
sqlserver默认隔离级别下并发批量update同一张表引起的死锁
提到死锁,最最常规的场景之一是Session1 以排它锁的方式锁定A表,请求B表,session2以排它锁的方式锁定B表,请求A表之类的,访问顺序不一致导致死锁的情况
本文通过简化,测试这样一种稍显特殊的场景:对同一张表,并发update其中的多行记录引起的死锁,同时简单分析,对于update操作的加锁步骤
这种场景引起的死锁比较少见,但是并不代表不存在,在某些并发场景下,可能会引起死锁的,应该需要引起重视。
测试环境搭建
sqlserver 数据库版本:
Microsoft SQL Server 2014 - 12.0.2269.0 (X64)
Jun 10 2015 03:35:45
Copyright (c) Microsoft Corporation
Enterprise Edition (64-bit) on Windows NT 6.1 <X64> (Build 7601: Service Pack 1)
创建测试表并写入测试数据
create table test_deadlock ( id int identity(1,1), col2 varchar(10), col3 varchar(5000), createdate datetime ) alter table test_deadlock add constraint pk_test_deadlock primary key(id) create index idx_col2 on test_deadlock(col2) go insert into test_deadlock select concat('A',cast(rand()*1000000 as int)),replicate('B',5000),getdate() go 1000000
死锁重现
