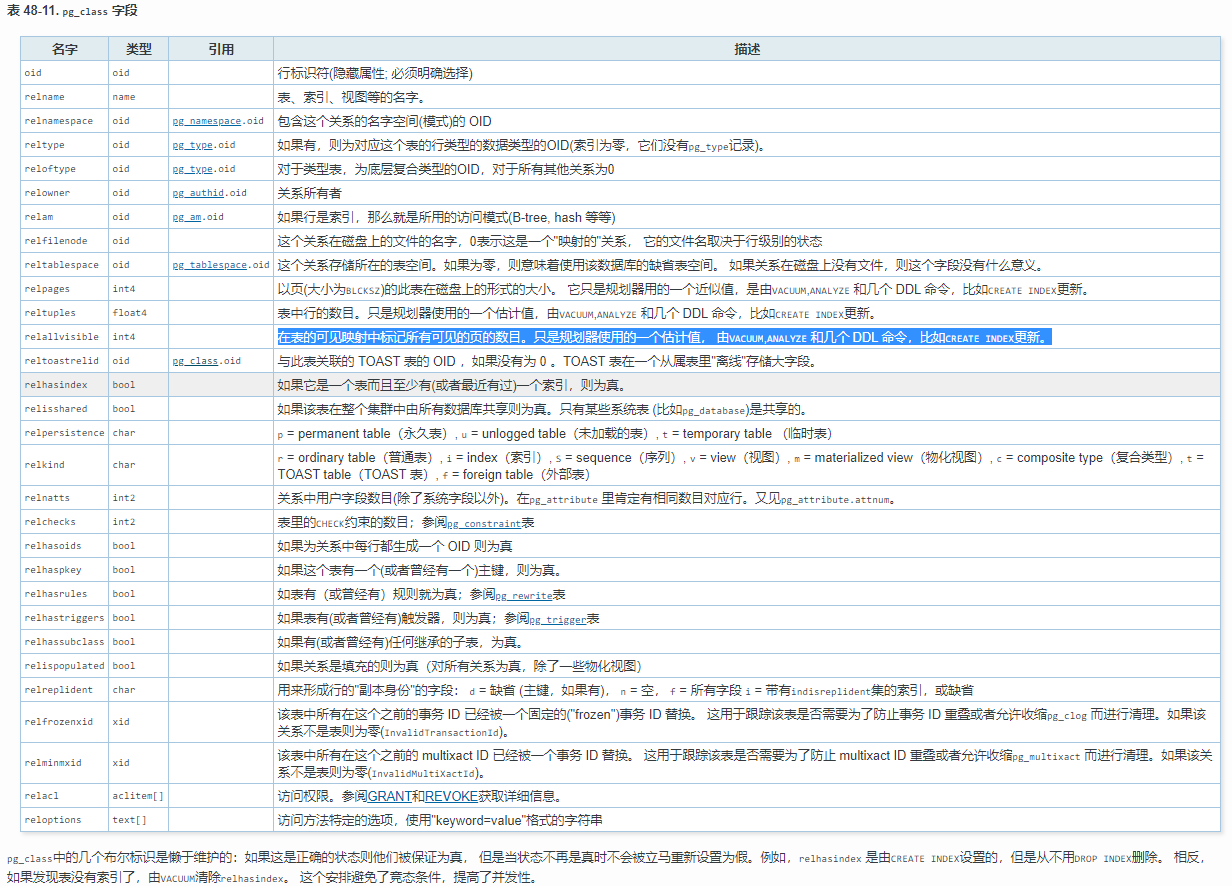
这里涉及到pg_class表的一个relallvisible字段,其含义是在表的可见映射中标记所有可见的页的数目。只是优化参考的一个估计值, 由VACUUM,ANALYZE 和几个 DDL 命令,比如CREATE INDEX更新。
这个字段的解释见这里:http://www.postgres.cn/docs/9.4/catalog-pg-class.html
Postgresql MVCC机制的优缺点
https://blog.csdn.net/xiaohai928ww/article/details/103742744
http://www.postgres.cn/docs/9.4/routine-vacuuming.html
https://www.enmotech.com/web/detail/1/701/1.html
https://smartkeyerror.com/PostgreSQL-MVCC-01
https://stackoverflow.com/questions/66183230/why-postgresql-indexes-do-not-contain-visibility-information
https://www.cnblogs.com/haylee/p/12206170.html
某些经验可以重用,但是不可复印

 浙公网安备 33010602011771号
浙公网安备 33010602011771号