

CVPR 2025 | Meta提出FovealSeg:毫秒级IOI分割
前言 最近,一项来自纽约大学和 Meta Reality Labs 的联合研究引发了行业关注:Foveated Instance Segmentation —— 一种结合眼动追踪信息进行实例分割的新方法,已被 CVPR 2025 正式接收。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
本文转载自CVer
仅用于学术分享,若侵权请联系删除
招聘高光谱图像、语义分割、diffusion等方向论文指导老师

- 代码连接:https://github.com/SAI-Lab-NYU/Foveated-Instance-Segmentation
- 论文连接:https://arxiv.org/pdf/2503.21854
1. 从算力瓶颈谈起
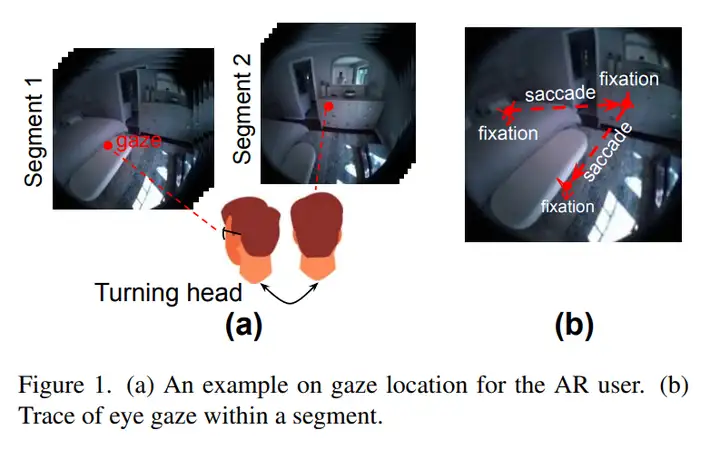
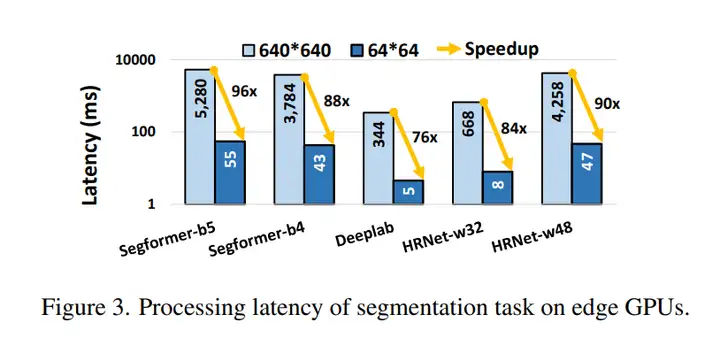
在当下主流的 AR / VR 头显中,内置相机往往具备 720 P、1080 P 乃至 1440 P 的拍摄能力,但要想在如此高分辨率的画面上做实例分割,推理延迟常常飙升至数百毫秒甚至秒级,远超人眼在交互中对时延(50–100 ms)所能接受的舒适阈值。论文 Foveated Instance Segmentation 便是从 “为什么一定要整幅图都分割” 这一疑问切入,指出绝大多数计算其实浪费在用户根本不关注的区域上。Figure 1 里的卧室示例就说明,用户目光仅停留在床或衣柜等极小区域,而 Figure 3 则量化了分辨率与延迟的关系:当输入从 640 × 640 缩到 64 × 64 时,延迟能从 300 ms 量级骤降到十毫秒级。
2. 人眼注视模式带来的灵感
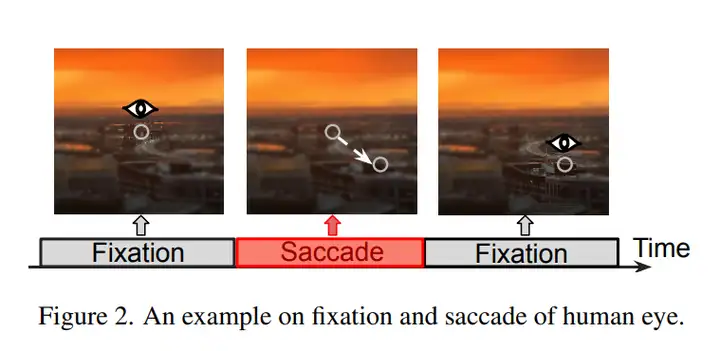
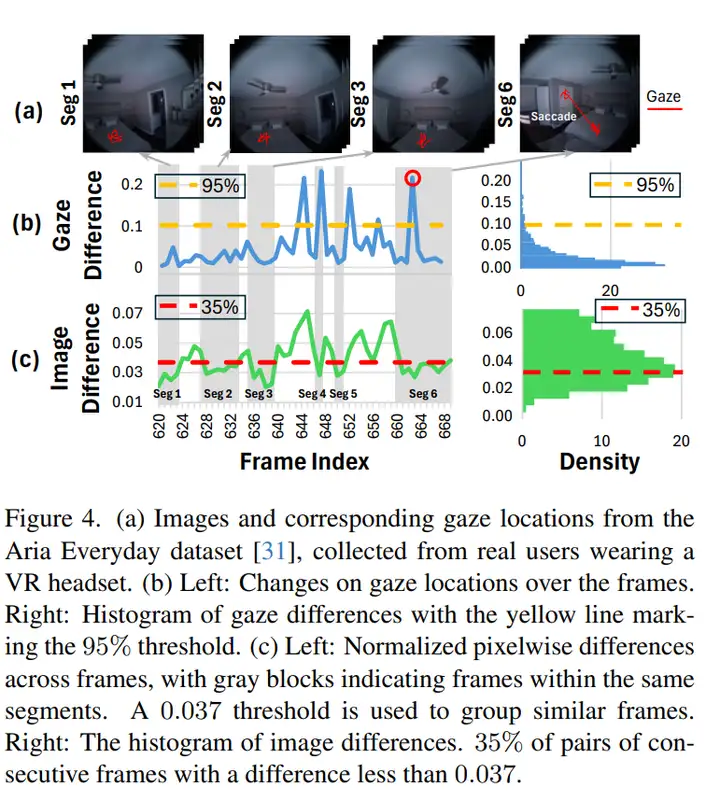
与桌面视觉任务不同,XR 用户的视线呈 “凝视 — 扫视” 交替:每秒 1–3 次扫视,每次 20–200 ms;扫视期间视觉输入被大脑抑制,凝视期间只有注视点周围拥有高视觉敏锐度。Figure 2 直观展示了凝视 / 扫视节奏,而作者在 Aria Everyday Activities 数据集上的统计进一步揭示:只需像素差分即可将视频切成 “视段”,段内帧间差异极小;若注视点位移低于 0.1 的阈值,上一帧的分割结果即可直接复用(Figure 4)。这为跨帧掩码复用和区域限定分割奠定了扎实的人因与统计基础。