两个session,假如是session 1 和session 2,分别造sqlserver manager studio查询窗口中执行如下语句,模拟两个session的并发操作
create table #t(col2 varchar(10)) insert into #t select top 1000 col2 from test_deadlock order by newid() go while 1=1 begin update a set createdate=getdate() from test_deadlock a inner join #t b on a.col2 = b.col2 end
逻辑就是随机写里临时表中1000行记录,然后依据临时表中的数据更新测试表test_deadlock
分别执行两个session的sql之后,因为#t是随机写入1000行数据,两个session中#t的数据肯定是不完全一样的,然后执行两个session的语句
等待执行一段时间之后(并不一定每次都会出现,或者很快出现,需要多次测试),就会发现其中一个session的执行遇到了死锁,如下
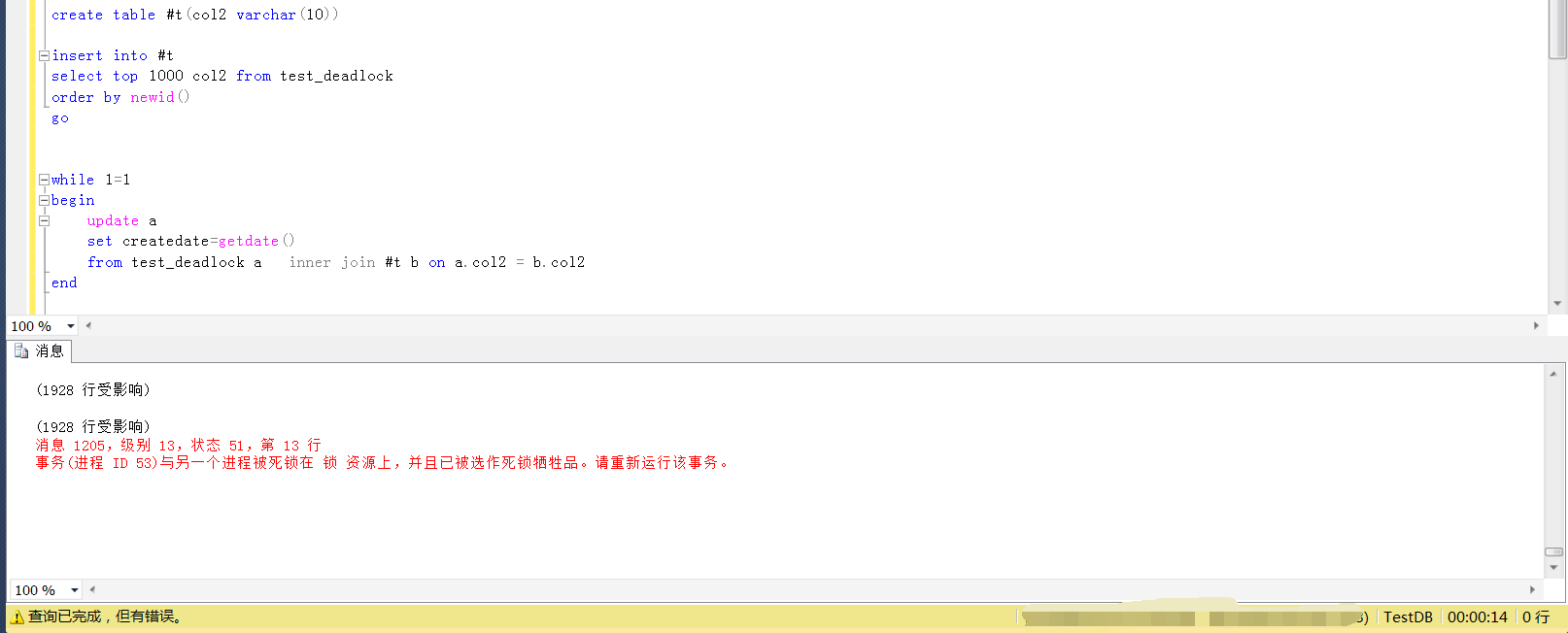
通过sqlserver自带的扩展事件[system_health]查看死锁的详细信息
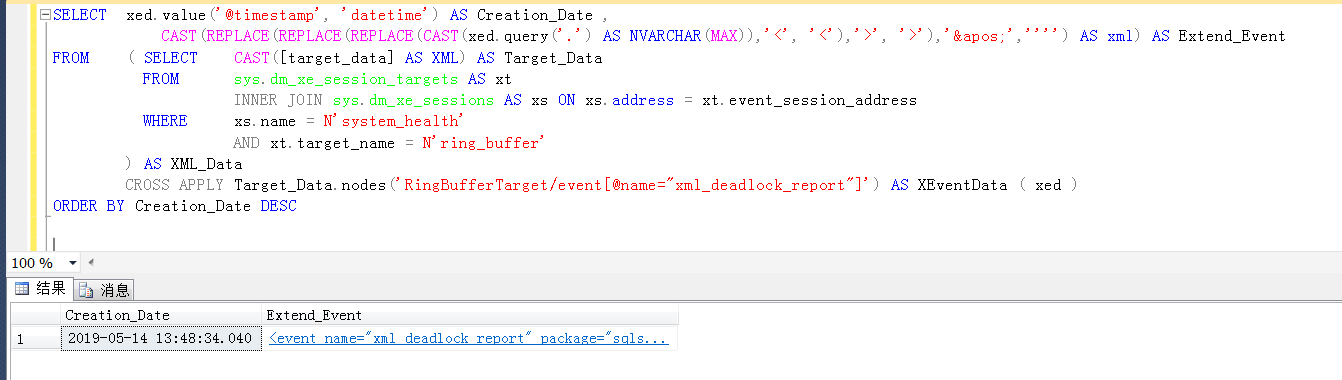
查看死锁xml的详细信息,非常清楚地显示,两个session在占用了某个key值的U锁之后,相互请求对方占用的U锁的,结果就是死锁
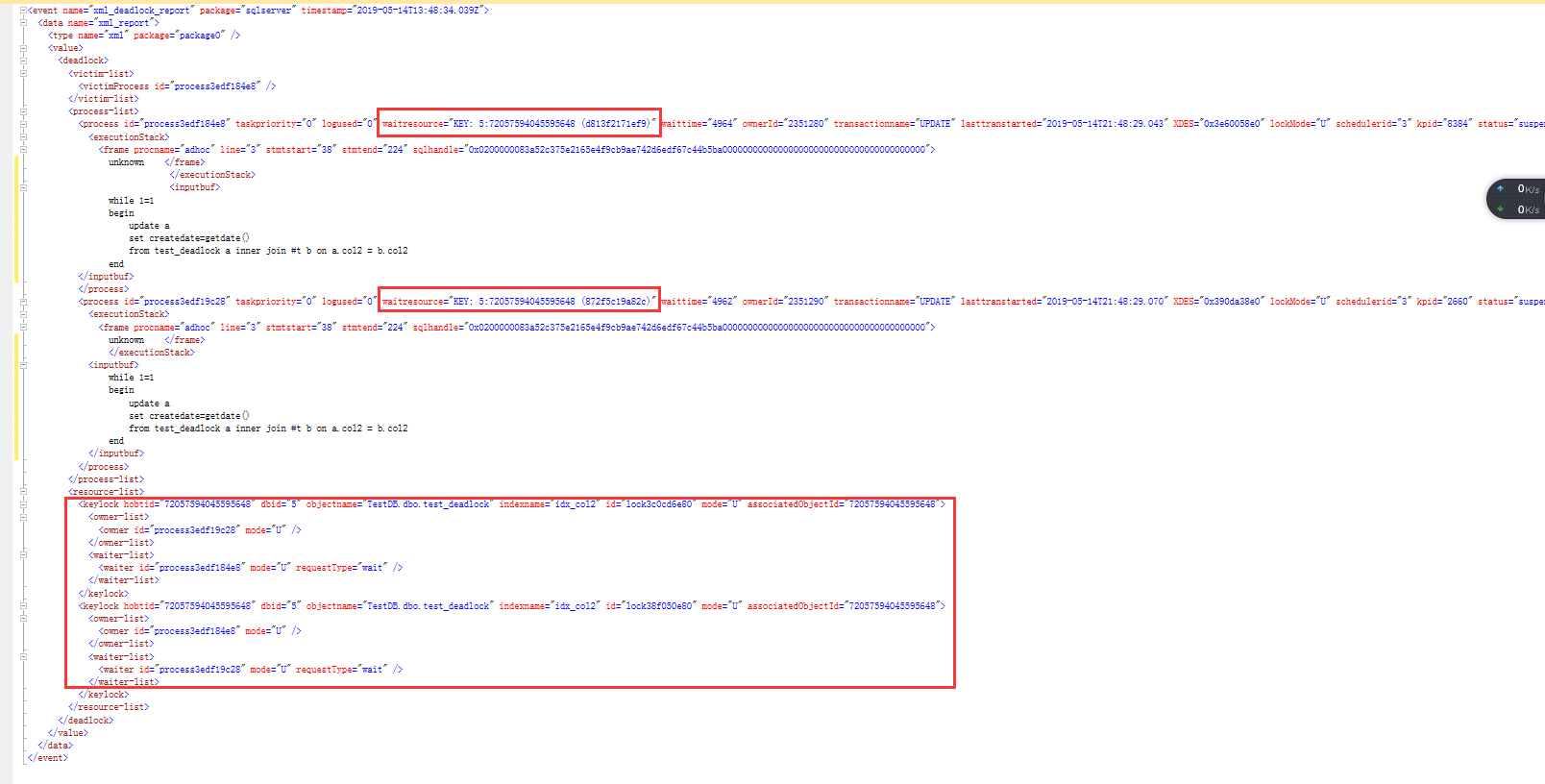
对于两个session wait的key分别是:KEY: 5:72057594045595648 (d813f2171ef9)和KEY: 5:72057594045595648 (872f5c19a82c)
