


Redis主从结构主节点执行写入后wait命令对性能的影响
这里的Redis主从结构可以是简单的主从,sentinel,redis cluster中的主从等。
wait命令的作用:
此命令将阻塞当前客户端,直到当前Session连接(主节点上)所有的写命令都被传送到指定数据量的slave节点。
如果到达超时(以毫秒为单位),则即使尚未完全传送到达指定数量的salve节点,该命令也会返回(成功传送到的节点的个数)。
该命令将始终返回确认在WAIT命令之前发送的写命令的副本数量,无论是在达到指定数量的副本的情况下,还是在达到超时的情况下。
具体说就是:比如对于1主2从的结构,Wait要求3秒钟之内传送到2个节点,但是达到超时时间3秒钟之后只成功传送到了1个slave节点上,此时wait也不会继续阻塞,而是返回成功传送的节点个数(1)。
有点类似于MySQL的半同步复制,但是效果完全不能跟半同步相比,因为Redis本身没有回滚的功能,这里的wait命令发起之后,即便是超时时间之后没有送到任何一个slave节点,主节点也不会回滚。
wait命令无法保证Redis主从之间的强一致,不过,在主从、sentinel和Redis群集故障转移中,wait能够增强(仅仅是增强,但不是保证)数据的安全性。
既然wait命令在当前连接之后会等待指定数量的从节点确认,其主节点的写入效率必然会收到一定程度的影响,那么这个影响有多大?
这里做一个简单的测试,环境2核4G的宿主机,docker下的集群3主3从的Redis集群,因此不用考虑网络延迟,在执行写入操作之后,使用两个Case,对比使不使用wait命令等待传送到salve的效率,
1,单线程循环写入100000个key值
2,多线程并发,10个线程每个线程写入10000个key,一共写入100000个key
Case1:单线程循环写入100000个key值
结论:不使用wait命令,整体耗时33秒,集群中单个节点的TPS为1000左右;使用wait命令,整体耗时72秒,集群中单个节点的TPS为480左右,整体效率下降了50%多一点
单线程不使用WAIT
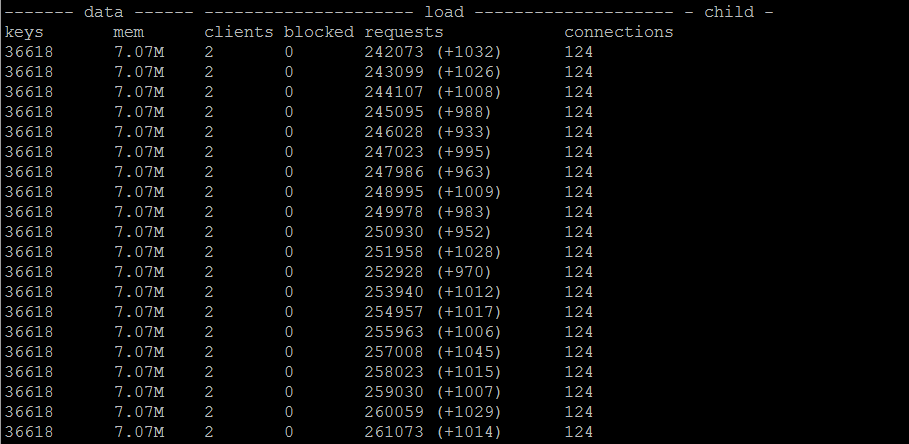
单线程使用WAIT(redis_conn.execute_command('wait', 1, 0))
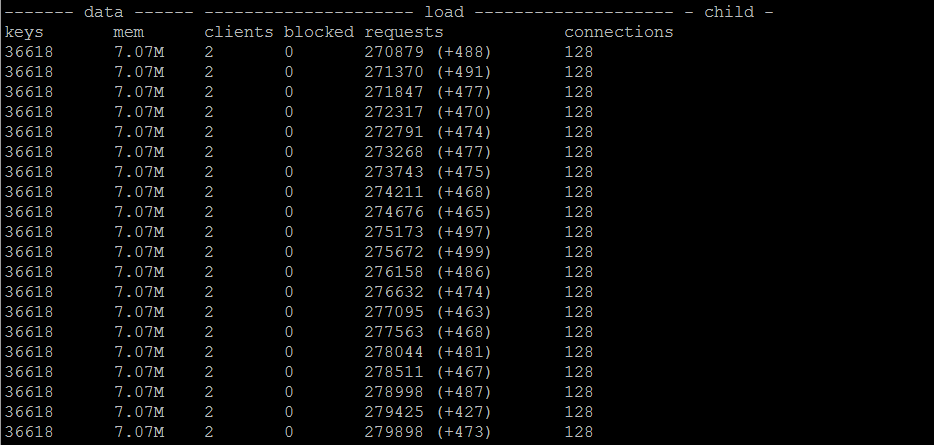
Case2:多线程循环写入100000个key值
结论:不使用wait命令,整体耗时19秒,集群中单个节点的TPS为1700左右;使用wait命令,整体耗时36秒,集群中单个节点的TPS为900左右,整体效率与单线程基本上一致,下降了50%多一点
多线程不使用WAIT,单节点上TPS可达到1700左右
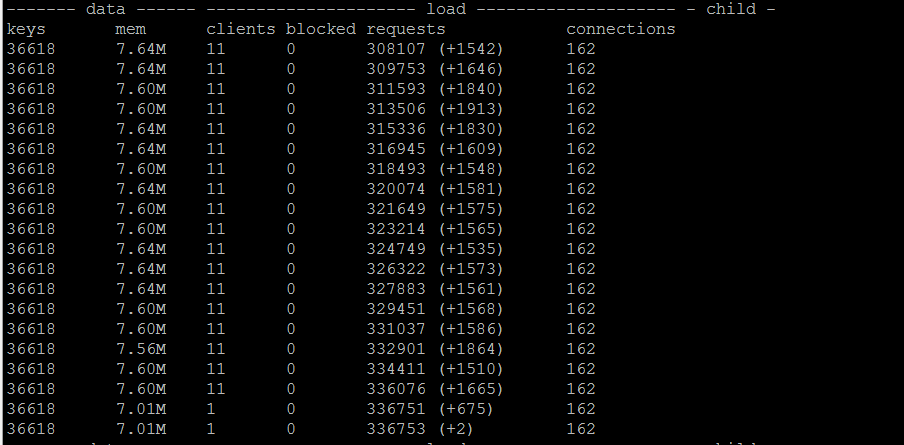
多线程使用WAIT,单节点上TPS可达到850左右
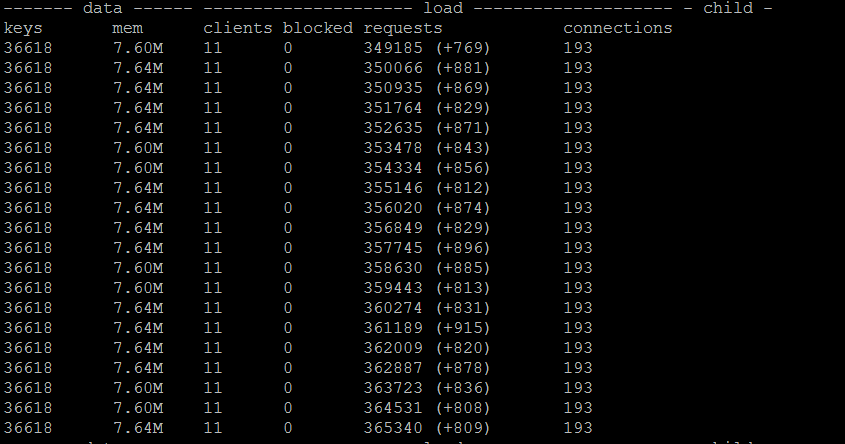
鉴于在多线程模式下,CPU负载接近于瓶颈,因此不能再加更多的线程数,测试数据也仅供参考。

总结:
wait能够在主节点写入命令之后,通过阻塞的方式等待数据传送到从节点,wait能够增强(但不保证)数据的安全性。
其代价或者说性能损耗也是不小的,通过以上测试可以看出,即便是不考虑网络传输延迟的情况下,其性能损耗也超出了50%。
