
Redis中的Scan命令的使用
Redis中有一个经典的问题,在巨大的数据量的情况下,做类似于查找符合某种规则的Key的信息,这里就有两种方式,
一是keys命令,简单粗暴,由于Redis单线程这一特性,keys命令是以阻塞的方式执行的,keys是以遍历的方式实现的复杂度是 O(n),Redis库中的key越多,查找实现代价越大,产生的阻塞时间越长。
二是scan命令,以非阻塞的方式实现key值的查找,绝大多数情况下是可以替代keys命令的,可选性更强
# -*- coding: utf-8 -*- # !/usr/bin/env python3 import redis import sys import datetime
def create_testdata(): r = redis.StrictRedis(host='***.***.***.***', port=***, db=0, password='***') counter = 0 with r.pipeline(transaction=False) as p: for i in range(0, 100000): p.set('key' + str(i), "value" + str(i)) counter = counter + 1 if (counter == 10000): p.execute() counter = 0 print("set by pipline loop") if __name__ == "__main__": create_testdata()
若使用keys命令,则执行keys key1111*,一次性全部查出来。
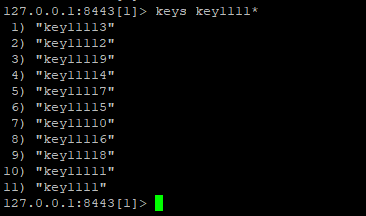
同样,如果使用scan命令,则用 scan 0 match key1111* count 20

scan的语法为:SCAN cursor [MATCH pattern] [COUNT count] The default COUNT value is 10.
SCAN命令是一个基于游标的迭代器。这意味着命令每次被调用都需要使用上一次这个调用返回的游标作为该次调用的游标参数,以此来延续之前的迭代过程。
这里使用scan 0 match key1111* count 20命令来完成这个查询,稍显意外的是,使用一开始都没有查询到结果,这个要从scan命令的原理来看。
scan在遍历key的时候,0就代表第一次,key1111*代表按照key1111开头的模式匹配,count 20中的20并不是代表输出符合条件的key,而是限定服务器单次遍历的字典槽位数量(约等于)。
那么,什么又叫做槽的数据?这个槽是不是Redis集群中的slot?答案是否定的。其实上图已经给出了答案了。
如果上面说的“字典槽”的数量是集群中的slot,又知道集群中的slot数量是16384,那么遍历16384个槽之后,必然能遍历出来所有的key信息,
上面清楚地看到,当遍历的字典槽的数量20000的时候,游标依旧没有走完遍历结果,因此这个字典槽并不等于集群中的slot的概念。
经过测试,在scan的时候,究竟遍历多大的COUNT值能完全match到符合条件的key,跟具体对象的key的个数有关,
如果以超过key个数的count来scan,必定会一次性就查找到所有符合条件的key,比如在key个数为10W个的情况下,一次遍历20w个字典槽,肯定能完全遍历出来结果。
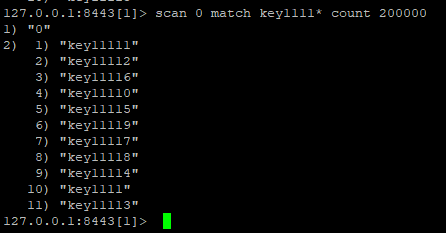
scan 指令是一系列指令,除了可以遍历所有的 key 之外,还可以对指定的容器集合进行遍历。
zscan 遍历 zset 集合元素,
hscan 遍历 hash 字典的元素、
sscan 遍历 set 集合的元素。
SSCAN 命令、 HSCAN 命令和 ZSCAN 命令的第一个参数总是一个数据库键(某个指定的key)。
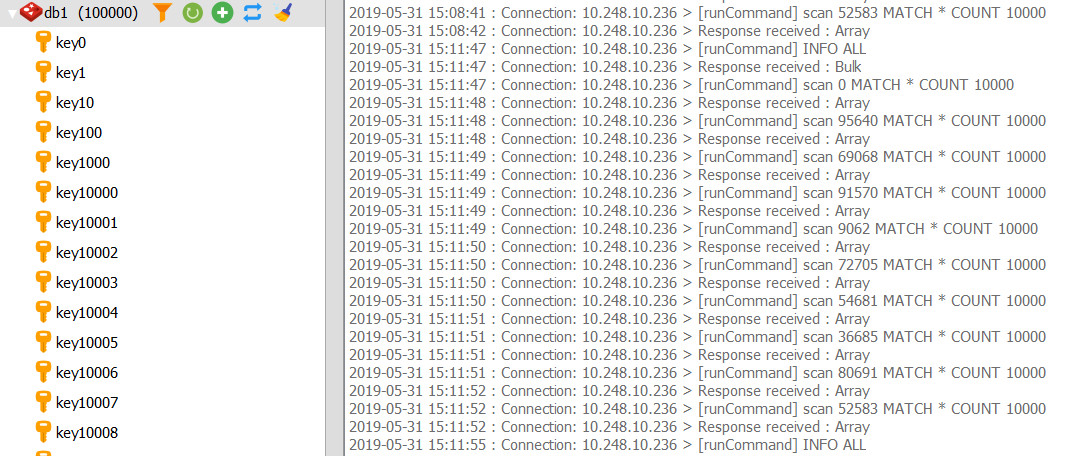
另外,使用redis desktop manager的时候,当刷新某个库的时候,控制台自动不断刷新scan命令,也就知道它在干嘛了
参考:http://jinguoxing.github.io/redis/2018/09/04/redis-scan/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号