关于key值格式的含义,简单说一下,以KEY: 5:72057594045595648 (872f5c19a82c)为例,5代表数据Id,72057594045595648 代表index的id,(872f5c19a82c)代表key值的内部Id
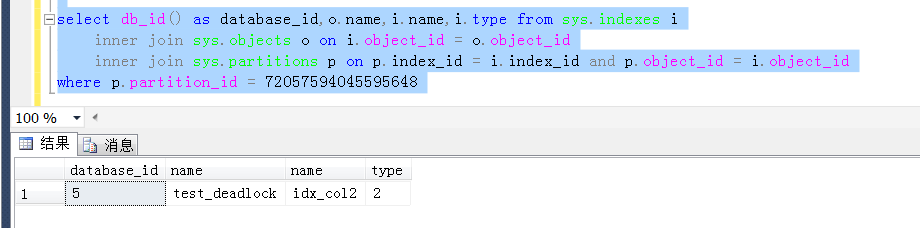
关于前两者,相对比较简单,通过系统表可以查询出来,如下是当前测试库执行的查询结果,很直观地显示了key值中的信息含义
关于(872f5c19a82c)代表key值的内部Id,可以通过一个未公布的系统函数 %%lockres%% 查看得到,如下,也相对比较清楚。关于 %%lockres%% 不做过多的表述,偏避免偏离主题。
有兴趣了解%%lockres%% 的参考:https://dba.stackexchange.com/questions/106762/how-can-i-convert-a-key-in-a-sql-server-deadlock-report-to-the-value
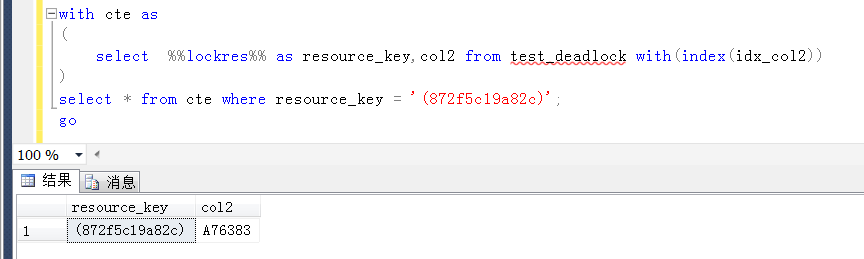
现在可以清楚地得到:
session1 以U锁的方式锁定了一个idx_col2上的索引值 (d813f2171ef9),请求索引值 (872f5c19a82c)上的U锁
session2 以U锁的方式锁定了一个idx_col2上的索引值 (872f5c19a82c),请求索引值(d813f2171ef9)上的U锁
U锁与U锁不兼容,然后发生了死锁。
这里简单分析一下,这两个key值内部Id对应的具体的key值以及两个session的锁定情况。
两个内部Id对应的col2字段分别是A229853和A76383,
也就是说session1 对col2=A229853 key值加U锁,请求col2 = A76383的key值的U锁