3. 系统总览:FovealSeg 框架
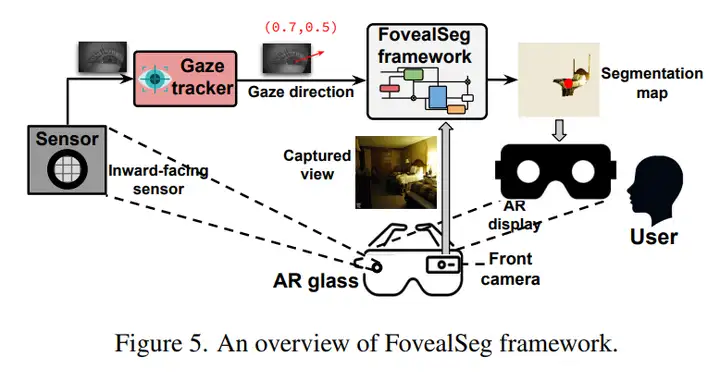
作者据此提出 FovealSeg:内向摄像头以 120 Hz 捕获眼部图像,经眼动追踪 5–10 ms 就能得出注视坐标;外向摄像头同步采集前向高分辨率画面。框架首先检测是否发生扫视(阈值 α),再判断场景是否突变(阈值 β),若两者皆否,就把分割任务限制在当前 gaze 坐标附近的 IOI 区域,并复用历史掩码。流程图见 Figure 5。
4. 算法核心:FSNet
FovealSeg 的核心网络模块是 FSNet:
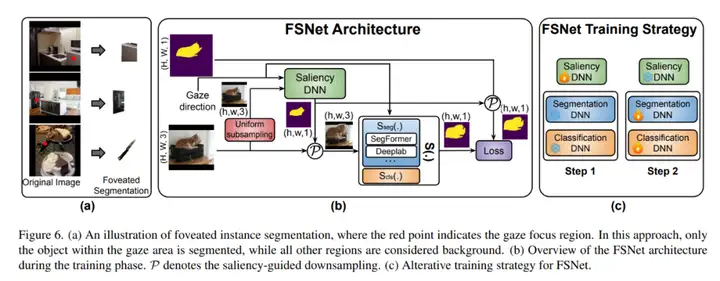
1. 显著性自适应下采样 —— 把 gaze 坐标编码成距离图,与原图拼成四通道张量;Saliency DNN 依据距离图按需放大 IOI、压缩背景。
2. 分割 / 分类双分支 —— 前支路输出二值 IOI 掩码,后支路输出类别向量,二者外积得最终掩码。
3. 阶段式训练 —— 先固定分割网训练 Saliency DNN,再反向微调分割 / 分类分支;Dice Loss + 面积加权 Focal Loss 解决小目标易被背景淹没的顽疾。
Figure 6 依次展示了 IOI 局部放大策略的可视化示意、网络结构图和交替训练流程。
5. 效果验证:速度与精度双赢
在 ADE20K、LVIS、Cityscapes 等数据集上,作者用 Jetson Orin NX 做测试:
- FSNet 将输入缩到 64 × 64 仍能把 IoU 提到 0.36 以上,比统一下采样基线高 ≥ 0.14;
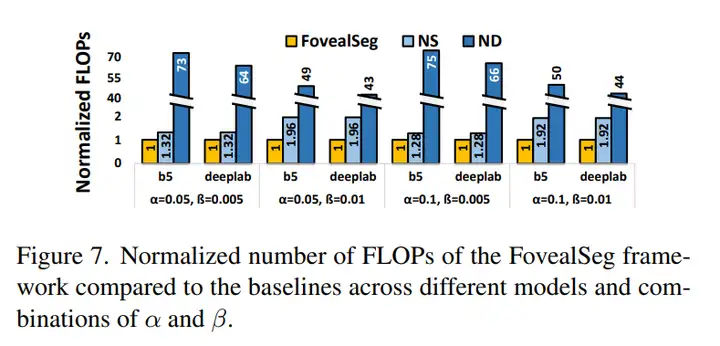
- FovealSeg 进一步利用跨帧重用,在 α=0.1、β=0.01 设置下把 FLOPs 降到 ND(无下采样 baseline)基线的 1⁄75,比 NS(无帧复用 baseline)进一步降低近两倍。
Figure 7 的柱状图直观呈现了不同 α、β 组合下三种方案的 FLOPs 差距,端到端延迟仅 84 ms,重回实时交互红线。
6. 消融与讨论
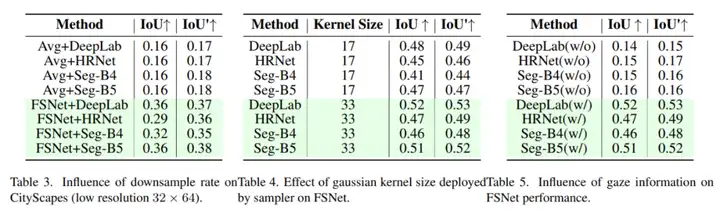