#!/usr/bin/env python # coding:utf-8 import sys import time import datetime from rediscluster import StrictRedisCluster import threading from time import ctime,sleep def redis_cluster_write(): redis_nodes = [ {'host':'172.18.0.11','port':8888}, {'host':'172.18.0.12','port':8888}, {'host':'172.18.0.13','port':8888}, {'host':'172.18.0.14','port':8888}, {'host':'172.18.0.15','port':8888}, {'host':'172.18.0.16','port':8888}] try: redis_conn = StrictRedisCluster(startup_nodes=redis_nodes,password='******') except Exception: raise Exception redis_conn.config_set('cluster-require-full-coverage', 'yes') counter = 0 for i in range(0,100000): counter = counter+1 redis_conn.set('key_'+str(i),'value_'+str(i)) #redis_conn.execute_command('wait', 1, 0) if counter == 1000: print('insert 1000 keys '+str(str(datetime.datetime.now()))) counter = 0 def redis_concurrence_test(thread_id): redis_nodes = [ {'host':'172.18.0.11','port':8888}, {'host':'172.18.0.12','port':8888}, {'host':'172.18.0.13','port':8888}, {'host':'172.18.0.14','port':8888}, {'host':'172.18.0.15','port':8888}, {'host':'172.18.0.16','port':8888}] try: redis_conn = StrictRedisCluster(startup_nodes=redis_nodes, password='******') except Exception: raise Exception redis_conn.config_set('cluster-require-full-coverage', 'yes') counter = 0 for i in range(0, 10000): counter = counter + 1 redis_conn.set('key_' + str(thread_id)+'_'+str(counter), 'value_' + str(i)) #redis_conn.execute_command('wait', 1, 0) if counter == 1000: print(str(thread_id)+':insert 1000 keys ' + str(str(datetime.datetime.now()))) counter = 0 if __name__ == '__main__': #redis_cluster_write() threads = [] for i in range(10): t = threading.Thread(target=redis_concurrence_test, args=(i,)) threads.append(t) begin_time = ctime() for t in threads: t.setDaemon(True) t.start() for t in threads: t.join()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号