session2 对col2=A76383 key值加U锁,请求col2 = A229853 的key值的U锁

那么去具体的session(查询窗口)中的临时表验证一下这两个Id是不是同时存在于两个session的临时表中,是不是这样的。
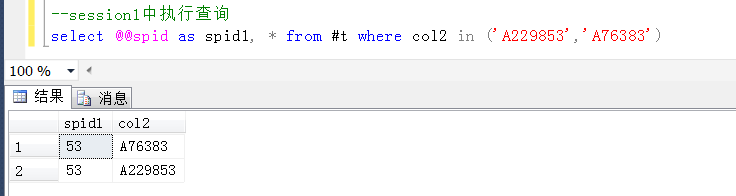
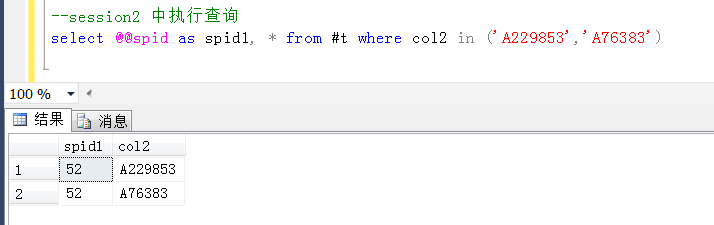
没有问题,session1和session2中都包含了这两个id,这里默认查询出来的顺序,也刚好相反,更加可以支持上述推断,在执行update的过程中,造成了上述的死锁。
死锁原因分析
update的加锁,这里是对1000个col2的值执行更新,内部可以看做是一个过程,即便是使用了索引查找(index seek)
批量update,虽然是一个事物,但是执行的过程,对于目标数据的加锁是一个过程(逐行),这个过程不是隔离的或者说排他性执行的(除非是表级别的排它锁)
粗略地讲,推断其大概过程如下:
依次遍历符合条件的目标数据(#t中的col2与test_deadlock)进行查找,如果找到,加U锁(尚不考虑锁升级为表锁)
伪代码如下
foreach(key in #t)--直接以#t中的col2字段的值,通过索引查找的方式驱动test_deadlock,依次加(U)锁
{
if(key==test_deadlock.col2)
{
updlock test_deadlock.col2
}
}
加锁,这里是逐行对test_deadlock中的col2 key加U锁是一个过程,而不是一瞬间。一旦两个session加锁目标存在交集,并且对加锁的key值加锁顺序不一致,就潜在发生死锁的可能性。
比如session1 先对key = A229853 的值加U锁,再视图key = A229853 加U锁