论文还就下采样倍率、Gaussian Kernel 大小、gaze 输入等因素做了消融:
- 下采样过猛虽降精度,但 FSNet 依旧显著优于平均池化基线;
- Kernel 越大,显著区域权重越高,精度随之提升。
- 将 gaze 坐标替换成随机噪声,IoU 至少掉 0.3,说明注视信息是方法立足之本。
这些对比虽以表格呈现(Table 3–5),但也佐证了 “人因驱动 + 统计约束” 在模型设计中的必要性。
7. 小结与展望
FovealSeg 以人眼生理特征为钥匙,把‘中央精细处理、周边压缩简化’的 foveated 思想真正落到实例分割上:
- FSNet 巧用显著性采样,把计算集中在 IOI,兼顾分割和分类;
- FovealSeg 又用扫视检测与帧间复用,把冗余推理压到极致。
在当前 XR 终端算力有限的背景下,它为 “毫秒级 IOI 分割” 提供了切实可落地的方案;随着更高精度、低延迟的眼动传感器普及,以及多 IOI 并行、多任务融合的需求升温,foveated 视觉计算或将成为 XR 生态里的 “默认范式”,也为更多实时计算密集型任务(如场景理解、三维重建)提供新的能效平衡思路。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
LSKA注意力 | 重新思考和设计大卷积核注意力,性能优于ConvNeXt、SWin、RepLKNet以及VAN
CVPR 2023 | TinyMIM:微软亚洲研究院用知识蒸馏改进小型ViT
ICCV2023|涨点神器!目标检测蒸馏学习新方法,浙大、海康威视等提出
ICCV 2023 Oral | 突破性图像融合与分割研究:全时多模态基准与多交互特征学习
HDRUNet | 深圳先进院董超团队提出带降噪与反量化功能的单帧HDR重建算法
南科大提出ORCTrack | 解决DeepSORT等跟踪方法的遮挡问题,即插即用真的很香
1800亿参数,世界顶级开源大模型Falcon官宣!碾压LLaMA 2,性能直逼GPT-4
SAM-Med2D:打破自然图像与医学图像的领域鸿沟,医疗版 SAM 开源了!
GhostSR|针对图像超分的特征冗余,华为诺亚&北大联合提出GhostSR
Meta推出像素级动作追踪模型,简易版在线可玩 | GitHub 1.4K星
CSUNet | 完美缝合Transformer和CNN,性能达到UNet家族的巅峰!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号