session2先对key = A229853 的值加U锁,再试图key = A229853 加U锁,死锁就因此而产生
这里的update语句,内部是一个事物没错,但是需要个事物区分来看,当前update加的锁是一个key锁,而不是表锁,既然是key锁,需要逐个查找然后加锁,而不是一次性加锁
这就是当前这种场景产生死锁的原因。
该死锁产生的条件
1,存在比较大的并发量,或者是做并发压力测试
2,并发session update的目标数据存在交集
3,服务器资源使用率比较高或者负载比较重的时候更容易出现
如何解决
上述分析原因是一次对不同的key值加U锁,不同session加锁目标存在交集,且加锁顺序不一致引起的,在read committed或者可重复度隔离级别,都无法解决上述家锁冲突问题
1,从逻辑key值加锁顺序入手:
问题的本质在于,并发session对目标数据加锁目标存在交集,且对加锁目标的加锁(key值)顺序不一致,如果使并发session对加锁目标(key值)加锁顺序一致,也就不会出现死锁的情况了。
如果按照对key值顺序的方式加锁(通过在key值上创建cluster索引),
可以将上面key值的随机访问变为顺序访问(table scan变为cluster index scan),只会出现相互阻塞,而不是死锁,想一想为什么……
这里通过对#t的目标值字段,创建一个索引,再经并发测试,不会出现死锁.
但是这种方式,并上不是最佳的,因为执行计划不会永远只有一种,
这里主观上要求一定是#t表驱动目标表test_deadlock,面对更加复杂的实际情形,如何保证?难道需要再次加强制索引+驱动顺序提示?(事实证明,这种方式极其不可靠)
insert into #t select top 1000 col2 from test_deadlock order by newid() create cluster index idx_col2 on #t(col2) go while 1=1 begin update a set createdate=getdate() from test_deadlock a inner join #t b on a.col2 = b.col2 end
2,从锁定方式入手:
可序列化隔离级别,或者直接对update的目标表加表级别锁解决
事实上经过测试,出乎意料的是,可序列化隔离级别依旧解决不了上述加锁冲突,如下,当然,序列化隔离级别下,死锁类型跟默认隔离级别下并不完全相同,是RangeS-U之间的冲突
序列化可能造成的死锁,也有大把的例子,这里不继续扯了,参考https://stackoverflow.com/questions/27347730/serializable-transaction-deadlock,https://stackoverflow.com/questions/39029573/why-does-a-serializable-isolation-level-lead-to-deadlock-and-concurrency-issues
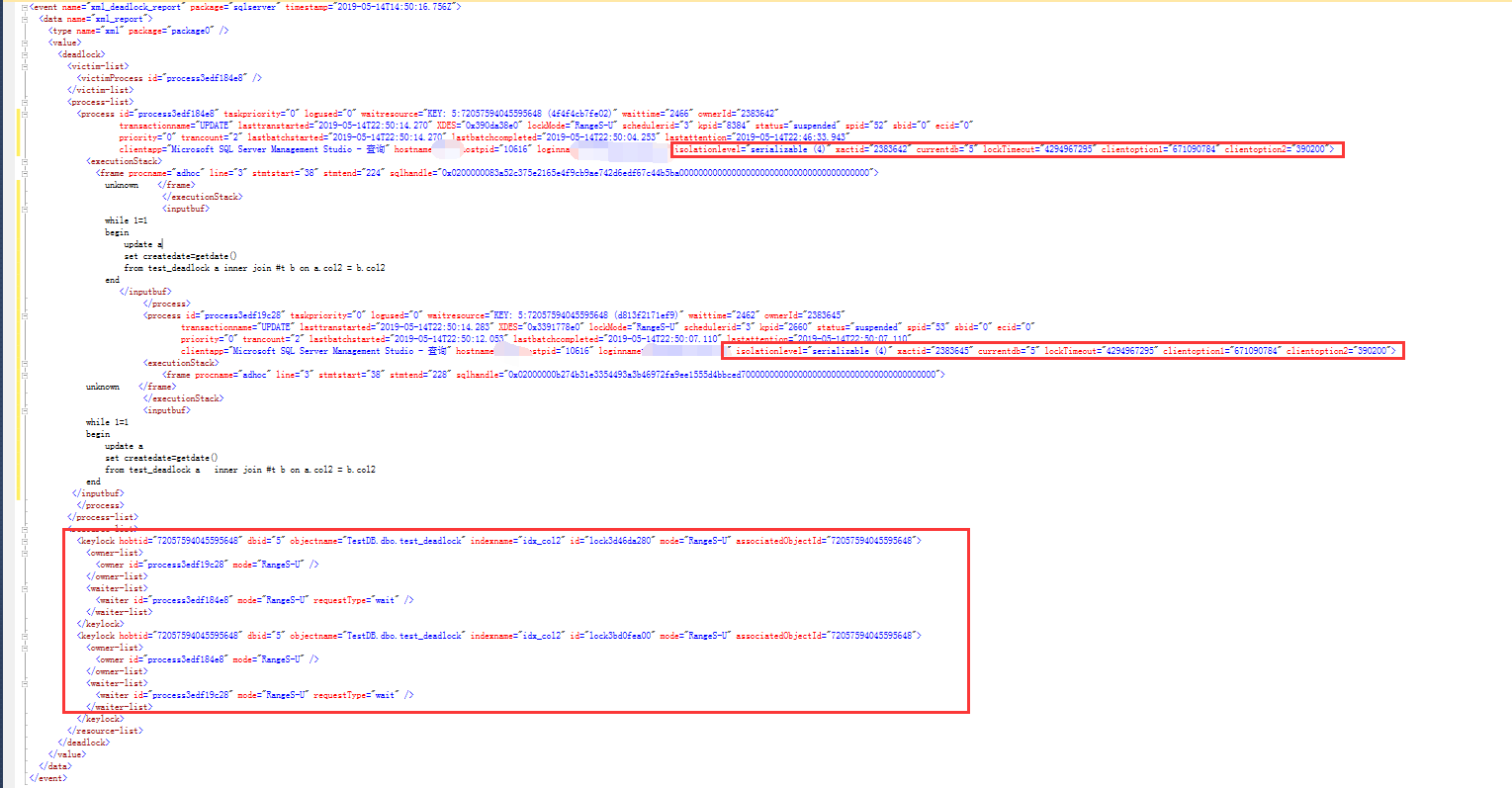
经测试,直接加表级别锁,可以解决上述死锁问题,参考如下
while 1=1 begin update a set createdate=getdate() from test_deadlock a with(updlock,tablock) inner join #t b on a.col2 = b.col2 end
另外,如果其他办法,也未尝不可,从应用程序的角度,可以使用类似于单例模式,从发起端开始排队,或者将目标数据写入队列的方式,依次排队打入数据的方式执行,都是可以避免死锁的。
最后
这种死锁,并不会轻易生成,但它是确确实实存在的,或者说是潜在的,笔者根据实际场景在本地反复做测试,中间也遇到一些问题
1,基于当前测试方式和场景,测试数据量要足够大,设计case的时候,要避免自动的锁升级造成测试干扰,避免某些写法让#t中生成的数据有序,都会重现这种场景
2,如果想从默认扩展事件system_health的ring_buffer中查看死锁信息,类似本文,需要对[system_health]默认的扩展事件加大ring_buffer的max_events_limit和max_memory。
至于为什么,参考这个:https://www.cnblogs.com/wy123/p/9055731.html
3,对于高性能的服务器,比较难以重现这种场景,因为每个session都执行的相对较快
4,测试库如果是完整恢复模式,小心撑爆事物日志或者磁盘空间
该死锁产生场景的扩展
对于类似的死锁产生场景,与并发批量update的逻辑一样,在并发批量做delete的时候也会出现死锁,并且已经在生产环境发现过。
并发批量insert,会不会产生类似的死锁,如果产生了,又如何解决,继续测试。
可能会死锁产生的场景,还是超出了预料……
并发insert的造成的死锁场景,也可以间接模拟出来,通过将批量insert拆分成多句单个的insert,来模拟key值加锁顺序冲突造成的死锁死锁
如下代码创建一个测试表
create table test_deadlock2 ( id int identity(1,1), col2 int, createdate datetime ) alter table test_deadlock2 add constraint pk_test_deadlock2 primary key(id) --注意,这里是的col2是一个唯一索引 create unique index idx_col2 on test_deadlock2(col2) --预先写入测试数据 insert into test_deadlock2 values (0,getdate()),(100,getdate()),(200,getdate()),(300,getdate())
这里模式的死锁方式并不是偶然的,是必然的,需要了解insert的加锁机制
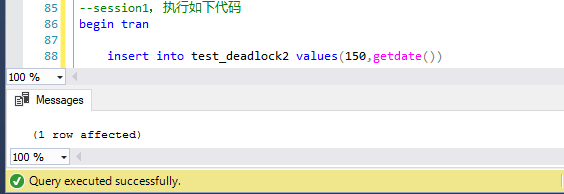
第一步,session1中,开事物,执行第一句insert语句
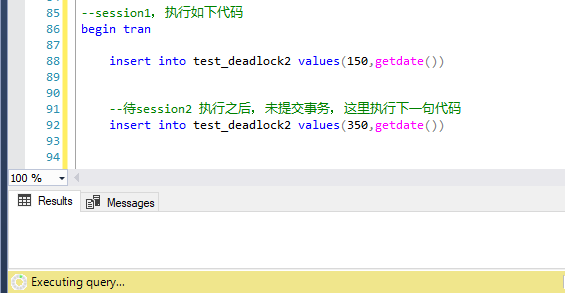
第二步,session2中,开事物,执行第一句insert语句

第三步,session1中执行第二句insert,被阻塞
第四部,session2中执行第二句insert语句,session2作为死锁的牺牲品,session1顺利完成
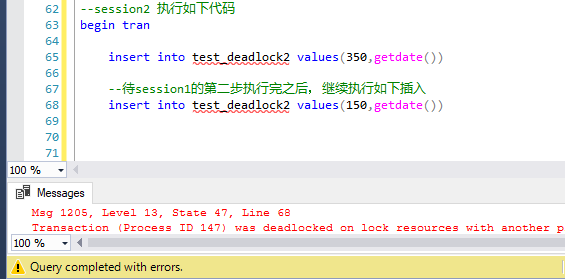
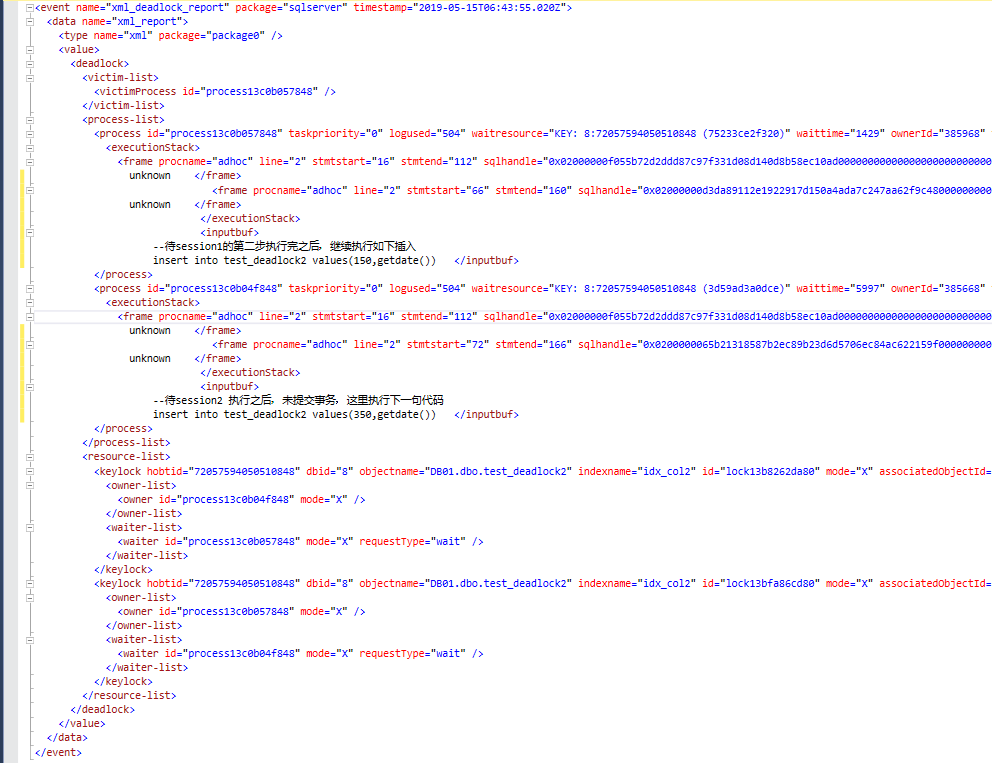
最后,session2死锁应运而生,session1 正常执行完成,至于问题的原因,跟上面批量update造成的死锁,基本上完全一样
只不过这里把批量insert(类似于insert into table select col from #t)转换为单行的insert,使得问题更容易出现。
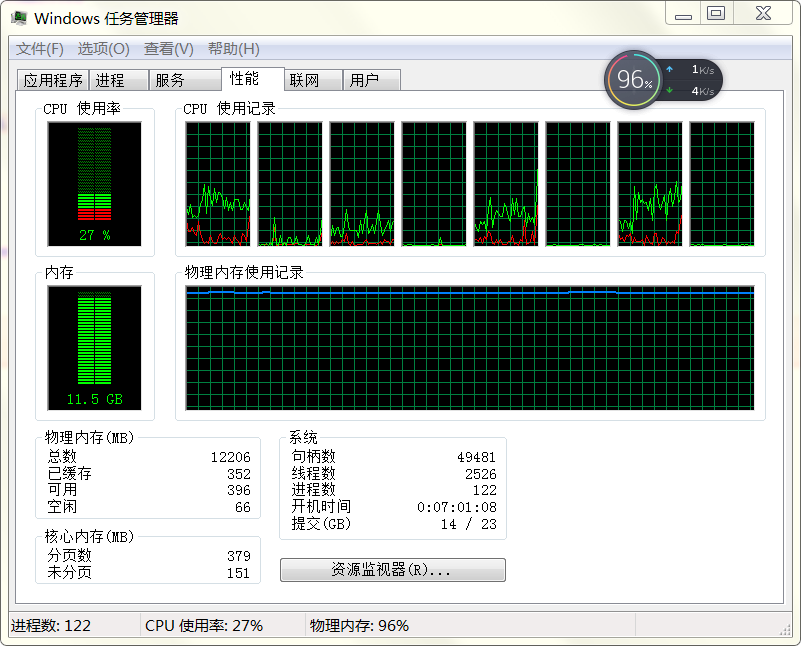
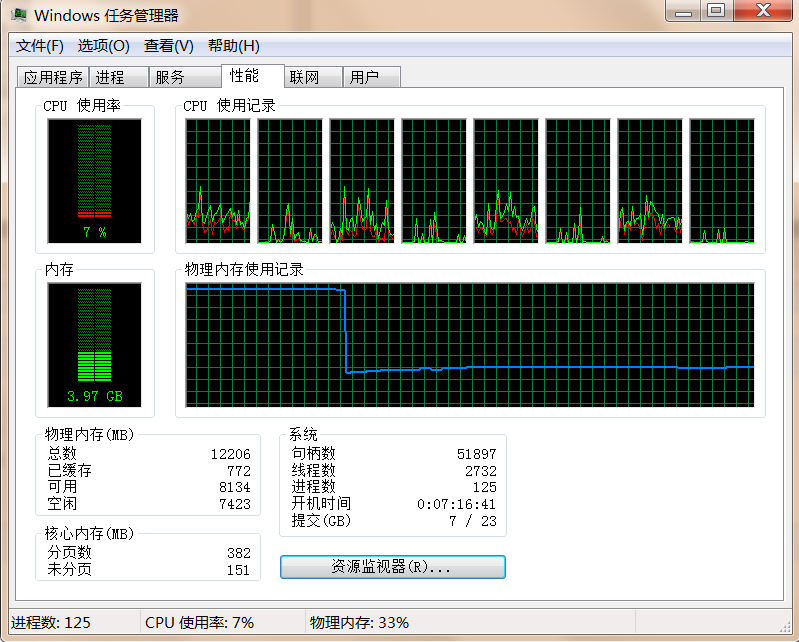
仅测试本文的场景,笔者个人的机器是12GB内存,8核心I7 CPU,测试过程,机器没有开其他应用程序,已经巨卡无比,内存几乎完全占满(当然CPU没有太大压力),重启数据库服务之后,瞬间轻松。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号